网站平台建设实训内容合肥网络公司哪个最好
webpack基础
- 前言
- 什么是webpack
- webpack的基本使用
- 指定webpack的entry和output
前言
- 本篇开始来学习下webpack的使用
什么是webpack
-
webpack: 是前端项目工程化的具体解决方案。
-
主要功能:它提供了友好的前端模块化开发支持,以及代码压缩混淆、处理浏览器端 JavaScript 的兼容性、性能优化等强大的功能。
-
好处:让程序员把工作的重心放到具体功能的实现上,提高了前端开发效率和项目的可维护性
webpack的基本使用
-
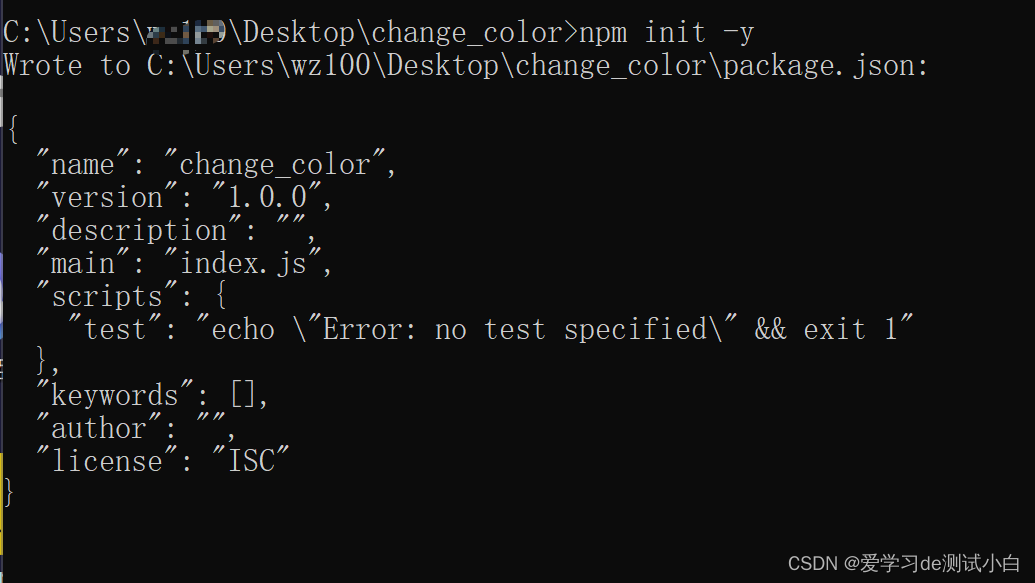
新建项目空白目录(change_coloe),并运行 npm init –y 命令,初始化包管理配置文件 package.json
-
新建 src 源代码目录
-
新建 src -> index.html 首页和 src -> index.js 脚本文件
-
初始化首页基本的结构
说明:
1. 快捷生成html基本结构: ! + tab (英文输入法下)
2. 快速生成9个li 标签 :ul>li{这是第$个}*9
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>修改行颜色</title>
</head>
<body><ul><li>这是第1个</li><li>这是第2个</li><li>这是第3个</li><li>这是第4个</li><li>这是第5个</li><li>这是第6个</li><li>这是第7个</li><li>这是第8个</li><li>这是第9个</li></ul>
</body>
</html>
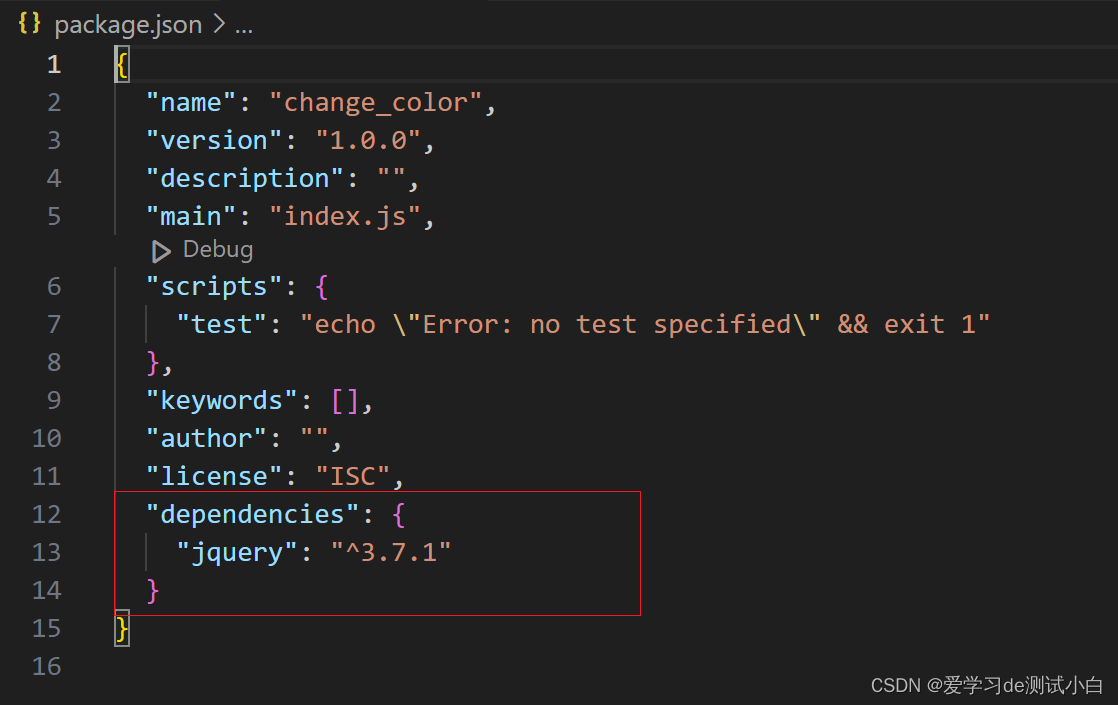
- 运行 npm install jquery –S 命令,安装 jQuery
说明:
- -S 是 --save简写 ,作用明确包的位置在dependencies中,可省略

- 通过 ES6 模块化的方式导入 jQuery,实现列表隔行变色效果
// index.js文件中
// 1. ES6语法导入jqueryimport $ from 'jquery'// 2. 定义 jQuery 的入口函数
$(function () {// 3. 实现奇偶行变色// 奇数行为红色 偶数行粉色~$('li:odd').css('background-color', 'red')$('li:even').css('background-color', 'pink')})- 在项目中安装 webpack
说明:
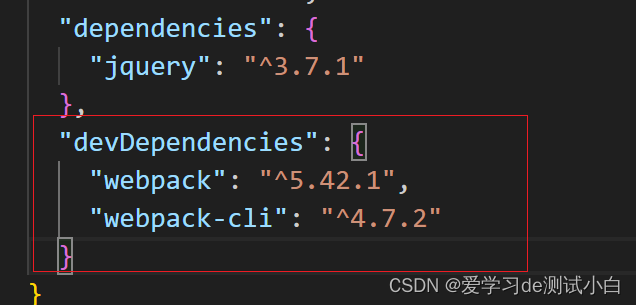
- -D 是 --save-dev 的简写,明确包位置在devDependencies中,
- dependencies 是开发和上线都会用到的包;devDependencies是开发阶段使用到的包
