温州网站制作多少钱怎么建小说网站
个人博客:Sekyoro的博客小屋
个人网站:Proanimer的个人网站
RPC是远程调用,而google实现了grpc比较方便地实现了远程调用,gRPC是一个现代的开源远程过程调用(RPC)框架
概念介绍
在gRPC中,客户端应用程序可以直接调用另一台计算机上的服务器应用程序上的方法,就好像它是本地对象一样。
远程过程调用是一个分布式计算的客户端-服务器(Client/Server)的例子,它简单而又广受欢迎。
远程过程调用总是由客户端对服务器发出一个执行若干过程请求,并用客户端提供的参数。执行结果将返回给客户端。
由于存在各式各样的变体和细节差异,对应地派生了各式远程过程调用协议,而且它们并不互相兼容。为了允许不同的客户端均能访问服务器,许多标准化的 RPC 系统应运而生了。其中大部分采用接口描述语言(Interface Description Language,IDL),方便跨平台的远程过程调用。
与许多RPC系统一样,gRPC基于定义服务的思想,指定可以通过其参数和返回类型远程调用的方法。在服务器端,服务器实现了这个接口,并运行gRPC服务器来处理客户端调用。在客户端,客户端有一个stub(在某些语言中称为客户端),它提供与服务器相同的方法。
它具有许多特性
- 强大的IDL特性
RPC使用ProtoBuf来定义服务,ProtoBuf是由Google开发的一种数据序列化协议,性能出众,得到了广泛的应用。 - 支持多种语言
支持C++、Java、Go、Python、Ruby、C#、Node.js、Android Java、Objective-C、PHP等编程语言。 - 基于HTTP/2标准设计
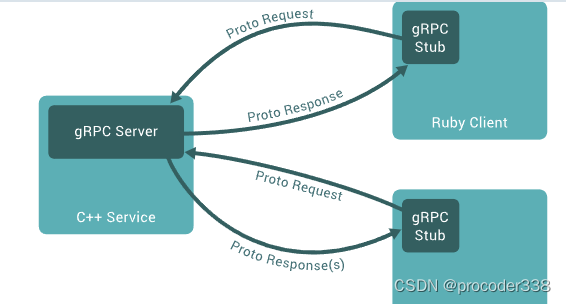
默认情况下,gRPC使用Protocol Buffers,这是谷歌成熟的开源机制,用于序列化结构化数据(尽管它可以与JSON等其他数据格式一起使用)
与REST差异
RPC 的消息传输可以通过 TCP、UDP 或者 HTTP等,所以有时候我们称之为 RPC over TCP、 RPC over HTTP。
RPC 通过 HTTP 传输消息的时候和 RESTful的架构是类似的,但是也有不同。
- gRPC使用HTTP/2,而REST使用HTTP1.1
- gRPC使用协议缓冲区数据格式,而不是REST API中通常使用的标准JSON数据格式
- 使用gRPC,可以利用HTTP/2功能,如服务器端流式传输、客户端流式传输,甚至双向流式传输
首先 RPC 的客户端和服务器端师紧耦合的,客户端需要知道调用的过程的名字,过程的参数以及它们的类型、顺序等。一旦服务器更改了过程的实现,客户端的实现很容易出问题。RESTful基于 http的语义操作资源,参数的顺序一般没有关系,也很容易的通过代理转换链接和资源位置,从这一点上来说,RESTful 更灵活。
其次,它们操作的对象不一样。 RPC 操作的是方法和过程,它要操作的是方法对象。 RESTful 操作的是资源(resource),而不是方法。
第三,RESTful执行的是对资源的操作,增加、查找、修改和删除等,主要是CURD,所以如果你要实现一个特定目的的操作,比如为名字姓张的学生的数学成绩都加上10这样的操作,
RESTful的API设计起来就不是那么直观或者有意义。在这种情况下, RPC的实现更有意义,它可以实现一个直接的方法方法供客户端调用
RPC over TCP可以通过长连接减少连接的建立所产生的花费,在调用次数非常巨大的时候(这是目前互联网公司经常遇到的情况,大并发的情况下),这个花费影响是非常巨大的。
当然 RESTful 也可以通过 keep-alive 实现长连接, 但是它最大的一个问题是它的request-response模型是阻塞的 (http1.0和 http1.1, http 2.0没这个问题),
发送一个请求后只有等到response返回才能发送第二个请求 (有些http server实现了pipeling的功能,但不是标配), RPC的实现没有这个限制。
其他RPC框架
目前的 RPC 框架大致有两种不同的侧重方向,一种偏重于服务治理,另一种偏重于跨语言调用。
服务治理型的 RPC 框架有Alibabs Dubbo、Motan 等,这类的 RPC 框架的特点是功能丰富,提供高性能的远程调用以及服务发现和治理功能,适用于大型服务的微服务化拆分以及管理,对于特定语言(Java)的项目可以十分友好的透明化接入。但缺点是语言耦合度较高,跨语言支持难度较大。
跨语言调用型的 RPC 框架有 Thrift、gRPC、Hessian、Finagle 等,这一类的 RPC 框架重点关注于服务的跨语言调用,能够支持大部分的语言进行语言无关的调用,非常适合于为不同语言提供通用远程服务的场景。但这类框架没有服务发现相关机制,实际使用时一般需要代理层进行请求转发和负载均衡策略控制。
thrift是Apache的一个跨语言的高性能的服务框架,也得到了广泛的应用。它的功能类似 gRPC, 支持跨语言,不支持服务治理。
rpcx 是一个分布式的Go语言的 RPC 框架,支持Zookepper、etcd、consul多种服务发现方式,多种服务路由方式, 是目前性能最好的 RPC 框架之一
使用protobuf
定义要在proto文件中序列化的数据的结构:这是一个扩展名为.proto的普通文本文件。协议缓冲区数据被构造为消息,其中每个消息都是一个包含一系列名值对(称为字段)的信息的小逻辑记录。
message Person {string name = 1;int32 id = 2;bool has_ponycopter = 3;
}
指定了数据结构,就可以使用协议缓冲区编译器protoc从proto定义中生成首选语言的数据访问类.
