我想自己做网站吗wordpress coolcode
文章目录
- 线性学习方法
- 聚类Clustering
- Kmeans
- HAC
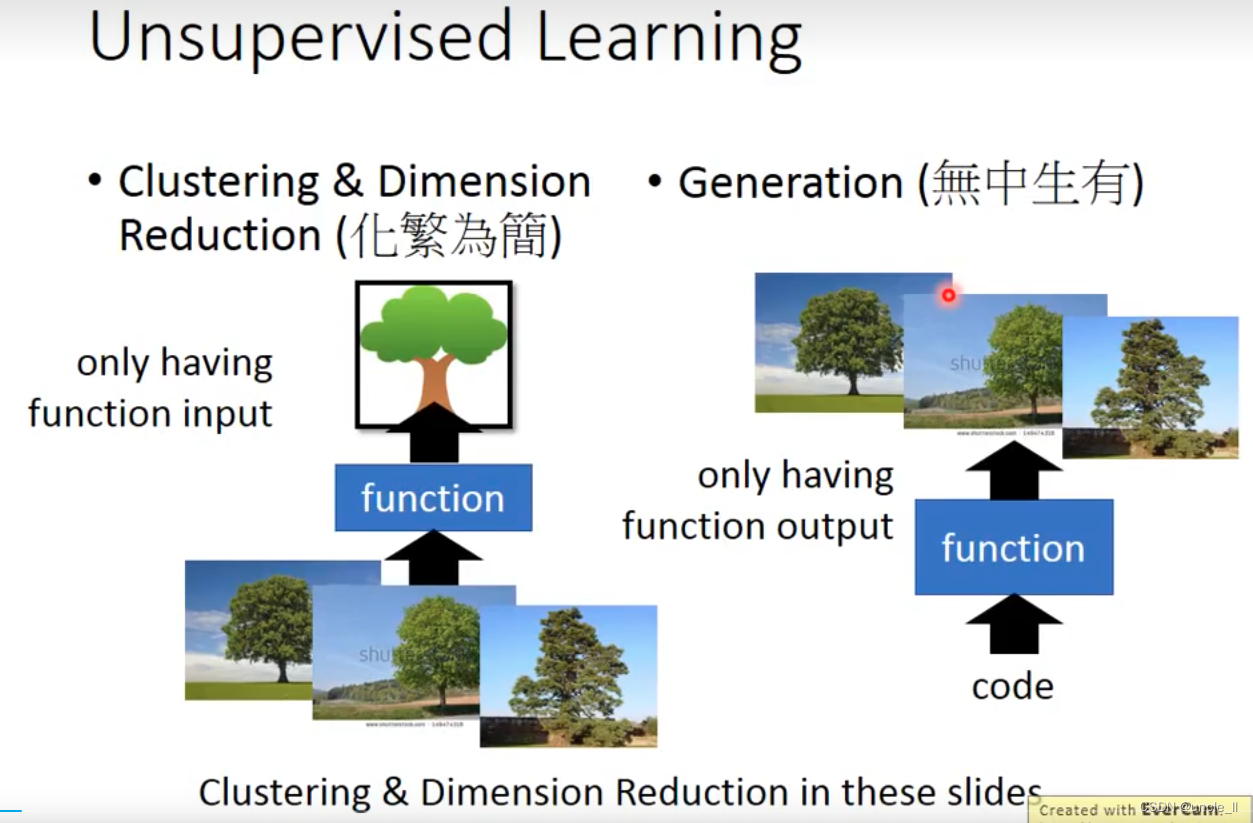
- 分布表示
- 降维
- PCA
- Matrix Factorization
- Manifold Learning
- LLE
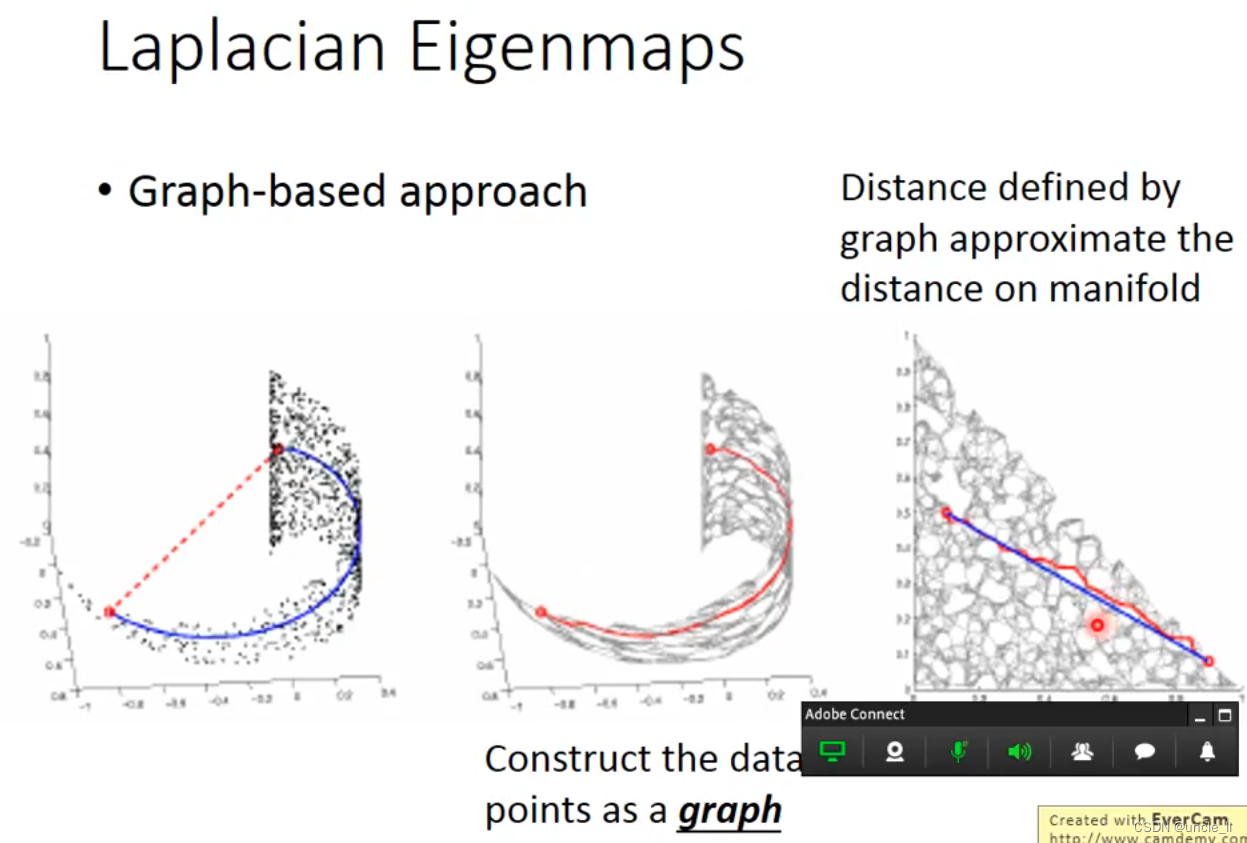
- Laplacian Eigenmaps
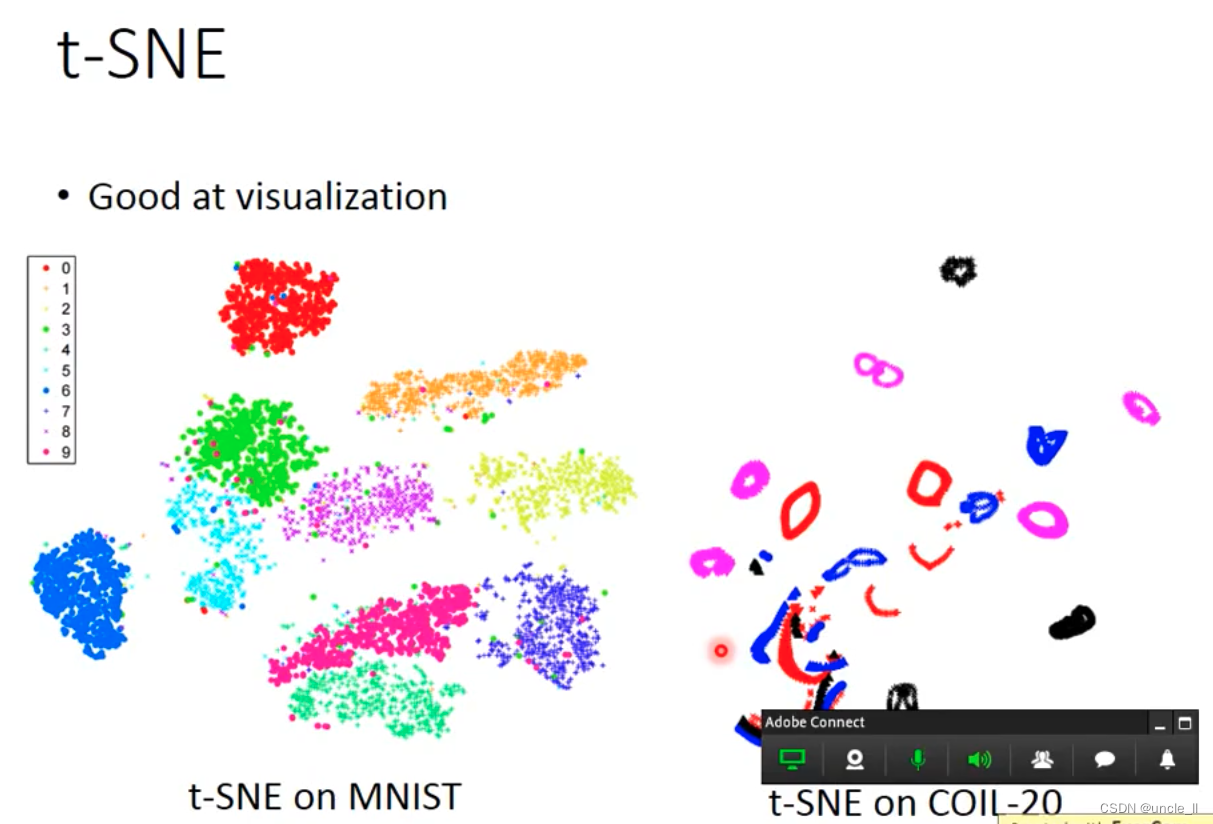
