手机和电脑网站分开做建立网站程序
个人主页:点我进入主页
专栏分类:C语言初阶 C语言程序设计————KTV C语言小游戏 C语言进阶
C语言刷题
欢迎大家点赞,评论,收藏。
一起努力,一起奔赴大厂。
目录
1.前言
2.指针题写出下列程序的结果
2.1
2.2
2.3
2.4
2.5
1.前言
在上一篇文章中我给大家讲解了关于指针和数组的笔试题,它主要就是sizeof(数组名),其中数组名是整个数组。&数组名加减整数其中&数组名是整个数组的地址,。即使在sizeof()中也是整个数组的地址对于二维数组,我们可以将二维数组看成一维数组的数组,例如arr[3][4],二维数组的数组名为arr,一维数组的数组名为arr[3],&arr ,arr都是二维数组的地址,但是在sizeof中arr加整数表示第几行的地址,arr[整数] &arr[整数]都表示第几行的地址。详细的可以点击指针和数组详解
2.指针题写出下列程序的结果
2.1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}我们看数组a是整形的有五个元素,我们对a进行取地址操作然后加1,其中取地址数组名得到的是数组的地址,加1是跳过一个数组,我们可以画成
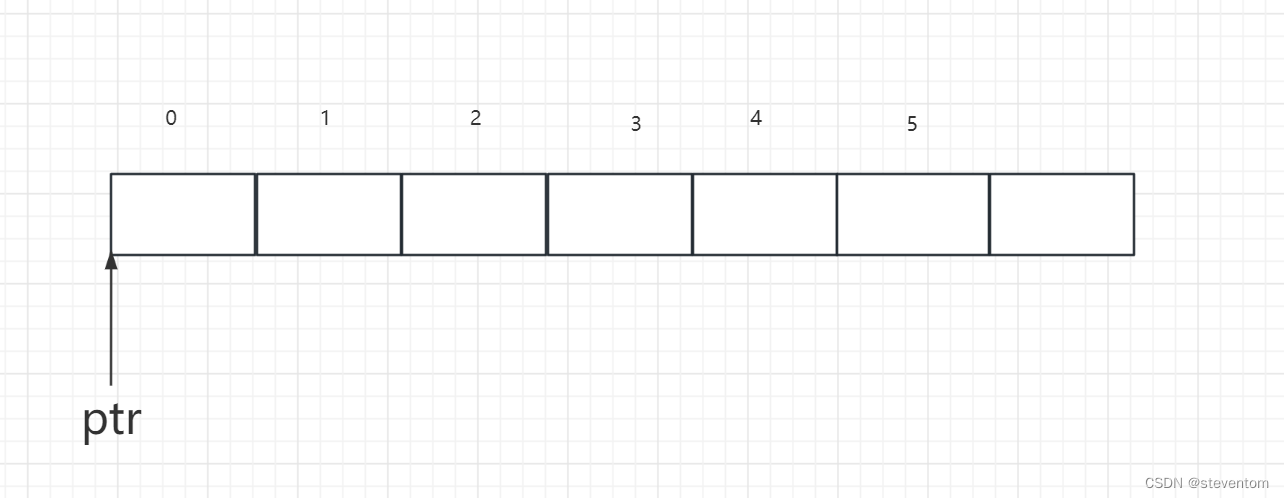
我们可以理解为ptr最开始指向数组的首元素,取地址数组名加1跳过一个数组得到
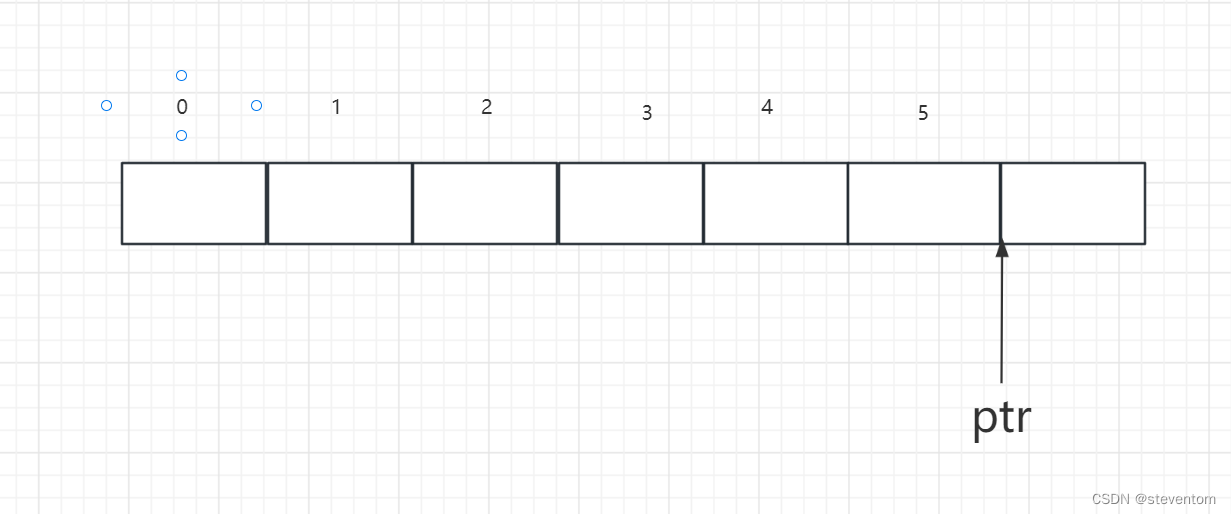
它指向了数组对后一个元素的后一个地址,我们看故*(ptr-1)就是将ptr前移一个元素,也就是5,*(a+1)中数组名没有单独存在,故是首元素的地址加1得到第二个元素的地址,解引用为第二个元素为2.
2.2
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
我们先看0X1是十六进制的数据是1,指针p值为0x100000加1是跳过一个元素故跳过20个字节得到0x100014,我们将指针p强制转化为unsigned long类型,加1就是单纯的加1得到0x100001,将p强制转化为unsigned int*类型也就是相当于p指向一个整形的元素,加1跳过4个字节得到0x100004。在这道题中我们需要对数据的类型掌握的很熟练。
2.3
int main()
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);
