公司自建网站佛山新网站建设代理商
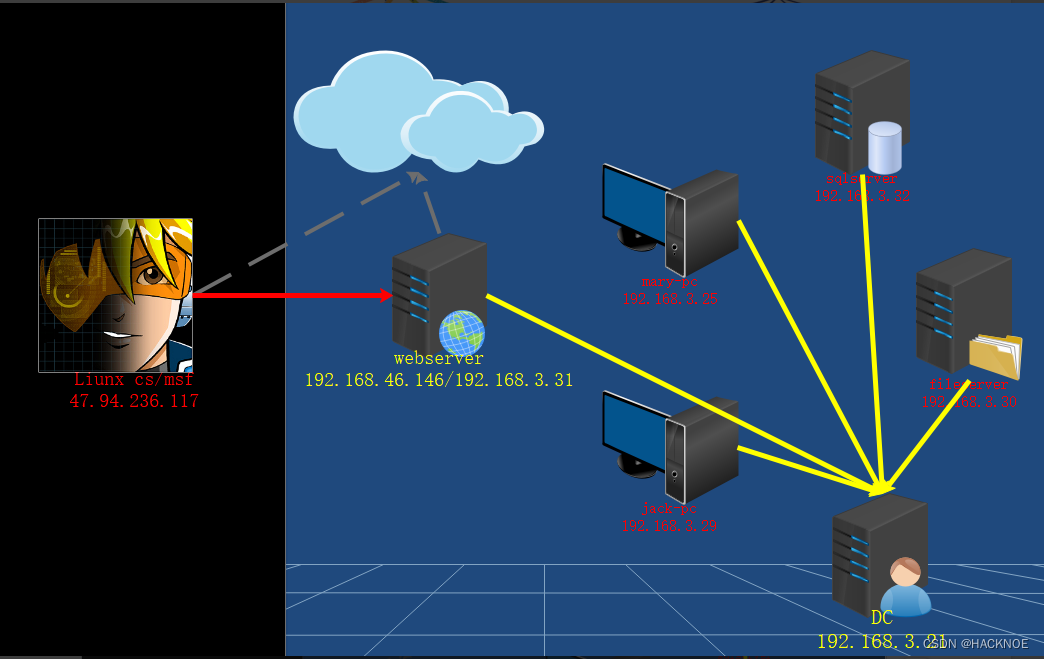
红队内网攻防渗透
- 1. 内网横向移动
- 1.1 委派安全知识点
- 1.1.1 域委派分类
- 1.1.2 非约束委派
- 1.1.2.1 利用场景
- 1.1.2.2 复现配置:
- 1.1.2.3 利用思路1:诱使域管理员访问机器
- 1.1.2.3.1 利用过程:主动通讯
- 1.1.2.3.2 利用过程:钓鱼
