甘肃网站建设公司产品图案设计网站

这一节的内容在WMCore中,回想我们的场景,是在Launcher启动某一个App,那么参与动画的就是该App对应Task(OPEN),以及Launcher App对应的Task(TO_BACK)。在确定了动画的参与者后,接下来我们就需要等待动画参与者绘制完成。一个基本的逻辑是,参与动画的主体要绘制出来了才能开始动画,不然动画都开始执行了,窗口还没有绘制出来,那对于用户来说屏幕上是没有任何变化的,这不就有点尴尬了。
ShellTransitions之前,检查动画是否可以开始的逻辑是在AppTransitionController.handleAppTransitionReady中,通过调用transitionGoodToGo来检查窗口是否绘制完成的,现在则是在BLASTSyncEngine.onSurfacePlacement中,通过调用BLASTSyncEngine.SyncGroup.tryFinish不断检查所有动画参与者是否已经全部同步完毕。一旦所有的动画参与者完成同步,则视为SyncGroup完成,或者说Transition就绪,就会调用BLASTSyncEngine.SyncGroup.finishNow,最终走到Transition.onTransactionReady,具体的调用堆栈为:
RootWindowContainer.performSurfacePlacementNoTrace
-> BLASTSyncEngine.onSurfacePlacement
-> BLASTSyncEngine.SyncGroup.tryFinish
-> BLASTSyncEngine.SyncGroup.finishNow
-> Transition.onTransactionReady
我们这一节先分析检查SyncGroup是否完成(BLASTSyncEngine.SyncGroup.tryFinish)以及SyncGroup完成(BLASTSyncEngine.SyncGroup.finishNow)的内容,Transition就绪的内容即Transition.onTransactionReady放到单独一章分析。
1 BLASTSyncEngine.onSurfacePlacement
BLASTSyncEngine.onSurfacePlacement由RootWindowContainer.performSurfacePlacementNoTrace调用,代码为:
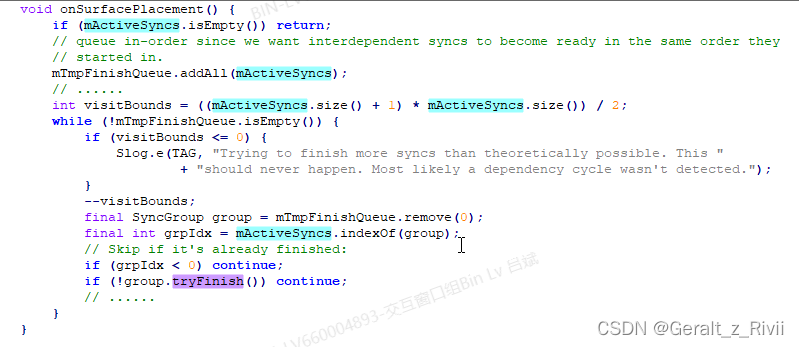
BLASTSyncEngine的成员变量mActiveSyncs之前已经介绍过了,当我们创建Transition的时候,也会创建一个SyncGroup,来收集参与动画的WindowContainer,创建的SyncGroup则保存在了BLASTSyncEngine.mActiveSyncs。
这里则是从BLASTSyncEngine.mActiveSyncs中拿出SyncGroup,调用SyncGroup.tryFinish来检查SyncGroup是否完成。
2 SyncGroup.tryFinish
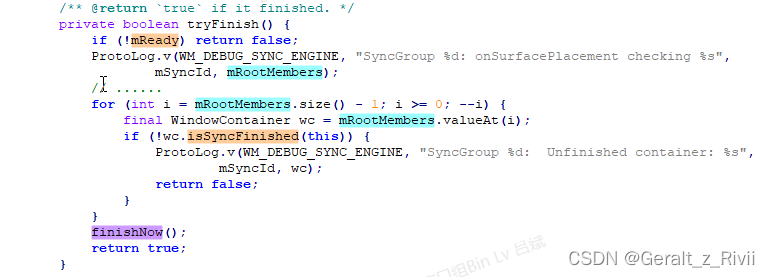
