江苏省建设厅官网网站首页山东网站建设流程
目录
- Ubuntu使用
- 下载
- Ubuntu
- Vmware
- 安装
- 图示
- 安装
- 步骤
- 图示
Ubuntu使用
系统环境:
- Windows 11 22H2
- Vmware 17 Pro
- Ubutun 22.04.3 Server
Ubuntu Server documentation | Ubuntu
下载
Ubuntu
官网下载 建议安装长期支持版本 ——> 可以选择桌面版或服务器版(仅包含命令行) 区别:
- 服务器版
- 空间占用内存小
- 仅命令行
- 桌面版
- 可视化桌面图标
- 与Windows类似操作
- 空间占用内存大

官网服务器版安装教程
Vmware
官网下载
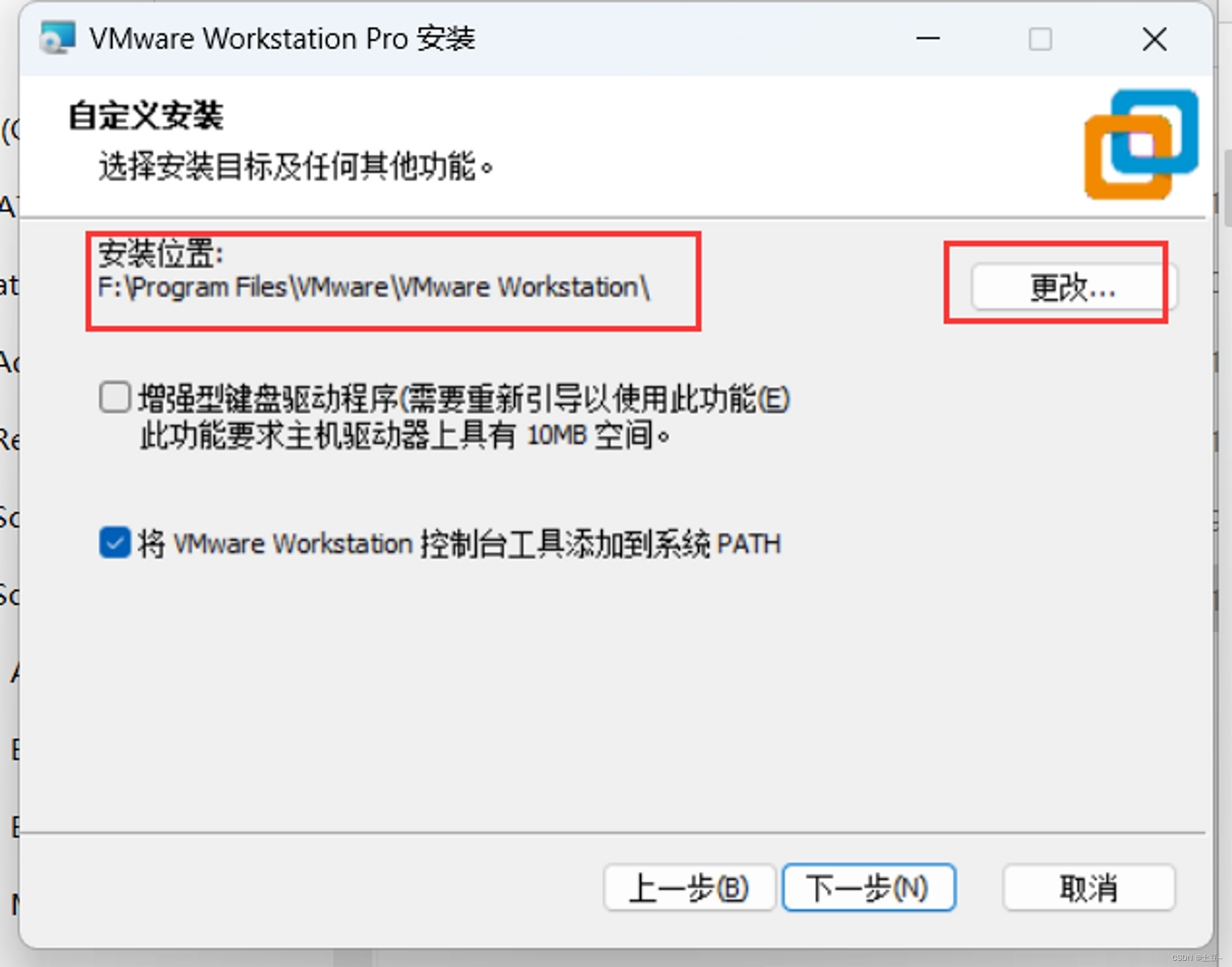
- 开始安装后一直点击下一步,直到自定义安装更改安装位置。
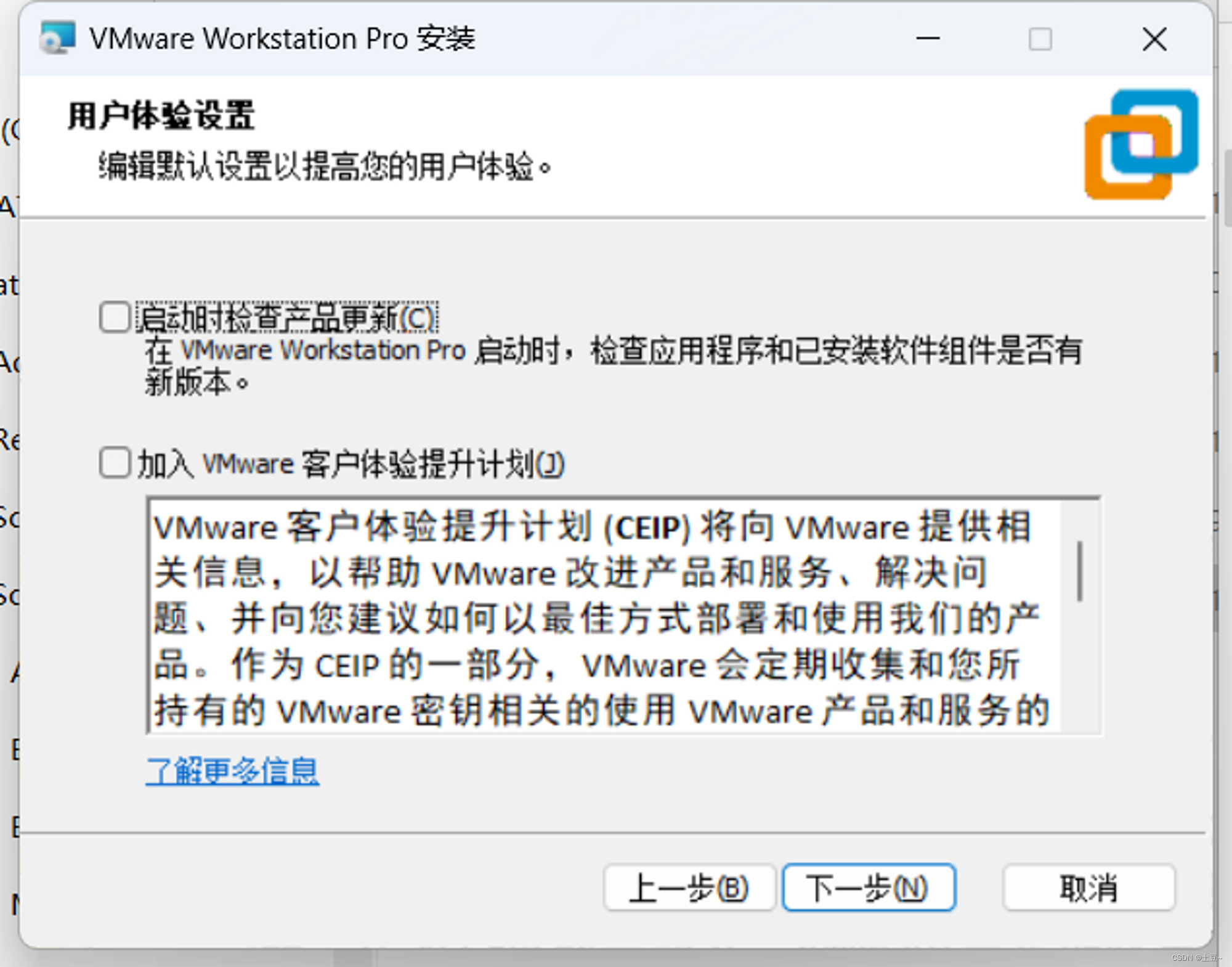
- 取消用户体验设置选项
密钥(点击链接可追溯获取源)
MC60H-DWHD5-H80U9-6V85M-8280D
安装
打卡Vmware,点击文件、新建虚拟机
