织梦网站自动跳转手机网站百度热门关键词
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501
提到函数,大家会想到数学函数吧,函数是数学最重要的一个模块,贯穿整个数学学习过程。在Python中,函数的应用非常广泛。在前面我们已经多次接触过函数。例如,用于输出的print()函数、用于输入的input()函数及用于生成一系列整数的range()函数,这些都是Python内置的标准函数,可以直接使用。除了可以直接使用的标准函数外,Python还支持自定义函数。即通过将一段有规律的、重复的代码定义为函数,来达到一次编写、多次调用的目的。使用函数可以提高代码的重复利用率。
1 创建一个函数
创建函数也称为定义函数,可以理解为创建一个具有某种用途的工具。使用def关键字实现,具体的语法格式如下:
def functionname([parameterlist]):
['''comments''']
[functionbody]
参数说明:
l functionname:函数名称,在调用函数时使用。
l parameterlist:可选参数,用于指定向函数中传递的参数。如果有多个参数,各参数间使用逗号“,”分隔。如果不指定,则表示该函数没有参数,在调用时也不指定参数。
注意:即使函数没有参数,也必须保留一对空的“()”,否则将显示如图1所示的错误提示对话框。
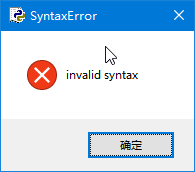
图1 语法错误对话框
l '''comments''':可选参数,表示为函数指定注释,注释的内容通常是说明该函数的功能、要传递的参数的作用等,可以为用户提供友好提示和帮助的内容。
说明:在定义函数时,如果指定了'''comments'''参数,那么在调用函数时,输入函数名称及左侧的小括号时,就会显示该函数的帮助信息,如图2所示。这些帮助信息就是通过定义的注释提供的。
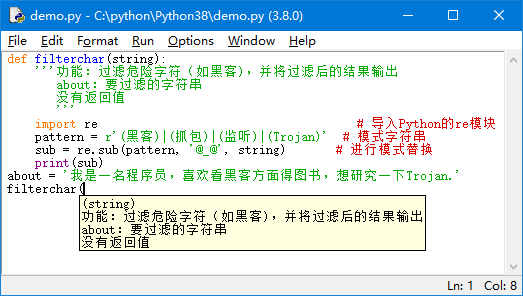
图2 调用函数时显示友好提示
注意:如果在输入函数名和左侧括号后,没有显示友好提示,那么就检查函数本身是否有误,检查方法可以是在未调用该方法时,先按下快捷键<F5>执行一遍代码。
l functionbody:可选参数,用于指定函数体,即该函数被调用后,要执行的功能代码。如果函数有返回值,可以使用return语句返回。
注意:函数体“functionbody”和注释“'''comments'''”相对于def关键字必须保持一定的缩进。
说明:如果想定义一个什么也不做的空函数,可以使用pass语句作为占位符。
例如,定义一个过滤危险字符的函数filterchar(),代码如下:
def filterchar(string):
'''功能:过滤危险字符(如黑客),并将过滤后的结果输出
about:要过滤的字符串
没有返回值
'''
import re # 导入Python的re模块
pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' # 模式字符串
sub = re.sub(pattern, '@_@', string) # 进行模式替换
print(sub)
运行上面的代码,将不显示任何内容,也不会抛出异常,因为filterchar()函数还没有被调用。
2 调用函数
调用函数也就是执行函数。如果把创建的函数理解为创建一个具有某种用途的工具,那么调用函数就相当于使用该工具。调用函数的基本语法格式如下:
functionname([parametersvalue])
参数说明:
l functionname:函数名称,要调用的函数名称必须是已经创建好的。
l parametersvalue:可选参数,用于指定各个参数的值。如果需要传递多个参数值,则各参数值间使用逗号“,”分隔。如果该函数没有参数,则直接写一对小括号即可。
例如,调用在6.1.1小节创建的filterchar()函数,可以使用下面的代码:
about = '我是一名程序员,喜欢看黑客方面的图书,想研究一下Trojan。'
filterchar(about)
调用filterchar()函数后,将显示如图3所示的结果。

图3 调用filterchar()函数的结果
场景模拟:第4章的实例01实现了每日一帖功能,但是这段代码只能执行一次,如果想要再次输出,还需要再重新写一遍。如果把这段代码定义为一个函数,那么就可以多次显示每日一帖了。
![]()
实例01 输出每日一帖(共享版)
在IDLE中创建一个名称为function_tips.py的文件,然后在该文件中创建一个名称为function_tips的函数,在该函数中,从励志文字列表中获取一条励志文字并输出,最后再调用函数function_tips(),代码如下:
def function_tips():
'''功能:每天输出一条励志文字
'''
import datetime # 导入日期时间类
# 定义一个列表
mot = ["今天星期一:\n坚持下去不是因为我很坚强,而是因为我别无选择",
"今天星期二:\n含泪播种的人一定能笑着收获",
"今天星期三:\n做对的事情比把事情做对重要",
"今天星期四:\n命运给予我们的不是失望之酒,而是机会之杯",
"今天星期五:\n不要等到明天,明天太遥远,今天就行动",
"今天星期六:\n求知若饥,虚心若愚",
"今天星期日:\n成功将属于那些从不说“不可能”的人"]
day = datetime.datetime.now().weekday() # 获取当前星期
print(mot[day]) # 输出每日一帖
# *****************************调用函数***********************************#
function_tips() # 调用函数
运行结果如图4所示。
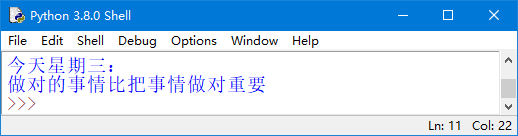
图4 调用函数输出每日一帖