1)、如果SyncGroup.mReady为false,则直接返回。之前我们分析Transition的启动流程时,知道了只有当WMShell侧创建了一个ActiveTransition后切换回WMCore并且调用Transition.start,Transition才算正式启动,正是在Transition.start中,调用了SyncGroup.setReady方法将SyncGroup的mReady设置为了true。从这里我们就看到了SyncGroup.mReady的作用,如果Transition没有启动,那么这里是不会去检查其对应的SyncGroup是否完成了的,而是直接返回false,也就是说如果SyncGroup没有ready,那么Transition将无法走到下一个阶段。
2)、SyncGroup.mRootMembers则保存了参与动画的WindowContainer,我们这里则是为每一个WindowContainer调用WindowContainer.isSyncFinished来检查这个WindowContainer是否完成同步/绘制,只要有一个没有完成同步,那么就直接返回false,不需要往下走了,等待下一次RootWindowContainer.performSurfacePlacementNoTrace到来的时候再检查看看有没有完成同步。
3)、如果所有参与动画的WindowContainer都已经完成同步了,那么就继续调用SyncGroup.finishNow来将当前SyncGroup结束掉。
我们先分析WindowContainer.isSyncFinished,再去分析SyncGroup.finishNow。
2.1 WindowContainer.isSyncFinished
首先再回顾一下,当把WindowContainer添加SyncGroup的时候,会为每一个WindowContainer调用prepareSync方法,结果是:
1)、WindowState类型的WindowContainer,其mSyncState被置为SYNC_STATE_WAITING_FOR_DRAW。
2)、非WindowState类型的WindowContainer,其mSyncState被置SYNC_STATE_READY。
再看WindowContainer.isSyncFinished的内容:
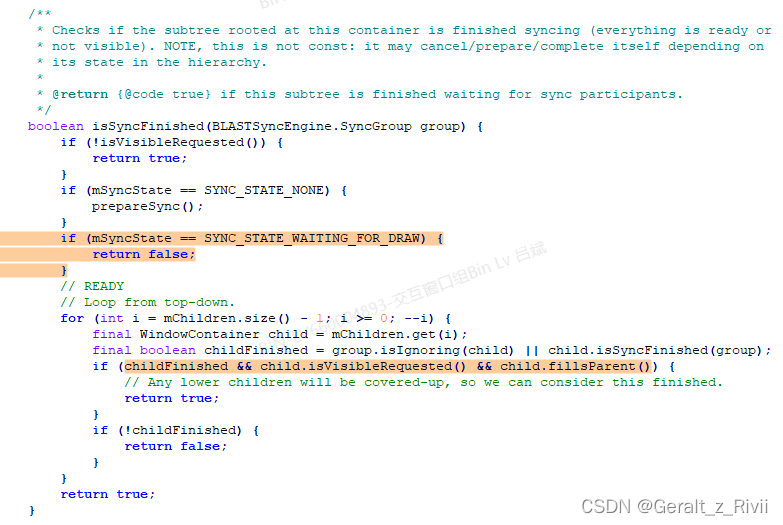
1)、首先一个基本的规则是,如果一个WindowContainer请求的是不可见的,那么将其视为同步完成。这个其实也很好理解,如果这个WindowContainer在完成动画的时候是不希望被显示的,那么就不需要等待它绘制完成了。
2)、对于非WindowState类型的WindowContainer,比如Task或者ActivityRecord,由于它们的mSyncState一开始就被设置为了SYNC_STATE_READY,因此它们主要是检查它们的mChildren是否同步完成,最终检查的就是其中的WindowState是否完成同步/绘制。一旦有一个WindowState:
- 同步完成。
- 请求可见。
- 和父容器大小相等。
只要找到一个符合以上条件的WindowState,那么就可以认为这个WindowContainer已经完成了同步。
3)、对于WindowState,则只有一个标准,即其mSyncState是否是SYNC_STATE_READY(暂不考虑子窗口的情况)。