它们为每个字段提供了简单的访问器,如name()和set_name(),以及将整个结构序列化到原始字节/从原始字节解析整个结构的方法。
因此,例如,如果选择的语言是C++,那么在上面的示例中运行编译器将生成一个名为Person的类。然后,您可以在应用程序中使用此类来填充、序列化和检索Person协议缓冲区消息。
gRPC使用protoc和一个特殊的gRPC插件从proto文件中生成代码:可以获得生成的gRPC客户端和服务器代码,以及用于填充、序列化和检索消息类型的常规协议缓冲区代码。(截至目前protobuf最新版本是v3)
gRPC in Go
下载protoc
虽然不是强制性的,但gRPC应用程序通常利用proto buffer进行服务定义和数据序列化。
Releases · protocolbuffers/protobuf (github.com)
protoc用于编译.proto文件,其中包含服务和消息定义,Linux或Mac直接使用对应包管理器下载即可
apt install -y protobuf-compiler
protoc --version # Ensure compiler version is 3+
Windows在github上下载二进制包Releases · protocolbuffers/protobuf (github.com)
protocol compiler的Go插件
下载protoc-go-gen
go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@v1.2
go install google.golang.org/protobuf/cmd/protoc-gen-go@v1.28
下载zip的文件
git clone -b v1.60.1 --depth 1 https://github.com/grpc/grpc-go
proto文件
下面定义了服务
// Interface exported by the server.
service RouteGuide {// A simple RPC.//// Obtains the feature at a given position.//// A feature with an empty name is returned if there's no feature at the given// position.rpc GetFeature(Point) returns (Feature) {}// A server-to-client streaming RPC.//// Obtains the Features available within the given Rectangle. Results are// streamed rather than returned at once (e.g. in a response message with a// repeated field), as the rectangle may cover a large area and contain a// huge number of features.rpc ListFeatures(Rectangle) returns (stream Feature) {}// A client-to-server streaming RPC.//// Accepts a stream of Points on a route being traversed, returning a// RouteSummary when traversal is completed.rpc RecordRoute(stream Point) returns (RouteSummary) {}// A Bidirectional streaming RPC.//// Accepts a stream of RouteNotes sent while a route is being traversed,// while receiving other RouteNotes (e.g. from other users).rpc RouteChat(stream RouteNote) returns (stream RouteNote) {}
}
其中涉及到一些参数message表示传递数据.
// Points are represented as latitude-longitude pairs in the E7 representation
// (degrees multiplied by 10**7 and rounded to the nearest integer).
// Latitudes should be in the range +/- 90 degrees and longitude should be in
// the range +/- 180 degrees (inclusive).
message Point {int32 latitude = 1;int32 longitude = 2;
}// A latitude-longitude rectangle, represented as two diagonally opposite
// points "lo" and "hi".
message Rectangle {// One corner of the rectangle.Point lo = 1;// The other corner of the rectangle.Point hi = 2;
}// A feature names something at a given point.
//
// If a feature could not be named, the name is empty.
message Feature {// The name of the feature.string name = 1;// The point where the feature is detected.Point location = 2;
}// A RouteNote is a message sent while at a given point.
message RouteNote {// The location from which the message is sent.Point location = 1;// The message to be sent.string message = 2;
}// A RouteSummary is received in response to a RecordRoute rpc.