return 0;
}首先对于ptr1指针他和第一题一样都是得到数组的地址加1跳过一个数组 ,对于ptr1[-1]相当于ptr-1也就是指针向前移动4个字节指向数组的最后一个元素得到0x4,对于ptr2指针我们先看(int)a+1,我们将a强制转化为整形然后加1,也就是数组将数组的首地址转化为整形然后加1,具体我们将初始状态画为
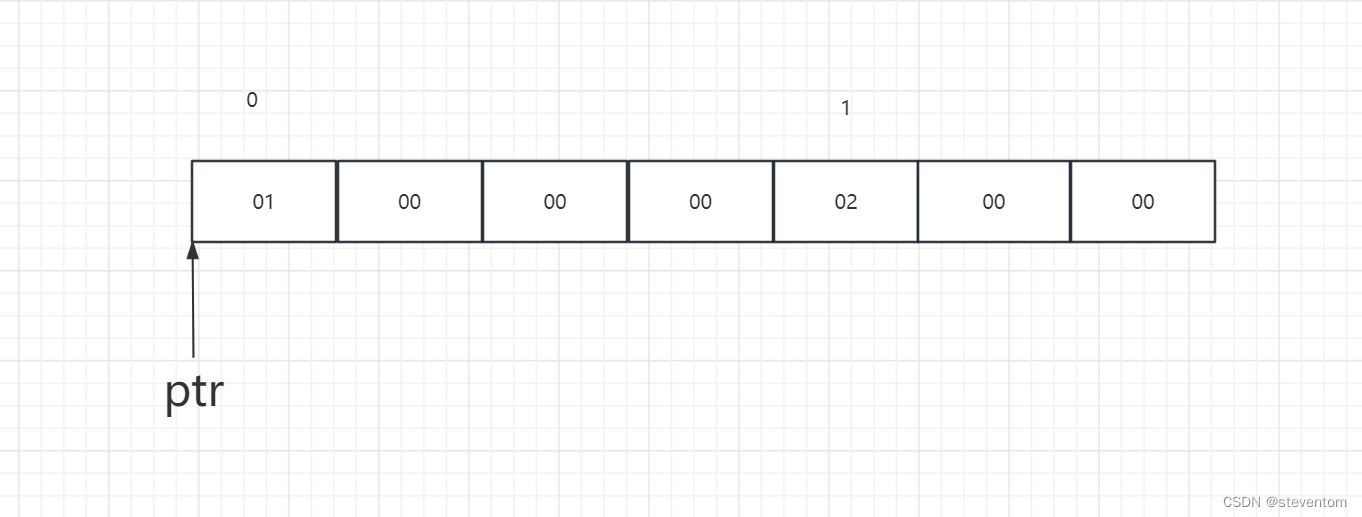
强制转化为整形让后加1在强制转化为int*为
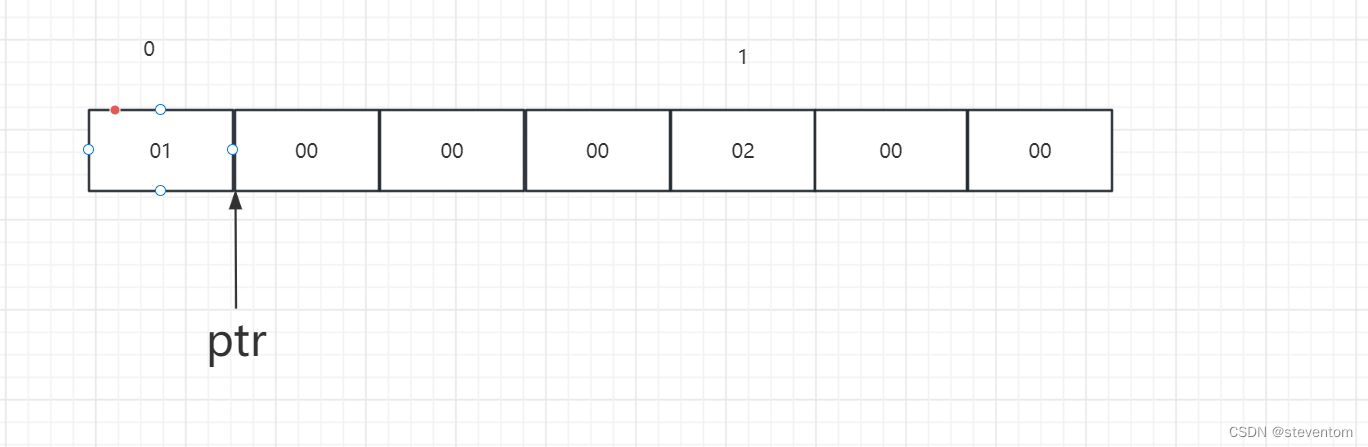
由于打印时会访问4个字节也就是
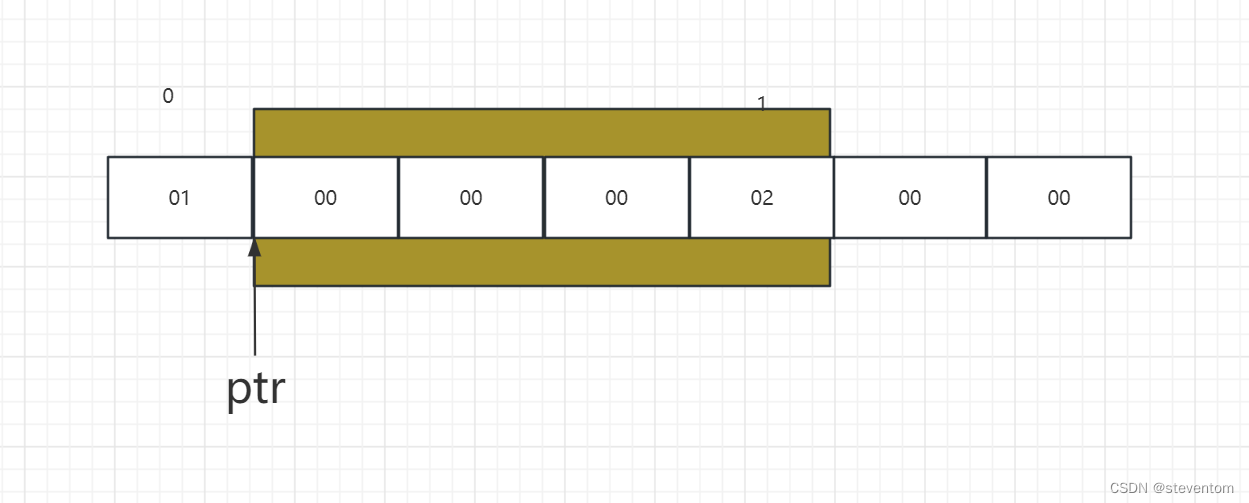
故得到0x2。
2.4
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}这道题非常的有意思,需要我们对数组有很深的认识,仔细看,它是逗号进行运算吗,看似6个元素其实是三个元素,分别为1,3,5;这是一个二维数组,p=a[0],其中a[0]是第一行的地址,对于p[0],相当于a[0][0],也就是1.