2.2 WindowContainer.onSyncFinishedDrawing
再看下什么时候WindowState的mSyncState什么被设置为SYNC_STATE_READY。
WindowState的mSyncState被设置为SYNC_STATE_READY的地方只有一处,在WindowContainer.onSyncFinishedDrawing:
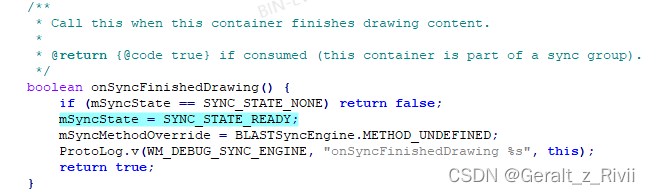
从注释也能看出,当WindowContainer完成绘制其内容的时候,这个方法会被调用。
具体调用的地方则是:
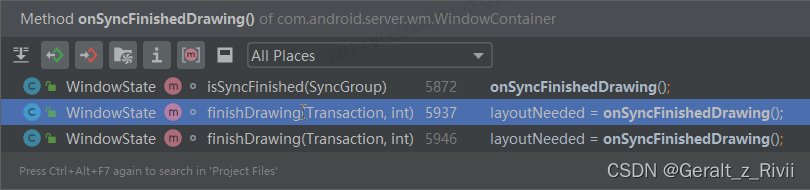
很明显,当窗口完成绘制时,会调用WindowState.finishDrawing,进而将WindowState的mSyncState设置为SYNC_STATE_READY。
而一旦Task/ActivityRecord中的WindowState绘制完成,那么该Task/ActivityRecord就会被视为同步完成。
这部分的内容之前分析WindowContainerTransaction的文章有过更加详细的介绍:
4【Android 12】【WCT的同步】BLASTSyncEngine - 掘金 (juejin.cn)
更多的详细内容可以看下当时的分析。
3 SyncGroup.finishNow
一旦SyncGroup中所有的动画参与者都同步完成,那么就调用SyncGroup.finishNow来结束掉这个SyncGroup。
这个方法是我们本篇文章的重点,且内容较多,我们分段去看。
3.1 合并Transaction
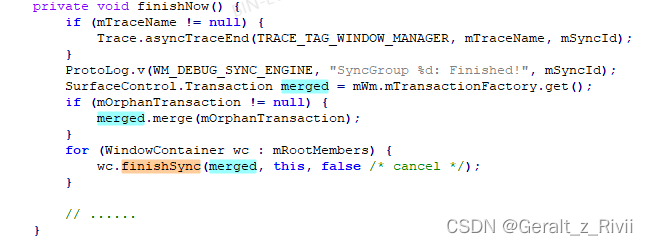
这里从对象工厂中拿到一个Transaction对象,局部变量merged,对于所有参与动画的WindowContainer,将它们在动画期间发生的同步操作都合并到这个局部变量merged中。
这一点主要是通过对所有参与动画的WindowContainer调用WindowContainer.finishSync方法来完成的,indowContainer.finishSync方法内容为:
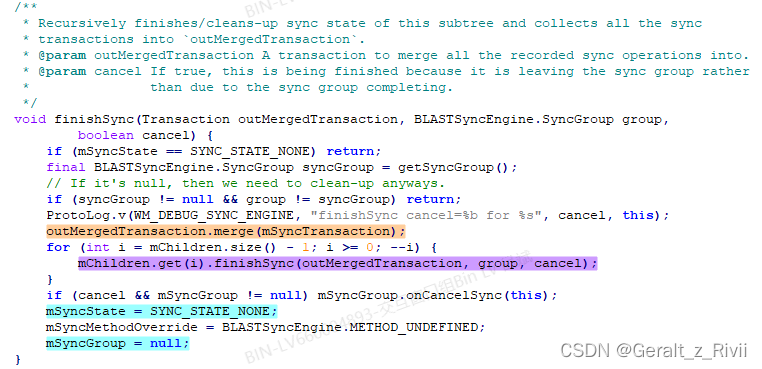
1)、将WindowContainer.mSyncTransaction中收集到的对当前WindowContainer对应的SurfaceControl的修改(同步操作)合并到传参outMergedTransaction中,即我们上面提到的SyncGroup.finishNow中的局部变量merged。
2)、递归调用所有子WindowContainer的finishSync方法,最终的结果是将这个WindowContainer以及所有子WindowContainer的同步操作都收集到传参outMergedTransaction中。
3)、最后由于同步工作已经结束,那么将这个WindowContainer的mSyncState以及mSyncGroup之类的成员变量进行重置。
这里所说的同步操作主要是针对WindowContainer.mSyncTransaction来说的,其实之前也看到过“sync”这个字眼了,我们这里来大致说明一下“同步”这个概念。
