金融投资管理公司网站源码网站制作论文题目
ZooKeeper 操作命令
ZooKeeper的操作命令主要用于对ZooKeeper服务中的节点进行创建、查看、修改和删除等操作。以下是一些常用的ZooKeeper操作命令及其说明:
一、启动与连接
-
启动ZooKeeper服务器:
./zkServer.sh start这个命令用于启动ZooKeeper服务器。
-
连接ZooKeeper客户端:
./zkCli.sh或者,指定服务器地址和端口号进行连接:
./zkCli.sh -server <ip>:<port> -
退出ZooKeeper客户端:
quit -
关闭ZooKeeper服务器:
./zkServer.sh stop -
查看ZooKeeper服务器状态:
./zkServer.sh status
二、节点操作
1. 查看节点
-
ls命令:用于列出指定节点下的所有子节点。
ls <path> [watch]其中,
<path>是节点的路径,[watch]是可选参数,用于监听该节点的变化。
-
ls2命令:与ls命令类似,但会同时列出子节点和节点的状态信息。
ls2 <path> [watch]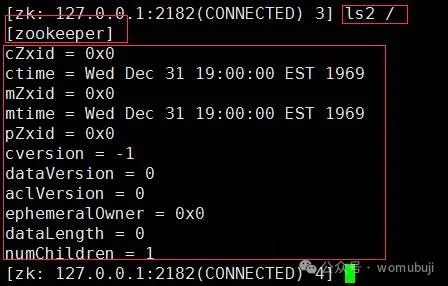
-
get命令:用于获取指定节点的数据内容和属性信息。
get <path> [watch]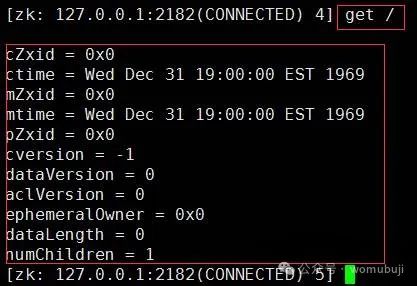
2. 创建节点
-
create命令:用于创建一个新的节点。
create <path> <data> [acl]其中,
<path>是节点的路径,<data>是节点存储的数据,[acl]是可选的访问控制列表。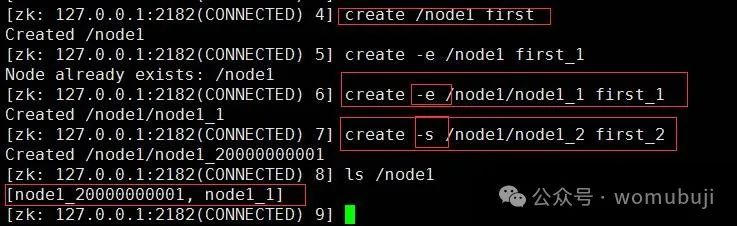
create -s <path> <data>顺序节点会在节点名后自动添加一个递增的序列号。
create -e <path> <data>临时节点在客户端会话结束后会自动删除。
-
创建临时节点:使用
-e选项。 -
创建顺序节点:使用
-s选项。
-
3. 修改节点
-
set命令:用于修改指定节点的数据内容。
bash set <path> <data> [version]其中,<path>是节点的路径,<data>是新的数据内容,[version]是可选的数据版本号,用于控制更新的条件。

4. 删除节点
-
delete命令:用于删除指定节点。
delete <path> [version]其中,
<path>是节点的路径,[version]是可选的数据版本号。注意,delete命令只能删除空节点(即没有子节点的节点)。
-
删除非空节点:一些ZooKeeper版本或扩展可能提供了
deleteall命令来删除非空节点,但这不是ZooKeeper核心功能的标准部分。在实际使用中,需要先删除非空节点的所有子节点,然后再删除该节点。
-
三、其他命令
-
stat命令:用于获取指定节点的状态信息。
stat <path> [watch]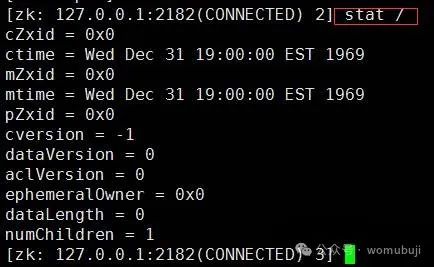
-
help命令:在ZooKeeper客户端中,可以使用help命令来查看所有可用的命令及其说明。
help
这些命令是ZooKeeper操作中常用的基本命令,它们涵盖了节点的创建、查看、修改和删除等核心功能。在实际使用中,可以根据需要选择合适的命令进行操作。
ZooKeeper 集群部署
ZooKeeper集群部署是一个涉及多个步骤和配置的过程,主要包括环境准备、ZooKeeper安装、配置文件修改、启动和验证集群等关键步骤。以下是一个以3台服务器详细的部署指南:
一、环境准备
-
硬件资源:
-
通常建议使用3台或更多(推荐为2n+1台,n为大于1的整数)的服务器来部署ZooKeeper集群,以确保高可用性和容错性。
-
每台服务器应具有足够的CPU、内存和存储空间来支持ZooKeeper的运行。
-
三个节点, 修改操作系统的/etc/hosts文件,添加IP与主机名映射:
-
10.109.142.53 zk-001
10.109.190.32 zk-002
10.109.165.20 zk-003
-
操作系统:
-
选择支持ZooKeeper的操作系统,如Linux(推荐CentOS、Ubuntu等)。
-
-
网络配置:
-
确保所有服务器都能相互通信,且网络延迟和丢包率保持在较低水平。
-
配置好服务器的IP地址和主机名,并确保它们能在集群中正确解析。
-
-
软件依赖:
-
