网站管理系统推荐上海平台网站建设平台
1. 设计接口
请求参数的介绍
Query:相当于get请求,写的参数在地址栏中可以看到
Body: 相当于 post请求,请求参数不在地址栏中显示。
请求表单类型,用form-data
json文件类型,用row
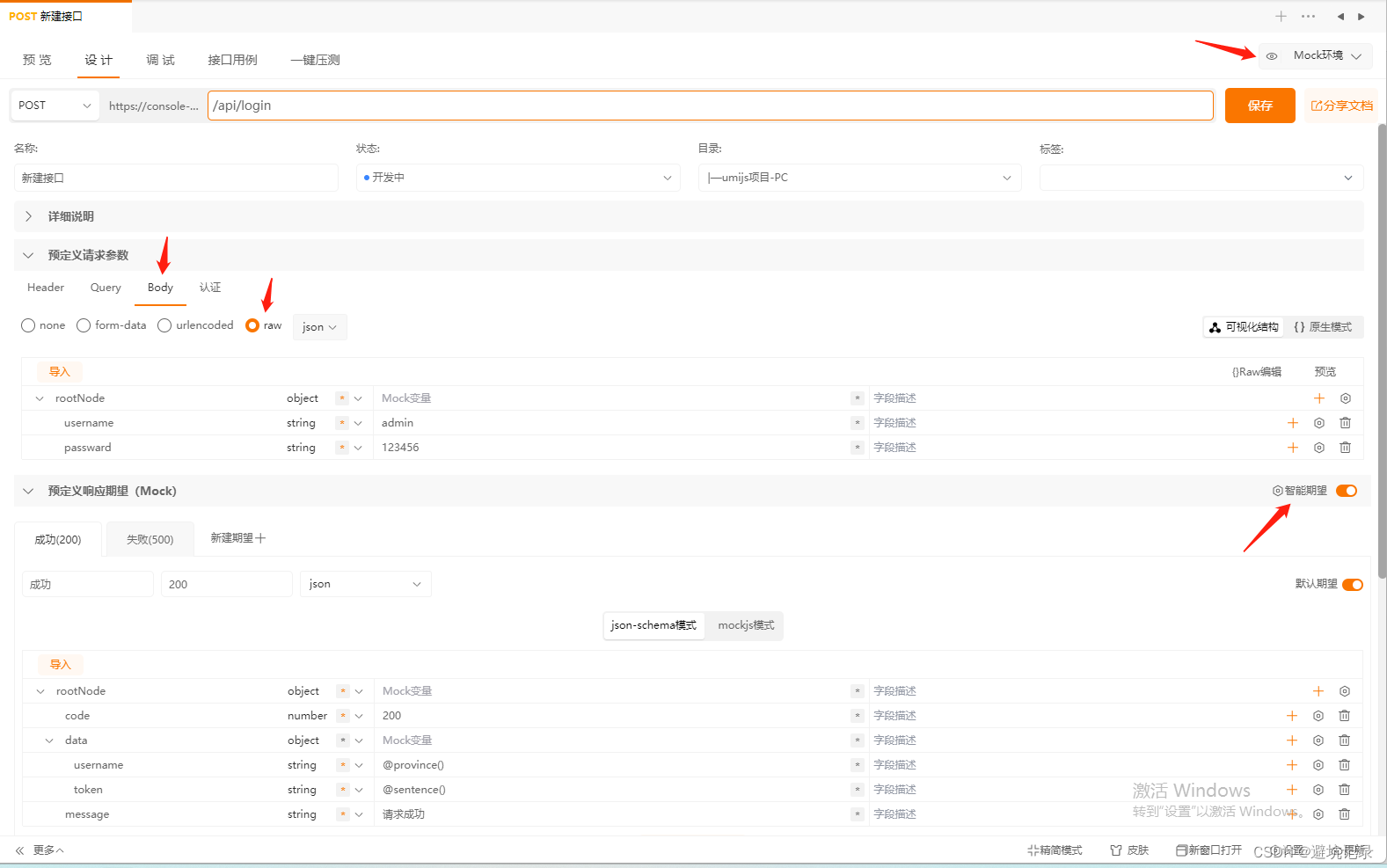
2. 预期响应期望
设置完每一项点一下生成响应示例
设置完之后打开右边智能期望,点击设置图标,进行设置。(就是参数成功,不成功的情况)

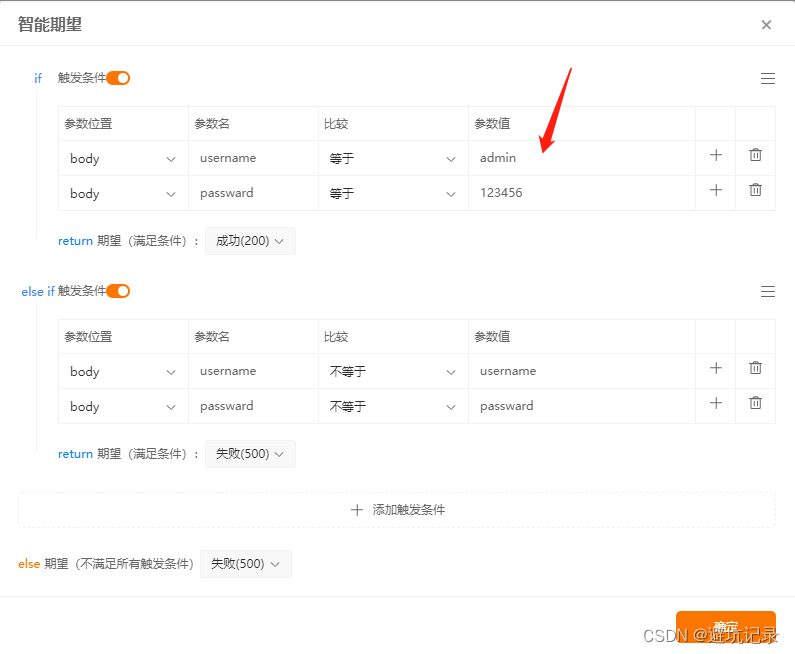
