做网站第一步要学什么做花酒的网站
等值式(等值联结词)
1、设A、B是两个命题公式,若A、B构成的等价式 A等价于B
为重言式,那么称A与B是等值的
2、常用等值式:


注意:
1 双否定律
2 幂等律
3 交换律
4 结合律
5 吸收律
6 德摩根律
7 同一律
8 零律
9 矛盾律
10 排中律
11 蕴含表达式
12 等值表达式
13 **逆反律**(假言易位)
14 归谬律(反证法)
15 输出律(间接证明法:CP规则)
将蕴含前件作为前提条件去推出蕴含后件
析取范式与合取范式
1、文字:命题变元及其否定
2、短语:有限个文字的合取式
3、子句:有限个文字的析取式
注意:
一个文字既可以看作是一个短语也可以看作是一个子句
4、析取范式:有限个短语(合取式)的析取式
5、合取范式:有限个子句(析取式)的合取式
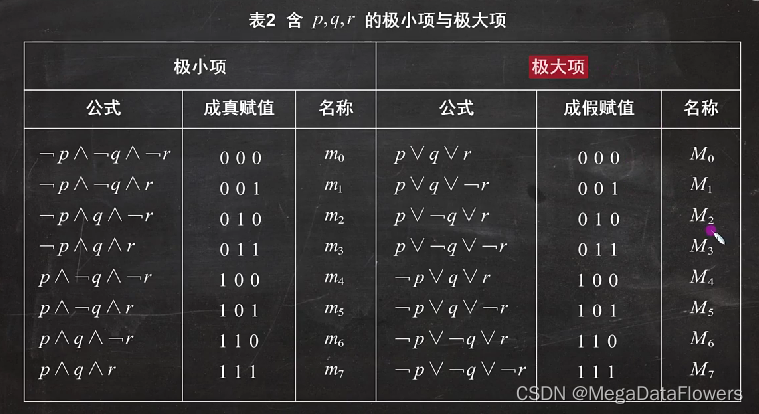
主析取范式与主合取范式
1、极小项(成真赋值):
1 是一个简单的**合取式**
2 每个命题变元和它的否定式恰好出现仅出现一次
3 命题变元或它的否定式按照下标从小到大排列
2、极大项(成假赋值):
1 是一个简单的**析取式**
2 每个命题变元和它的否定式恰好出现仅出现一次
3 命题变元或它的否定式按照下标从小到大排列

3、主析取范式:所有的合取式都是极小项的析取范式
4、主合取范式:所有的析取式都是极大项的合取范式
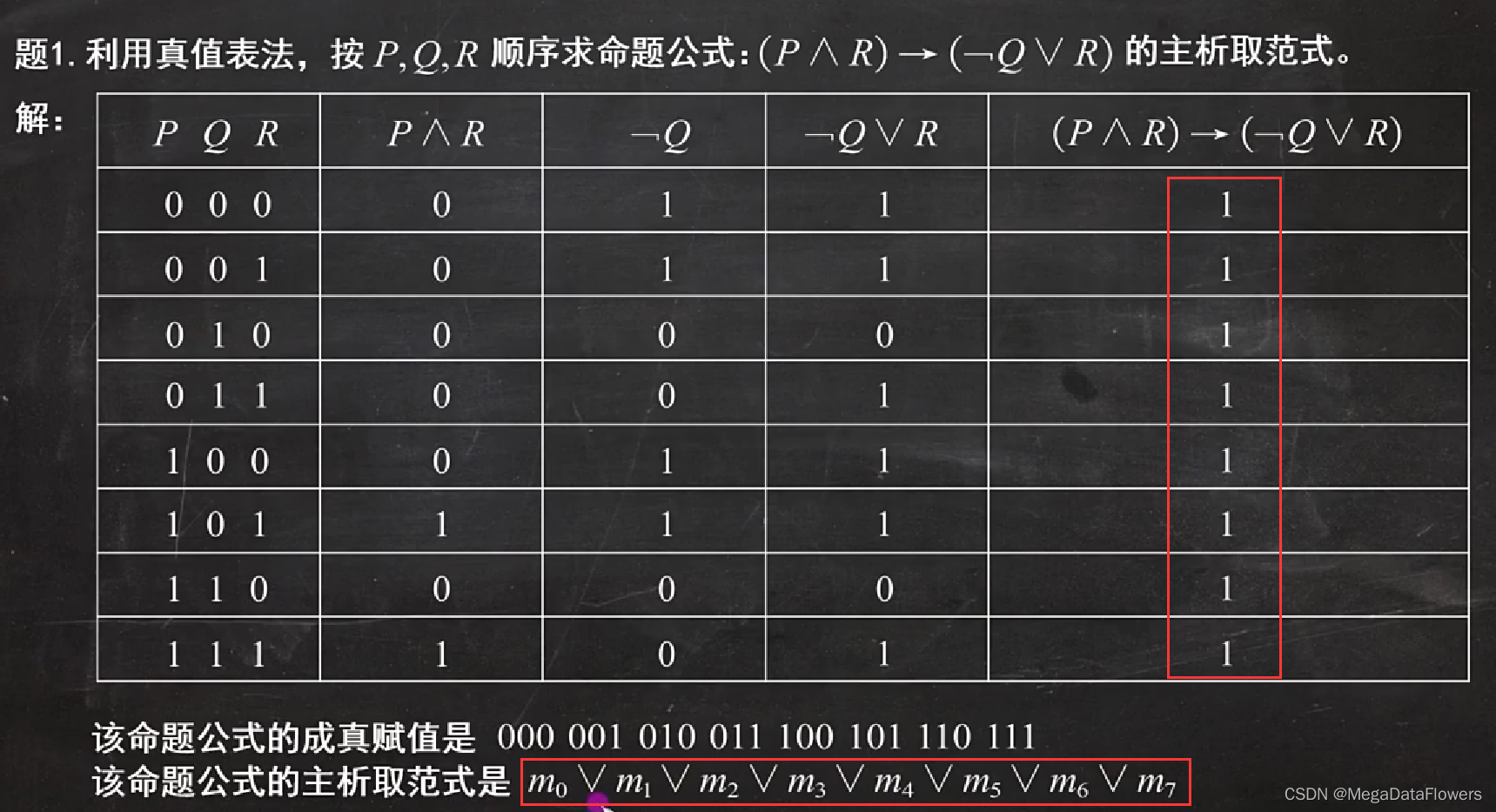
5、求主析取范式和主合取范式的方法:
1 真值表法
2 等值演算法