3.1.1 “同步”的概念
其实最早的时候,BLASTSyncEngine以及SyncGroup并不是用于动画,而是和WindowContainerTransaction一起结合使用,主要是用于分屏。
分屏由于将屏幕一分为二以供两个App同时显示,那么一旦分屏发生变化(进退分屏,调整分割线位置等),那么最起码就会有两个可见的SurfaceControl参与了变化,即参与分屏的这两个App下的SurfaceControl。
那么一个很明显能够想到的问题是,如何做到这两个分屏的App界面能够一起改变呢,比如我调整分屏分割线的位置,我肯定不希望看到上分屏的App界面改变之后,下分屏的App界面没有跟着一起改变,而是又过了几百毫秒才开始变化。这是一个肯定会遇到的问题,App界面改变是在窗口绘制完成之后,而WMS无法控制窗口绘制的时间,因此如果WMS不加以控制,那么就会出现由于两个窗口的绘制时间不同,导致用户看到的两个界面先后进行了改变(异步),而非同一时间进行了改变(同步)。
因此当时引出了BLASTSyncEngine以及SyncGroup的概念,这套机制最开始就是用来保证使用WindowContainerTransaction的模块(比如分屏)可以做到SurfaceControl的同步。
同步的大致做法,则是创建一个统一的Transaction对象(即SyncGroup.finishNow中创建的那个Transaction类型的局部变量merged),来收集所有参与到分屏的SurfaceControl的变化,并且只有等到所有参与分屏的窗口都绘制完成后,才对这个Transaction对象调用apply方法,这样就保证了所有的SurfaceControl变化在一次Transaction.apply中进行了提交。
从以上介绍可以看到要实现同步,有两个比较重要点,一是有一个统一的Transaction来收集所有SurfaceControl的变化,二是当所有参与同步的窗口绘制完成后再调用Transaction.apply。
更多的内容可以去看下之前分析WindowContainerTransaction的系列文章。
3.1.2 WindowContainer.mSyncTransaction
回到现在Android14的ShellTransitions中来,现在是动画也开始用BLASTSyncEngine这一套逻辑了,接下来看下现在动画是如何实现同步的。
从上面的介绍中,我们知道同步的两个重要的点是:
1)、有一个统一的Transaction来收集所有SurfaceControl的变化。
2)、当所有参与同步的窗口绘制完成后再调用这个统一的Transaction对象的Transaction.apply方法。
可知和这个Transaction是有很大的关系。
第二点放到后面再说,这一节我们分析一下第一点,即有一个统一的Transaction来收集所有SurfaceControl的变化。
之前看SyncGroup.finishNow,我们知道了这个统一的Transaction就是这里创建的Transaction类型的局部变量merged,它合并了所有参与动画的WindowContainer的mSyncTransaction中收集的内容,那么WindowContainer.mSyncTransaction又是什么?
