江苏和住房建设厅网站做外贸网站特色
原文网址:2023在Ubuntu安装最新版QQ Linux v3.1.0 - 哔哩哔哩
作者:sprlightning https://www.bilibili.com/read/cv22100663/ 出处:bilibili
2022年末QQ推出了QQ Linux v3.0系列,目前最新版是今年2月24日推出的v3.1.0版本。注意网址是{https://im.qq.com/linuxqq/index.shtml}。如果在百度搜索QQ Linux,那得到的是2.x的老版,v3.x新版本可以通过“QQ Linux新版”来搜出来。
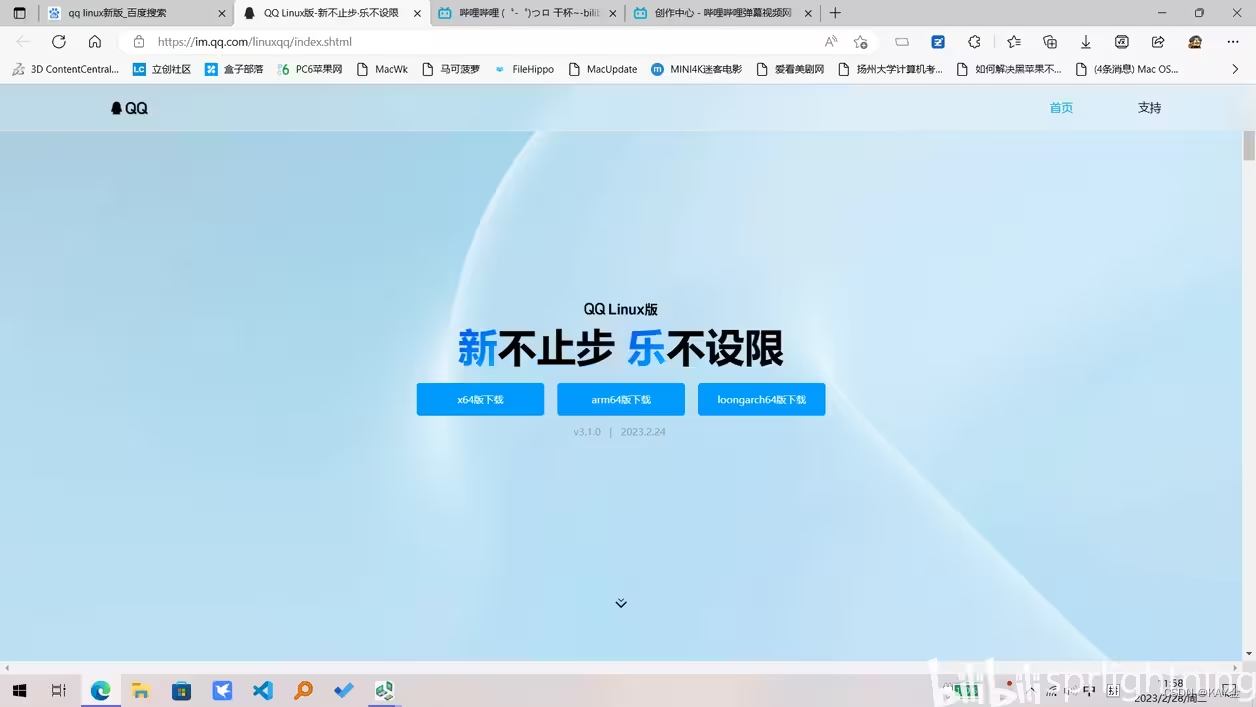
选x86的deb格式。
下载好后不要双击打开,因为安装不了。需要去终端安装,终端切换到下载目录,输入{sudo dpkg -i linuxqq...}即可安装,省略号那里用tab补全。
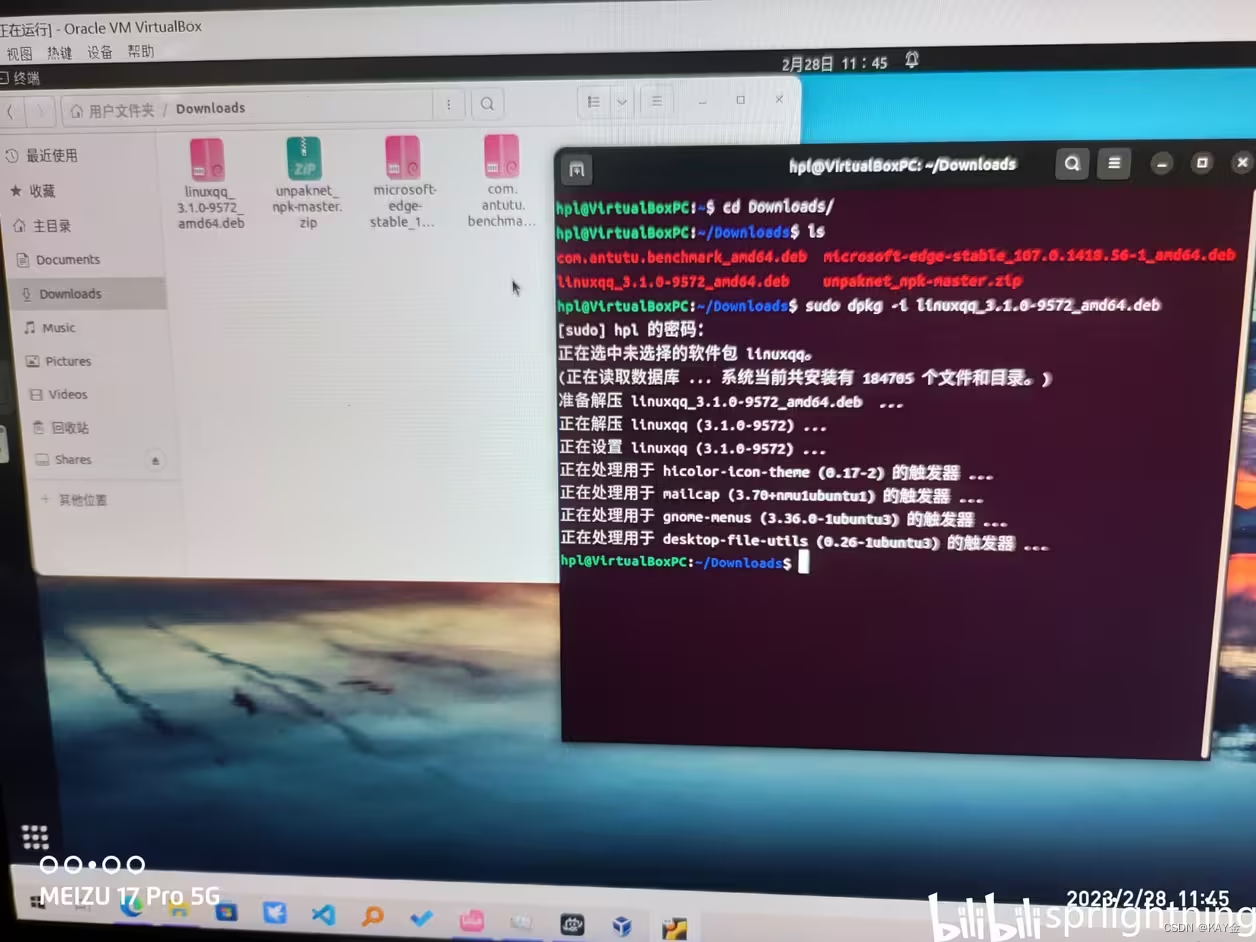
安装好后,点开启动菜单,就可看见QQ了,正常打开,扫码登陆即可,和PC版操作一样。