手机站点农化网站建设
ldconfig
ldconfig 查看默认库路径和ld.so.conf包含的库路径,来建立运行时动态装载的库查找路径。
ldconfig命令的用途,主要是在默认搜寻目录(/lib和/usr/lib)以及动态库配置文件/etc/ld.so.conf内所列的目录下,搜索出可共享的动态链接库(格式如前介绍,lib*.so*),进而创建出动态装入程序(ld.so)所需的连接和缓存文件.缓存文件默认为/etc/ld.so.cache,此文件保存已排好序的动态链接库名字列表.
ldconfig命令通常与ld.so(动态链接器)一起使用。在大多数的Linux发行版中,ldconfig属于libc-bin软件包的一部分,并且已经默认安装。
在linux系统中,ldconfig是一个用于管理共享库缓存的命令。当您安装新的共享库或更改了库文件的位置时,ldconfig命令将帮助您更新系统的库缓存以反应这些更改。它会扫描默认的库搜索路径,查找共享库文件,并创建相应的链接以供程序在运行时使用。
ldd
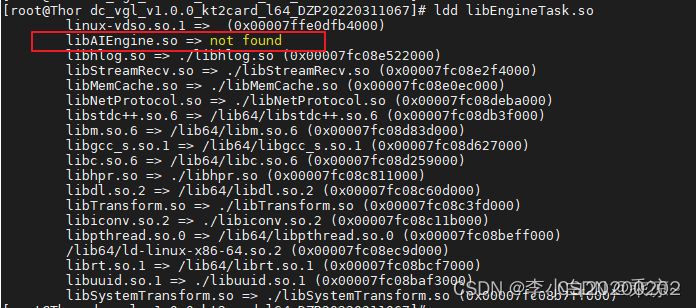
ldd命令全称为list dynamic dependencies(列出动态依赖),是Linux下常用的命令之一。它可以用来显示一个可执行文件或者共享库(动态链接库)所依赖的共享库。
如果当前的动态库因为缺少依赖库而无法链接,那么可以通过ldd查看缺少的依赖库。比如还是上面的例子,我去AI_lib路径下手动把libAIEngine.so删掉,再去执行ldd,结果如下