再举一个例子,来看一个经典的对SurfaceControl进行显示的操作,为WindowSurfaceController.showRobustly:

根据以往的系列文章知WindowSurfaceController.mSurfaceControl对应的是SurfaceFlinger侧的BufferStateLayer。
调用Transaction.show的时候,只是将对SurfaceControl的操作暂存在了Transaction中(更准确的说,是native层的layer_state_t结构体中),只有当调用Transaction.apply的时候,这个对SurfaceControl的操作才算真正提交到了SurfaceFlinger端,进而作用到了Layer上。
那么我们再看下这个传参Transaction对象是从哪里拿到的,一般来说,调用堆栈为:
WindowState.prepareSurfaces
-> WindowStateAnimator.prepareSurfaces
-> WindowSurfaceController.showRebustly
看到是在WindowState.prepareSurfaces中,通过WindowContainer.getSyncTransaction拿到的:

WindowContainer.getSyncTransaction为:
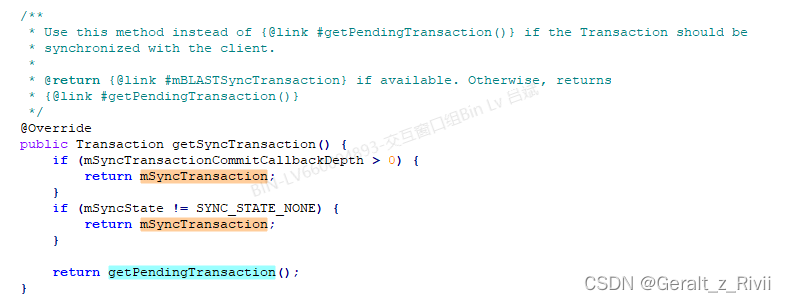
如果WindowContainer.mSyncTransactionCommitCallbackDepth大于0,或者WindowContainer.mSyncTransaction不为SYNC_STATE_NONE,说明此时WindowContainer仍然处于需要同步的场景中,因此返回WindowContainer.mSyncTransaction,否则返回WindowContainer.getPendingTransaction。
WindowContainer.getPendingTransaction为:

一般返回的是DisplayContent的mPendingTransaction。
再看下mSyncTransaction和mPendingTransaction的定义以及初始化:
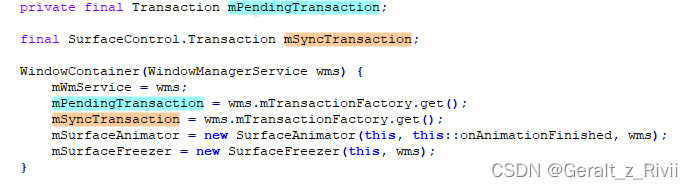
看到mSyncTransaction和mPendingTransaction其实都是一个普通的Transaction对象,本质上没有区别,区别在于它们的使用方式:
1)、pendingTransaction基本上每次RootWindowContainer.performSurfacePlacementNoTrace就apply一次:
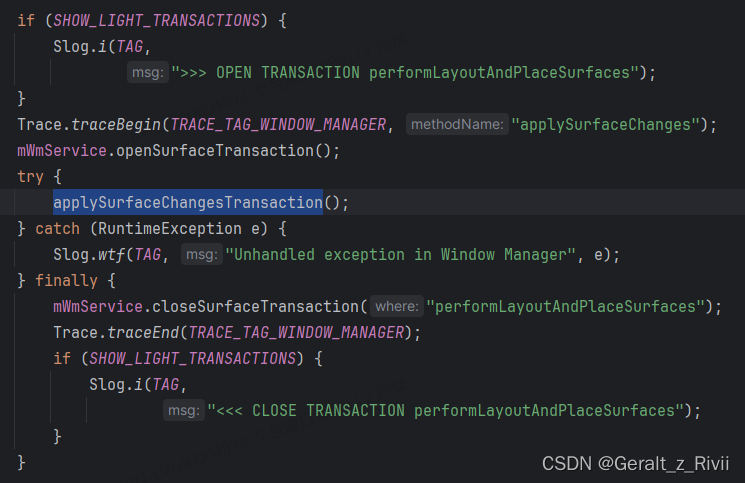
可以认为是使用pendingTransaction对SurfaceControl操作后,很快就会调用Transaction.apply,也就是说使用pendingTransaction对SurfaceControl进行的操作很快就能见到效果。
2)、syncTransaction的apply方法的调用时机则是和Transition的流程密切相关,只有走到特定的阶段才会调用Transaction.apply方法,以后的分析中我们会看到。
最后一句话总结一下pendingTransaction和syncTransaction的区别就是,需要WindowContaienr同步的场景使用syncTransaction,不需要WindowContainer同步的场景则使用pendingTransaction…怎么有点像废话呢
3.2 注册TransactionCommittedListener回调以及超时处理

主要内容是:
1)、为所有参与到动画的WindowContainer调用waitForSyncTransactionCommit方法.