步骤
- 选择自定义
- 选择镜像文件
- 更改安装位置
- 分配处理器(按照自己的电脑设置)
- 网络类型NAT
- I/O和磁盘类型不更改
- 创建新建虚拟磁盘
- 磁盘容量自定义(仅作学习20G够了,单个或多个文件自定义)
- 开启虚拟机
图示
-
选择镜像文件
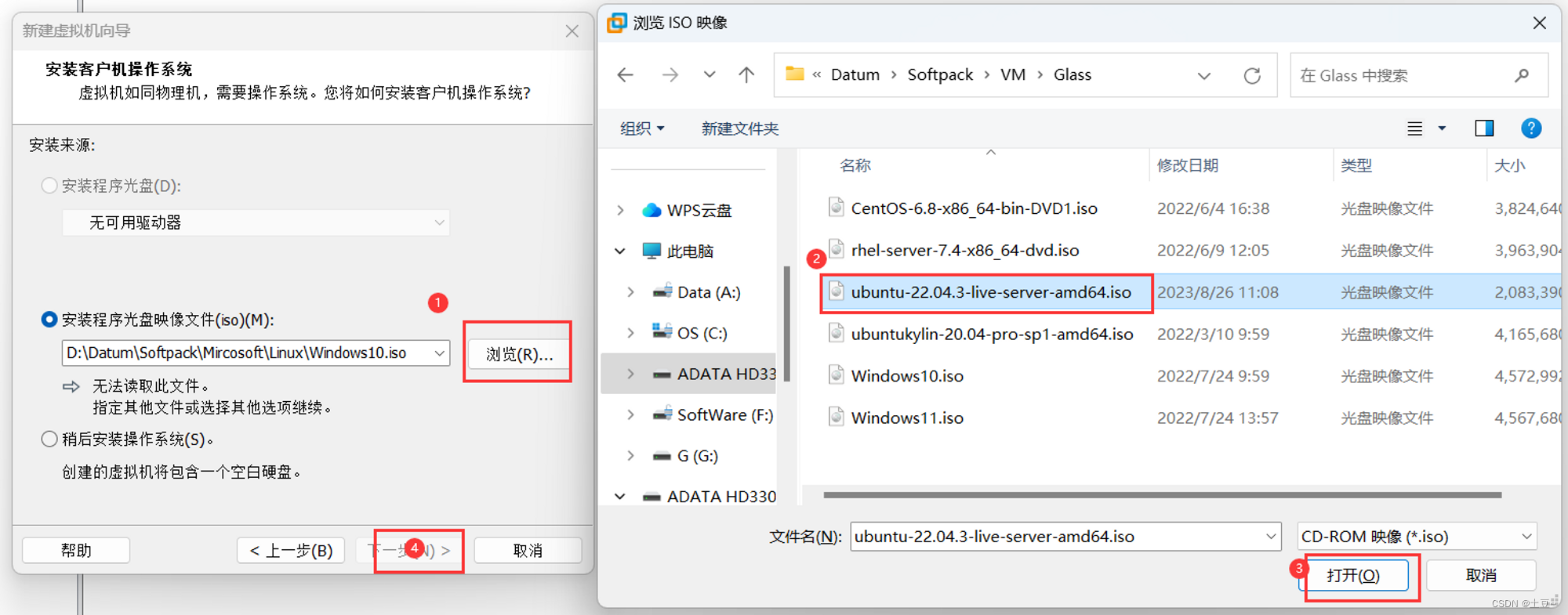
-
更改安装位置
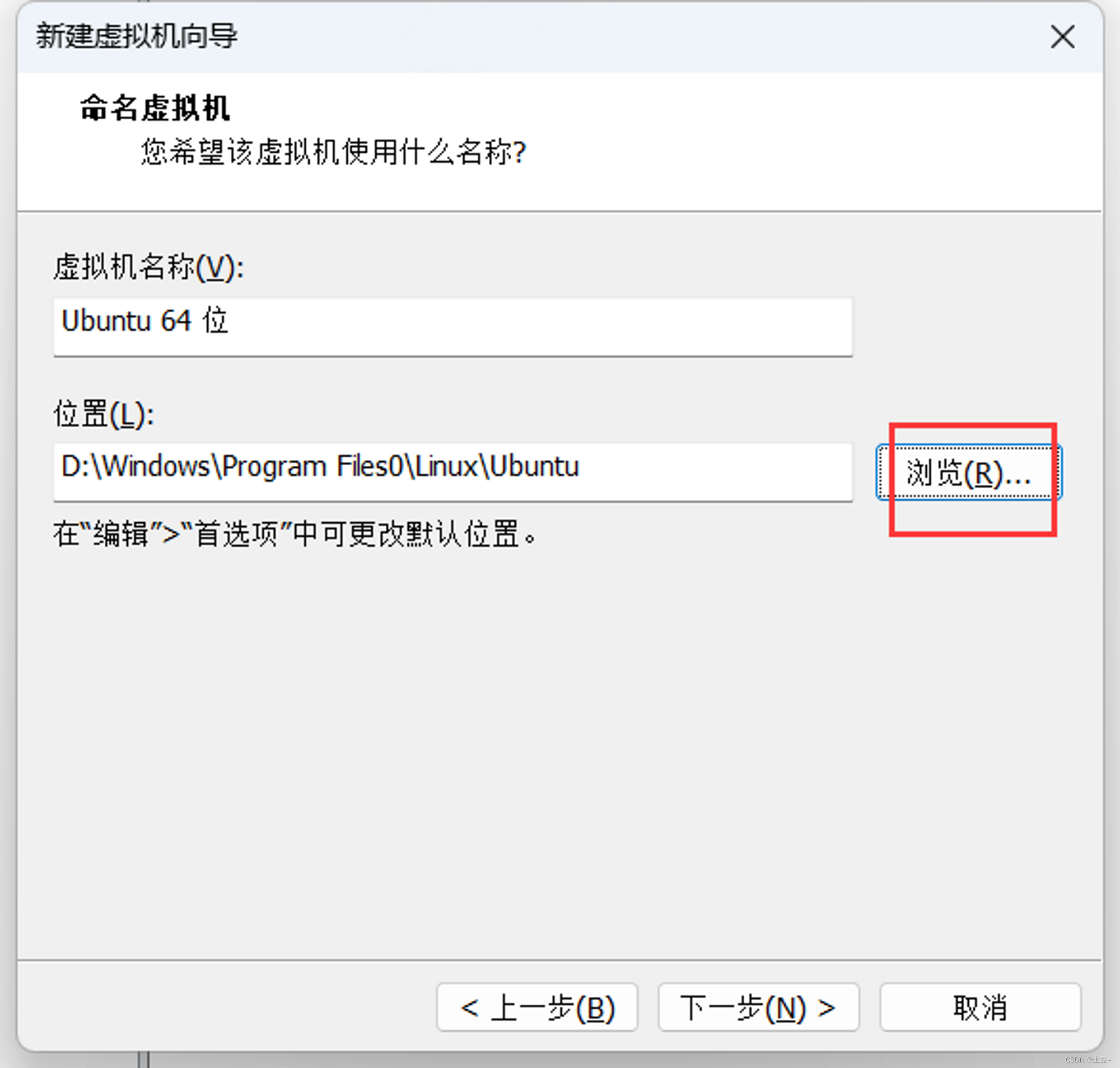
-
分配处理器(按照自己的电脑设置)
