网站建设经验会议讲话稿鲜花网站建设规模设想
文章目录
1、什么是跨域
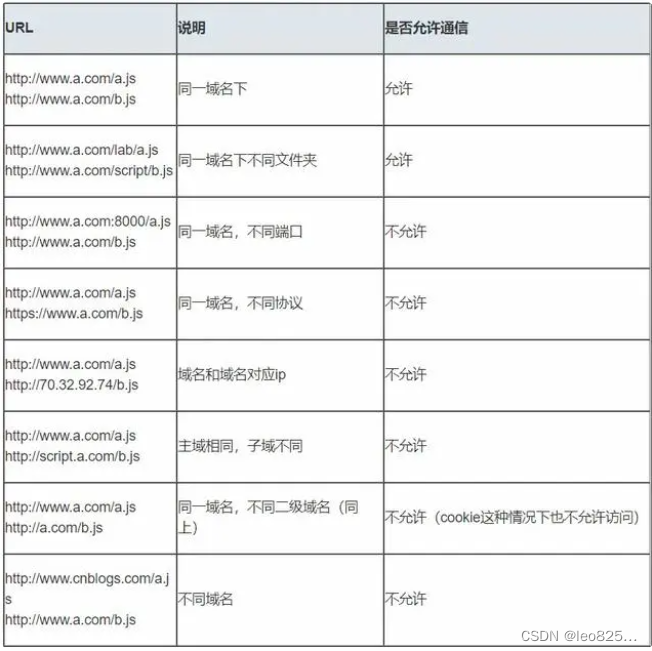
假如一个域名地址的为:http://www.a.com:8080/scripts/jquery.js
它的构成如下:
- 协议:http://
- 子域名:www
- 子域名:a.com
- 端口号:8080
- 请求资源地址:scripts/jquery.js
跨域根本原因是由同源策略引起的。所谓同源是指域名,协议,端口相同,当页面在执行一个脚本时会检查访问的资源是否同源,如果非同源,在请求数据的时候浏览器会在控制台报一个异常,提示拒绝访问。注意:跨域限制访问,其实是浏览器的限制。理解这一点很重要!!!
跨域访问的例子:
请求跨域了,那么请求到底发出去没有?
跨域并不是请求发不出去,请求能发出去,服务端能收到请求并正常返回结果,只是结果被浏览器拦截了。你可能会疑问明明通过表单的方式可以发起跨域请求,为什么 Ajax 就不会?因为归根结底,跨域是为了阻止用户读取到另一个域名下的内容,Ajax 可以获取响应,浏览器认为这不安全,所以拦截了响应。但是表单并不会获取新的内容,所以可以发起跨域请求。同时也说明了跨域并不能完全阻止 CSRF,因为请求毕竟是发出去了。
2、解决跨域的几种方案
互联网上存在很多解决跨域的方式,如下图所示:
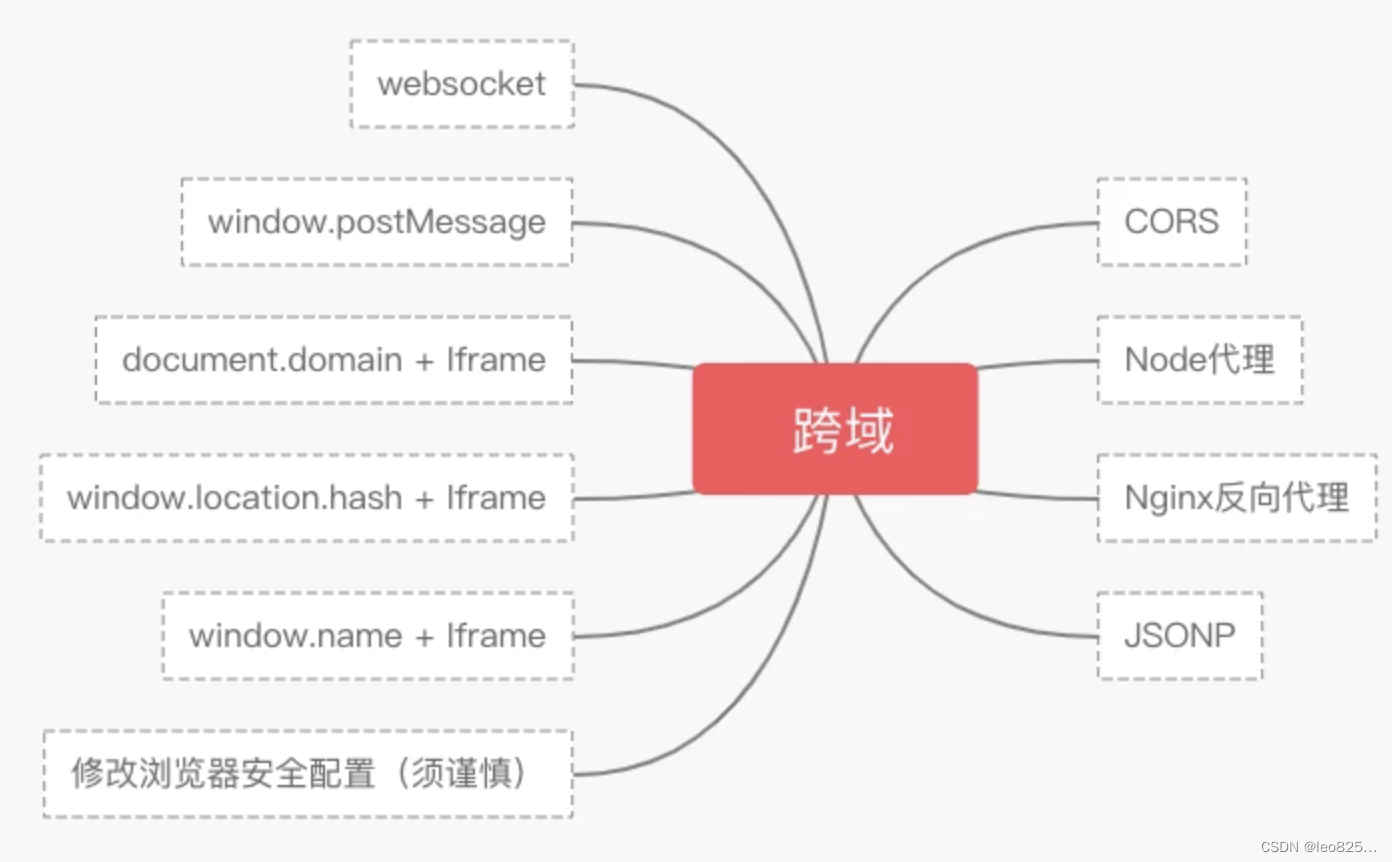
以下介绍几种常见的解决跨域的办法,其他想了解的可以自行在网上查阅。
2.1、JSONP 方式解决跨域
Jsonp 包含两部分:回调函数和数据。
回调函数是当响应到来时要放在当前页面被调用的函数。
数据就是传入回调函数中的 json 数据,也就是回调函数的参数了。
function handleResponse(response){console.log('The responsed data is: '+response.data);
}
var script = document.createElement('script');
script.src = 'http://www.baidu.com/json/?callback=handleResponse';
document.body.insertBefore(script, document.body.firstChild);
/*handleResonse({"data": "zhe"})*/
//原理如下:
//当我们通过script标签请求时
//后台就会根据相应的参数(json,handleResponse)
//来生成相应的json数据(handleResponse({"data": "zhe"}))
//最后这个返回的json数据(代码)就会被放在当前js文件中被执行
//至此跨域通信完成
缺点:
1)安全问题(请求代码中可能存在安全隐患)
2)要确定 jsonp 请求是否失败并不容易
2.2、CORS 方式解决跨域(常见,通常仅需服务端修改即可)