2)、定义一个CommitCallback的类,这个类有一个自定义的onCommitted方法,以及复写Runnable的run方法。
3)、创建一个CommitCallback类的对象,callback。
4)、调用Transaction.addTransactionCommittedListener方法注册TransactionCommittedListener回调,回调触发的时候执行这个callback的onCommitted方法。
5)、Handler.postDelayed将这个callback添加到了MessageQueue中,5000ms超时之后执行这个callback的run方法。
接下来分别介绍,并不一定按照顺序。
3.2.1 注册TransactionCommittedListener回调
CommitCallback callback = new CommitCallback();merged.addTransactionCommittedListener(Runnable::run,() -> callback.onCommitted(new SurfaceControl.Transaction()));
看到这里为merged调用了Transaction.addTransactionCommittedListener方法:

从注释来看,TransactionCommittedListener的onTransactionCommitted回调方法会在Transaction被apply的时候调用,另外这个回调被执行的时候也说明当前Transaction将不会被一个新的Transaction对象复写。
那么再结合SyncGroup.finishNow的代码,也就是说,当merged这个Transaction对象被apply后,Transaction.addTransactionCommittedListener这段代码将被执行:
executor.execute(listener::onTransactionCommitted)
也就是异步执行传参listener的onTransactionCommitted方法,即SyncGroup.finishNow中的这段代码:
callback.onCommitted(new SurfaceControl.Transaction())
即当merged这个Transaction对象被apply后,这里定义的CommitCallback类的onCommitted方法将会被执行。
分析了注册TransactionCommittedListener回调后,我们可以再回过头来看CommitCallback类的定义,即它的onCommitted方法和run方法。
3.2.2 CommitCallback.onCommitted
先看onCommitted方法,从上面的分析我们知道这个方法将会在merged被apply的时候调用,作用为:
1)、将CommitCallback从MessageQueue中移除,即merged在规定的5000ms内得到apply了,那么就不需要触发超时了。
2)、将ran这个变量置为true,因为Transaction有可能在5000ms超时后才apply,那么onCommitted方法就有可能走两次。
3)、调用WindowContainer的onSyncTransactionCommitted方法,onSyncTransactionCommitted方法要和waitForSyncTransactionCommit结合着来看:

正好WindowContainer.waitForSyncTransactionCommit方法也是在上面被调用了,感觉这两个方法主要是对mSyncTransactionCommitCallbackDepth这个成员变量进行操作,而mSyncTransactionCommitCallbackDepth作用的地方也在我们之前看过的WindowContainer.getSyncTransaction中:

我自己的看法是,这个变量用来继续延长WindowContainer的同步状态。
如我们之前第一节合并Transaction中提到的,这里会为所有参与同步的WindowContainer调用WindowContainer.finishSync方法,这将会使得WindowContainer的mSyncState重置为SYNC_STATE_NONE,那么假如没有mSyncTransactionCommitCallbackDepth,此时调用WindowContainer.getSyncTransaction将会返回pendingTransaction,而非syncTransaction,也就是说WindowContainer的同步状态在走到SyncGroup.finishNow的时候就结束了。
而加入了mSyncTransactionCommitCallbackDepth之后,WindowContainer的同步状态的结束将会被延迟到merged被apply的时候。
