网站信息设计平面设计软件大全免费
2. 后端服务器部分
2.1 服务器分析
2.2 代码编写
2.2.2 前端发起一个ajax请求
2.2.3 服务器读取上述请求,并计算出响应
服务器需要使用 jackson 读取到前端这里的数据,并且进行解析:
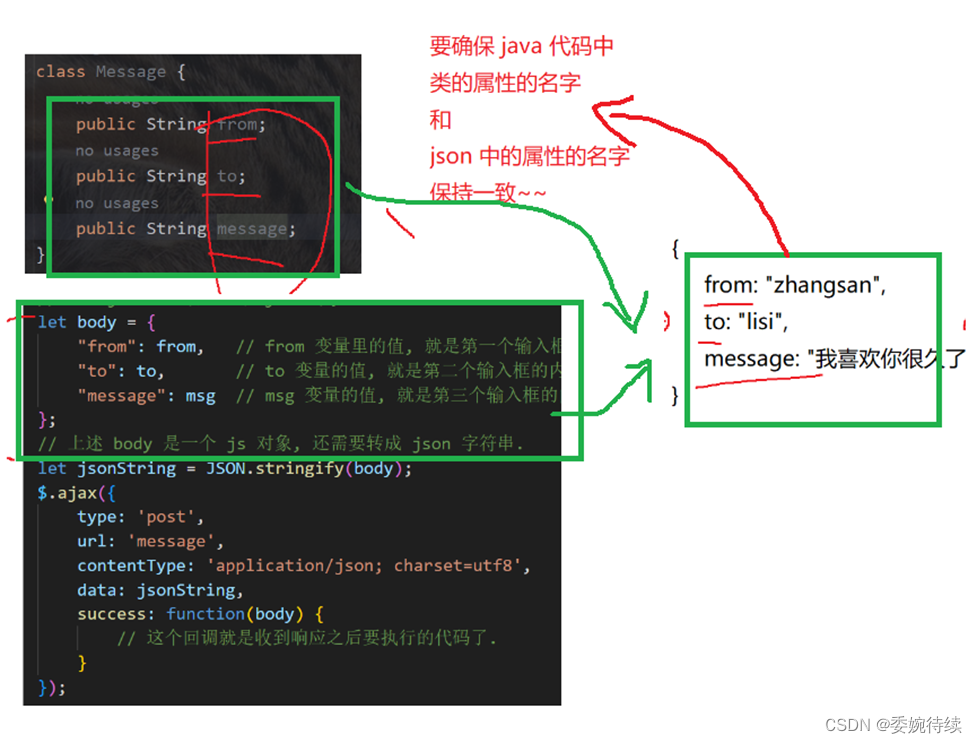
代码运行图:
2.2.4 回到前端代码,处理服务器返回的响应
1、对服务器的响应做出反应

此处 success 回调函数,不是立即执行的,而是在浏览器收到服务器返回的成功这样的响应的时候,才会执行到 function,这个函数的第一个参数,就是响应数据的 body 中的内容,如下所示:
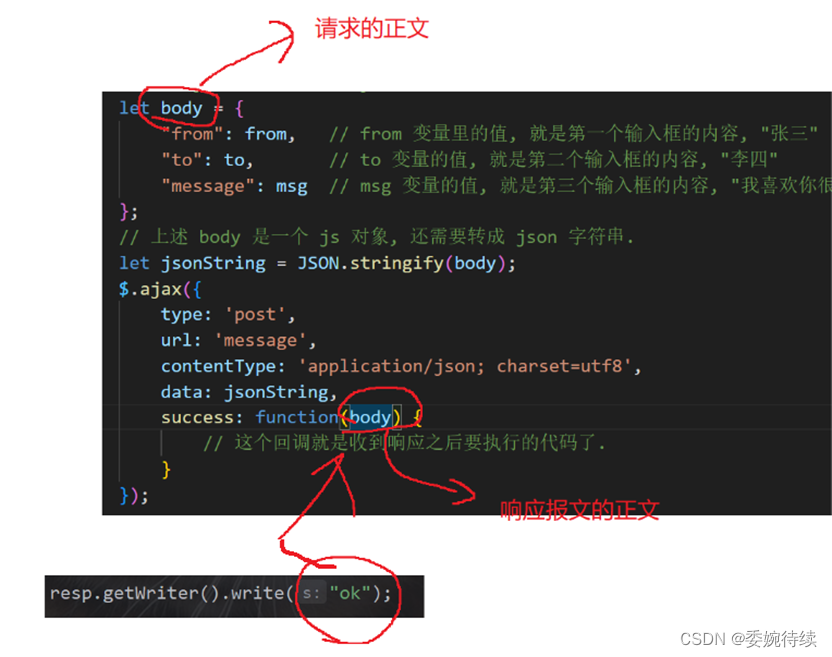
为了和请求对应上,一般服务器返回的数据,也会按照 json 格式来组织,代码如下所示:

当前浏览器和服务器所实现的效果如下:

服务器收到的请求:

浏览器收到的响应:
![]()
当前数据已经被提交到服务器保存了,目前还需要能够把服务器的数据拿回到客户端页面上并显示;
2、把服务器的数据拿回到客户端页面上,并显示;
至于为啥还要从服务器拿消息?
(1、当前页面上显示的数据,也是在浏览器内存中保存的,刷新页面/关闭了重新打开,之前的数据就没了
(2、其他的客户端打开页面也是有数据的.
编写代码步骤如下:
1)客户端在页面加载的时候,发起一个 http 请求
$.ajax({type: 'get', url: 'message',success: function(body) { //处理服务器返回来的数据,使用json格式的数组});2)服务器收到这个请求,要处理这个请求并生成响应,
服务器收到的每条消息,都转成了 Message 对象,放到上述 List 中了,返回的结果, 也就是这个 List 的数据.,需要把 List 里的每个 Message 取出来, 转成json 字符串,最终拼到一起,得到了响应结果;
注意:jackson 本身就支持把 List 类型的数据转成json 数组
jackson 看到了 messagelist 是一个 List 类型,转成的json 字符串就是一个json 数组,
jackson 自动遍历 List 里的每个元素,把每个元素,分别都转成 json 字符串;这一部分代码如下:
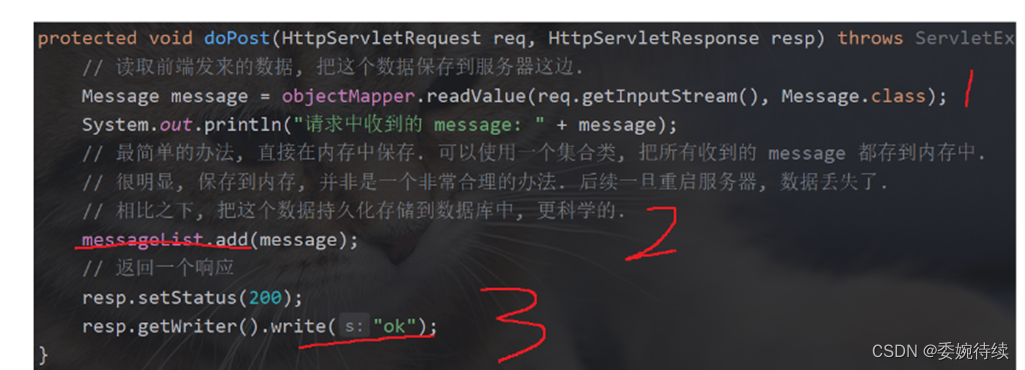
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {// 通过这个方法来处理当前获取消息列表的 get 请求. 不需要解析参数, 直接返回数据即可.resp.setStatus(200);resp.setContentType("application/json; charset=utf8");// 从数据库查询List<Message> messageList = null;try {messageList = load();} catch (SQLException e) {throw new RuntimeException(e);}String respJson = objectMapper.writeValueAsString(messageList);resp.getWriter().write(respJson);}确保这几个代码的执行顺序:
setStatus 和 setContentType 必须在 getWriter 前面,否则可能不会生效(构造出一个非法的 http 响应报文)
3)、客户端收到响应,就需要针对响应数据进行解析处理,把响应中的信息,构造成页面元素,并显示出来.
上图中body 就是服务器返回的响应,即数据中 json 格式的数组;当响应中, header 带有 Content-Type: application/ison,jquery 就会自动的把 json字符串, 解析成js 对象了。
如果没有带 Content-Type: application/json,就需要通过js 代码 JSON.parse 方法来手动把 json 字符申转成js 对象;
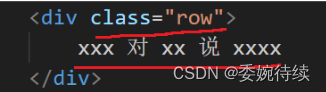
我们要构造的内容如下图所示:
将构造出来的上面的这个 div,添加到下面这个 div 的末尾:
html页面上的任何一个元素,都可以用一个js 对象来表示;反之,js 的对象也可以设置到页面中,