- t-SEN
线性学习方法
聚类Clustering
Kmeans

随机选取K个中心,然后计算每个点与中心的距离,找最近的,然后更新中心点
HAC
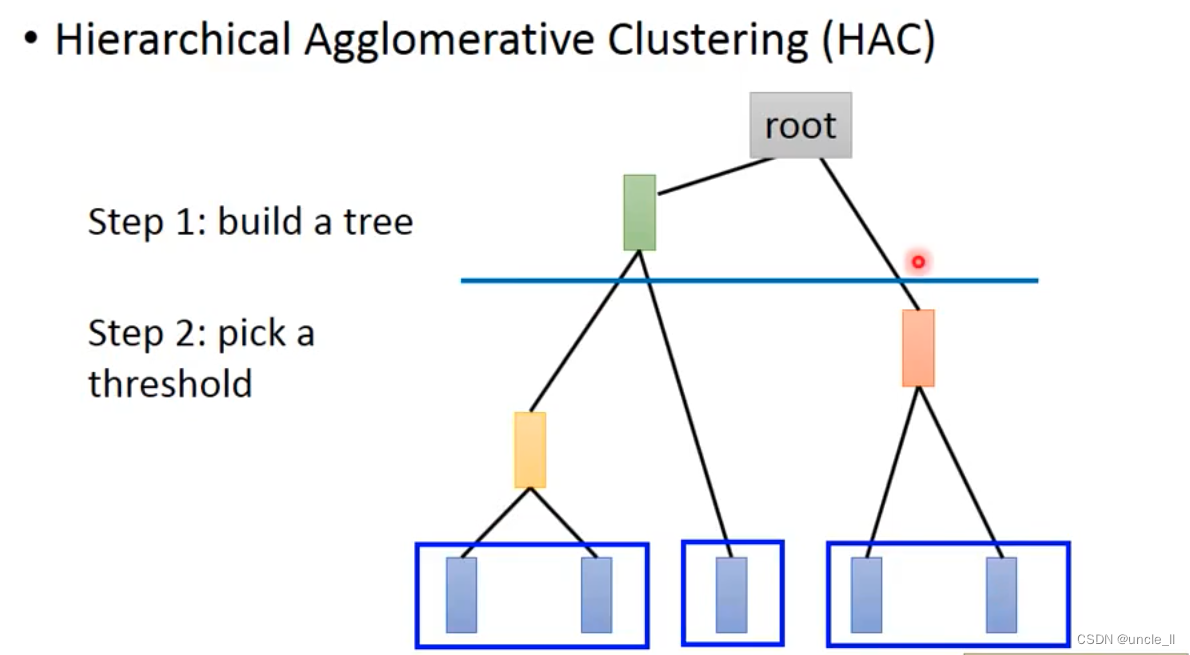
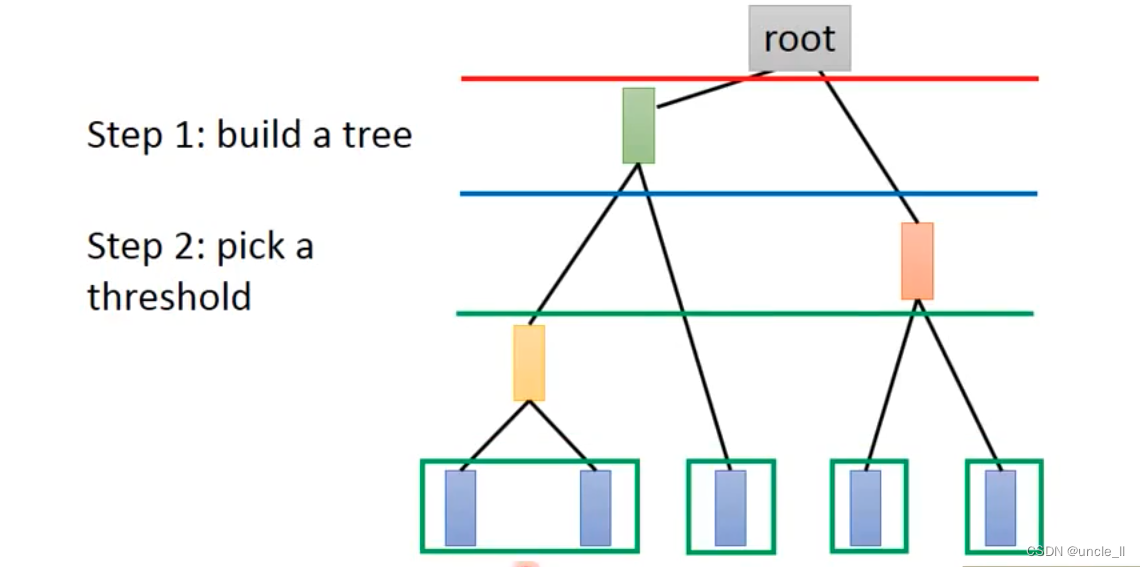
如何觉得距离的个数跟kmeans不一样,切的地方不一样导致的数量会不一样。
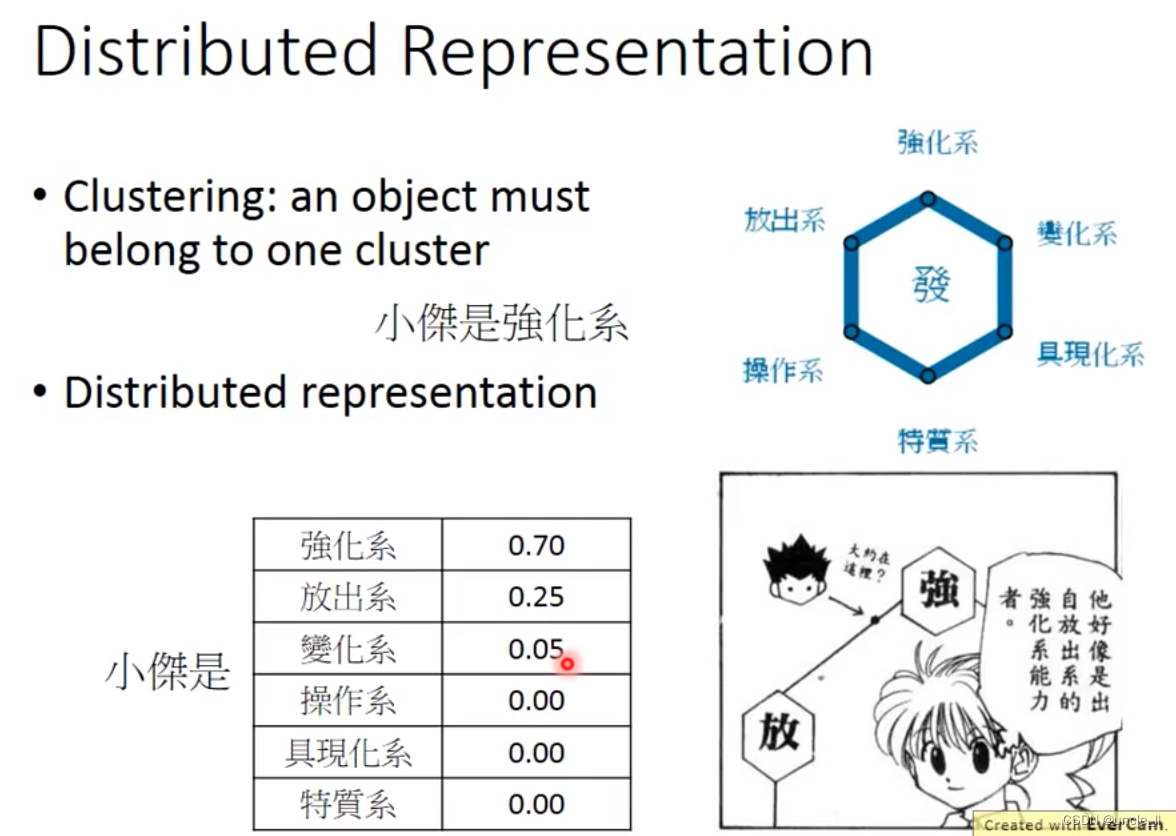
分布表示
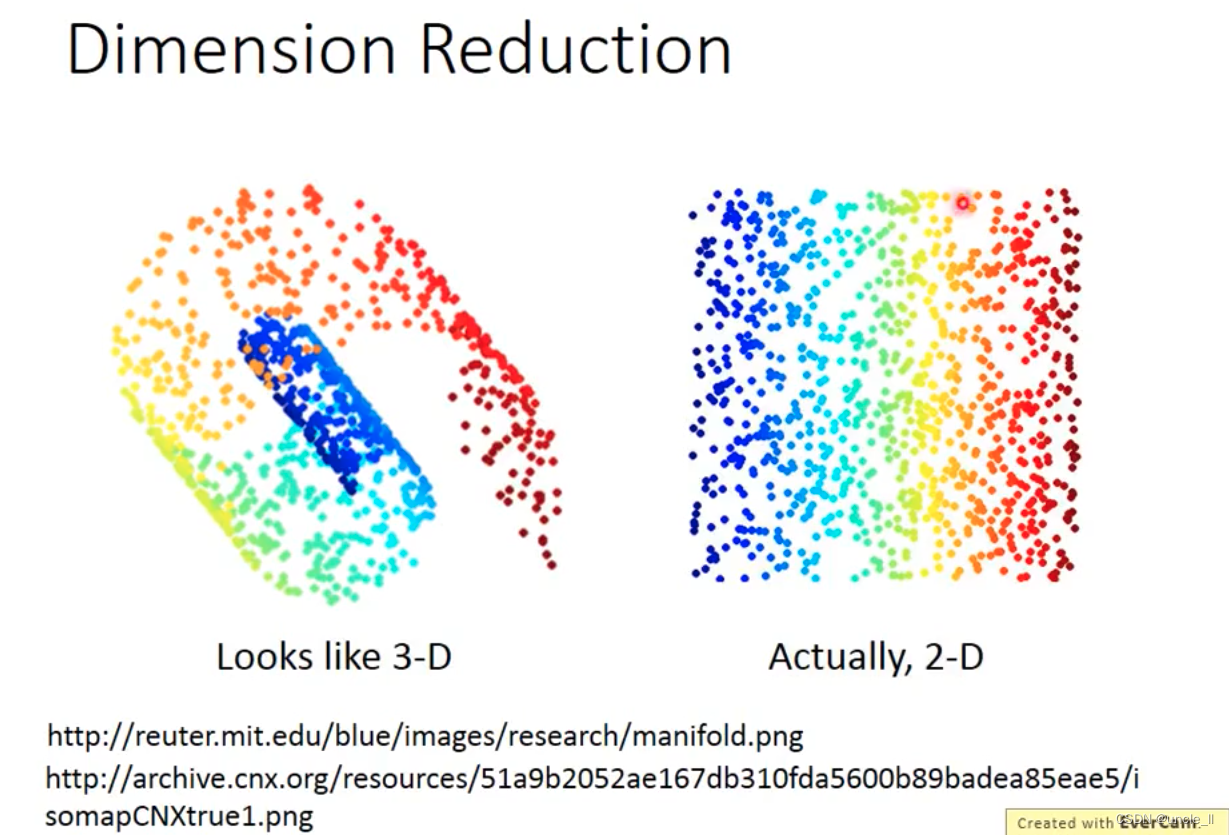