//
// It contains the number of individual points received, the number of
// detected features, and the total distance covered as the cumulative sum of
// the distance between each point.
message RouteSummary {// The number of points received.int32 point_count = 1;// The number of known features passed while traversing the route.int32 feature_count = 2;// The distance covered in metres.int32 distance = 3;// The duration of the traversal in seconds.int32 elapsed_time = 4;
}
生成的两个文件包括message实现和用于server,client的代码
在pb.go文件中对于每个message实现了其type,比如对于Rectangle
type Rectangle struct {state protoimpl.MessageStatesizeCache protoimpl.SizeCacheunknownFields protoimpl.UnknownFields// One corner of the rectangle.Lo *Point `protobuf:"bytes,1,opt,name=lo,proto3" json:"lo,omitempty"`// The other corner of the rectangle.Hi *Point `protobuf:"bytes,2,opt,name=hi,proto3" json:"hi,omitempty"`
}
func (x *Rectangle) Reset() {*x = Rectangle{}if protoimpl.UnsafeEnabled {mi := &file_routeguide_route_guide_proto_msgTypes[1]ms := protoimpl.X.MessageStateOf(protoimpl.Pointer(x))ms.StoreMessageInfo(mi)}
}func (x *Rectangle) String() string {return protoimpl.X.MessageStringOf(x)
}func (*Rectangle) ProtoMessage() {}func (x *Rectangle) ProtoReflect() protoreflect.Message {mi := &file_routeguide_route_guide_proto_msgTypes[1]if protoimpl.UnsafeEnabled && x != nil {ms := protoimpl.X.MessageStateOf(protoimpl.Pointer(x))if ms.LoadMessageInfo() == nil {ms.StoreMessageInfo(mi)}return ms}return mi.MessageOf(x)
}// Deprecated: Use Rectangle.ProtoReflect.Descriptor instead.
func (*Rectangle) Descriptor() ([]byte, []int) {return file_routeguide_route_guide_proto_rawDescGZIP(), []int{1}
}func (x *Rectangle) GetLo() *Point {if x != nil {return x.Lo}return nil
}func (x *Rectangle) GetHi() *Point {if x != nil {return x.Hi}return nil
}
对于Client来说,定义接口.首先使用grpc库中的grpc.ClientConnInterface作为routeGuideClient的成员.
type routeGuideClient struct {cc grpc.ClientConnInterface
}
给结构体routeGuideClient实现多个方法,并定义接口
type RouteGuideClient interface {// A simple RPC.//// Obtains the feature at a given position.//// A feature with an empty name is returned if there's no feature at the given// position.GetFeature(ctx context.Context, in *Point, opts ...grpc.CallOption) (*Feature, error)// A server-to-client streaming RPC.//// Obtains the Features available within the given Rectangle. Results are// streamed rather than returned at once (e.g. in a response message with a// repeated field), as the rectangle may cover a large area and contain a// huge number of features.ListFeatures(ctx context.Context, in *Rectangle, opts ...grpc.CallOption) (RouteGuide_ListFeaturesClient, error)// A client-to-server streaming RPC.//// Accepts a stream of Points on a route being traversed, returning a// RouteSummary when traversal is completed.RecordRoute(ctx context.Context, opts ...grpc.CallOption) (RouteGuide_RecordRouteClient, error)// A Bidirectional streaming RPC.//// Accepts a stream of RouteNotes sent while a route is being traversed,// while receiving other RouteNotes (e.g. from other users).RouteChat(ctx context.Context, opts ...grpc.CallOption) (RouteGuide_RouteChatClient, error)
}
然后通过NewRouteGuideClient返回结构体
func NewRouteGuideClient(cc grpc.ClientConnInterface) RouteGuideClient {return &routeGuideClient{cc}
}
实现结构体的方法
func (c *routeGuideClient) GetFeature(ctx context.Context, in *Point, opts ...grpc.CallOption) (*Feature, error) {out := new(Feature)err := c.cc.Invoke(ctx, RouteGuide_GetFeature_FullMethodName, in, out, opts...)if err != nil {return nil, err}return out, nil
}func (c *routeGuideClient) ListFeatures(ctx context.Context, in *Rectangle, opts ...grpc.CallOption) (RouteGuide_ListFeaturesClient, error) {stream, err := c.cc.NewStream(ctx, &RouteGuide_ServiceDesc.Streams[0], RouteGuide_ListFeatures_FullMethodName, opts...)if err != nil {return nil, err}x := &routeGuideListFeaturesClient{stream}if err := x.ClientStream.SendMsg(in); err != nil {return nil, err}if err := x.ClientStream.CloseSend(); err != nil {return nil, err}return x, nil
}
如果涉及stream还有新的结构,定义结构体,方法和接口
type RouteGuide_ListFeaturesClient interface {Recv() (*Feature, error)grpc.ClientStream
}type routeGuideListFeaturesClient struct {grpc.ClientStream
}func (x *routeGuideListFeaturesClient) Recv() (*Feature, error) {m := new(Feature)if err := x.ClientStream.RecvMsg(m); err != nil {return nil, err}return m, nil
}
对于server类似,定义接口
type RouteGuideServer interface {// A simple RPC.//// Obtains the feature at a given position.//// A feature with an empty name is returned if there's no feature at the given// position.GetFeature(context.Context, *Point) (*Feature, error)// A server-to-client streaming RPC.//// Obtains the Features available within the given Rectangle. Results are// streamed rather than returned at once (e.g. in a response message with a// repeated field), as the rectangle may cover a large area and contain a// huge number of features.ListFeatures(*Rectangle, RouteGuide_ListFeaturesServer) error// A client-to-server streaming RPC.//// Accepts a stream of Points on a route being traversed, returning a// RouteSummary when traversal is completed.RecordRoute(RouteGuide_RecordRouteServer) error// A Bidirectional streaming RPC.//// Accepts a stream of RouteNotes sent while a route is being traversed,// while receiving other RouteNotes (e.g. from other users).RouteChat(RouteGuide_RouteChatServer) errormustEmbedUnimplementedRouteGuideServer()
}
实现server和client
当使用protoc生成文件之后,就可以写server和client了.