3. 把数据存储到数据库中
数据库引入到代码中,主要有一下几个步骤:
1)、引入数据库的依赖
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency>2)、建库建表.建库建表需要用到 sql;
3)、编写数据库代码--->JDBC
后端代码如下所示:
import com.fasterxml.jackson.databind.ObjectMapper;
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.sql.DataSource;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;class Message {public String from;public String to;public String message;@Overridepublic String toString() {return "Message{" +"from='" + from + '\'' +", to='" + to + '\'' +", message='" + message + '\'' +'}';}
}@WebServlet("/message")
public class MessageServlet extends HttpServlet {private ObjectMapper objectMapper = new ObjectMapper();// 引入数据库, 此时 messageList 就不再需要了.// private List<Message> messageList = new ArrayList<>();private DataSource dataSource = new MysqlDataSource();@Overridepublic void init() throws ServletException {// 1. 创建数据源((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/message_wall?characterEncoding=utf8&useSSL=false");((MysqlDataSource) dataSource).setUser("root");((MysqlDataSource) dataSource).setPassword("111111");}@Overrideprotected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {// 读取前端发来的数据, 把这个数据保存到服务器这边.Message message = objectMapper.readValue(req.getInputStream(), Message.class);System.out.println("请求中收到的 message: " + message);// 最简单的办法, 直接在内存中保存. 可以使用一个集合类, 把所有收到的 message 都存到内存中.// 很明显, 保存到内存, 并非是一个非常合理的办法. 后续一旦重启服务器, 数据丢失了.// 相比之下, 把这个数据持久化存储到数据库中, 更科学的.// messageList.add(message);// 插入数据库try {save(message);} catch (SQLException e) {throw new RuntimeException(e);}// 返回一个响应resp.setStatus(200);resp.getWriter().write("ok");// resp.setContentType("application/json");// resp.getWriter().write("{ ok: true }");}@Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {// 通过这个方法来处理当前获取消息列表的 get 请求. 不需要解析参数, 直接返回数据即可.resp.setStatus(200);resp.setContentType("application/json; charset=utf8");// 从数据库查询List<Message> messageList = null;try {messageList = load();} catch (SQLException e) {throw new RuntimeException(e);}String respJson = objectMapper.writeValueAsString(messageList);resp.getWriter().write(respJson);}private void save(Message message) throws SQLException {// 通过这个方法把 message 插入到数据库中// 1. 建立连接Connection connection = dataSource.getConnection();// 2. 构造 SQLString sql = "insert into message values(?, ?, ?)";PreparedStatement statement = connection.prepareStatement(sql);statement.setString(1, message.from);statement.setString(2, message.to);statement.setString(3, message.message);// 3. 执行 SQLstatement.executeUpdate();// 4. 回收资源statement.close();connection.close();}private List<Message> load() throws SQLException {// 通过这个方法从数据库读取到 message.// 1. 建立连接Connection connection = dataSource.getConnection();// 2. 构造 SQLString sql = "select * from message";PreparedStatement statement = connection.prepareStatement(sql);// 3. 执行 sqlResultSet resultSet = statement.executeQuery();// 4. 遍历结果集合List<Message> messageList = new ArrayList<>();while (resultSet.next()) {Message message = new Message();message.from = resultSet.getString("from");message.to = resultSet.getString("to");message.message = resultSet.getString("message");messageList.add(message);}// 5. 回收资源resultSet.close();statement.close();connection.close();// 6. 返回 messageListreturn messageList;}
}
ps:关于表白墙小项目就到这里了,后续如有不足会维持更新的!!!