CORS 全称是"跨域资源共享"(Cross-origin resource sharing)。CORS需要浏览器和服务器同时支持,但是目前基本上浏览器都支持,所以我们只要保证服务器端服务器实现了 CORS 接口,就可以跨域通信。
实现方式:在数据包的头部配置 Access-Control-Allow-Origin 字段以后,数据包发送给浏览器后,浏览器就会根据这里配置的白名单 “放行” 允许白名单的服务器对应的网页来用 ajax 跨域访问 。
CORS 解决跨域问题,就是在服务器端给响应添加头信息:
Access-Control-Allow-Origin 允许请求的域
Access-Control-Allow-Methods 允许请求的方法
Access-Control-Allow-Headers 预检请求后,告知发送请求需要有的头部
Access-Control-Allow-Credentials 表示是否允许发送cookie,默认false;
Access-Control-Max-Age 本次预检的有效期,单位:秒;
以下以 java 语言为例,服务端 Filter 的设置如下:
// 接收客户端发送的 origin (重要)
// res.setHeader("Access-Control-Allow-Origin", "*") // * 代表允许所有的地址跨域访问
// 如果是白名单,可以定义跨域访问白名单
// String[] authOrigin = {'http://127.0.0.1:5500'}
// if(authOrigin.includes(origin)) {
// // 只有白名单中的地址才可以跨域访问
// res.setHeader('Access-Control-Allow-Origin', origin)
// }
res.setHeader("Access-Control-Allow-Origin", origin)
//服务器支持的所有跨域请求的方法
res.setHeader("Access-Control-Allow-Methods", "POST, GET, OPTIONS, PUT, DELETE,UPDATE")
//允许跨域设置可以返回其他子段,可以自定义字段
res.setHeader("Access-Control-Allow-Headers", "Authorization, Content-Length, X-CSRF-Token, Token,session")
// 允许浏览器(客户端)可以解析的头部 (重要)
res.setHeader("Access-Control-Expose-Headers", "Content-Length, Access-Control-Allow-Origin, Access-Control-Allow-Headers")
//设置缓存时间
res.setHeader("Access-Control-Max-Age", "172800")
//允许客户端传递校验信息比如 cookie (重要)
