中国建设教育协会网站培训中心怎样制作网站的步骤

为什么要学习unittest
按照测试阶段来划分,可以将测试分为单元测试、集成测试、系统测试和验收测试。单元测试是指对软件中的最小可测试单元在与程序其他部分相隔离的情况下进行检查和验证的工作,通常指函数或者类,一般是开发完成的。
单元测试可以将测试工作前移,及早发现问题,降低解决问题的成本。同时单元测试还可以保证单个模块的功能没有问题,为后续的集成测试提供准备,可以减少合成后的出现的问题。
对于测试来说,单元测试就是执行用例。为了更好的管理用例,我们需要学习Python自带的单元测试框架unittest.
unittest框架及原理
unittest是python自带的一套测试框架,学习起来也相对容易,unittest框架最核心的概念有四个:
- test case:测试用例。unittest中提供了一个基本类TestCase,可以用来创建新的测试用例,一个TestCase的示例就是一个测试用例;unittest中测试用例的方法都是以 test开头的,且执行顺序会按照方法名的ASCII值排序。
- test fixure:测试夹具。用于测试用例换进的搭建和销毁,即用例测试前环境的大件(SetUp前置条件),测试后环境的恢复(TearDown后置条件)。比如测试前需要登陆获取token等就是测试用例需要的环境,运行完成后执行下一个用例前需要还原环境,以免影响下一条用例的测试结果。
- test suit:测试套件。用来把需要一起执行的测试用例几种放到一块执行,相当于一个篮子。我们一般使用 TestLoader来加载测试用例到测试套件中。
- test runner:测试运行。用来执行测试用例的,并返回测试用例的执行结果。可以结合图形或者文本接口,把返回的测试结果更形象的展示出来,如 HTMLTestRunner.
unittest断言
断言是测试用例的中很重要的一部分内容,可以用来检查操作是否正确。比如说登入处理,成功后的页面一定有类似于用户名称之类的元素,这个时候我们就可以使用断言判断预期结果与实际是否一致,如果吻合,就可以认为测试用例通过。
在Python基础中,有一个 assert断言方法,基本使用格式为 assert 表达式,基本信息。在unittest框架中,也提供了一个自带的断言方式,如果断言失败即不通过就会抛出一个 AssertionError断言错误;成功则标识通过。
以下的断言方法都有一个 msg=None参数(表中只列出了第一个,其实都有),默认返回 None。但是如果指定msg参数的值,则将该信息作为失败的错误信息返回。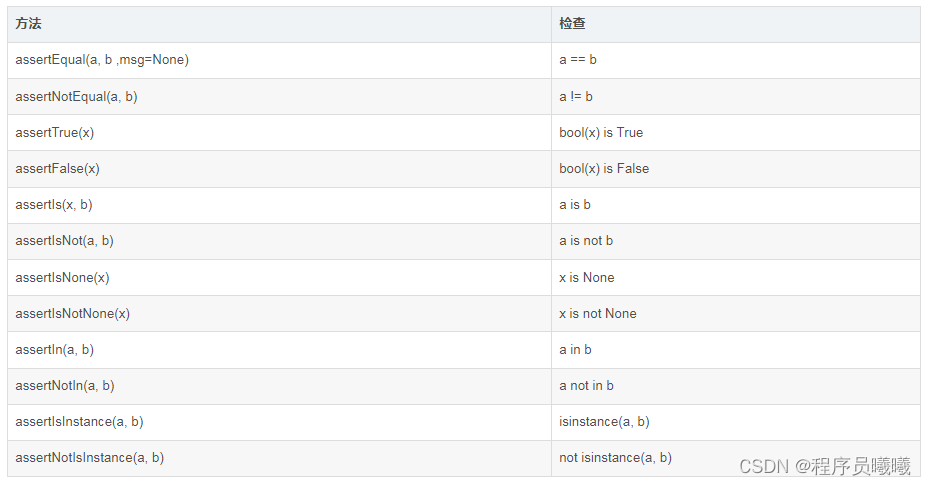
TestCase测试用例
编写测试用例前,我们需要创建一个类继承unittest里面的TestCase类,之后我们才能真正的使用unittest框架去编写测试用例.