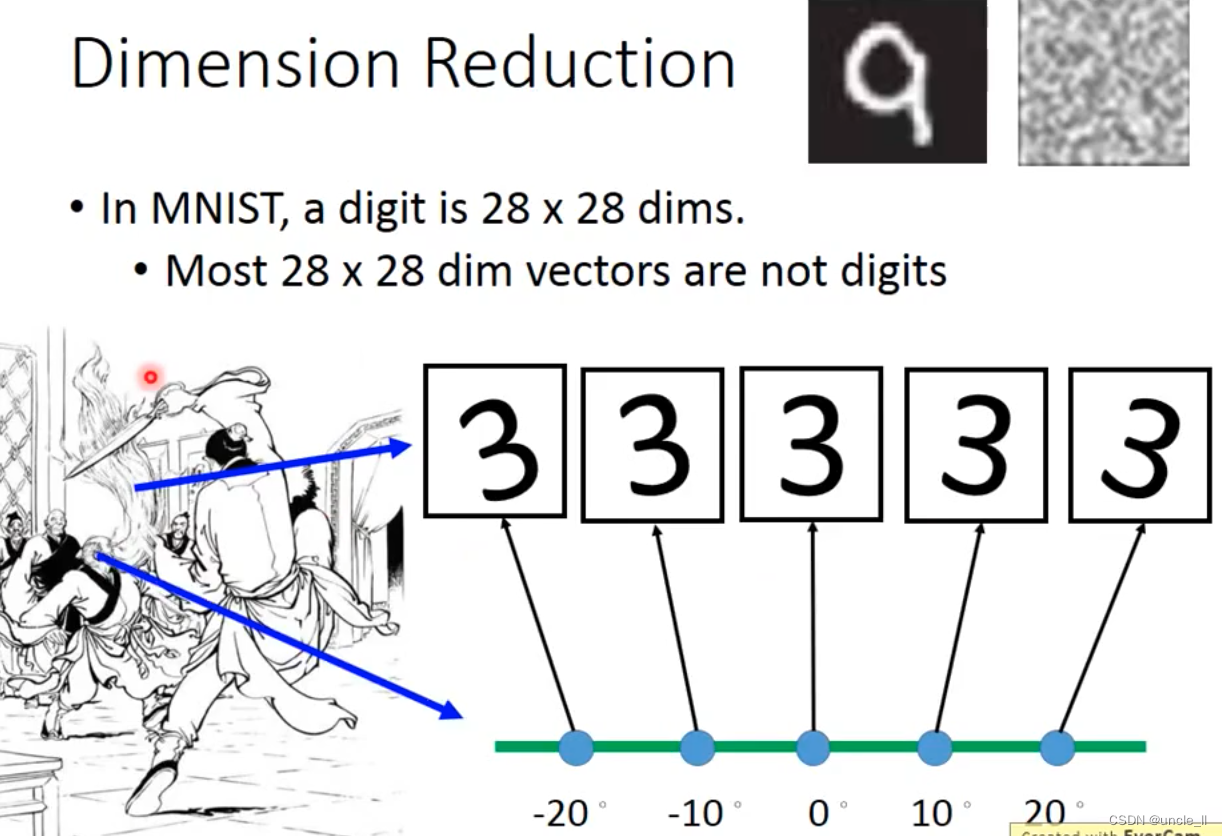
降维

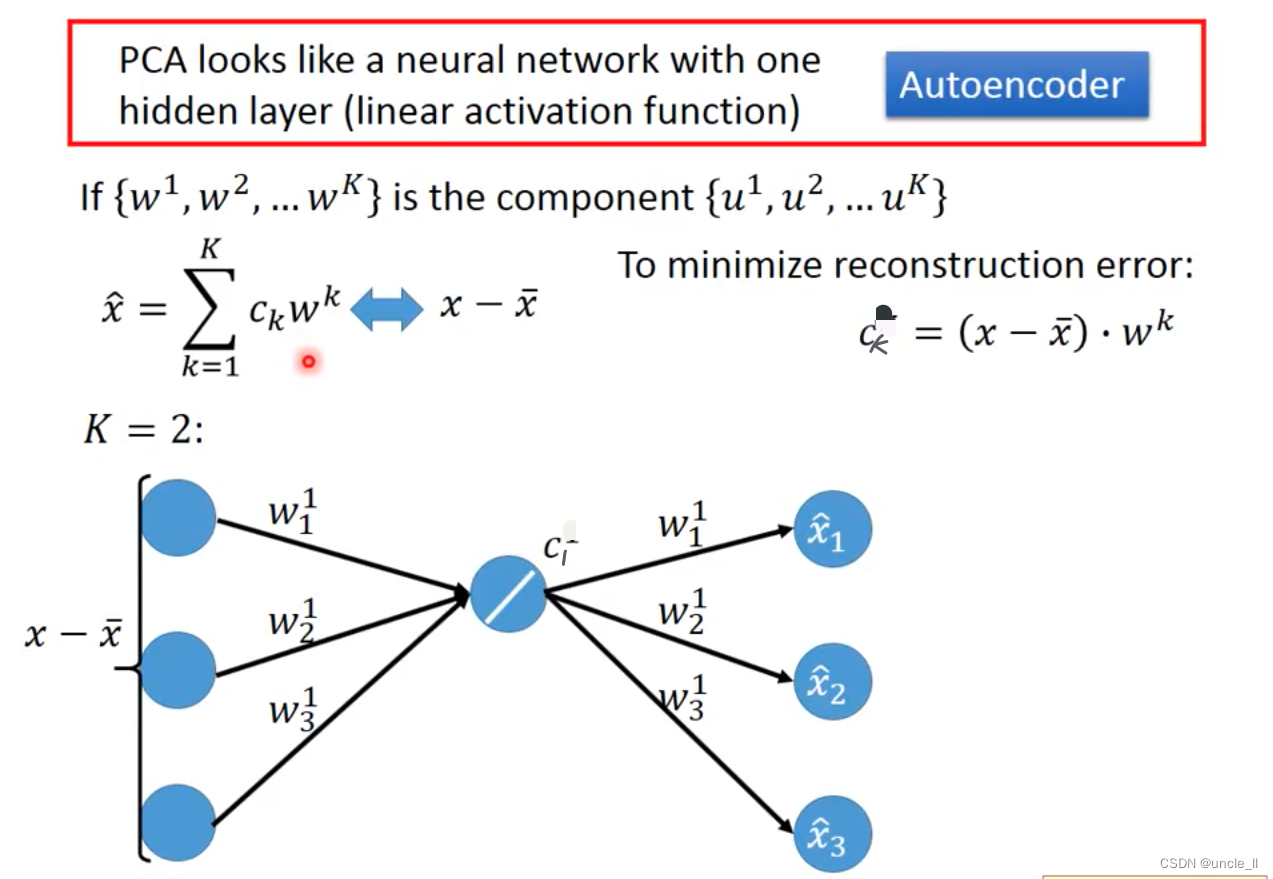
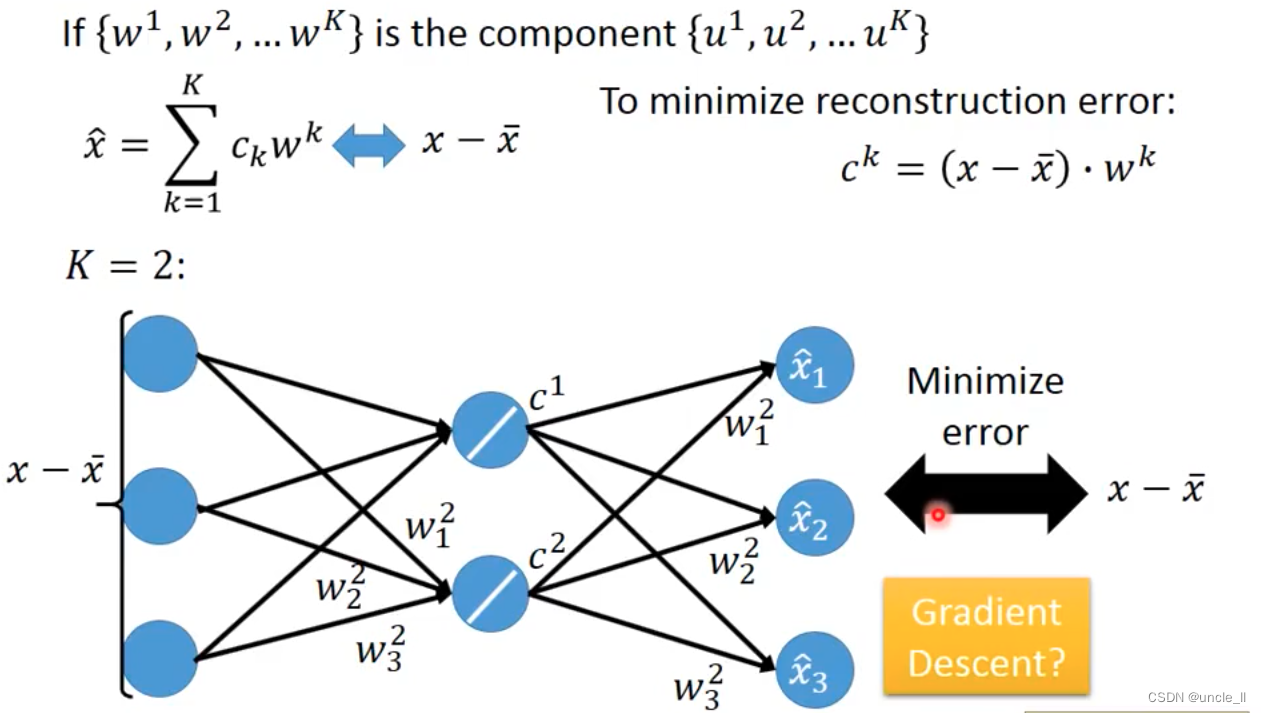
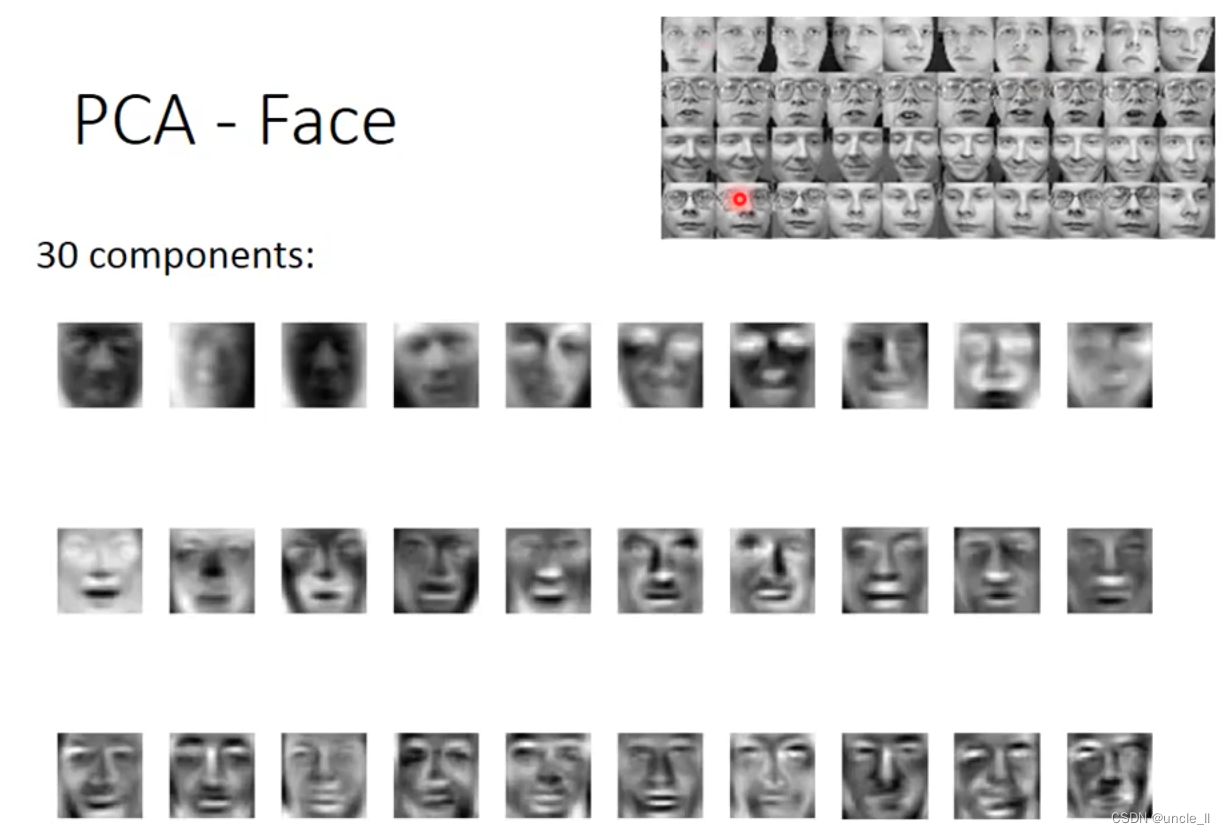
PCA
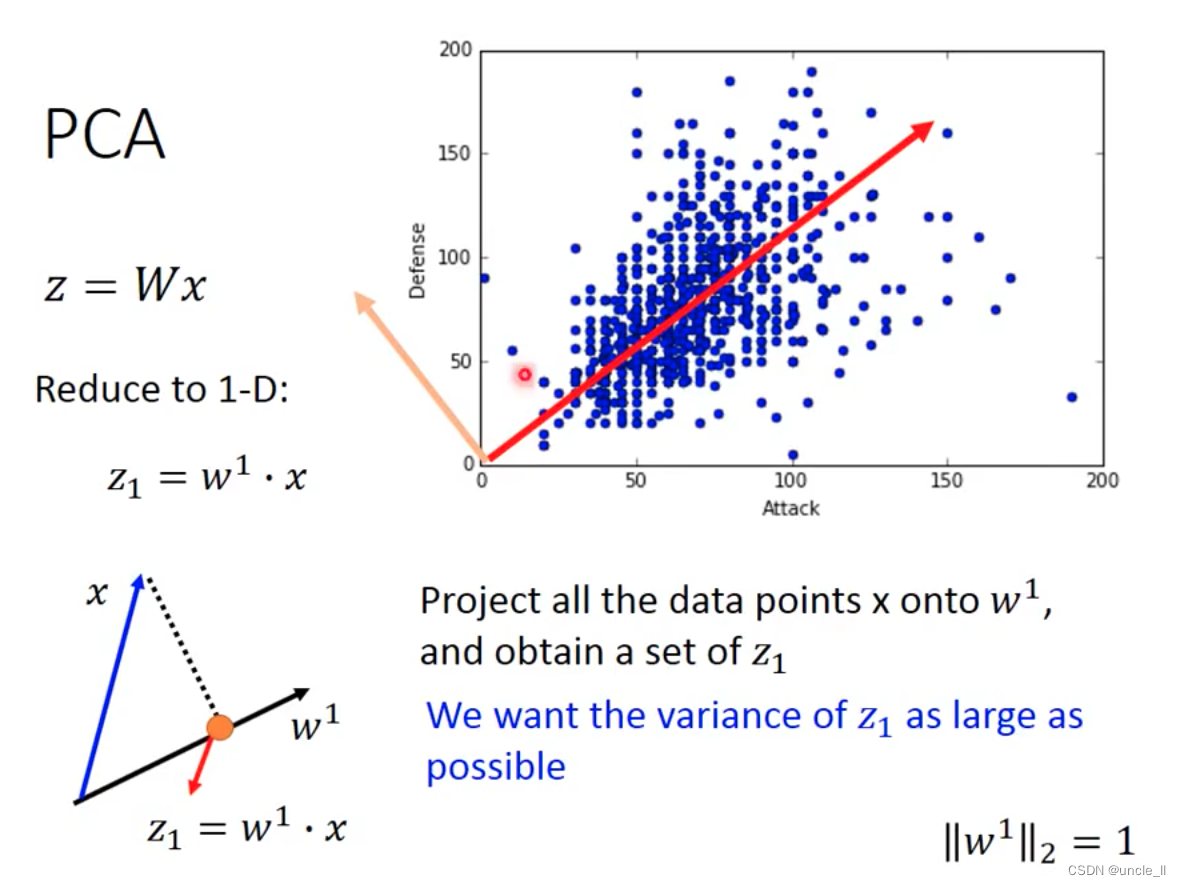
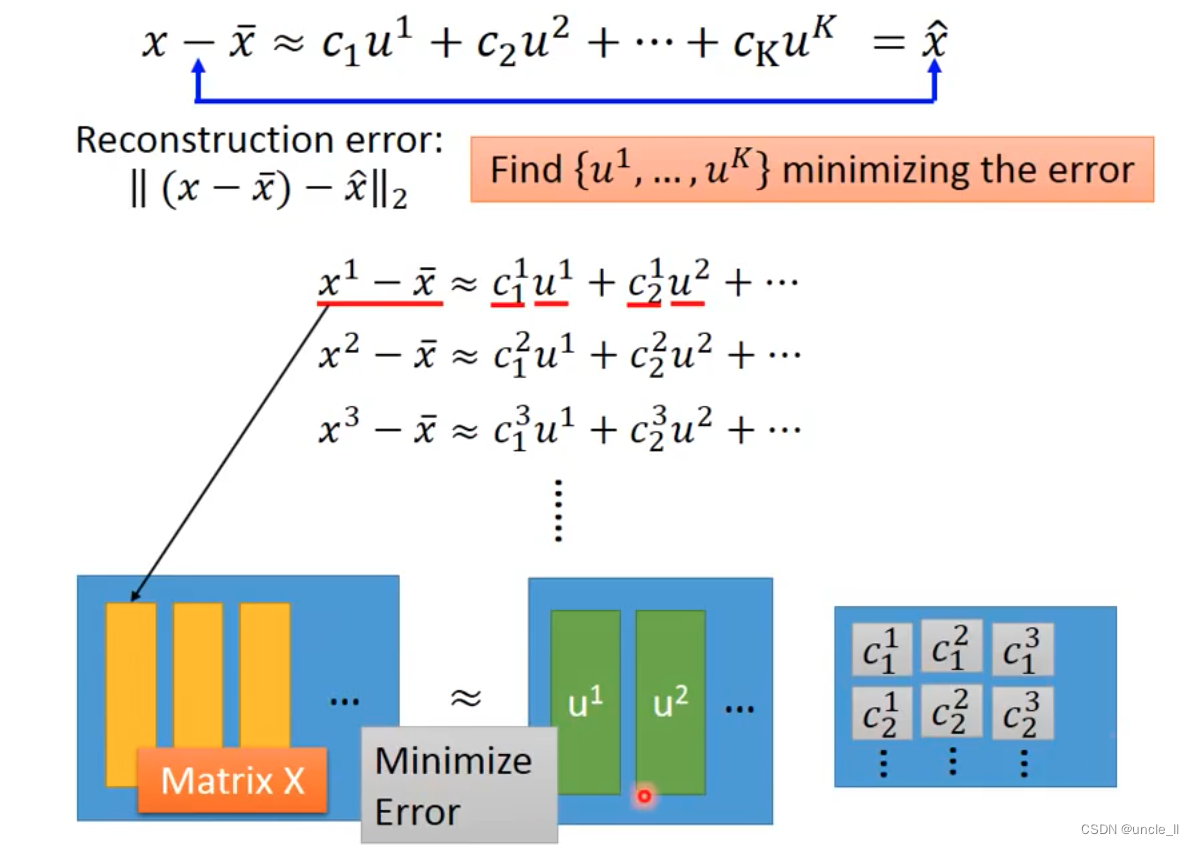