- 1.1.2.4 利用思路2:强制结合打印机漏洞
- 1.1.2.5 利用思路3:结合PetitPotam
- 1.1.3 约束委派
- 1.1.3.1 原理
- 1.1.3.2 利用场景
- 1.1.3.3 复现配置
- 1.1.3.4 利用思路:使用机器账户票据
1. 内网横向移动
1、横向移动篇-凭据传递攻击-PTH&PTT&PTK
2、横向移动篇-Kerberoast-四个票据攻击点
1.1 委派安全知识点
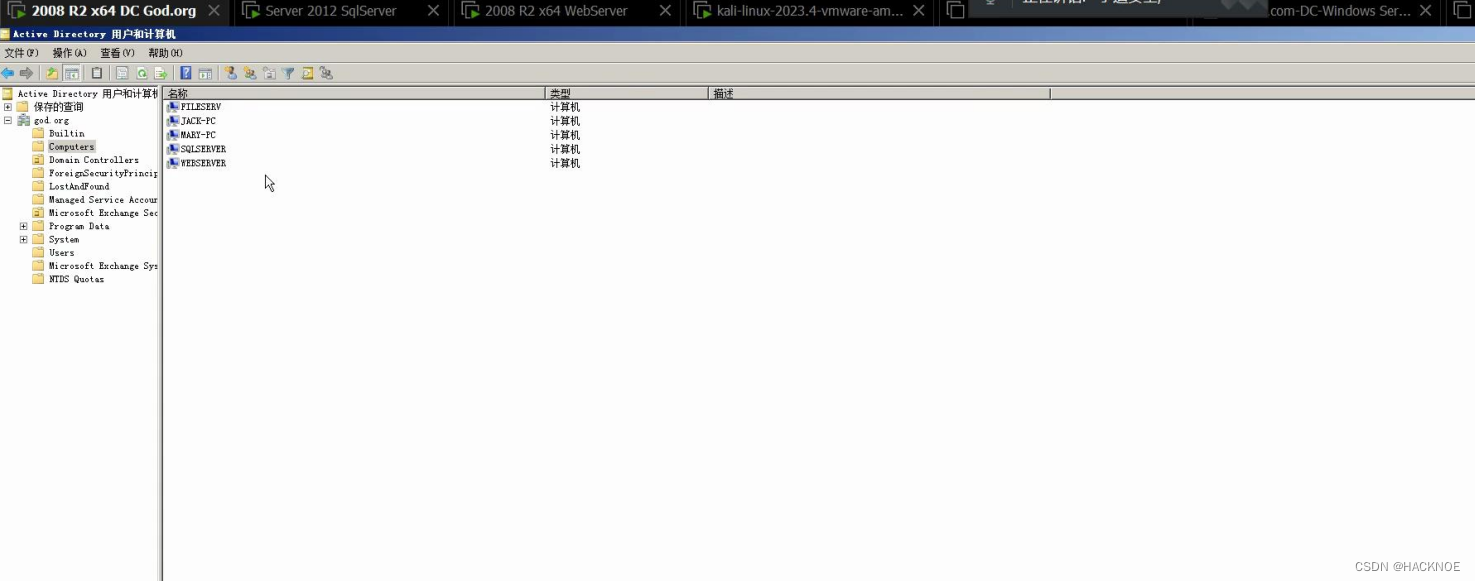
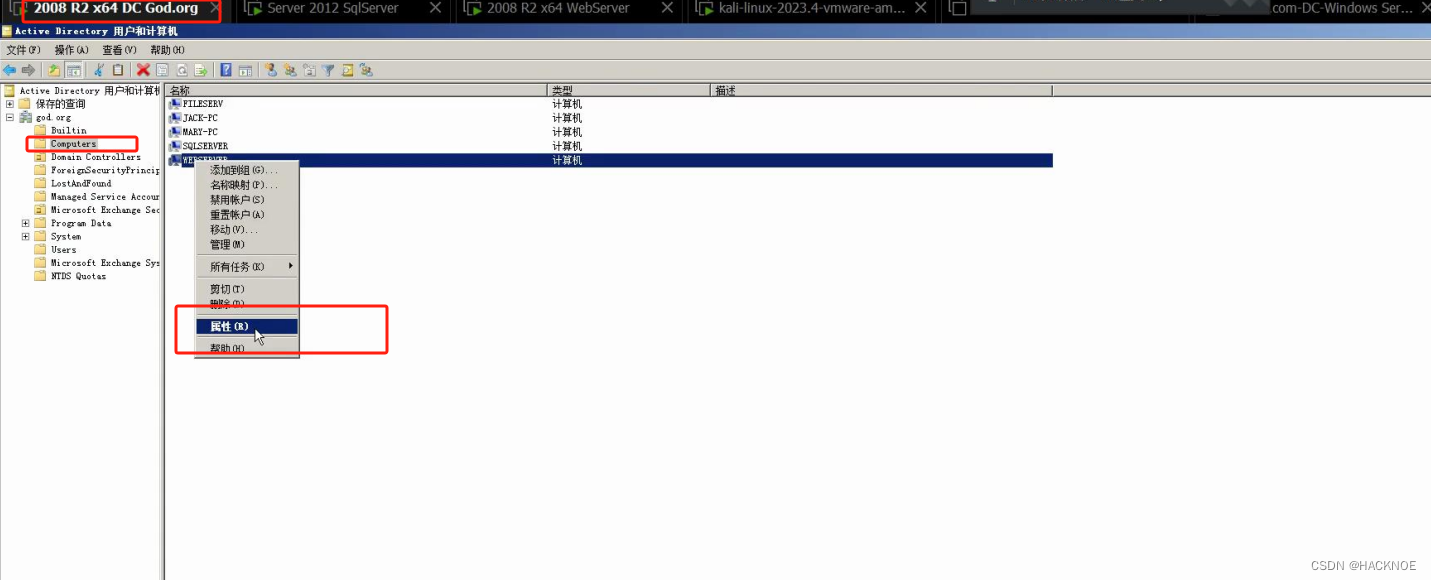
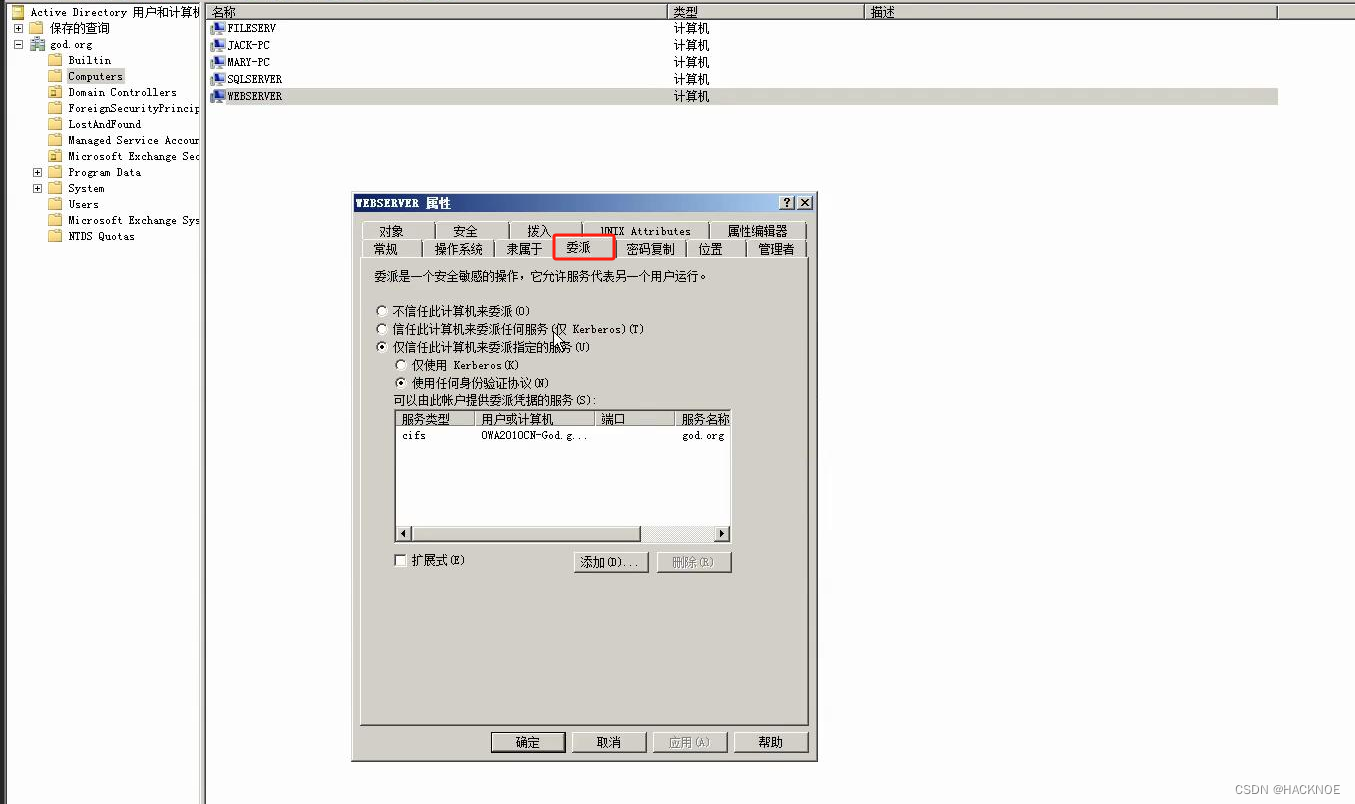
委派是一种域内应用模式,是指将域内用户账户的权限委派给服务账号,服务账号因此能以用户的身份在域内展开活动(请求新的服务等),类似于租房中介房东的关系去理解。
这是机器用户的委派