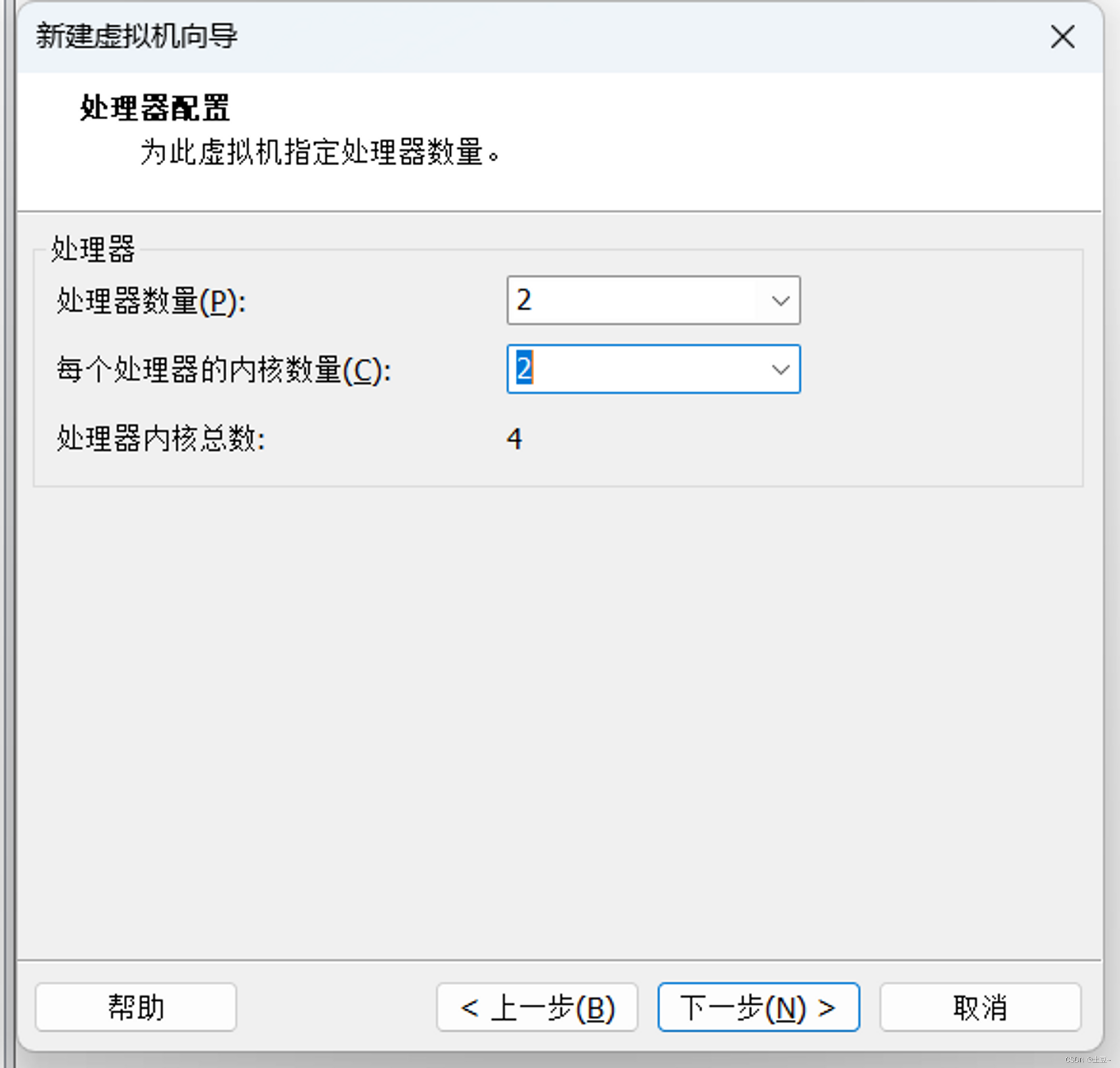
-
网络类型NAT
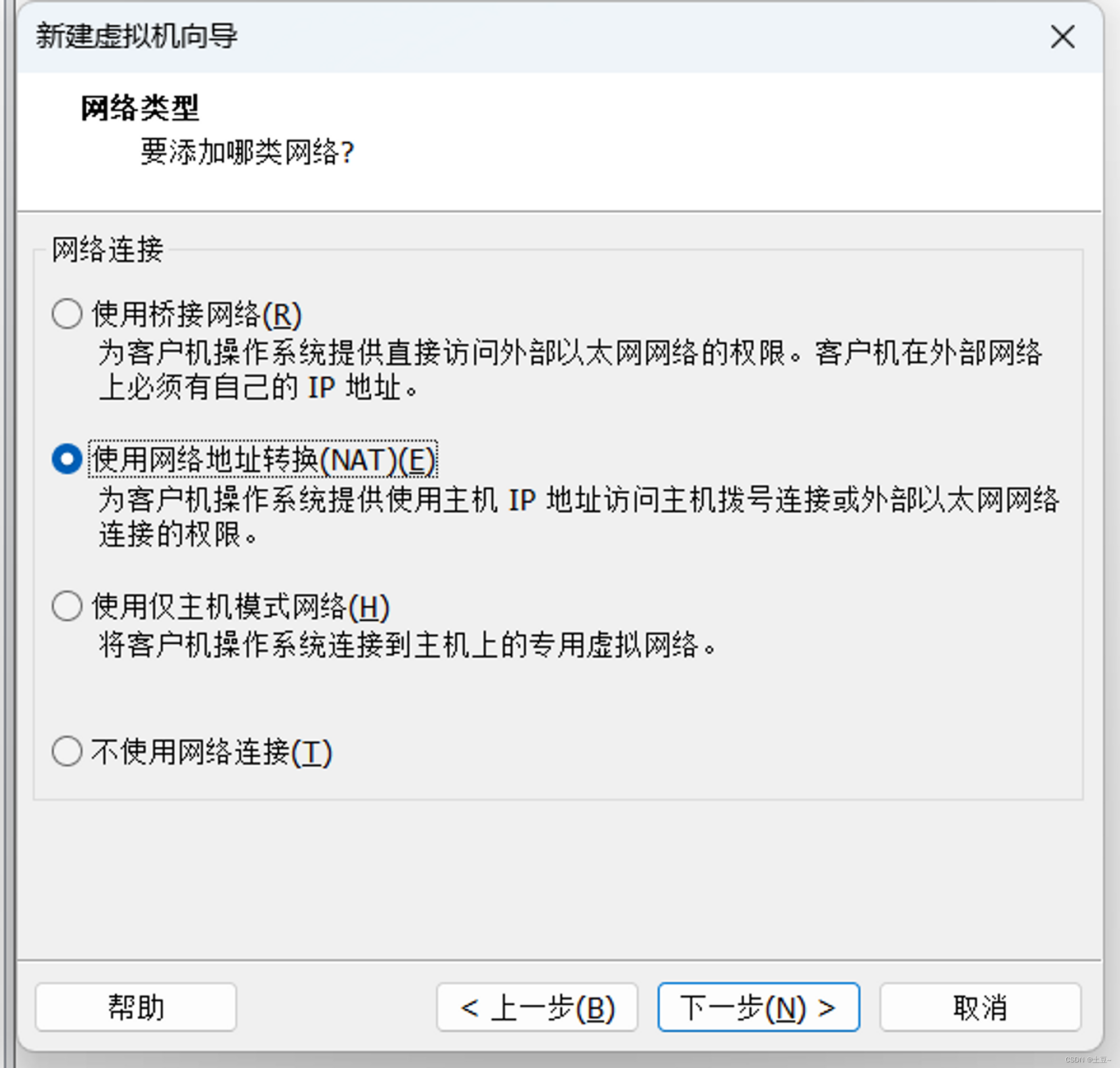
-
创建新建虚拟磁盘
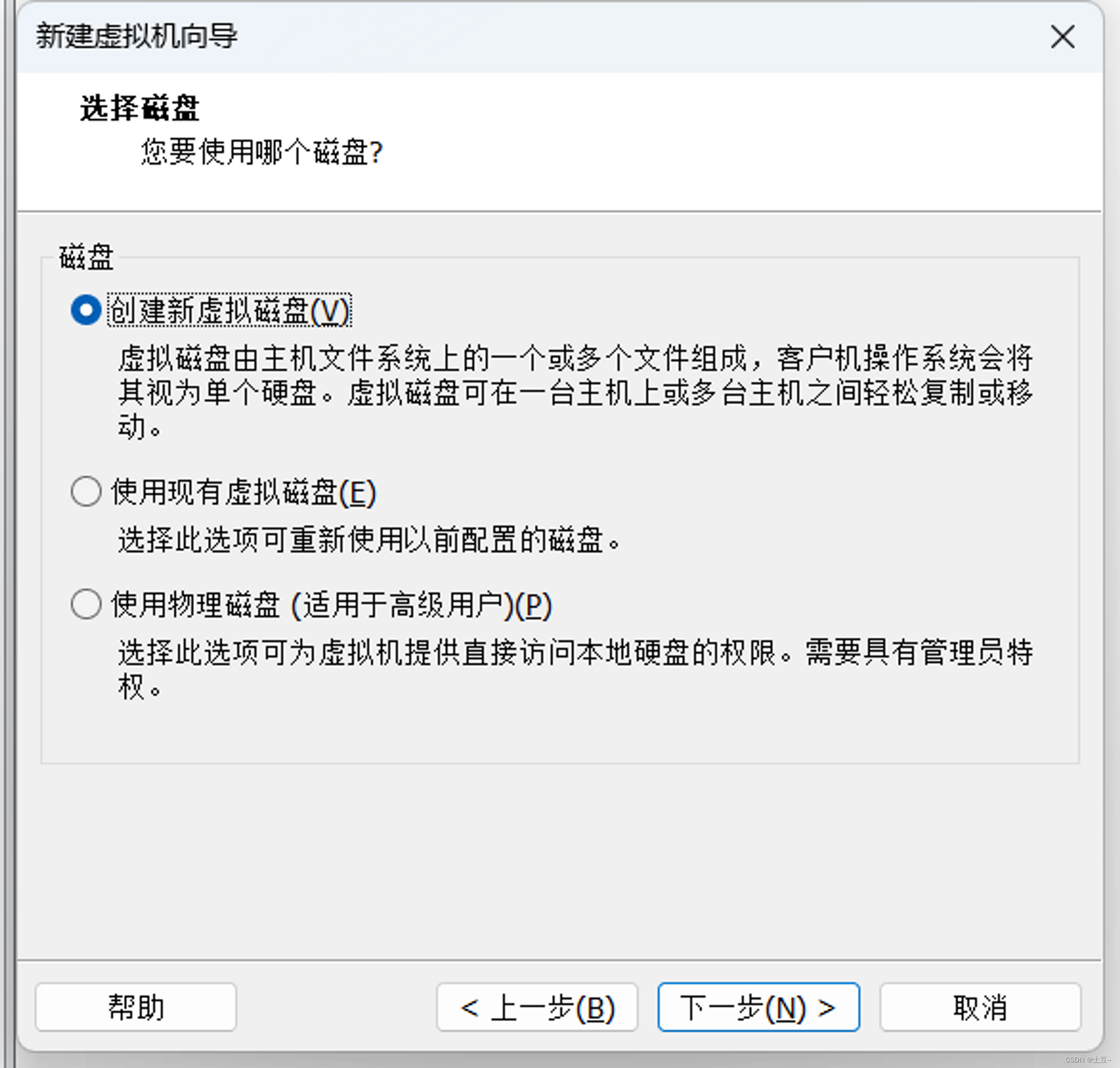
-
磁盘容量自定义(仅作学习20G够了,单个或多个文件自定义)
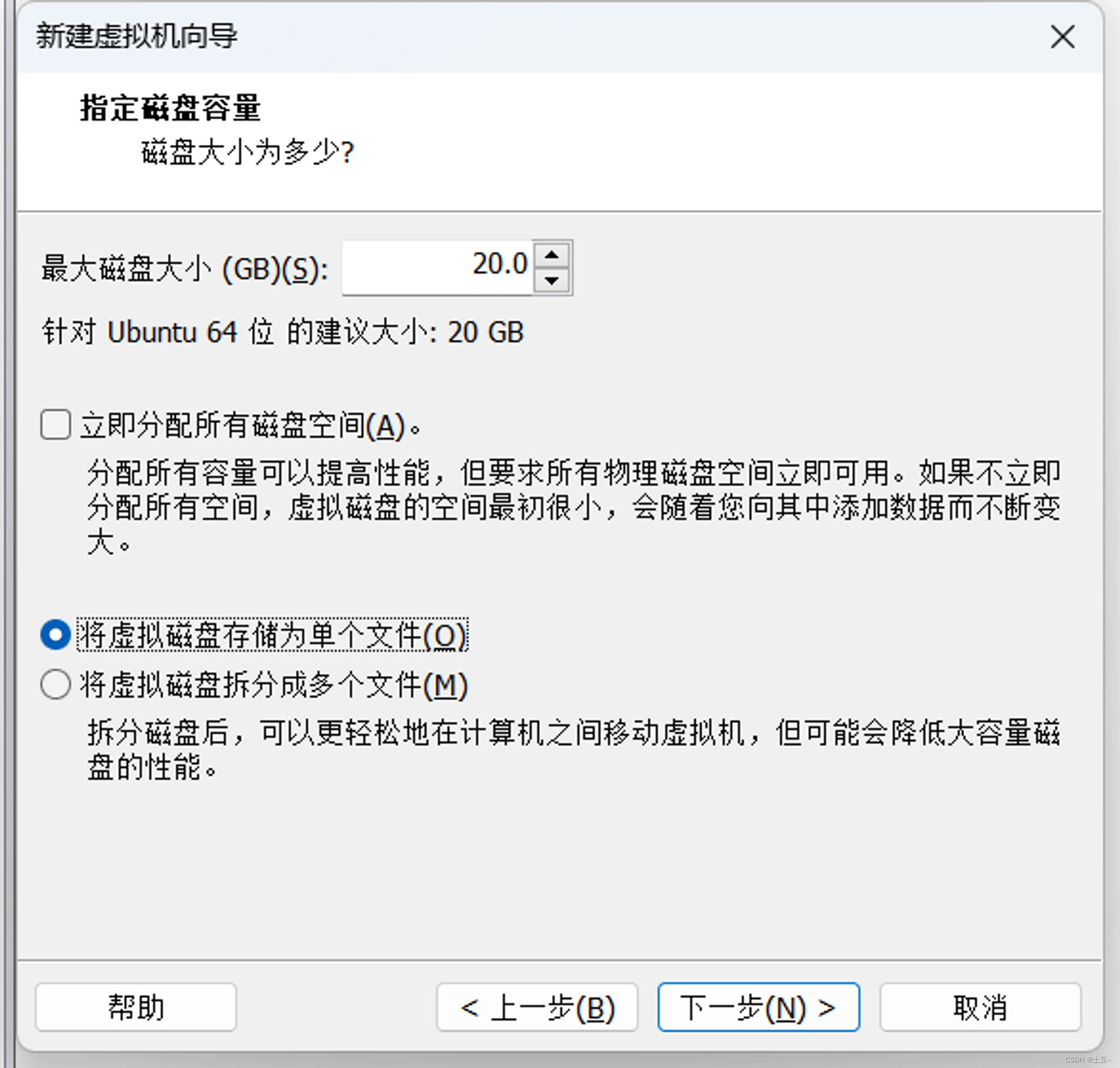
-
开启虚拟机
开启后等待初始化……
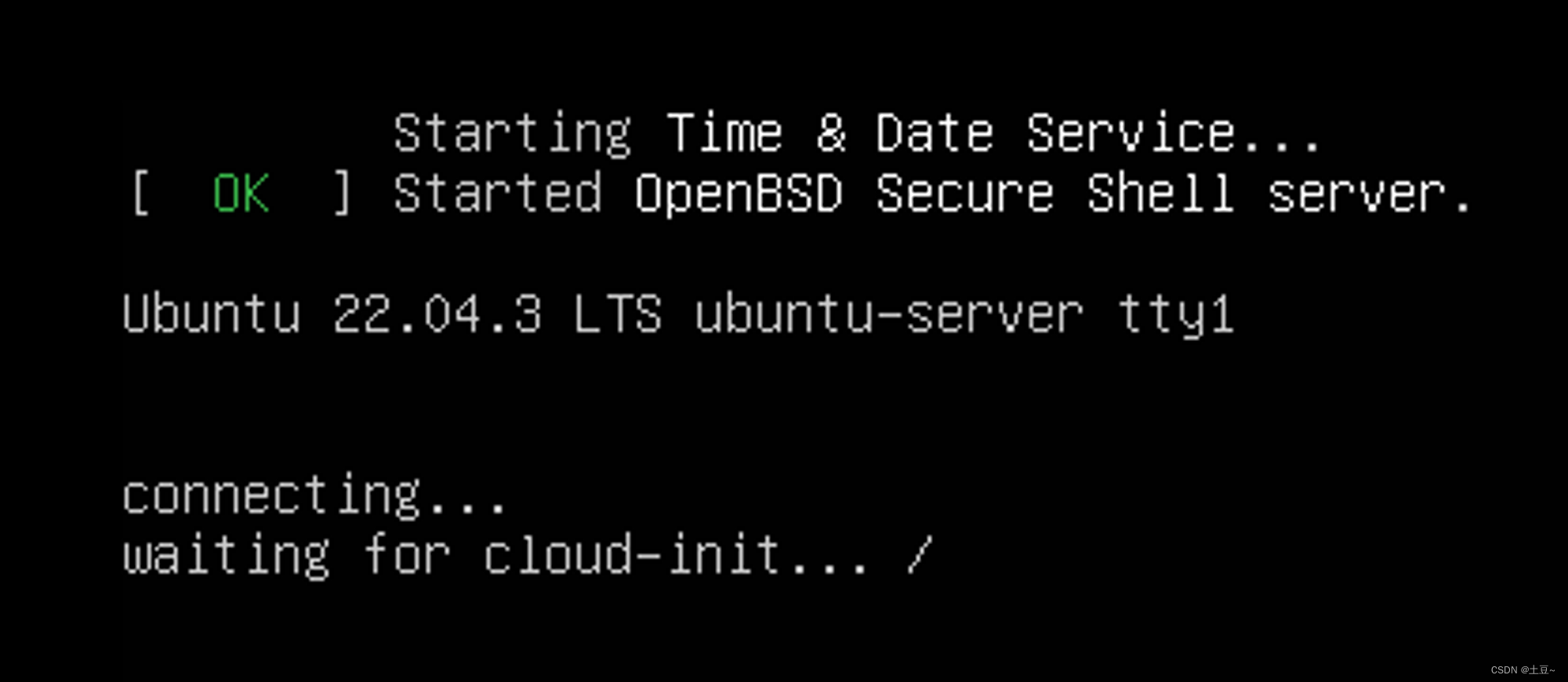
安装