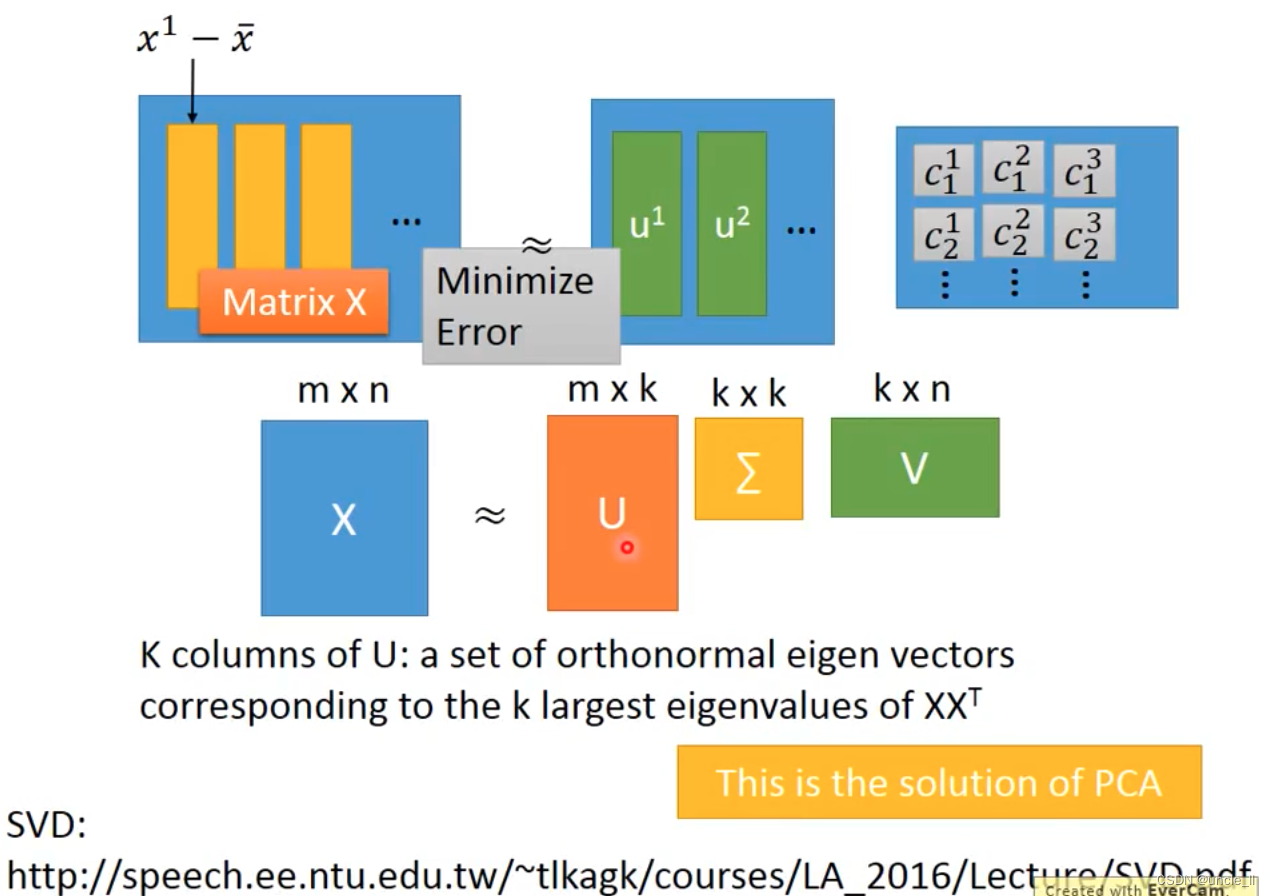
特征先归一化,然后计算投影,选择最大的方差的
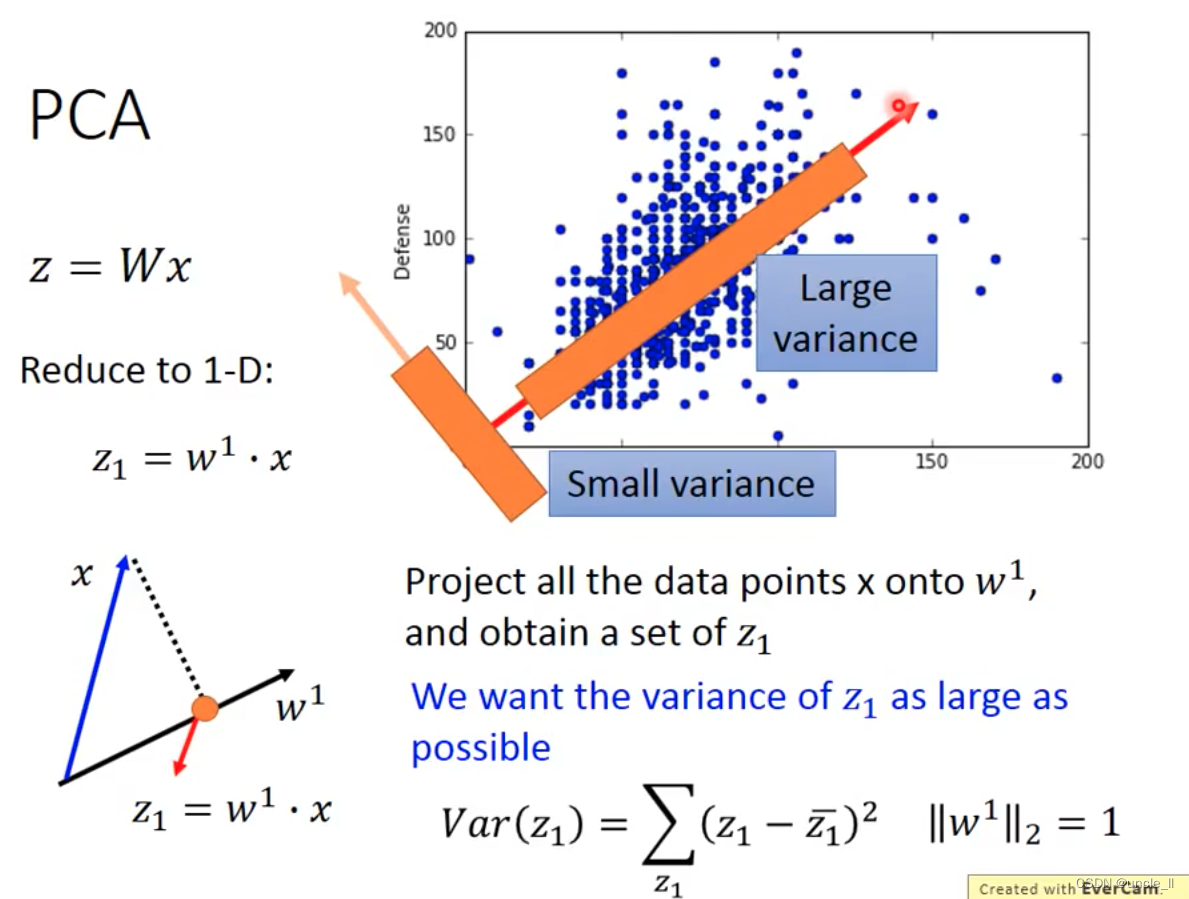
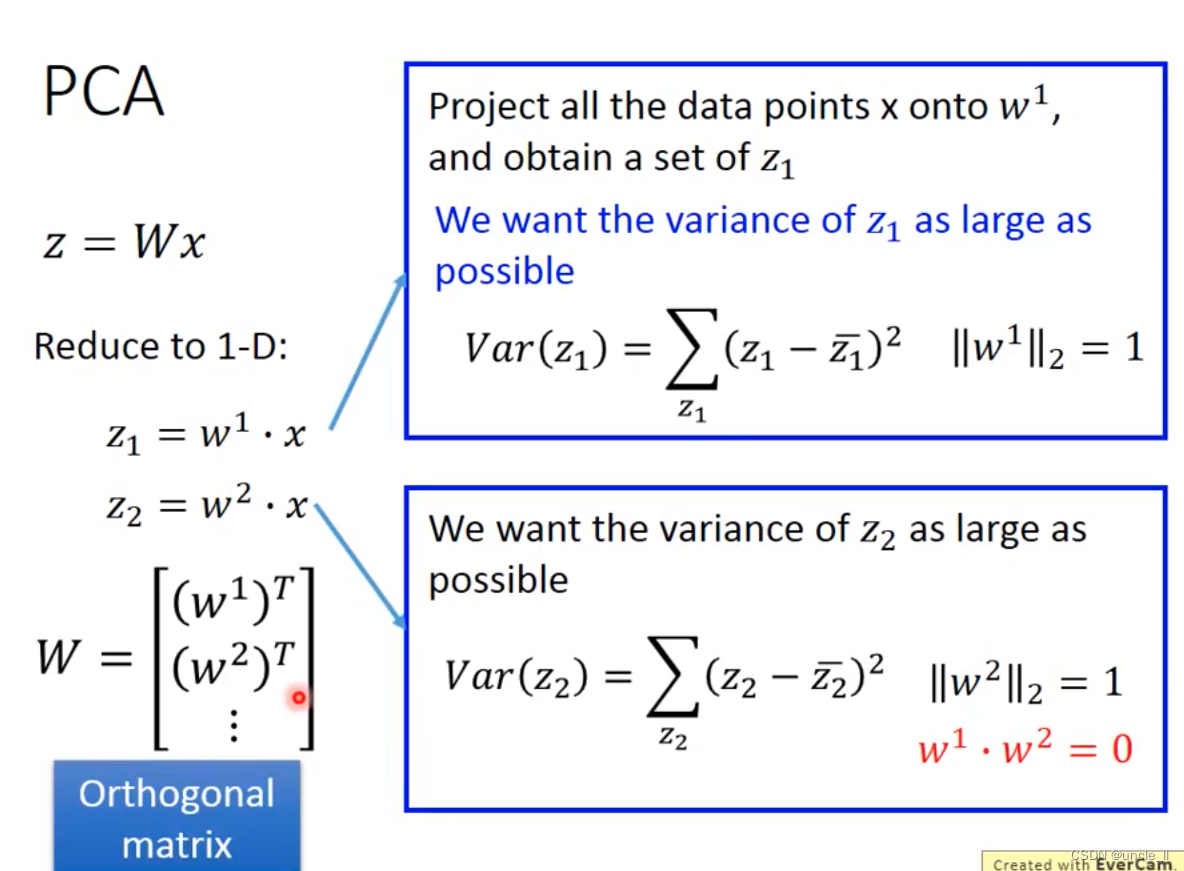
w 1 w_1 w1 与 w 2 w_2 w2是垂直的,后续也是找垂直于它们的 w 3 w_3 w3 …看需要多少维。


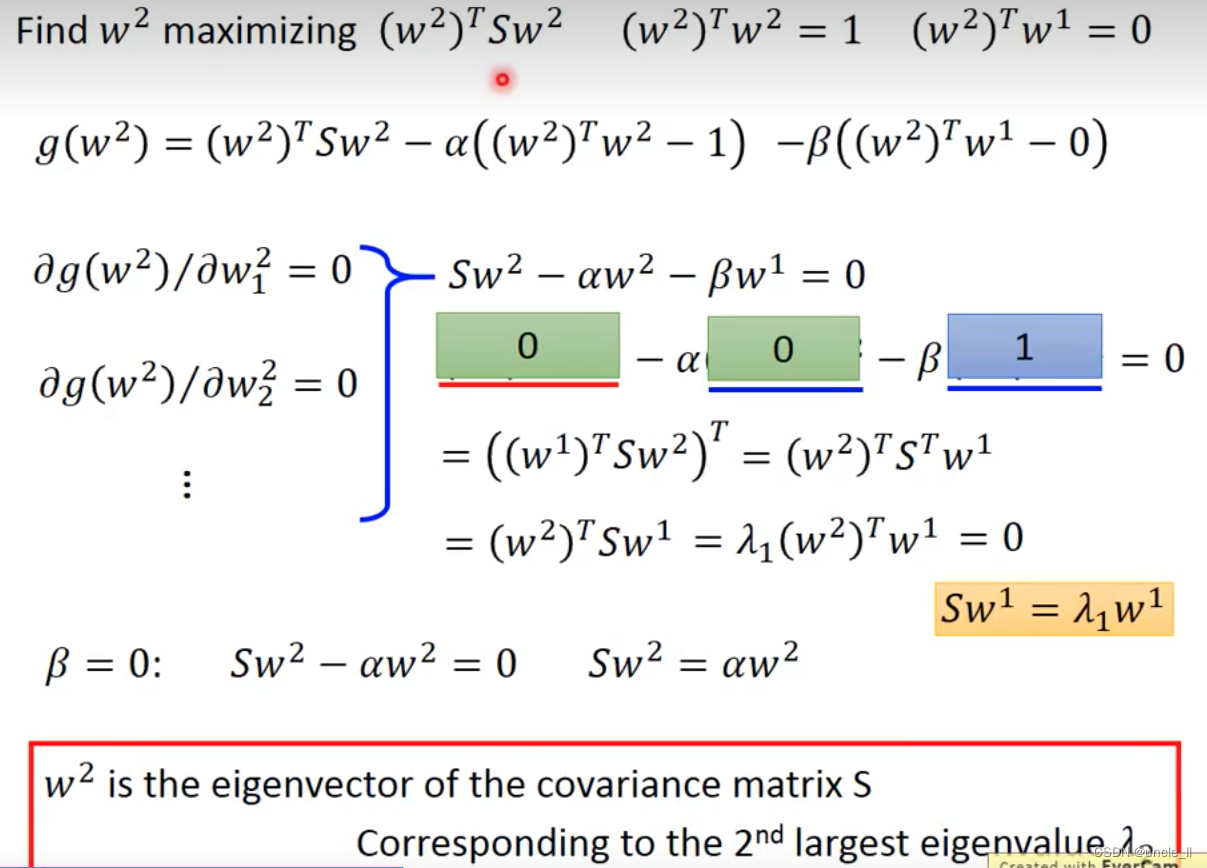
w 1 w1 w1就是最大的特征向量。然后找下一个 w 2 w2 w2