为什么要这么做呢,因为此时SyncGroup.finishNow距离merged被apply还有一段时间,而且这个时间其实可能会超过5000ms,即上面规定的超时时限。假如在merged被apply之前,WindowContainer又发生了变化,那么如果没有mSyncTransactionCommitCallbackDepth的存在,此时WindowContainer将使用pendingTransaction,并且pendingTransaction如果再在merged被apply之前就apply,就会出现新的Transaction(pendingTransaction)的内容被旧的Transaction(syncTransaction)内容覆盖的情况。
4)、调用WindowContainer.onSyncTransactionCommitted,将所有参与动画的WindowContainer.mSyncTransaction收集到Transaction类型传参t中,集中进行一次apply。
如之前所说,此时距离merged被apply还有一段时间,在这段时间内参与到动画的WindowContainer是有可能继续发生变化的,而syncTransaction合并到merged的操作已经结束了,为了让这个时间段的变化也能够被应用,所以这里调用WindowContainer.mSyncTransaction,将收集到变化的syncTransaction都合并到一个Transaction中,然后调用apply。
但是这样不就是后发生变化的WindowContainer的Transaction先被apply了吗,这样不是还会出现上面提到的Transaction被覆盖的情况?目前我暂时没有碰到过这种情况,但是这个逻辑我感觉是有问题的。
3.2.3 CommitCallback.run
根据我们的分析,我们知道了这个方法将会在5000ms超时后调用,主要的内容是:
1)、调用TransactionReadyListener.onTransactionCommitTimeout,通知关心方超时的情况。
2)、调用CommitCallback.onCommitted方法,应该是想让syncTransaction收集到的变化得到应用,但是之前合并到merged那部分变化则是永久丢失掉了,这部分应该才是最重要的。
3)、这里打印了一条log:
Slog.e(TAG, "WM sent Transaction to organized, but never received" +" commit callback. Application ANR likely to follow.");
打印了这个条log的时候,我们已经知道是处于5000ms超时的情况了,那么可能会出现本来应该显示的Layer,在5000ms的时间内得不到显示,那么屏幕上就可能会出现没有任何一个输入窗口可以作为焦点窗口的情况(输入窗口能够接收焦点,需要其Layer为可见),如果此时再来一个KeyEvent事件,那么就会发生无焦点窗口的ANR。
3.3 调用Transition.onTransactionReady
只剩下最后一点内容了,一起来看下:
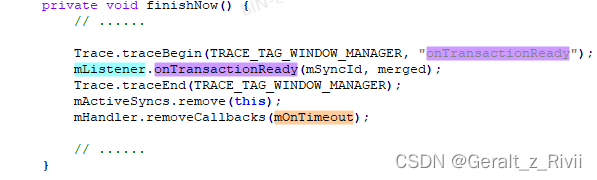
1)、调用TransactionReadyListener类型的mListener的onTransactionReady方法。
2)、将当前SyncGroup从BLASTSyncEngine.mActiveSyncs中移除。
3)、将其成员变量mOnTimeout从MessageQueue中移除。
有关其成员变量mListener以及mOnTimeout的部分,在之前创建SyncGroup对象的时候漏说了,现在大概过一遍。
首先看下SyncGroup的构造方法:
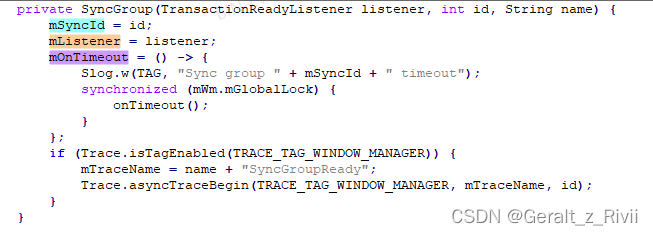
1)、int类型的mSyncId成员变量保存该SyncGroup的ID。
2)、TransactionReadyListener类型的成员变量mListener保存与该SyncGroup一一对应的Transition对象,TransactionReadyListener定义为:

用来通知Transition同步完成以及Transaction提交超时。
所以这里调用的是Transition.onTransactionReady,Transition.onTransactionReady的内容比较多,需要单独开一篇分析。
3)、mOnTimeout则是一个Runnable,用来在超时的时候触发BLASTSyncEngine.onTImeout方法:

主要内容就是遍历一下参与同步的WindowContainer,看下是哪个WindowContainer没有同步完成,以及在方法的最终调用SyncGroup.finishNow,这个一点也很好理解,毕竟我们不能无限等待某一个WindowState绘制完成。
注意区分一下这里的超时和我们上面提到的超时。
这里的超时是在SyncGroup刚刚创建,或者说Transition刚开始收集的时候,开始计时的,防止某一个窗口迟迟没有完成绘制,从而无限等待这个窗口绘制完成的情况。
上面提到的超时是在SyncGroup.finishNow的时候开始计时的,防止merged这个Transaction迟迟没有得到apply(Transition没有走到下一个阶段),从而syncTransaction的收集的变化内容无法被apply的情况。