res.setHeader("Access-Control-Allow-Credentials", "true")
其他请参考:CORS 官网
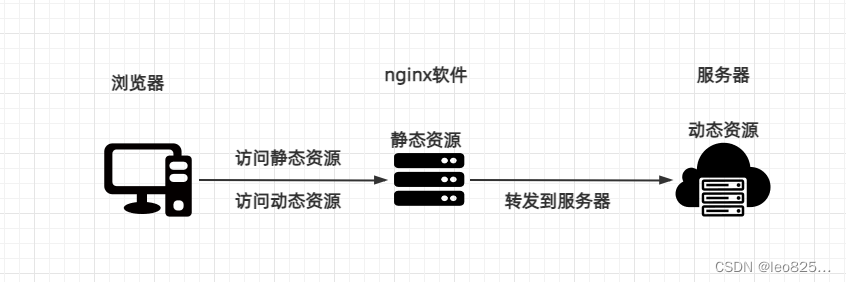
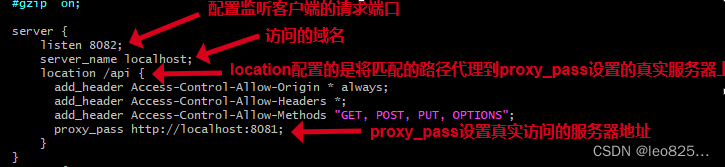
2.3、Nginx 反向代理解决跨域(推荐使用,配置简单)
原理:因为跨域是浏览器限制的,服务器请求服务器不受浏览器同源策略限制。
2.4、WebSocket 解决跨域
WebSocket 是一种浏览器的API,它的目标是在一个单独的持久连接上提供全双工、双向通信。(同源策略对 WebSocket 不适用)
原理:在 JS 创建了 WebSocket 之后,会有一个 HTTP 请求发送到浏览器以发起连接。取得服务器响应后,建立的连接会使用 HTTP 升级从 HTTP 协议交换为 WebSocket 协议。
var socket = new WebSockt('ws://www.baidu.com');//http->ws; https->wss
socket.send('hello WebSockt');
socket.onmessage = function(event){var data = event.data;
}
缺点:
只能在支持 WebSocket 协议的服务器上才能正常工作。
2.5、PostMessage方式解决跨域(HTML5中的XMLHttpRequest Level 2中的API)
- http://a.com/index.html中的代码:
<iframe id="ifr" src="b.com/index.html"></iframe>
<script type="text/javascript">
window.onload = function() {var ifr = document.getElementById('ifr');var targetOrigin = 'http://b.com'; // 若写成'http://b.com/c/proxy.html'效果一样// 若写成'http://c.com'就不会执行postMessage了ifr.contentWindow.postMessage('I was there!', targetOrigin);
};
</script>
- http://b.com/index.html中的代码:
<script type="text/javascript">window.addEventListener('message', function(event){// 通过origin属性判断消息来源地址if (event.origin == 'http://a.com') {alert(event.data); // 弹出"I was there!"alert(event.source); // 对a.com、index.html中window对象的引用// 但由于同源策略,这里event.source不可以访问window对象}}, false);
</script>