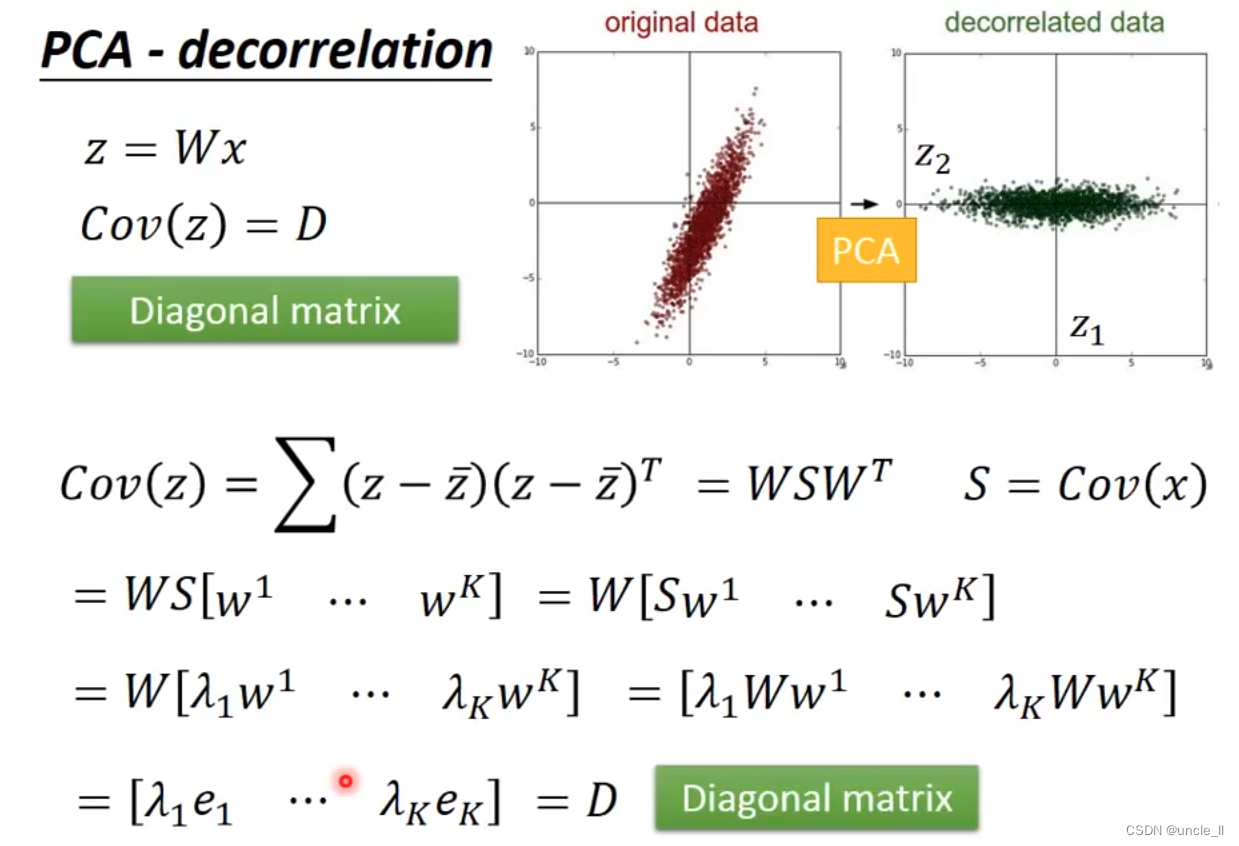
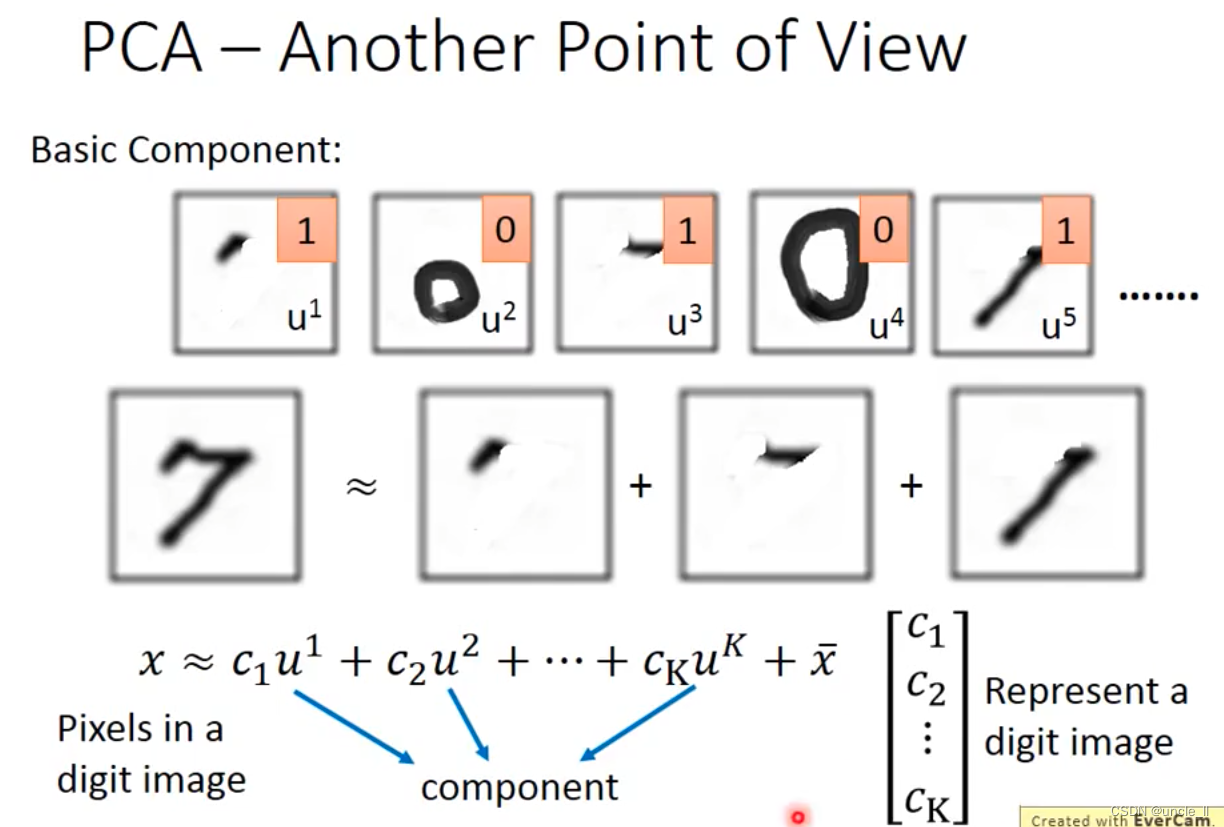
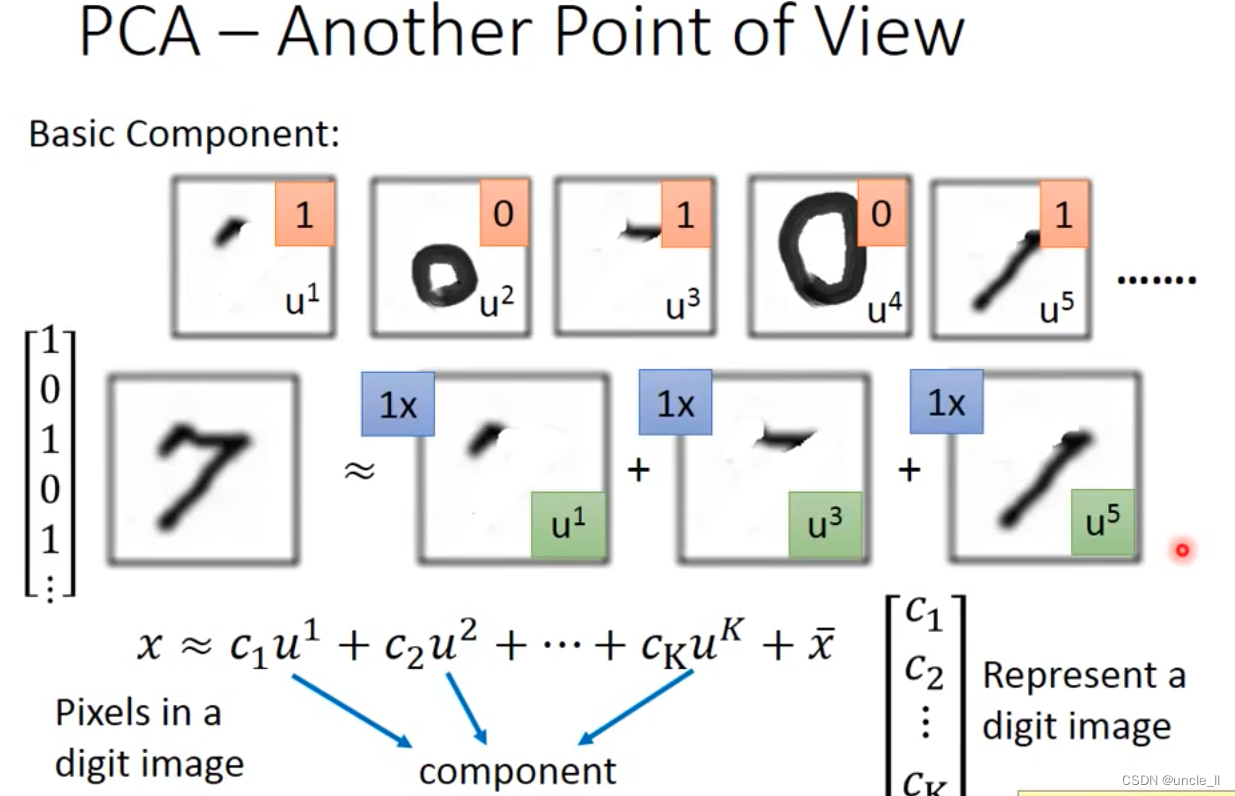
基本的内容组成,直线,点,斜线,圆圈等。一个数字就能用这些进行表示:



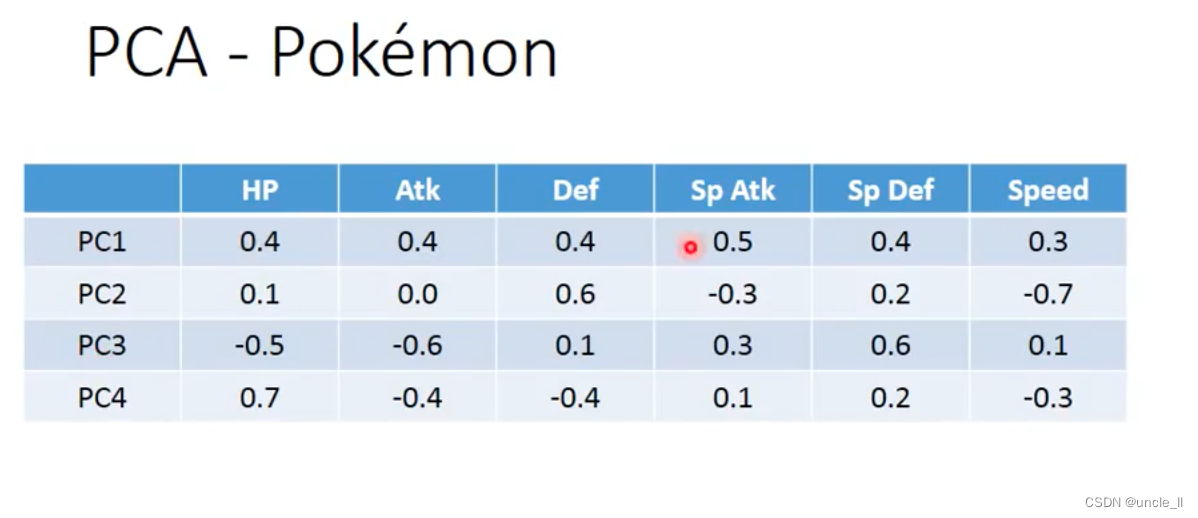
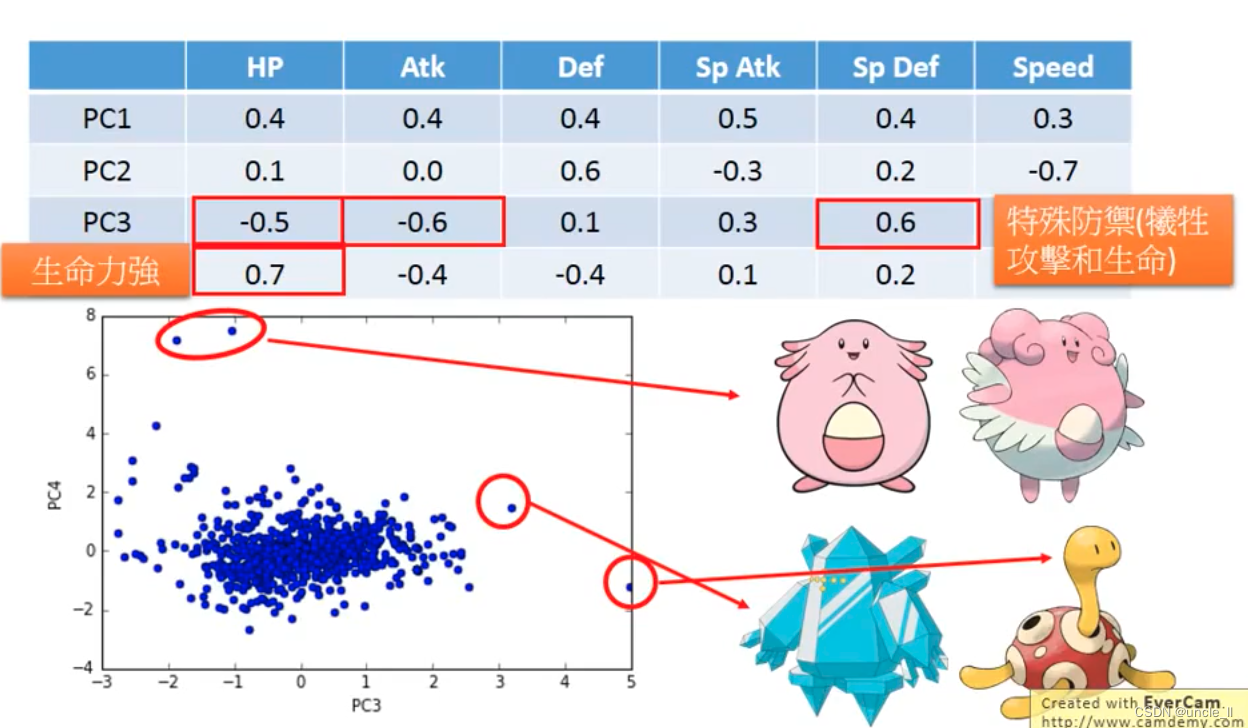
在强度,生命力,攻击力等方面各有侧重