2.5
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}我们可以进行画图为
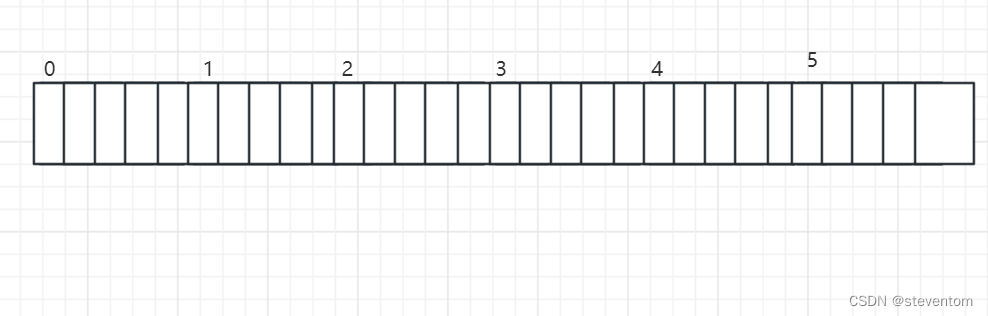
对于int(*p)[4]是一个数组指针,每个指针含义4个元素,想要将p指向二维数组虽然二维数组每行是占5个元素,我们 也是可以将它放进去对于&a[4][2],具体可以画为
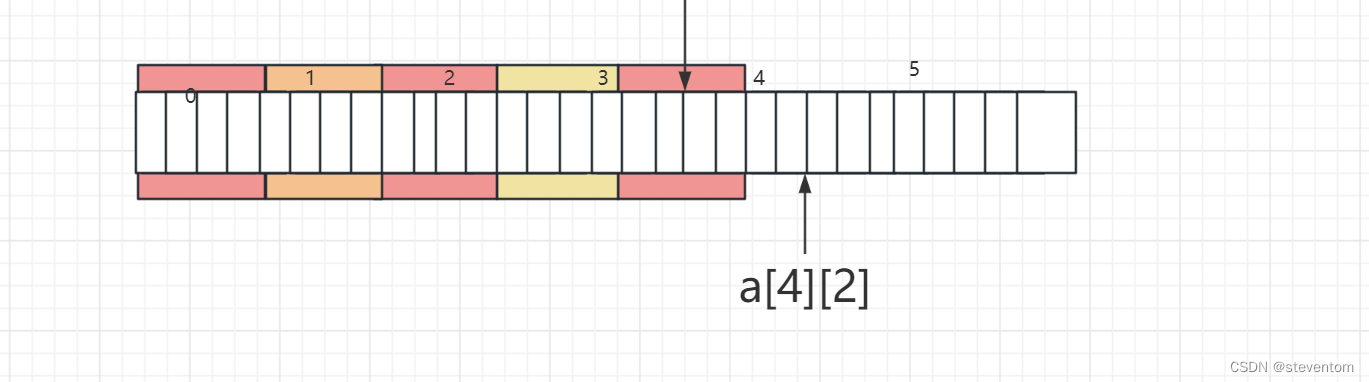
地址进行相减为-4,%p对应的为FFFF FFFF FFFF FFFC。
到这里今天的内容就结束了,希望大家可以学到很多东西,最好别忘了一键三连呦.