以上设置结束后,就可以测试接口了。
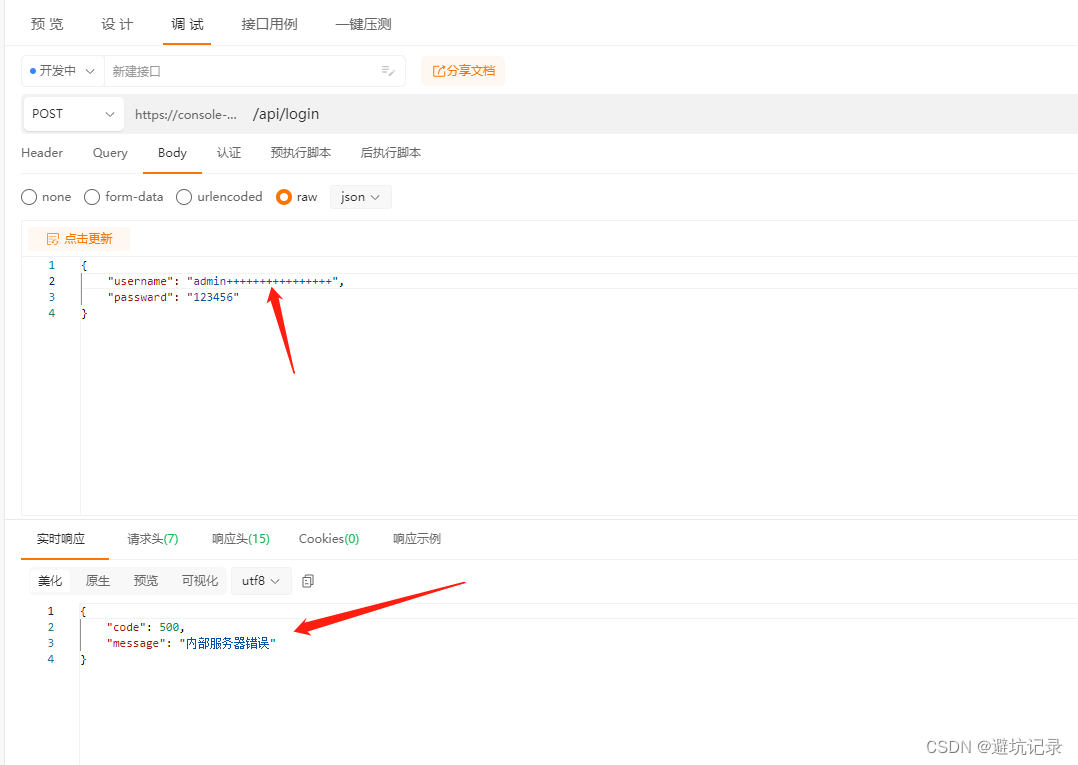
3.调试接口

参数不对的时候就会报错
请求参数的介绍
Query:相当于get请求,写的参数在地址栏中可以看到
Body: 相当于 post请求,请求参数不在地址栏中显示。
请求表单类型,用form-data
json文件类型,用row
设置完每一项点一下生成响应示例
设置完之后打开右边智能期望,点击设置图标,进行设置。(就是参数成功,不成功的情况)
以上设置结束后,就可以测试接口了。
参数不对的时候就会报错