Matrix Factorization
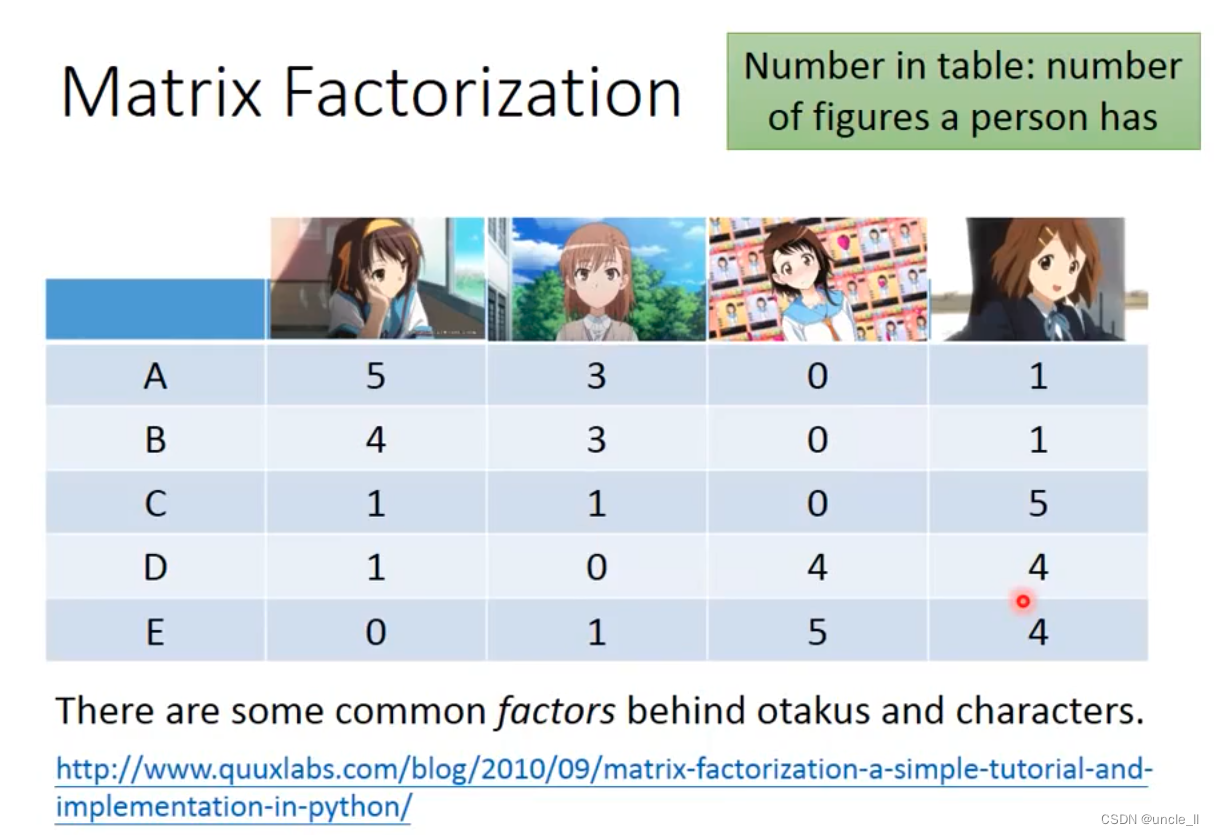
元素之间有些相同的特点。
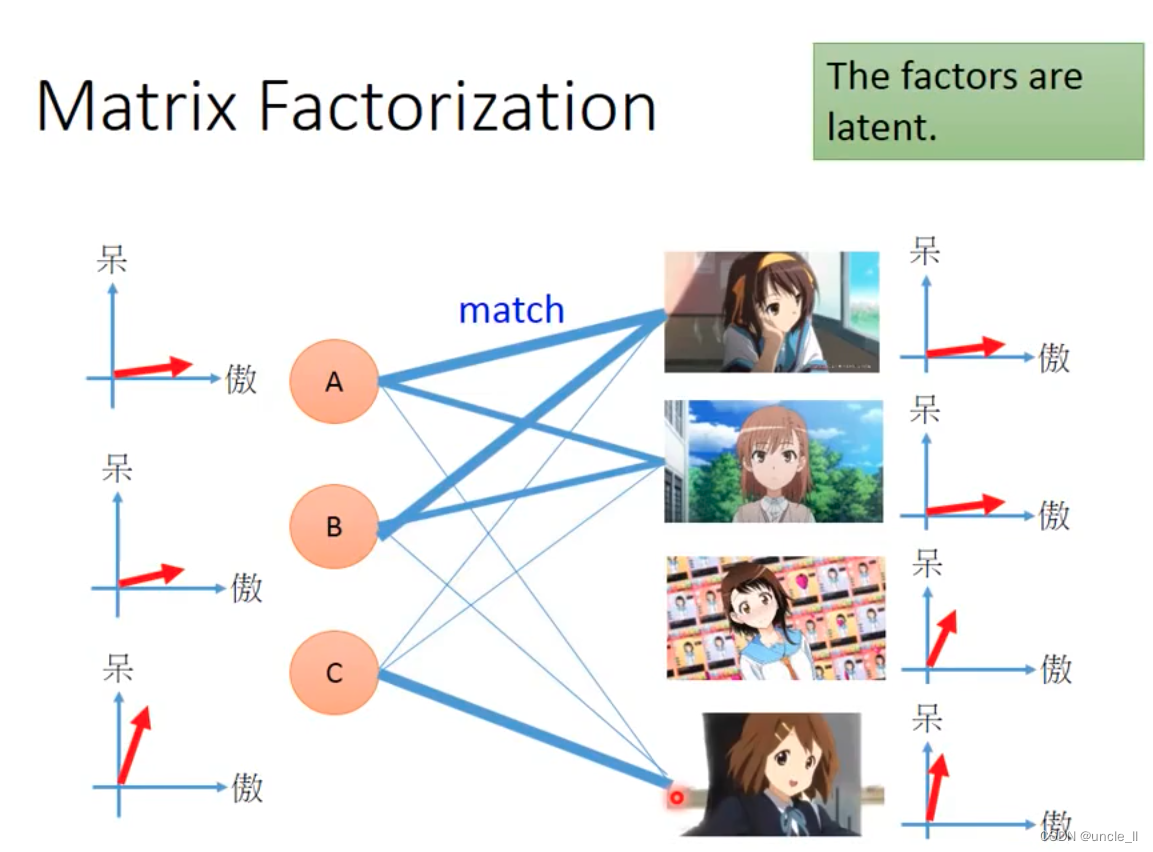
这些事情是没有人知道的。
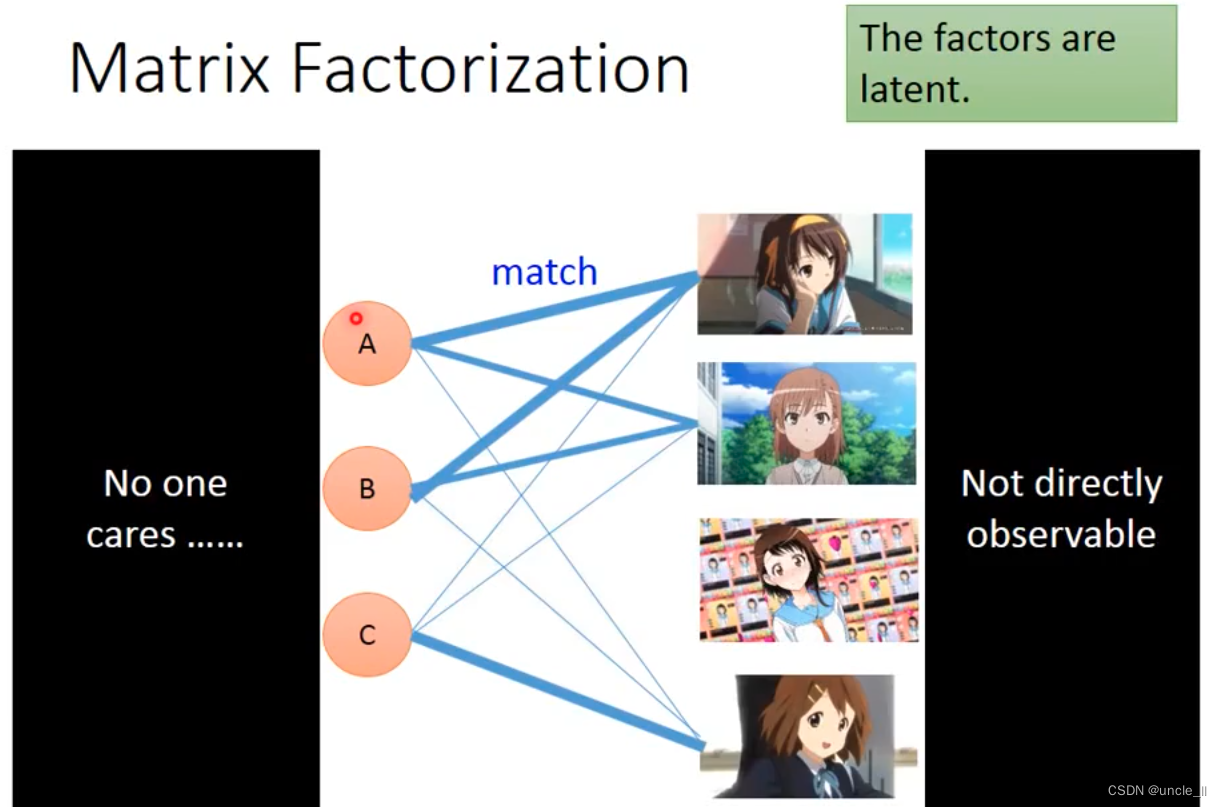
有的是只有这种关系矩阵,如果基于这些关系推断出关系:
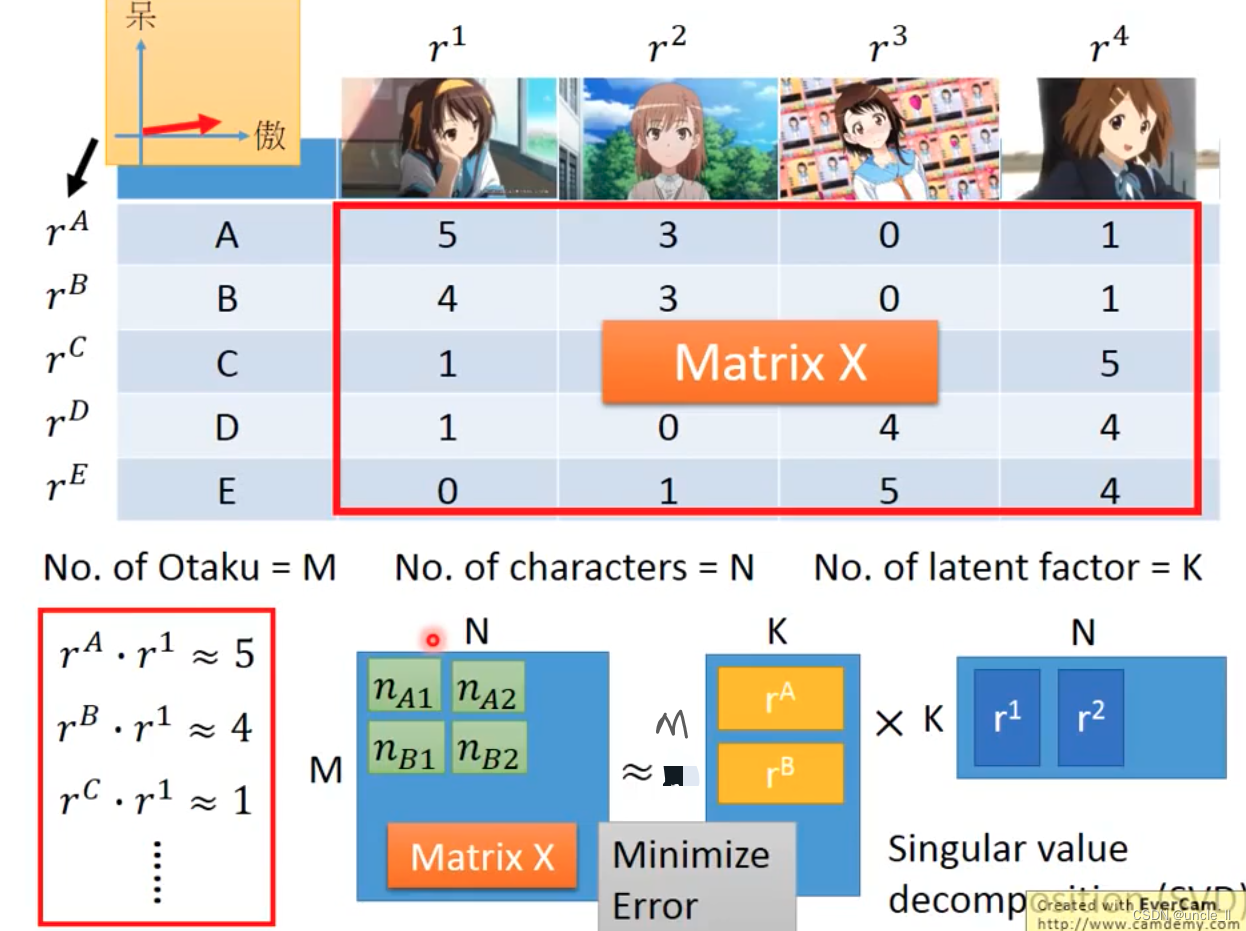
可以将这个进行矩阵分解,得到两个向量相乘,但是会存在那种缺失值的话,可以考虑使用梯度下降方法:

只考虑有定义的值。
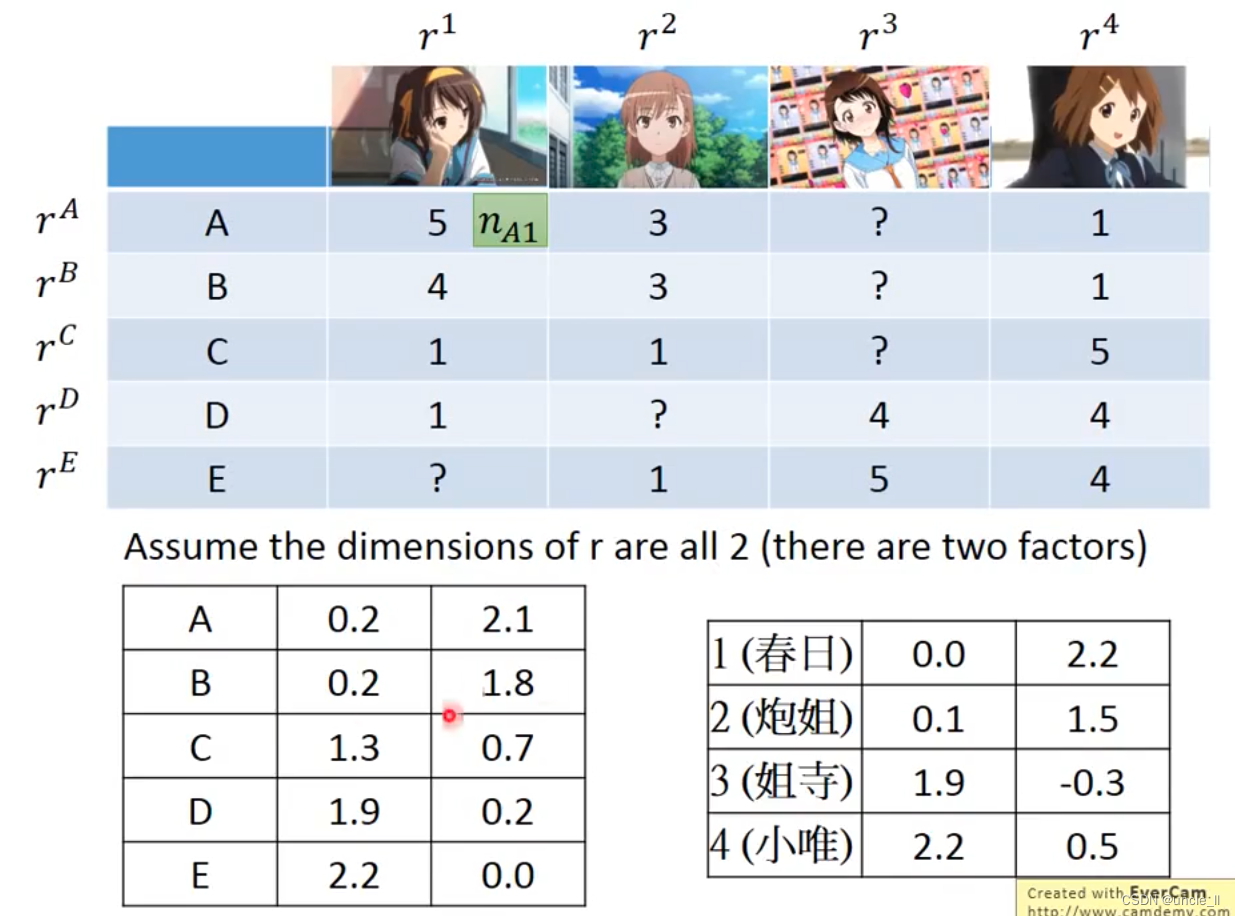
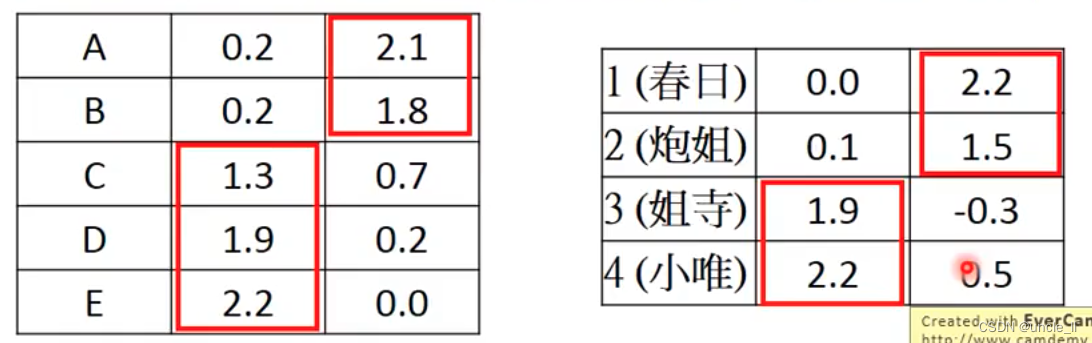
就可以预测缺失的值,然后就能判断每个人对某个物体的喜好程度,填充:
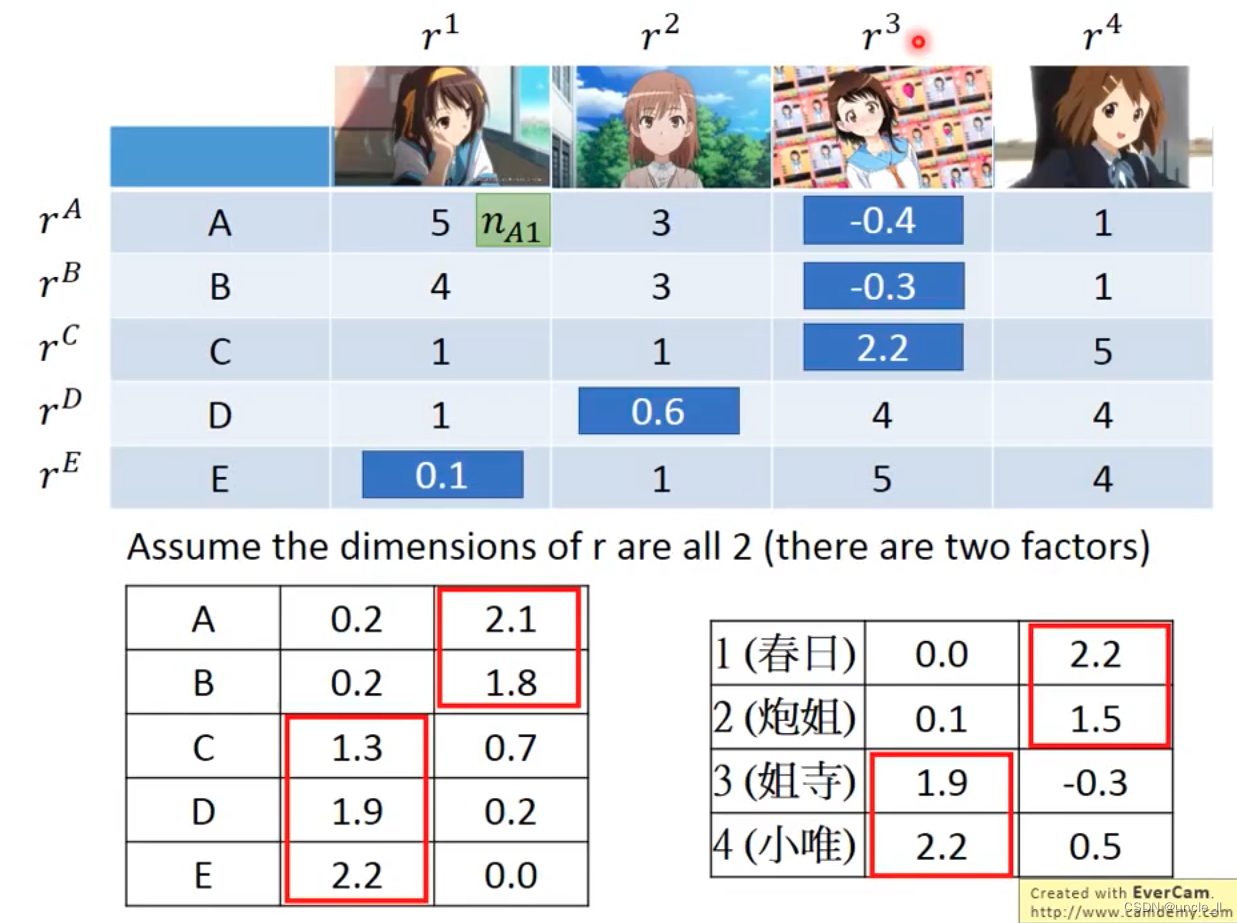
该算法可以用于推荐系统。

可以考虑通过梯度下降算法硬解一下。
MF也可以用于主题分析,LSA


Manifold Learning
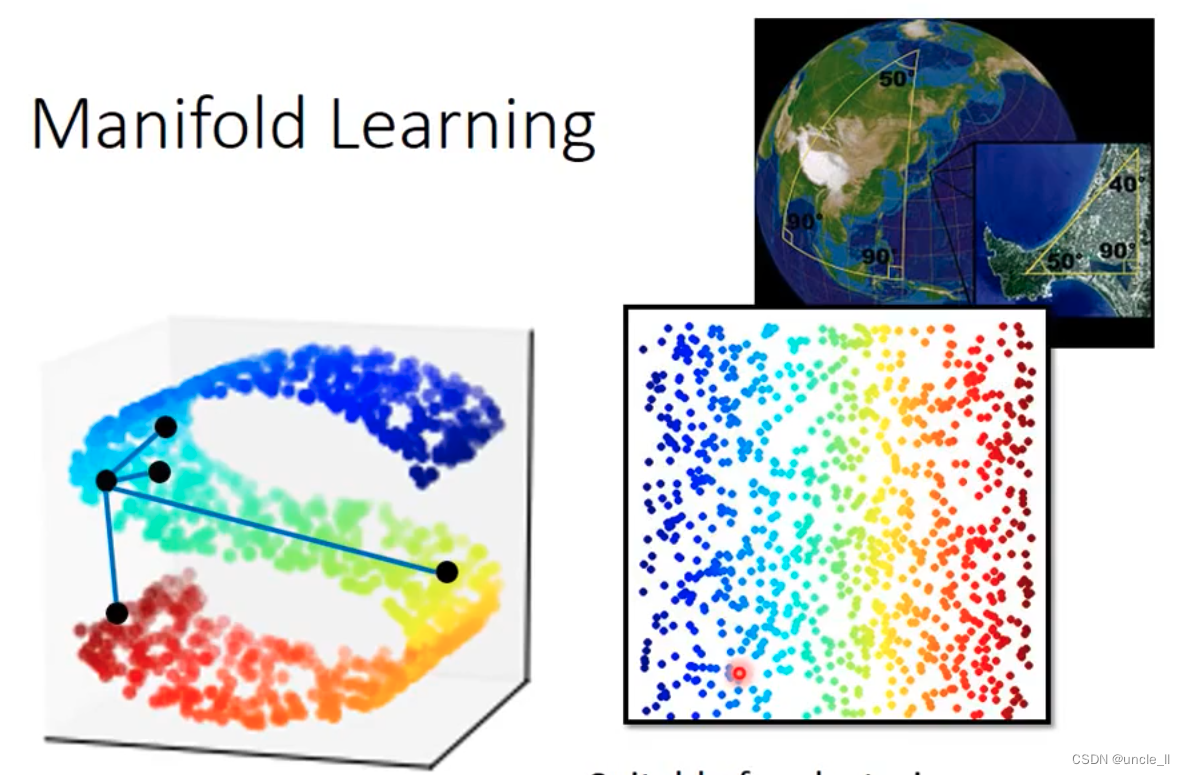