Done:确定
Back:上一步
步骤
- 选择语言
- 选择输入法语言
- 选择安装类型 (默认安装即可)
- Ubuntu Server ——> 默认安装
- Ubuntu Server (minimized) ——> 最小化安装
- 网络连接
- 代理设置 (跳过直接回车)
- 镜像地址 (可更改为国内源,如阿里镜像)
- 分配存储空间 (会显示给到的20G,下一步即可)
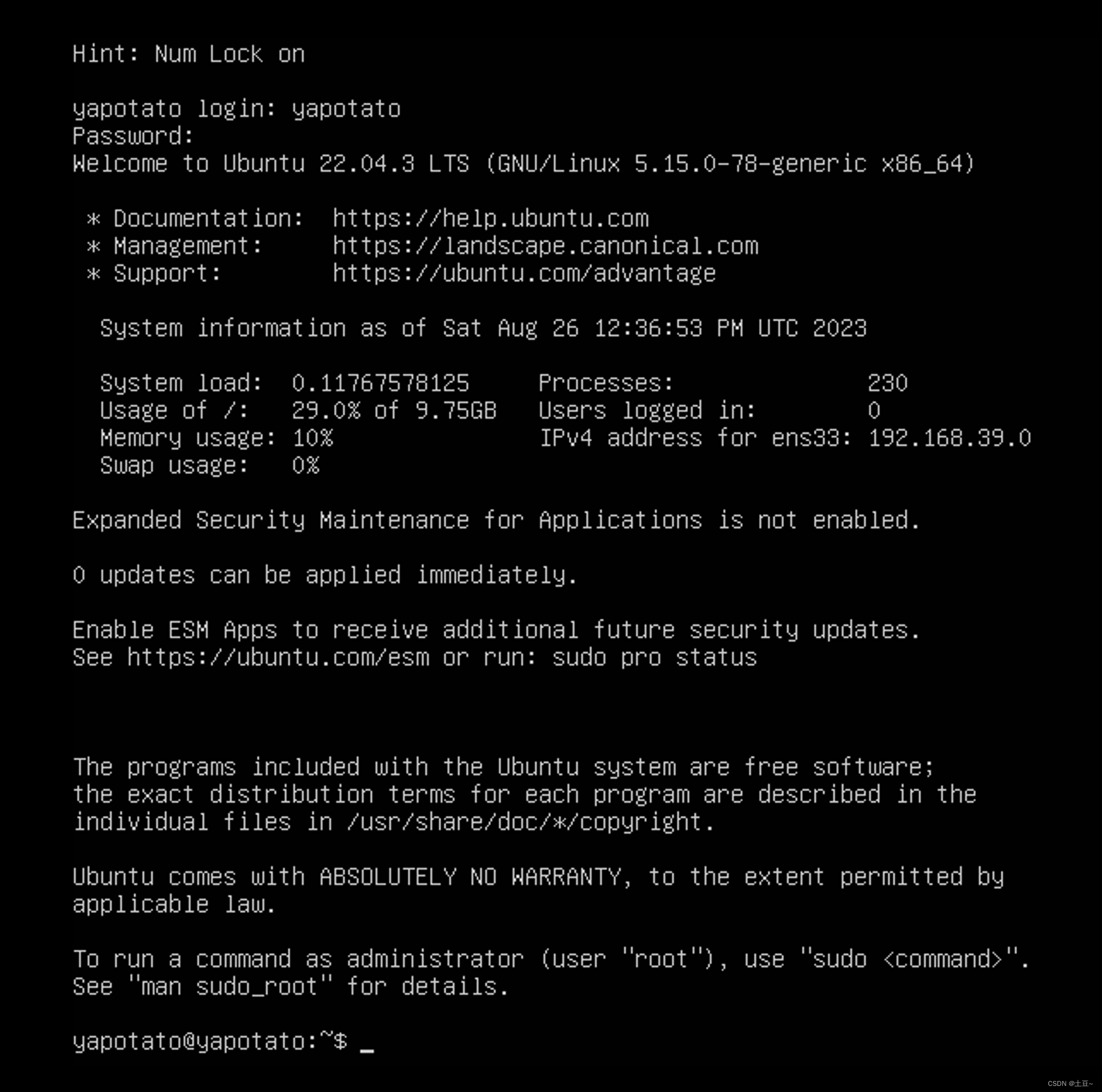
- 设置用户名及密码 (因学习使用不涉及私人或商用,建议密码设置简单的如:123456 )