步骤如下:
导入unittest模块
创建一个测试类,继承unittest.TestCase类
定义测试方法,方法名必须以test_开头
调用unittest.main()方法来运行测试用例。unittest.main()方法会搜索该模块下所有以test开头的测试用例和方法,并自动执行。
代码示例
# 注册功能代码# users列表存储成功注册的用户
users = [{'username': 'testing', 'password': '123456'}] def register(username, password1, password2):if not all([username, password1, password2]):return {'code': 0, 'msg': '所有参数不能为空.'}# 注册for user in users:if username == user['username']:return {'code': 0, 'msg': '用户名已存在!'}else:if password1 != password2:return {'code': 0, 'msg': '两次密码输入不一致!'}else:if 6 <= len(username) <= 18 and 6 <= len(password1) <= 18:# 追加到users列表users.append({'username': username, 'password': password2})return {'code': 0, 'msg': '注册成功.'}else:return {'code': 0, 'msg': '用户名和密码的长度必须在6~18位之间.'}import unittest
from demo import register # 导入被测试代码class RegisterTest(unittest.TestCase):'''注册接口测试类'''def test_register_success(self):'''注册成功'''data = ('palien', 'palien', 'palien') # 测试数据result = register(*data) # 测试结果expected = {'code': 0, 'msg': '注册成功.'} # 预期结果self.assertEqual(result, expected) # 断言测试结果与预期结果一致# passdef test_username_exist(self):'''注册失败-用户名已存在'''data = ('testing', '123456', '123456')result = register(*data)expected = {'code': 0, 'msg': '用户名已存在!'}self.assertEqual(result, expected)def test_username_isnull(self):'''注册失败-用户名为空'''data = ('', 'palien', 'palien')result = register(*data)expected = {'code': 0, 'msg': '所有参数不能为空.'}self.assertEqual(result, expected)# passdef test_username_lt18(self):'''注册失败-用户名长度大于18位'''data = ('palienpalienpalienpalien', 'palien', 'palien')result = register(*data)expected = {'code': 0, 'msg': '用户名和密码的长度必须在6~18位之间.'}self.assertEqual(result, expected)# passdef test_password1_not_password2(self):'''注册失败-两次输入密码不一致'''data = ('palien', 'palien1', 'palien2')result = register(*data)expected = {'code': 0, 'msg': '两次密码输入不一致!'}self.assertEqual(result, expected)# pass# 如果要直接运行这个测试类,需要使用unittest中的main函数来执行测试用例
if __name__ == '__main__':unittest.main()# Output
Windows PowerShell
版权所有 (C) Microsoft Corporation。保留所有权利。尝试新的跨平台 PowerShell https://aka.ms/pscore6PS D:\d_02_study\01_git> cd d:/d_02_study/01_git/papers/system/02automation
PS D:\d_02_study\01_git\papers\system\02automation> & C:/Users/TDH/AppData/Local/Programs/Python/Python310-32/python.exe d:/d_02_study/01_git/papers/system/02automation/demo.py