从立体变成2d
LLE
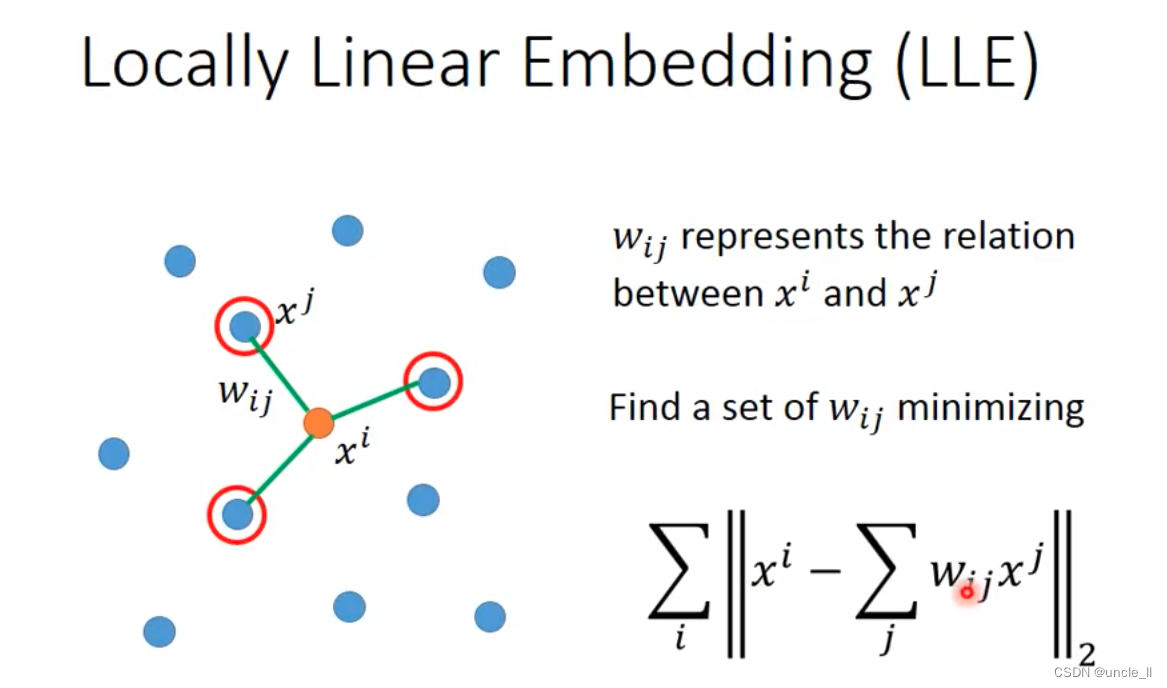


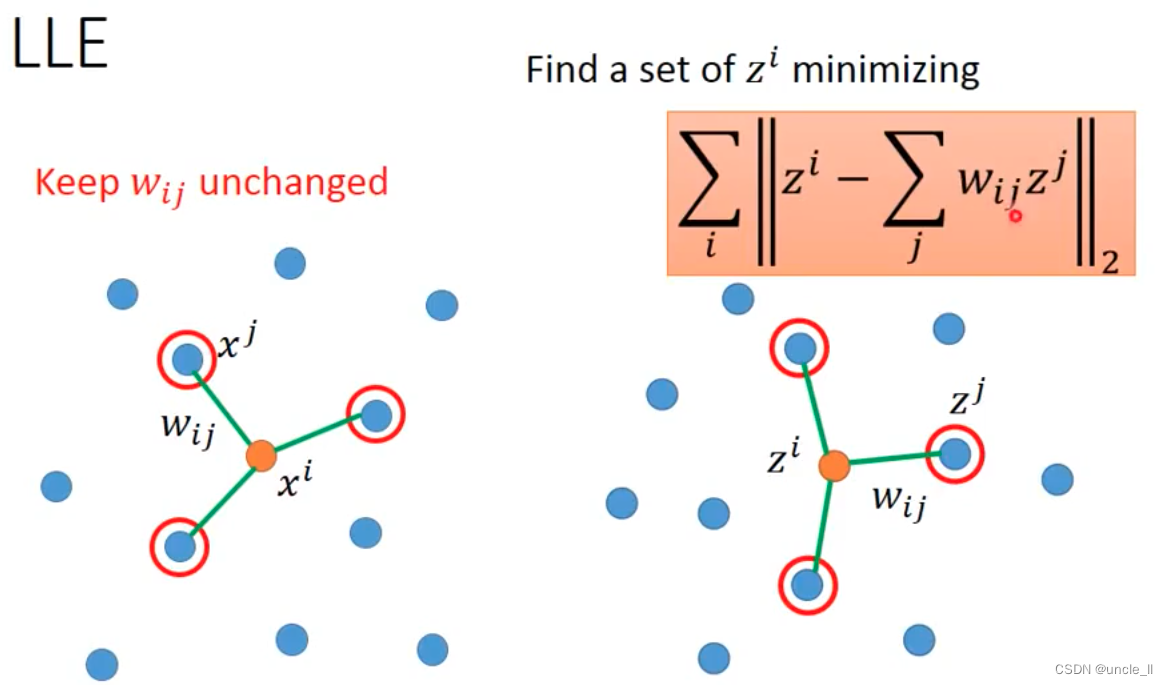
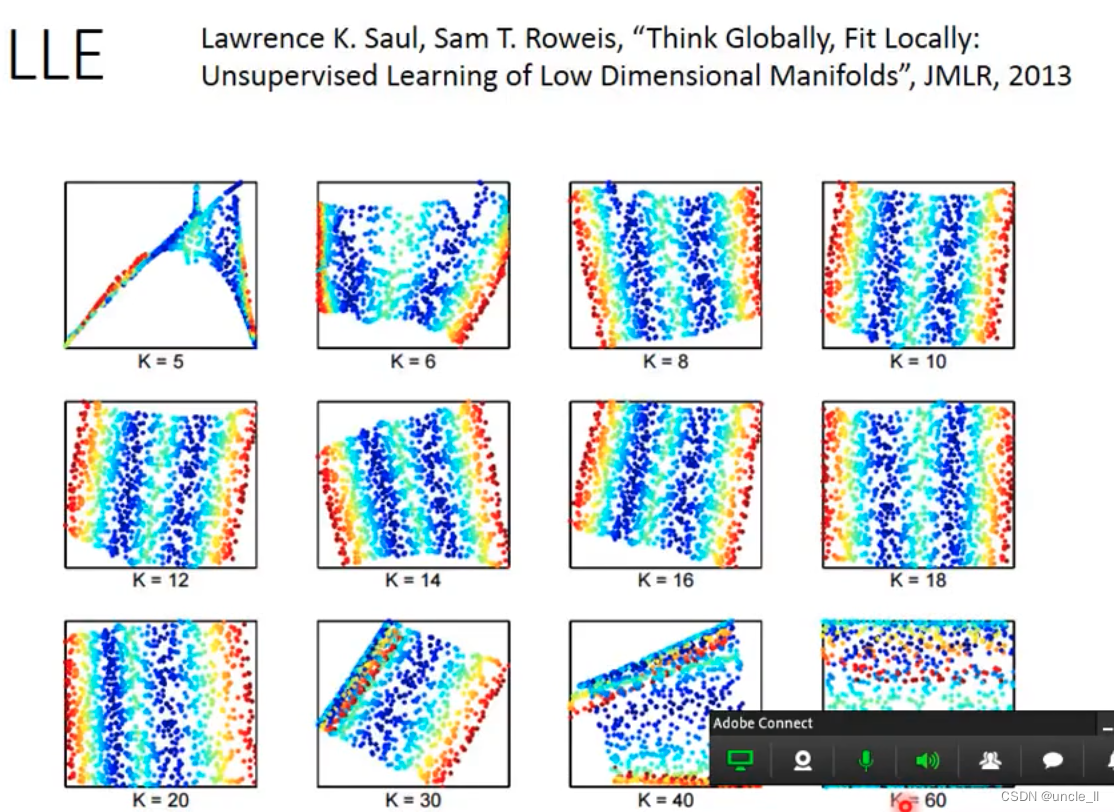
Laplacian Eigenmaps


t-SEN

coil-20数据

两个分布越接近越好,KL散度,对这个问题做梯度下降的。
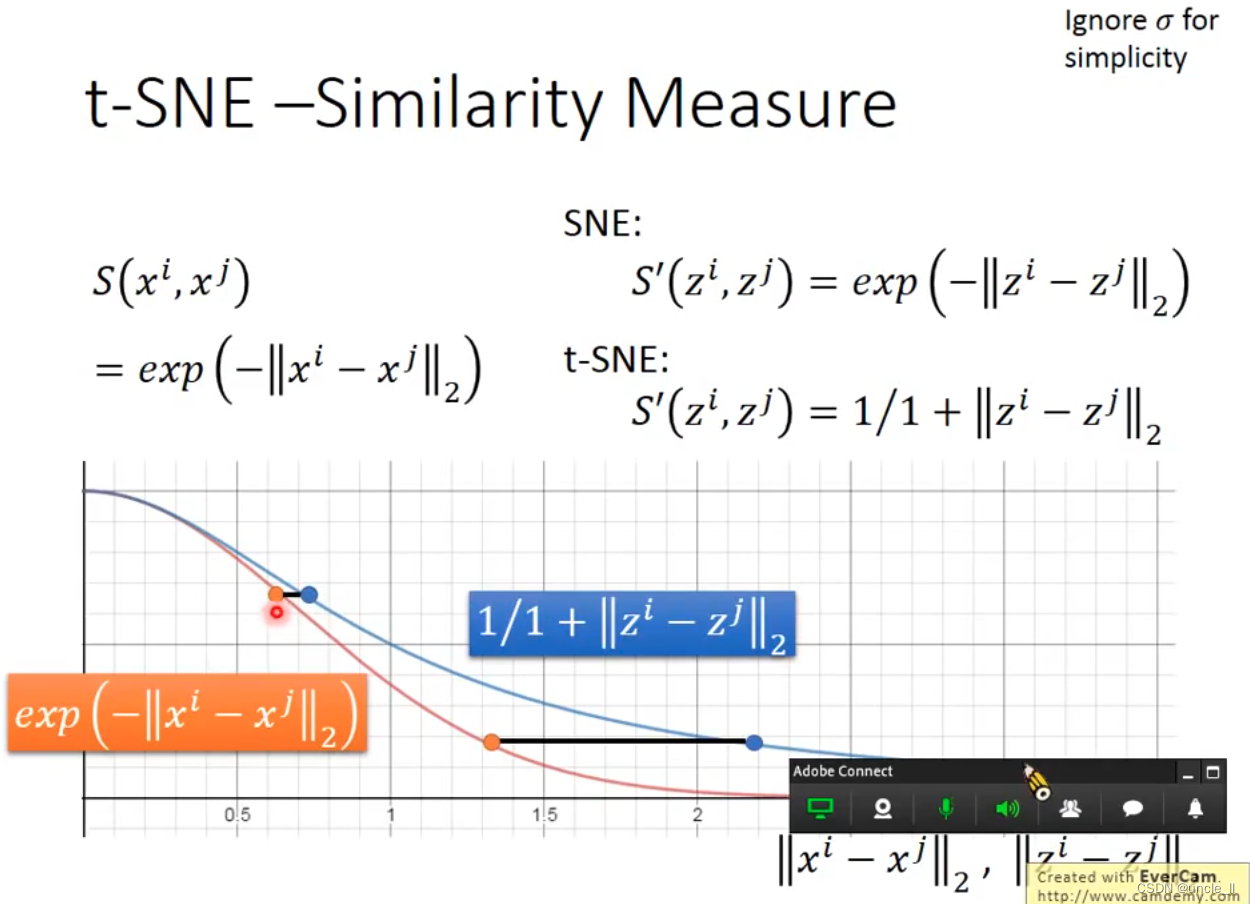
这种相似度计算方式会维持原来的距离。