- 升级为Ubuntu Pro (默认跳过)
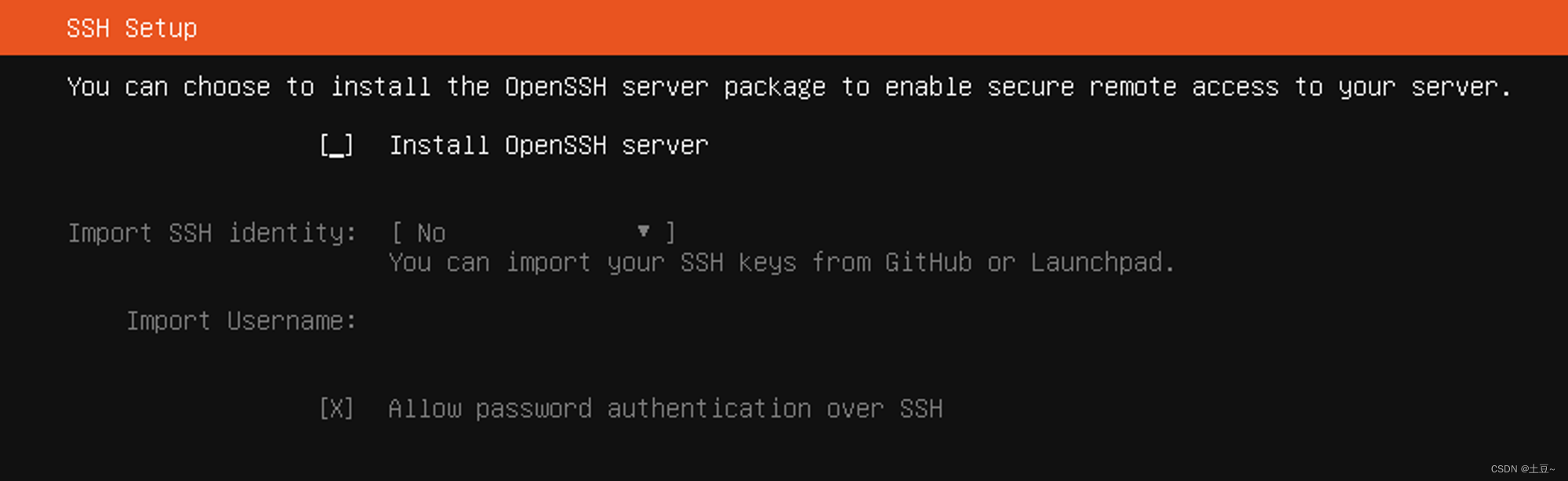
- 安装OpenSSH (如果你需要远程拉去包可以选择安装它)
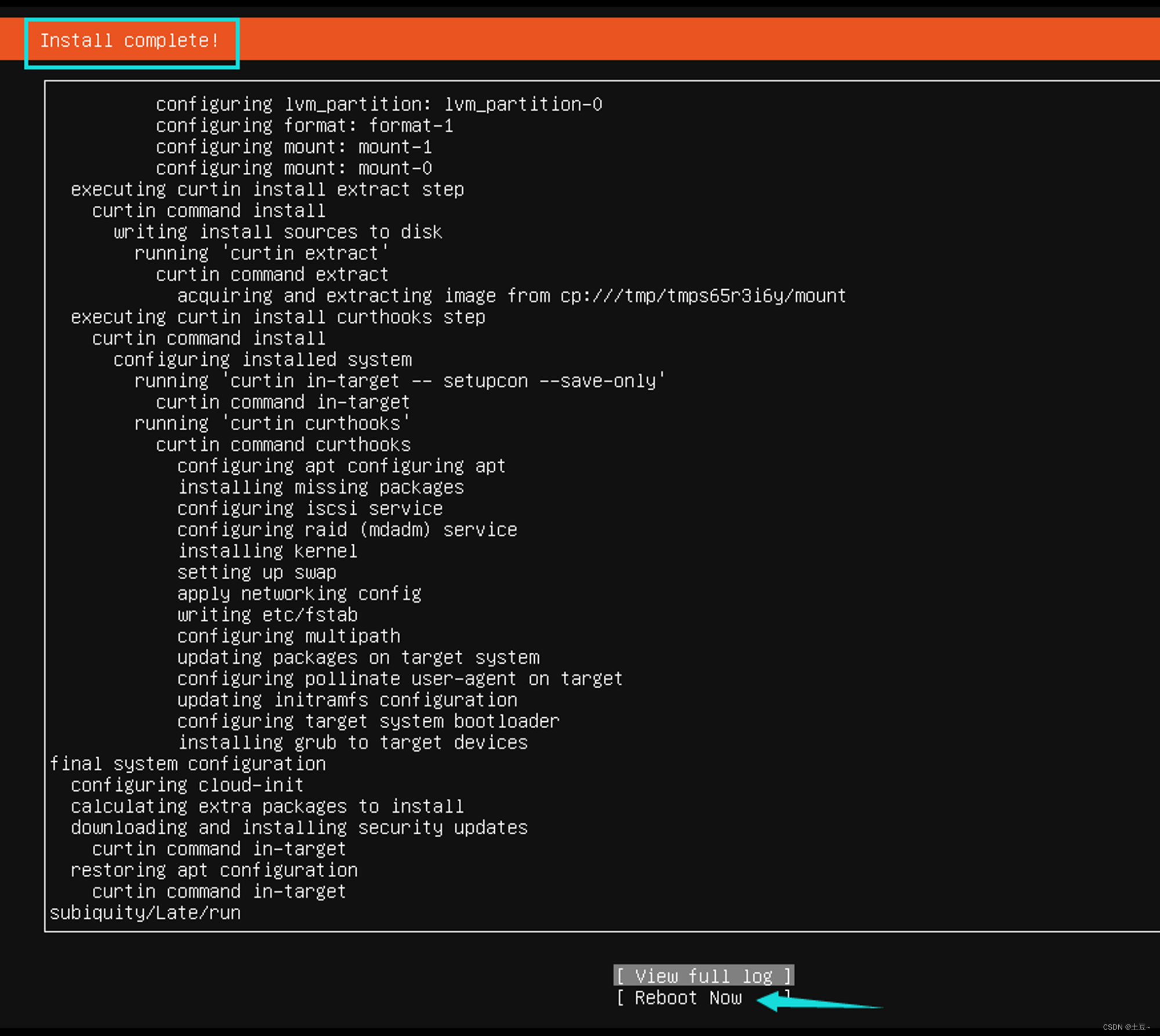
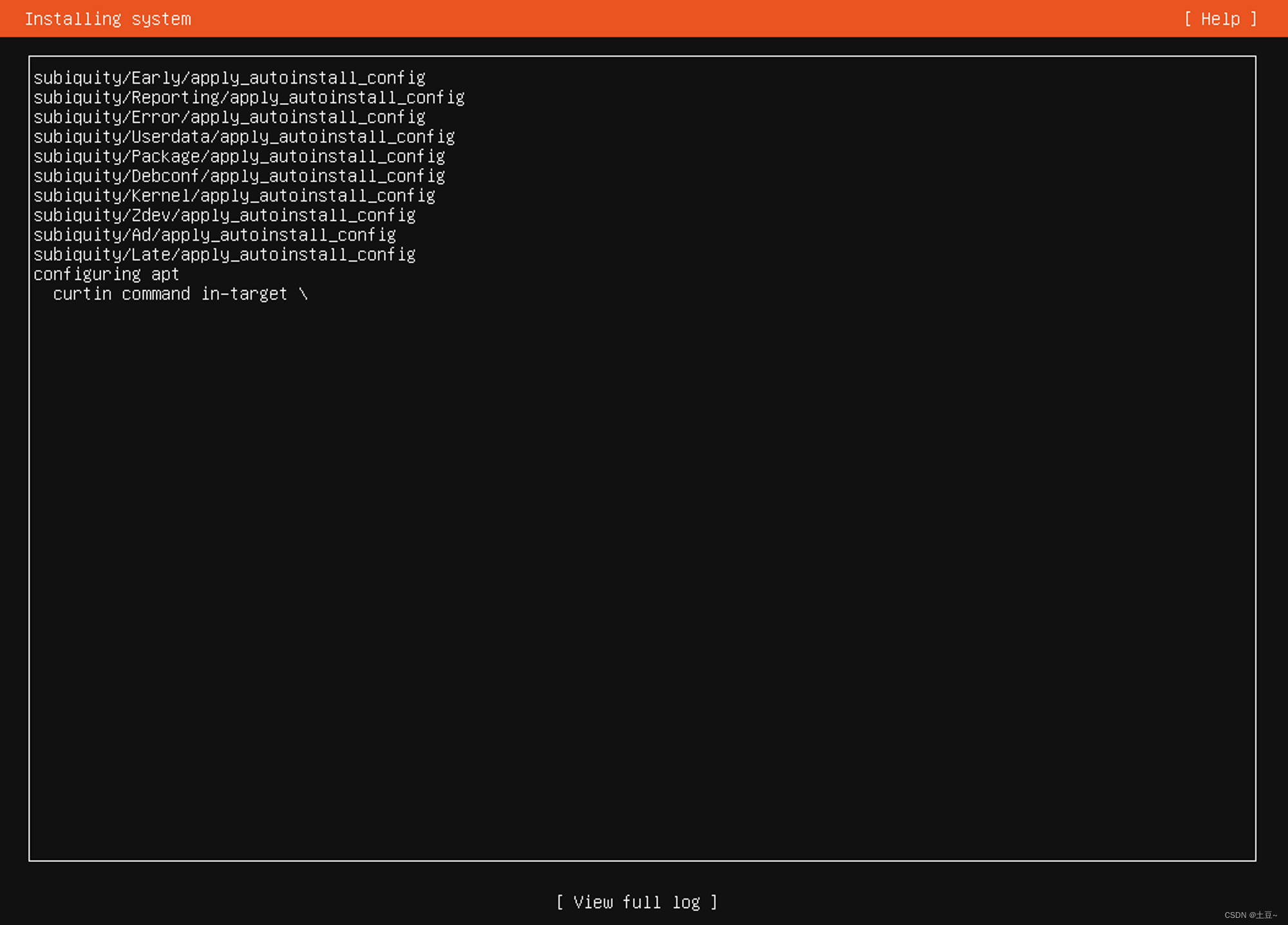
- 安装系统
- 安装完成 重启
图示
-
选择语言
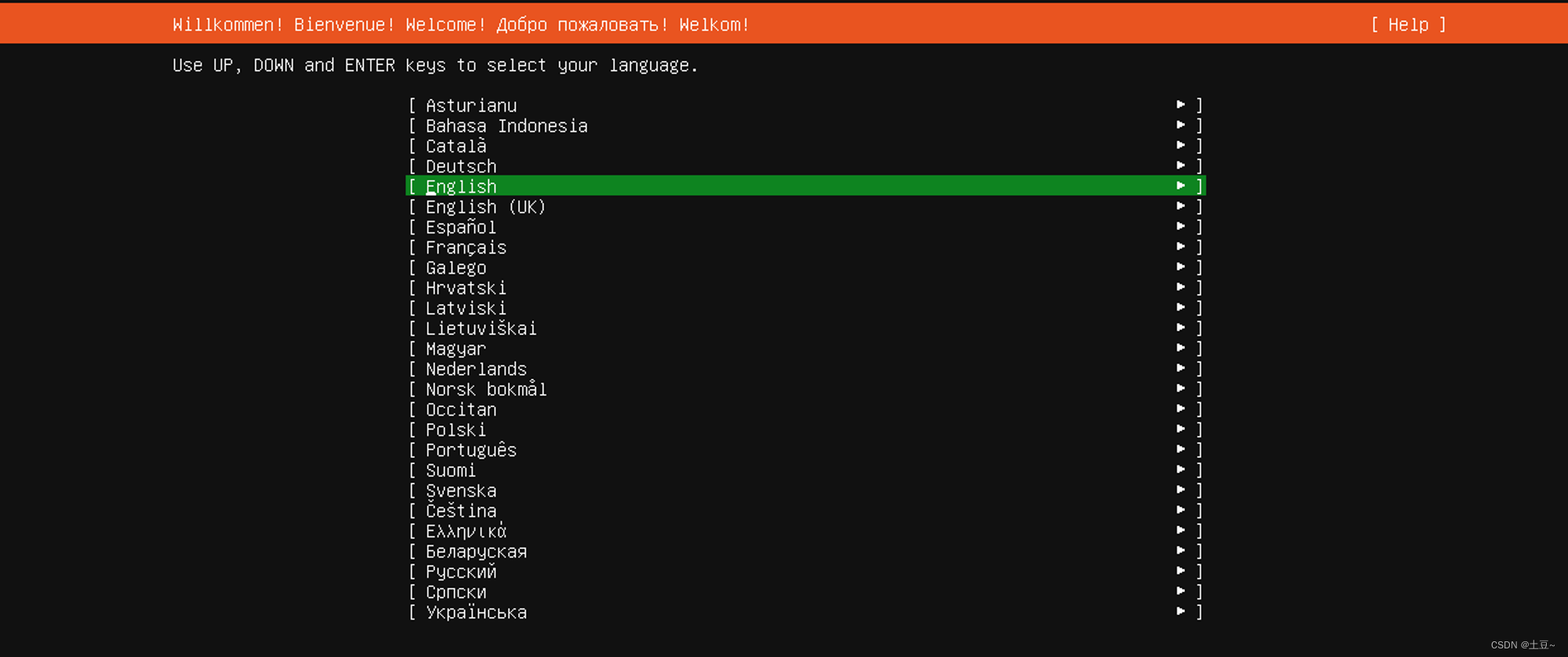
-