.....
----------------------------------------------------------------------
Ran 5 tests in 0.001sOK
PS D:\d_02_study\01_git\papers\system\02automation> TestFixture测试夹具
unittest的测试夹具有两种使用方式,一种是以测试用例的方法为维度的:setUp()和 tearDown();另一种是以测试类为维度的:setUpClass()和 tearDownClass()。
代码示例:
# users列表存储成功注册的用户
users = [{'username': 'testing', 'password': '123456'}] def register(username, password1, password2):if not all([username, password1, password2]):return {'code': 0, 'msg': '所有参数不能为空.'}# 注册for user in users:if username == user['username']:return {'code': 0, 'msg': '用户名已存在!'}else:if password1 != password2:return {'code': 0, 'msg': '两次密码输入不一致!'}else:if 6 <= len(username) <= 18 and 6 <= len(password1) <= 18:# 追加到users列表users.append({'username': username, 'password': password2})return {'code': 0, 'msg': '注册成功.'}else:return {'code': 0, 'msg': '用户名和密码的长度必须在6~18位之间.'}import unittest
from demo import register # 导入被测试代码class RegisterTest(unittest.TestCase):'''注册接口测试类'''@classmethod # 指明这是个类方法,以类为维度去执行的def setUpClass(cls) -> None:'''整个测试用例类中的用例执行之前,会先执行此方法'''print('-----setup---class-----')@classmethoddef tearDownClass(cls) -> None:'''整个测试用例类中的用例执行完成后,会执行此方法'''print('-----teardown---class-----')def setUp(self):'''每条测试用例执行前都会执行'''print('用例{}开始执行...'.format(self))def tearDown(self):'''每条测试用例执行结束后都会执行'''print('用例{}执行结束...'.format(self))def test_register_success(self):'''注册成功'''data = ('palien', 'palien', 'palien') # 测试数据result = register(*data) # 测试结果expected = {'code': 0, 'msg': '注册成功.'} # 预期结果self.assertEqual(result, expected) # 断言测试结果与预期结果一致# passdef test_username_exist(self):'''注册失败-用户名已存在'''data = ('testing', '123456', '123456')result = register(*data)expected = {'code': 0, 'msg': '用户名已存在!'}self.assertEqual(result, expected)def test_username_isnull(self):'''注册失败-用户名为空'''data = ('', 'palien', 'palien')result = register(*data)expected = {'code': 0, 'msg': '所有参数不能为空.'}self.assertEqual(result, expected)# passdef test_username_lt18(self):'''注册失败-用户名长度大于18位'''data = ('palienpalienpalienpalien', 'palien', 'palien')result = register(*data)expected = {'code': 0, 'msg': '用户名和密码的长度必须在6~18位之间.'}self.assertEqual(result, expected)# passdef test_password1_not_password2(self):'''注册失败-两次输入密码不一致'''data = ('palien', 'palien1', 'palien2')result = register(*data)expected = {'code': 0, 'msg': '两次密码输入不一致!'}self.assertEqual(result, expected)# pass# 如果要直接运行这个测试类,需要使用unittest中的main函数来执行测试用例