安装Java环境,因为ZooKeeper是用Java编写的。推荐使用Java 8或更高版本。
-
安装必要的工具和库,如tar、wget等,以便下载和解压ZooKeeper安装包。
-
二、ZooKeeper安装
-
下载ZooKeeper安装包:
-
访问Apache ZooKeeper的官方网站(https://zookeeper.apache.org/)或镜像站点,下载最新版本的ZooKeeper安装包。
-
可以使用wget命令或浏览器下载到本地,然后上传到服务器。
-
-
解压安装包:
-
将下载的ZooKeeper安装包解压到指定的目录,如
/usr/local/。 -
重命名解压后的文件夹,以便更容易识别,如
zookeeper-3.x.x。
-
三、配置文件修改
1. 复制配置文件:
-
进入ZooKeeper的
conf目录,复制zoo_sample.cfg文件为zoo.cfg。
2. 编辑zoo.cfg文件:
配置如下:
# 服务器之间或客户端与服务器之间维持心跳的时间间隔
# tickTime以毫秒为单位。tickTime=2000# 集群中的follower服务器(F)与leader服务器(L)之间的初始连接心跳数initLimit=10# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数syncLimit=5# 快照保存目录# 不要设置为/tmp,该目录重新启动后会被自动清除dataDir=/data/zookeeper/zk1/data# 日志保存目录dataLogDir=/data/zookeeper/zk1/logs# 客户端连接端口clientPort=2181# 客户端最大连接数。# 根据自己实际情况设置,默认为60个# maxClientCnxns=60# 三个接点配置,格式为:# server.服务编号=服务地址、通信端口、选举端口server.1=zk-001:2888:3888server.2=zk-002:2888:3888server.3=zk-003:2888:3888
说明:
-
修改
dataDir参数,指定ZooKeeper存储快照的目录。 -
如果需要,还可以设置
dataLogDir参数,指定ZooKeeper存储事务日志的目录。 -
修改
clientPort参数,设置ZooKeeper服务监听的端口号(默认为2181)。 -
在配置文件末尾添加集群配置,格式为
server.n=host:peerPort:electionPort,其中n是服务器的唯一标识(与myid文件中的值对应);host是服务器的IP地址或主机名;peerPort是用作leader与follwer之间的通信端口号(数据同步),默认为2888;electionPort是用于选举Leader投票的端口号(默认为3888)。
这一步主要是配图中的框出来的内容:

3. 创建myid文件:
-
在每台服务器的
dataDir指定的目录下,创建一个名为myid的文件,内容为该服务器的唯一标识(与zoo.cfg中配置的server.n中的n相对应)。
以第一台为例 vim myid:
按照以上步骤,三台服务器做同样的操作。
四、启动ZooKeeper集群
-
启动ZooKeeper服务:
-
在每台服务器上,进入ZooKeeper的
bin目录,执行./zkServer.sh start命令分别启动ZooKeeper服务。
-
-
验证集群状态:
-
在每台服务器上执行
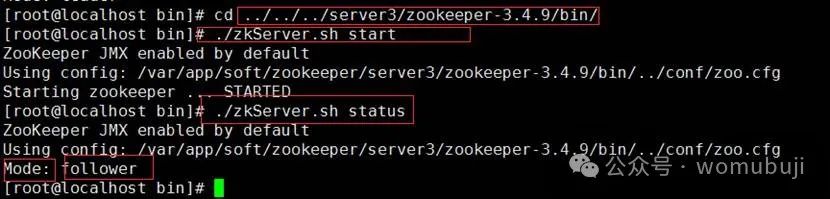
./zkServer.sh status命令,查看ZooKeeper服务的状态。 -
正常情况下,集群中应该有一个Leader和多个Follower。可以通过查看日志或使用ZooKeeper客户端工具(如zkCli.sh)来进一步验证集群的运行状态。
-
如第三台服务器:
五、注意事项
-
防火墙和安全组配置:
-
确保ZooKeeper服务监听的端口(默认为2181)在服务器的防火墙和安全组中已开放。
-
-
数据备份和恢复:
-
定期备份ZooKeeper的数据目录和日志目录,以便在数据丢失或损坏时能够恢复。
-
-
监控和日志:
-
配置监控工具来监控ZooKeeper集群的性能和健康状况。
-
定期查看ZooKeeper的日志文件,以便及时发现并解决问题。
-
-
版本兼容性:
-
确保集群中所有服务器上的ZooKeeper版本相同,以避免版本不兼容导致的问题。
-
通过以上步骤,您可以成功部署一个ZooKeeper集群,并确保其能够稳定运行。