如何建立一个私人网站担路网做网站多少钱
1. C++程序的一般组织结构
C++源程序的结构基本上都是由3个部分构成:类的定义、类的成员的实现和主函数。因为所编写的程序比较小,所以这三个部分都写在了同一个文件当中。在规模比较大的项目中,往往需要多个源程序文件,每个源程序文件称为一个编译单元。这时C++语法要求一个类的定义必须出现在所有使用该类的编译单元中。习惯的做法是把类的定义写在头文件中,使用该类的编译单元则包含这个头文件。通常一个项目至少划分为3个文件:类定义文件(*.h文件)、类实现文件(*.cpp文件)和类的使用文件(*.cpp,主函数文件)。对于更复杂的程序,每一个类都有单独的定义和实现文件。采用这样的结构,可以对不同的文件进行单独编写、编译,最后再连接,同时可以充分利用类的封装性,在程序的调试、修改时只对其中一个类的定义和实现进行修改,而其余部分不用改动。
【例】具有静态数据、函数成员的Point类,多文件组织。
(1)文件1,类的定义:point.h
#pragma once
class Point//类的定义
{
public://外部接口Point(int x, int y) :x(x), y(y) { count++; }Point(const Point& p);~Point() { count--; }int getX() { return x; }int getY() { return y; }static void ShowCount();//静态函数成员
private://私有函数成员int x, y;static int count;//静态数据成员
};
(2)文件2,类的实现:point.cpp
#include<iostream>
#include"Point.h"
using namespace std;int Point::count = 0;//使用类名初始化静态数据成员
Point::Point(const Point& p):x(p.x),y(p.y)//拷贝构造函数的实现
{count++;
}
void Point::ShowCount()//静态函数成员ShowCount()的实现
{cout << "对象的数量" <<count<< endl;
}
(3)文件3,主函数文件的实现:Main.cpp
#include<iostream>
#include"Point.h"
using namespace std;int main()
{Point a(4, 5);cout << "Point A: " <<"("<< a.getX() << "," << a.getY()<<") ";Point::ShowCount();Point b(a);cout << "Point B: " <<"("<< b.getX() << "," << b.getY()<<") ";Point::ShowCount();return 0;
}
运行结果:

分析整个源程序的结构,C++多文件组织结构图,由3个单独的文件构成,它们相互关系和编译、连接过程如下图所示(这是windows操作系统的情形):
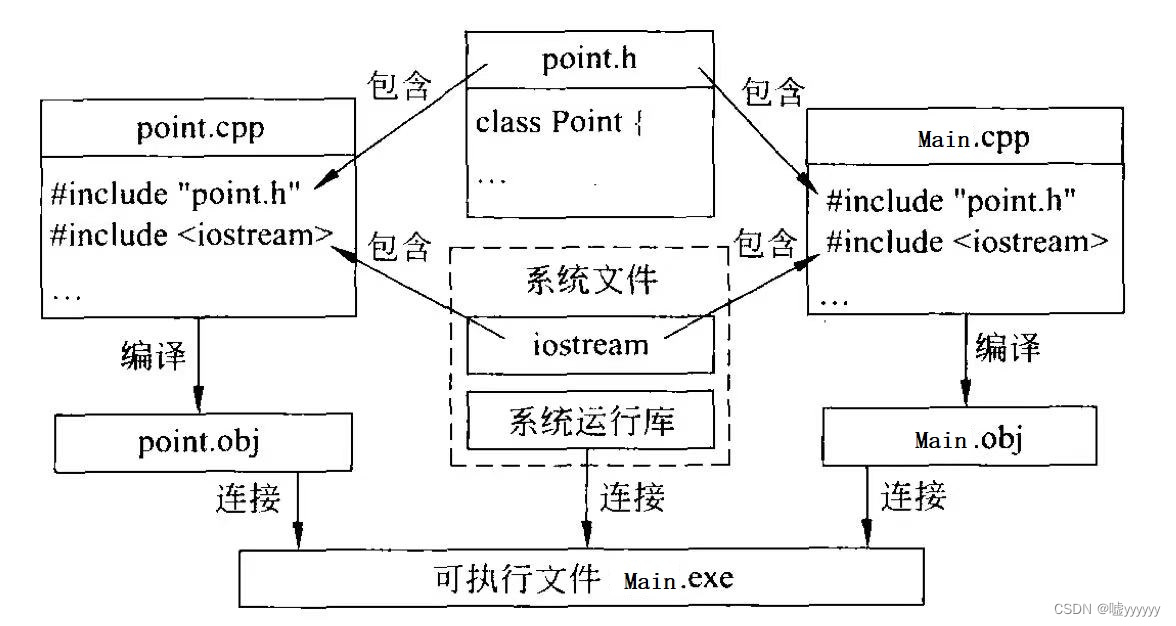
在多文件结构中,可以看到两个.cpp文件中都增加了一个新的include语句。在使用输入输出操作时,需要使用#include<iostream>,将系统提供的标准头文件iostream包含到源程序中。这里,同样需要使用语句#include"Point.h"将自定义的头文件包含进来。C++中的#include指令的作用就是将指定的文件嵌入到当前的源文件中#include指令所在的位置,这个嵌入的文件可以是.h文件,也同样可以是.cpp文件。
指令include可以有两种写法。第一种写法是#include<文件名>,表示按照标准方式搜索要嵌入的文件,该文件位于编译环境的include子目录下,一般要嵌入系统提供的标准文件时采用这样的方式,如对标准头文件iostream的包含。另一种写法是#include"文件名",表示首先在当前目录下搜索要嵌入的文件,如果没有,再按照标准方式搜索,对用户自己编写的文件一般采用这种方式,如本例中类的定义文件Point.h。
#include属于预处理指令。
从C++多文件组织结构图中可以看出,两个.cpp文件被分别编译生成各自的目标文件.obj,然后再与系统的运行库共同连接生成两个可执行文件.exe。如果只修改类的成员函数的实现部分,则只重新编译Point.cpp并连接即可,其余的文件可以看都不用看。所以,如果是一个语句很多、规模很大的程序,效率就会得到显著的提高。
这种多文件组织技术,在不同环境下有不同的方式来完成。在Windows系列操作系统下的C++一般使用工程来进行多文件管理,在Unix系列操作系统下一般可以用make工具完成。
决定一个声明放在源文件中还是头文件中的一般原则是,将需要分配的空间的定义放在源文件中,例如函数的定义(需要为函数代码分配空间)、命名空间作用域中的变量的定义(需要为变量分配空间)等;而将不需要分配空间的声明放到头文件中,例如类声明、外部函数的原型声明、外部变量的声明、基本数据类型常量的声明等。内联函数比较特殊,由于它的内容需要嵌入到每个调用他的函数中,所以对于那些需要被多个编译单元调用的内联函数,它们的代码应该被各个编译单元可见,这些内联函数的定义应当出现在头文件中。
【注意】如果误将分配了空间的定义写入到头文件中,在多个源文件包含该头文件时,会导致空间在不同的编译单元中被分配多次,从而在连接时引发错误。