if __name__ == '__main__':unittest.main()### Output
PS D:\d_02_study\01_git> cd d:/d_02_study/01_git/papers/system/02automation
PS D:\d_02_study\01_git\papers\system\02automation> & C:/Users/TDH/AppData/Local/Programs/Python/Python310-32/python.exe d:/d_02_study/01_git/papers/system/02automation/demo.py
-----setup---class-----
用例test_password1_not_password2 (__main__.RegisterTest)开始执行...
用例test_password1_not_password2 (__main__.RegisterTest)执行结束...
.用例test_register_success (__main__.RegisterTest)开始执行...
用例test_register_success (__main__.RegisterTest)执行结束...
.用例test_username_exist (__main__.RegisterTest)开始执行...
用例test_username_exist (__main__.RegisterTest)执行结束...
.用例test_username_isnull (__main__.RegisterTest)开始执行...
用例test_username_isnull (__main__.RegisterTest)执行结束...
.用例test_username_lt18 (__main__.RegisterTest)开始执行...
用例test_username_lt18 (__main__.RegisterTest)执行结束...
.-----teardown---class---------------------------------------------------------------------------
Ran 5 tests in 0.004sOK
PS D:\d_02_study\01_git\papers\system\02automation> TestSuit测试套件
unittest.TestSuit()类用来表示一个测试用例集,把需要执行的用例类或模块集合在一起。
常用的方法:
unittest.TestSuit()
addTest():添加单个测试用例方法
addTest([...]):添加多个测试用例方法,方法名存在一个列表
unittest.TestLoader()
loadTestsFromTestCase(测试类名):添加一个测试类
loadTestsFromMdule(模块名):添加一个模块
discover(测试用例所在的目录):指定目录去加载,会自动寻找这个目录下所有符合命名规则的测试用例
代码示例:
'''以下三个文件必须在同一文件夹下:demo.pytest_demo.pyrun_test.py
'''import os
import unittest
import test_demo# 第一步,创建一个测试套件
suit = unittest.TestSuite()# 第二步,将测试用例加载到测试套件中# # 方式一,添加单条测试用例
# case = test_demo.RegisterTest('test_register_success')
# '''
# 创建一个用例对象。
# 注意:通过用例类去创建测试用例对象的时候,需要传入用例的方法名(字符串类型)
# 这里不是像调用普通类中的方法那样通过类名.方法名调用,可以理解为unittest框架的特殊之处
# '''
# suit.addTest(case) # 添加用例到测试套件中# # 方式二:添加多条用例
# case1 = test_demo.RegisterTest('test_username_exist')
# case2 = test_demo.RegisterTest('test_username_isnull')
# suit.addTest([case1, case2]) # 添加用例到测试套件中。注意这里使用的是suit.addTest()方法而不是suit.addTests()方法# # 方式三:添加一个测试用例集
# loader = unittest.TestLoader() # 创建一个加载对象
# suit.addTest(loader.loadFromTestCase(test_demo.RegisterTest)) # 通过加载对象从测试类中加载用例到测试套件中# '''
# 通产我们使用方式4、5比较多,可以根据实际情况来运用。
