优秀建筑方案设计文本福田我要做网站优化比较好
传统的session认证
我们知道,http协议是一种无状态的协议,这就意味着当用户向我们的应用提供了用户名和密码进行用户认证,那么在下一次登录的时候,用户还要再进行验证,因为根据http协议,浏览器并不知道是谁发出的请求,所以为了能够让浏览器识别出是哪个用户发出的请求,我们需要在服务器端存储一份用户登录的信息,这份信息会在响应时传递给浏览器,告诉其被保存为cookie,以便下次请求时发送给我们的应用,这样浏览器就可以知道是哪个用户登录了。
但这种基于session的认证使应用难以得到扩展,随着不同客户端用户的增加,独立的服务器无法承载越来越多的用户信息,而这时候基于session认证应用的问题就会暴露出来。
基于session认证应用的问题
Session
每个用户经过我们的应用认证之后,应用都要在服务端做一次记录,以方便用户下次请求的鉴别,通常而言 session 都是保存在内存中, 而随着认证用户的增多,服务端的开销会明显增大。
扩展性
用户认证之后,服务端做认证记录,如果认证的记录被保存在内存 中的话,这意味着用户下次请求还必须要请求在这台服务器上,这样才能拿到授权的资源,这样在分布式的应用上,相应的限制了负载均衡器的能力。这也意味着限制了应用的扩展能力。
CSRF (跨站请求伪造)
基于token的认证
基于token的鉴权机制类似于http协议也是无状态的,它不需要在服务端保留用户的认证信息或者会话信息,这就意味着基于token认证机制的应用无需考虑用户在哪一台服务器登录,这就问应用的扩展提供了便利性。
token的工作流程
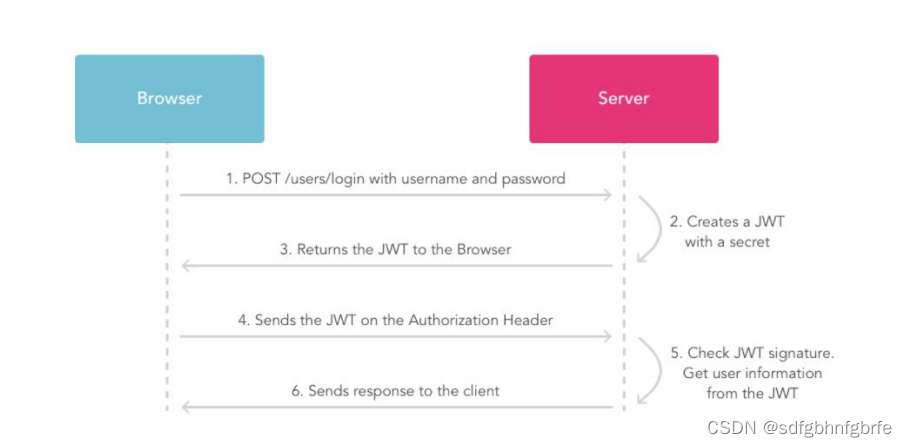
使用token的目的:是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。