server
定义结构体,注意定义时加上pb.UnimplementedRouteGuideServer这样避免有些方法没有实现.
type routeGuideServer struct {pb.UnimplementedRouteGuideServersavedFeatures []*pb.Feature // read-only after initializedmu sync.Mutex // protects routeNotesrouteNotes map[string][]*pb.RouteNote
}
实现接口满足的方法.
func (s *routeGuideServer) GetFeature(ctx context.Context, point *pb.Point) (*pb.Feature, error)
func (s *routeGuideServer) ListFeatures(rect *pb.Rectangle, stream pb.RouteGuide_ListFeaturesServer)
func (s *routeGuideServer) RecordRoute(stream pb.RouteGuide_RecordRouteServer)
func (s *routeGuideServer) RouteChat(stream pb.RouteGuide_RouteChatServer)
然后使用tcp链接新建grpc服务
func main() {flag.Parse()lis, err := net.Listen("tcp", fmt.Sprintf("localhost:%d", *port))if err != nil {log.Fatalf("failed to listen: %v", err)}var opts []grpc.ServerOptionif *tls {if *certFile == "" {*certFile = data.Path("x509/server_cert.pem")}if *keyFile == "" {*keyFile = data.Path("x509/server_key.pem")}creds, err := credentials.NewServerTLSFromFile(*certFile, *keyFile)if err != nil {log.Fatalf("Failed to generate credentials: %v", err)}opts = []grpc.ServerOption{grpc.Creds(creds)}}grpcServer := grpc.NewServer(opts...)pb.RegisterRouteGuideServer(grpcServer, newServer())grpcServer.Serve(lis)
}
上面使用pb.RegisterRouteGuideServer注册服务,参数分别是grpc服务和newServer返回的结构体
client
func printFeature(client pb.RouteGuideClient, point *pb.Point) {log.Printf("Getting feature for point (%d, %d)", point.Latitude, point.Longitude)ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)defer cancel()feature, err := client.GetFeature(ctx, point)if err != nil {log.Fatalf("client.GetFeature failed: %v", err)}log.Println(feature)
}
利用context创建ctx和cancel,利用client := pb.NewRouteGuideClient(conn)创建client调用方法.
NewRouteGuideClient返回对应的client接口
func NewRouteGuideClient(cc grpc.ClientConnInterface) RouteGuideClient {return &routeGuideClient{cc}
}
gRPC面临的挑战
虽然gRPC确实允许您使用这些较新的技术,但gRPC服务的原型设计更具挑战性,因为无法使用Postman HTTP客户端等工具来轻松地与您公开的gRPC服务交互。你确实有一些选择可以实现这一点,但这并不是一种在本地就可以获得的东西。
有一些选项可以使用诸如特使之类的工具来反转代理标准JSON请求,并将其转码为正确的数据格式,但这是一个额外的依赖项,对于简单的项目来说,设置它可能很困难。
参考资料
- Documentation | gRPC
- Go gRPC Beginners Tutorial | TutorialEdge.net
- [Go RPC开发简介 - 官方RPC库 - 《Go RPC开发指南 中文文档]》 - 书栈网 · BookStack
- RESTful API 最佳实践 - 阮一峰的网络日志 (ruanyifeng.com)
- Basics tutorial | Go | gRPC
- What is gRPC? | gRPC
如有疑问,欢迎各位交流!
服务器配置
宝塔:宝塔服务器面板,一键全能部署及管理
云服务器:阿里云服务器
Vultr服务器
GPU服务器:Vast.ai