# 其中方式5还可以自定义匹配规则,默认是会寻找目录下的test*.py文件,即所有以test开头命名的py文件。
# '''
# # 方式四:添加一个模块(其实就是一个后缀名为.py文件,这里就是test_demo.py文件)
# loader = unittest.TestLoader() # 创建一个加载对象
# suit.addTest(loader.loadTestsFromModule(test_demo)) # 通过加载对象从模块中加载测试用例到测试套件中# 方式五:指定测试用例的所在目录路径,进行加载
loader = unittest.TestLoader() # 创建一个加载对象
case_path = os.path.dirname(os.path.abspath(__file__)) # 文件路径
# print('用例所在的目录路径为:', case_path)
# suit.addTest(loader.discover(case_path)) # 通过加载对象从用例所在目录加载测试用例到测试套件
suit.addTest(loader.discover(start_dir=case_path, pattern='test_demo*.py')) # 两个参数:路径和匹配规则TestRunner执行用例
testRunner用来执行用例,并且可以生成相应的测试报告。测试报告有两种形式:一种是 text文本;一种是 html格式。
html格式是 HTMLTestRunner插件辅助生成的,是Python标准库的unittest框架的一个拓展,可以生成一个清晰直观的html测试报告。使用的前提就是需要下载 HTMLTestRunner.py,下载完成后放在python安装目录下的scripts目录下即可。
text文本相对于html来说过于简陋,与输出控制台没有什么区别,也几乎不适用。
代码示例:
# demo.py,与test_demo.py和run_test.py在同一目录下# 导入模块
import unittest
import os
import test_demo
from HTMLTestReportCN import HTMLTestRunner# 用例文件所在目录
base_path = os.path.dirname(os.path.abspath(__file__))
# report_path = base_path + 'report.html'# 打开报告文件# 创建测试套件
suit = unittest.TestSuite()# 通过模块加载测试用例
loader = unittest.TestLoader()
suit.addTest(loader.discover(start_dir=base_path, pattern='test_demo*.py'))# 创建测试运行程序启动器
runner = HTMLTestRunner(stream=open('report.html', 'w', encoding='utf-8'), # 打开一个报告文件,并将句柄传给streamtester='palien', # 报告中显示的测试人员 description='注册接口测试报告', # 报告中显示的描述信息title='自动化测试报告' # 测试报告标题
)# 使用启动器去执行测试套件里面的测试用例
runner.run(suit)相关参数说明:
stream:指定输出方式
tester:报告中要显示的测试人员的名字
description:报告中要显示的描述信息
title:测试报告的标题
verbosity:表示测试报告信息的详细程度,一共三个值,默认为2
0(静默模式):只能获得总的测试用例书和总的结果,如:总共100个,失败90
1(默认模式):类似静默模式,只是在在每个成功的用例面前有个. 每个失败的用例前面有个F
2(详细模式):测试结果会显示每个测试用例的所有相关信息
运行完毕,在项目目录下面会生成一个report.html文件,在浏览器中打开,就可以看到测试报告了。
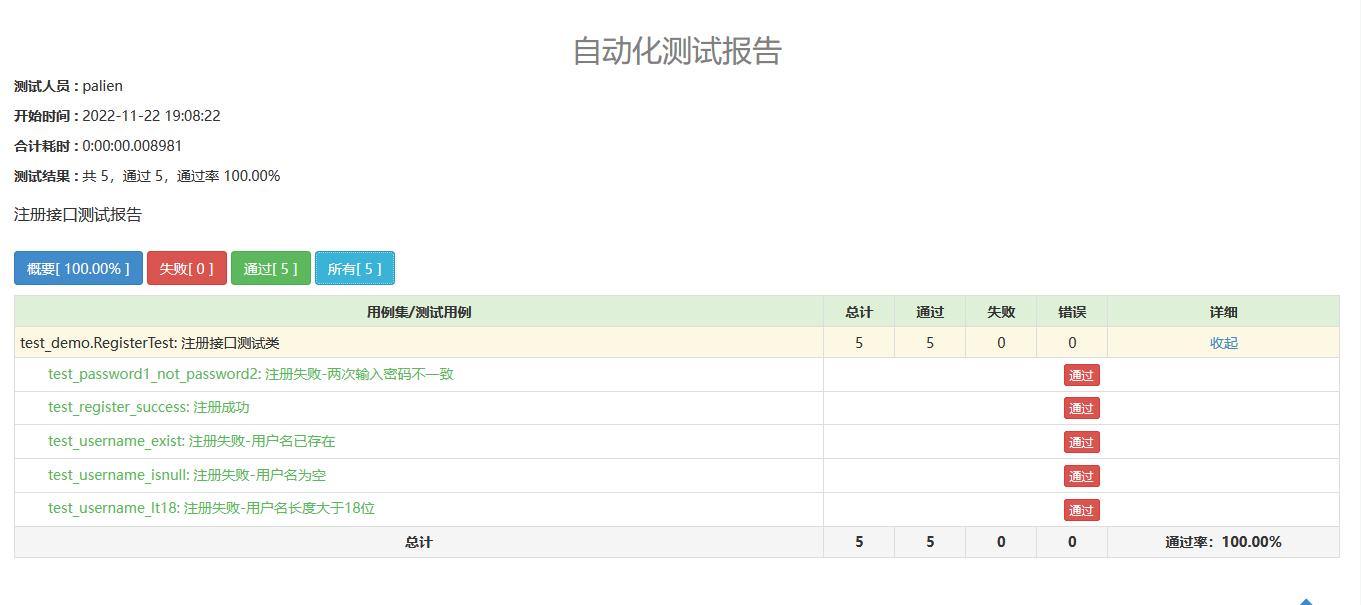
问题记录
在学习的过程中遇到了一些问题,记录一下。
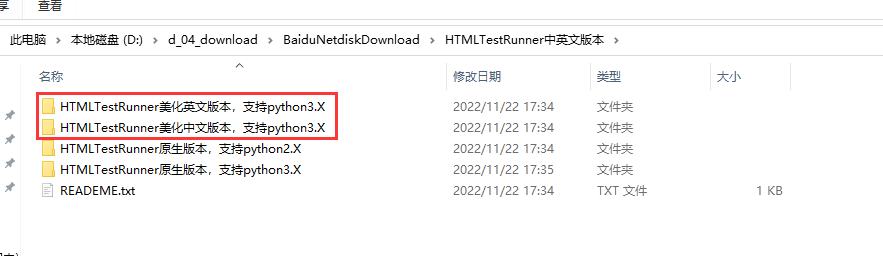
HTMLTestRunner下载
经验证,以下两个文件就支持生成上面截图的报告。
- 报错
TypeError: a bytes-like object is required, not 'str'解决
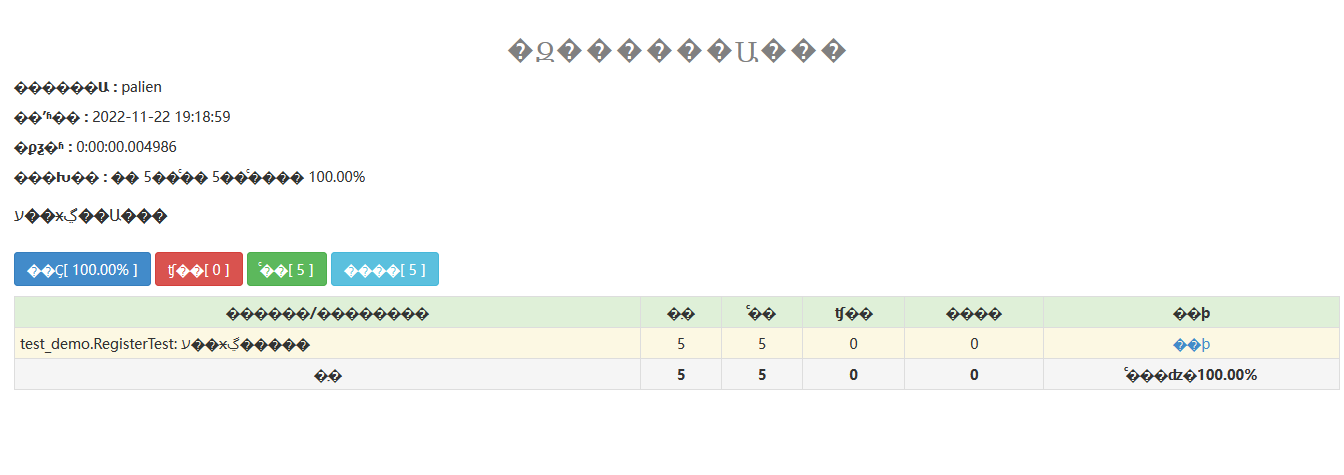
- 中文报告乱码问题
问题如图:
【2023最新】Python自动化测试,7天练完60个实战项目,全程干货。【自动化测试/接口测试/性能测试/软件测试】
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!