选择输入法语言
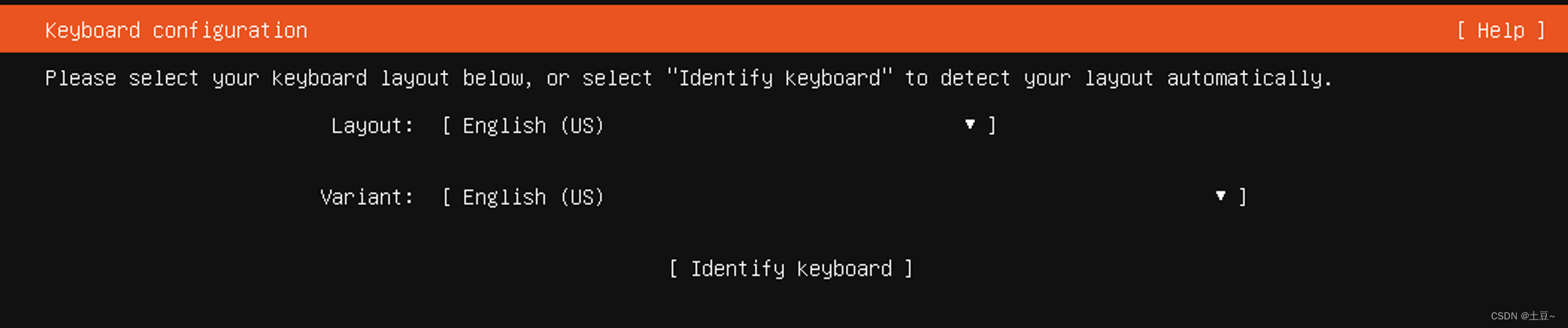
-
选择安装类型 (默认安装即可)
- Ubuntu Server ——> 默认安装
- Ubuntu Server (minimized) ——> 最小化安装
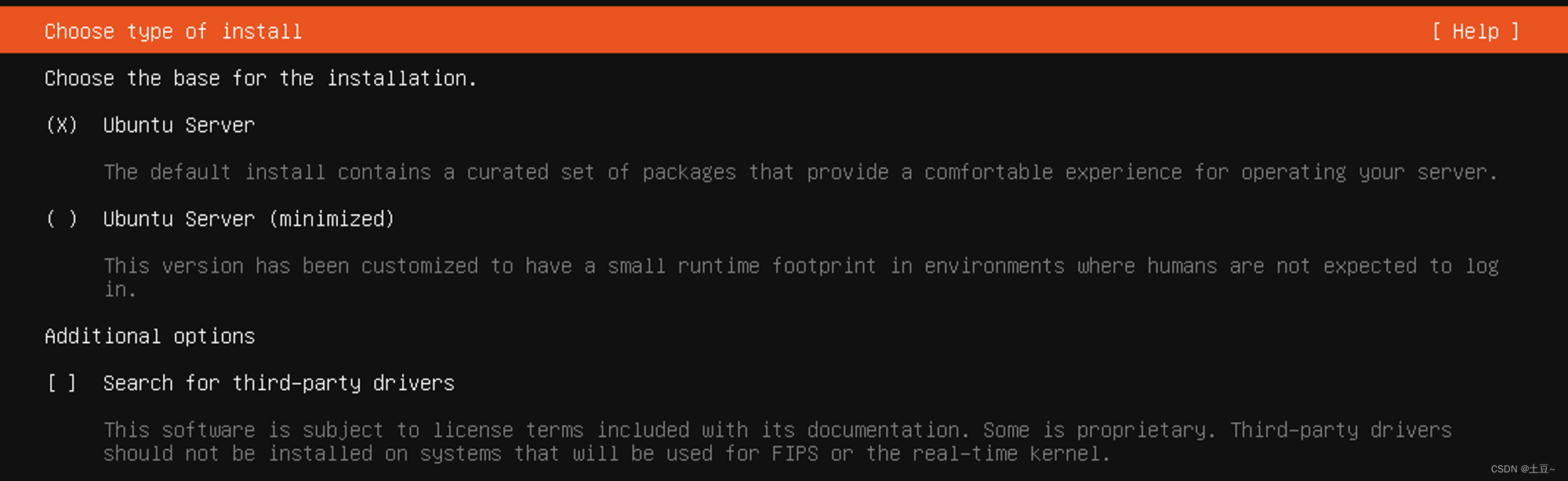
-
网络连接
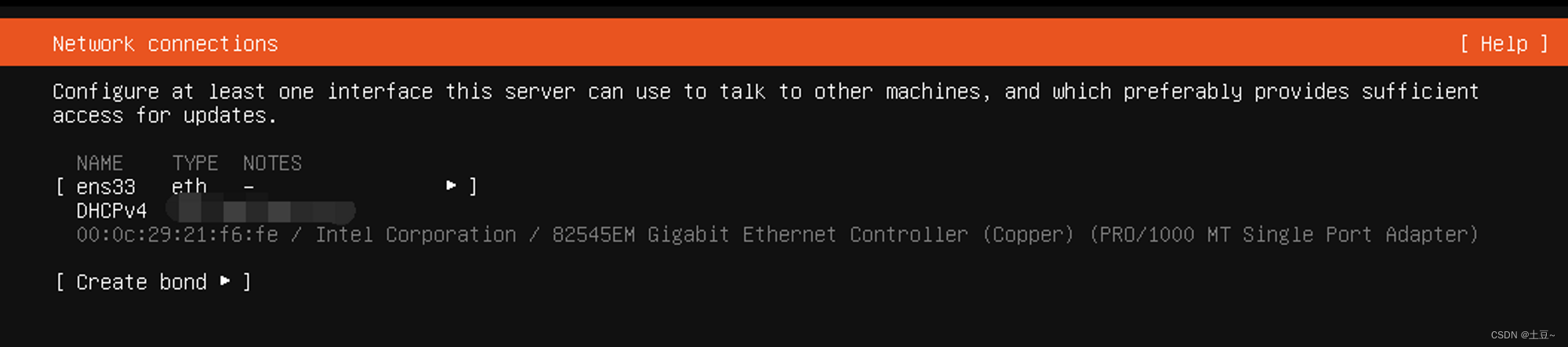
- 分配存储空间 (会显示给到的20G,下一步即可)