npm install webpack@5.42.1 webpack-cli@4.7.2 -D
- 在项目中配置webpack文件
- 在项目根目录中,创建名为 webpack.config.js 的 webpack 配置文件,并初始化如下的基本配置
module.exports = {// mode 代表 webpack 运行的模式,可选值有两个 development 和 production// 结论:开发时候一定要用 development,因为追求的是打包的速度,而不是体积;// 反过来,发布上线的时候一定能要用 production,因为上线追求的是体积小,而不是打包速度快!mode: 'development', }- 在 package.json 的 scripts 节点下,新增 dev 脚本如下
"scripts": {"dev": "webpack" // 可以通过npm run 运行,如 npn run dev}- 在项目目录下执行 npm run dev 命令,启动 webpack 进行项目的打包构建
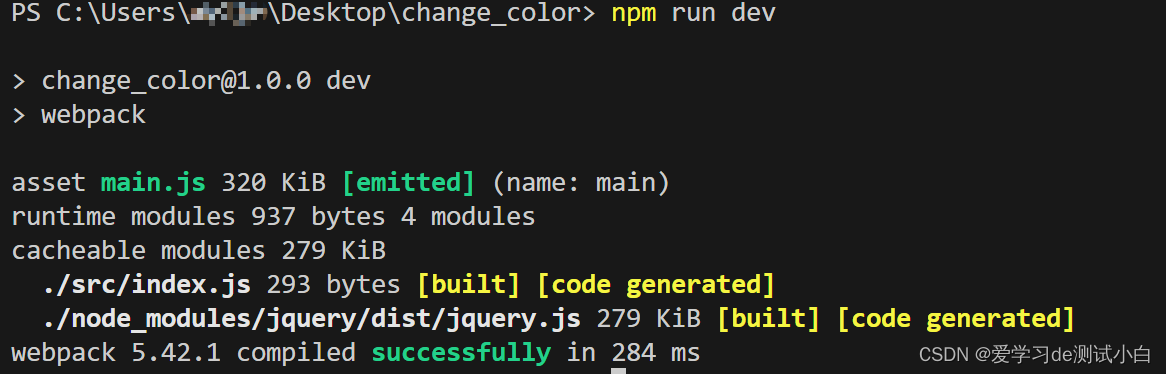
- 说明:webpack.config.js 作用:是 webpack 的配置文件。webpack 在真正开始打包构建之前,会先读取这个配置文件,
从而基于给定的配置,对项目进行打包
- 在index.html中导入打包生成的main.js
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>修改行颜色</title><script src="../dist/main.js"></script>
</head>
<body><ul><li>这是第1个</li><li>这是第2个</li><li>这是第3个</li><li>这是第4个</li><li>这是第5个</li><li>这是第6个</li><li>这是第7个</li><li>这是第8个</li><li>这是第9个</li></ul>
</body>
</html>
效果如下图

指定webpack的entry和output
在 webpack 4.x 和 5.x 的版本中,有如下的默认约定:
- 默认的打包入口文件为 src -> index.js
- 默认的输出文件路径为 dist -> main.js
- 在 webpack.config.js 配置文件中,通过 entry 节点指定打包的入口。通过 output 节点指定打包的出口
const path = require('path')module.exports = {mode: 'development',// entry: '指定要处理哪个文件' __dirname当前文件目录entry: path.join(__dirname, './src/index1.js'),// 指定生成的文件要存放到哪里output: {// 存放的目录path: path.join(__dirname, 'dist'),// 生成的文件名filename: 'bundle.js'}
}