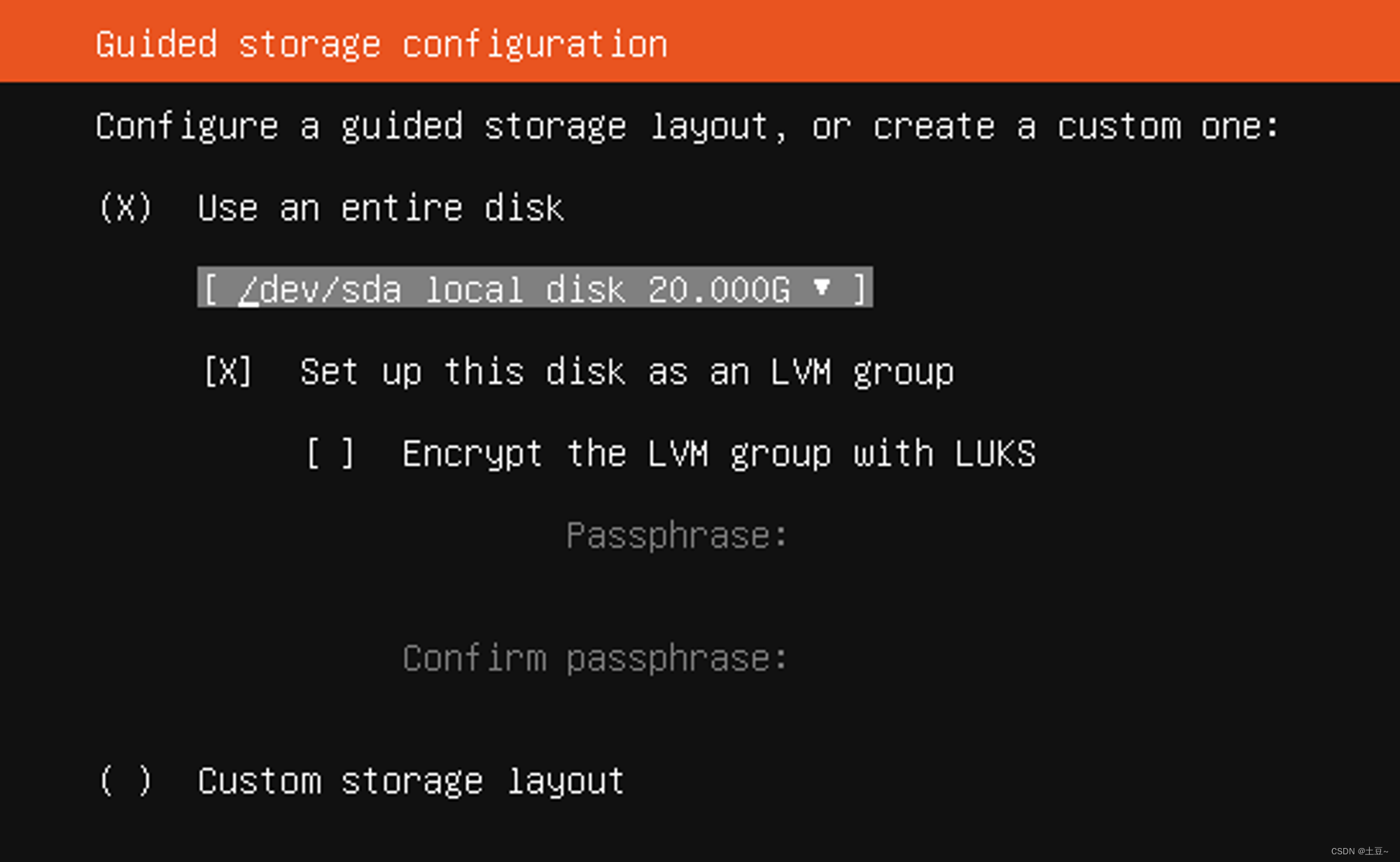
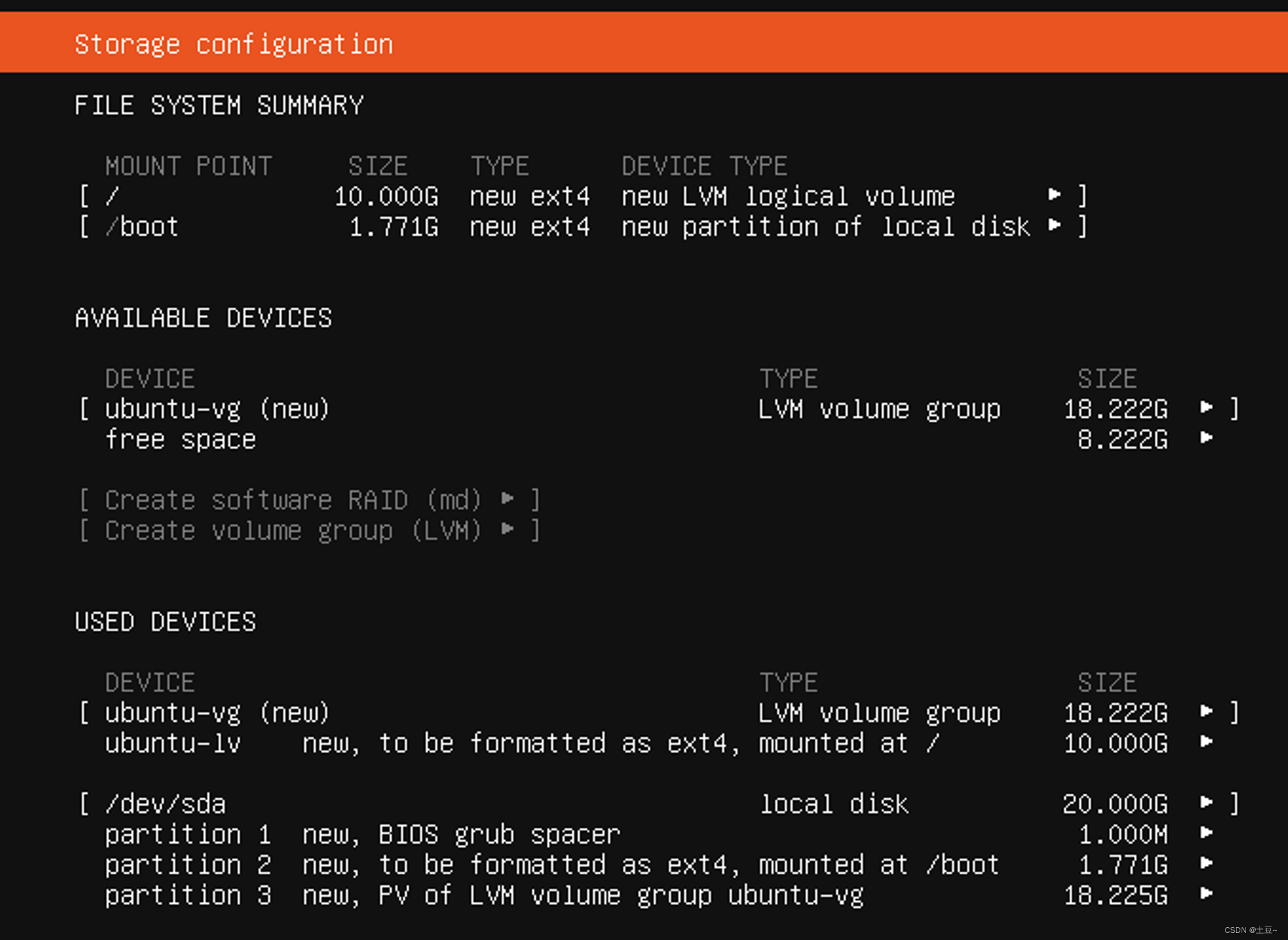
-
设置用户名及密码 (因学习使用不涉及私人或商用,建议密码设置简单的如:123456 )
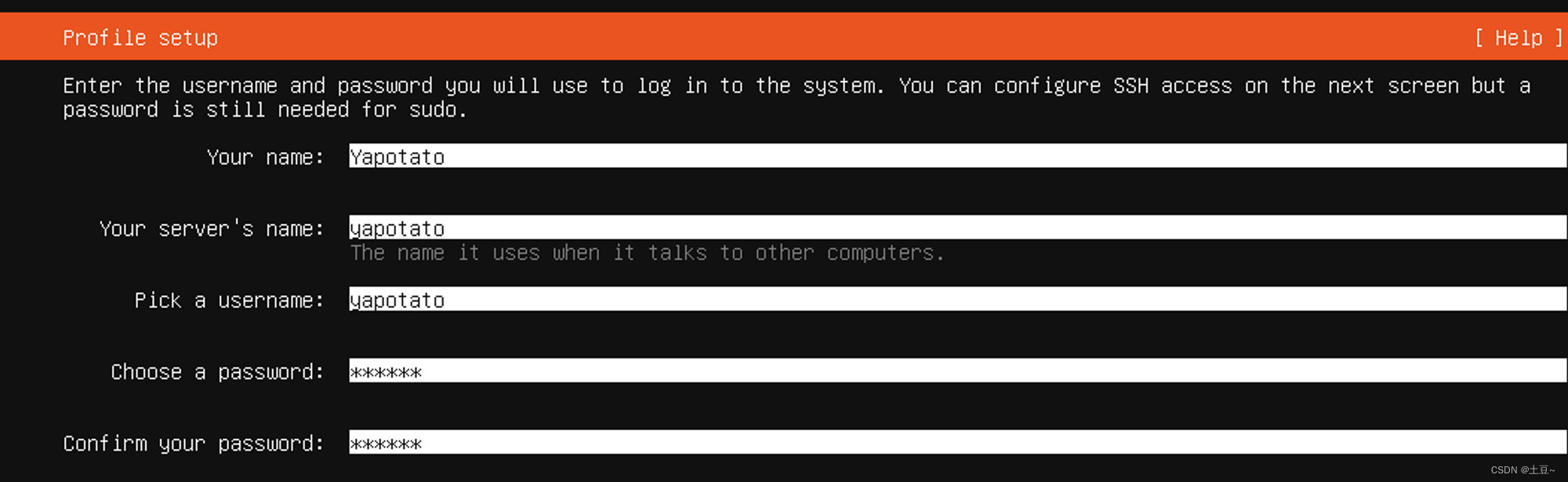
-
升级为Ubuntu Pro (默认跳过)
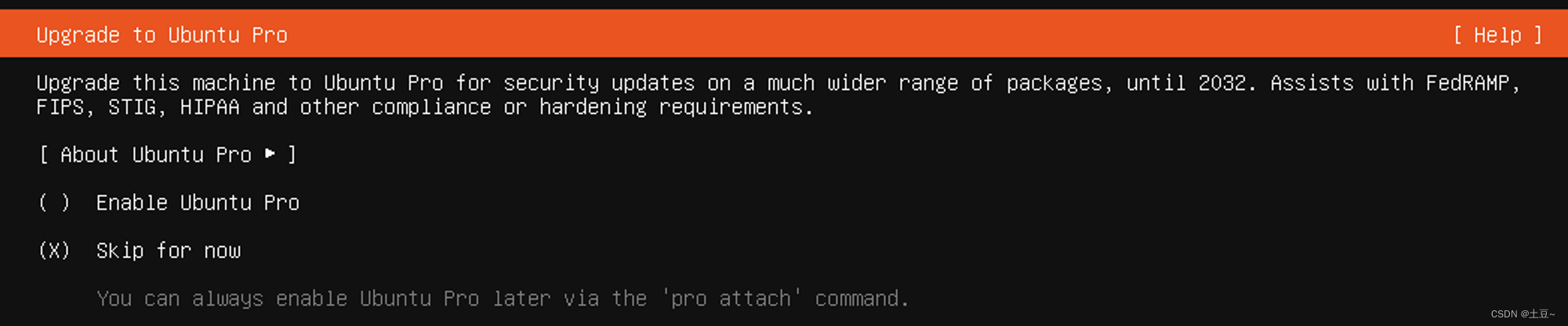
-
安装OpenSSH (如果你需要远程拉去包可以选择安装它)
- 安装系统
- 安装完成 重启