中国大型网站建设公司青岛seo排名公司
SaaS软件能保证数据安全吗?
本文将要尝试从各个方面尽可能客观的去阐述这个问题,而不是简单自嗨式的说简道云平台如何保障数据安全。
建议先收藏起来慢慢品!
01 SaaS安全到底是什么?——定义解读
本文所用SaaS平台>>>>https://www.jiandaoyun.com
简单来说,SaaS安全是基于云的安全性,旨在保护这些应用程序所涉及的敏感信息免遭广泛使用和轻松访问。
那么什么又是“云”呢?
本地部署大家都知道吧,云部署就是和本地部署相对的一种部署方式。大家可以这样理解——
本地系统就像是房子的业主,你是唯一负责安全的人。但你实际上能负担得起什么质量的安全技术呢?这个不好说,如果是没有很强的技术资源,也不见得你能保证“房子”的安全。
而SaaS “云部署”就像一个多租户系统,房东或设施经理在专家协助下提供安全保障。
这意味着你将构建访问控制的责任外包给拥有最新、多级访问技术和最佳安全技能的经理。同时你也可以控制谁可以或不能进入你自己的建筑物部分。
这就是云部署和本地部署的区别。
回到正题,基于云部署的SaaS安全就是指管理、监控和保护敏感数据免受网络攻击,确保从客户支付信息到部门间信息交换等情况下的用户数据隐私和安全。
而为了加强对SaaS安全的正规监管,世界各地的监管机构也发布了安全指南,例如 GDPR(欧盟通用数据保护条例)、欧盟-美国和瑞士-美国隐私护盾框架。

在本土,我们也有非常严格的信息安全保护措施——国家信息安全等级保护三级认证

02 说了半天还是很抽象?——SaaS 安全剖析
如果我们从鸟瞰的角度来看一个理想的SaaS产品技术栈,它会形成一个三层蛋糕,每一部分代表不同的环境。
- 基础设施(服务器端)
- 网络(互联网)
- 应用程序和软件(客户端)
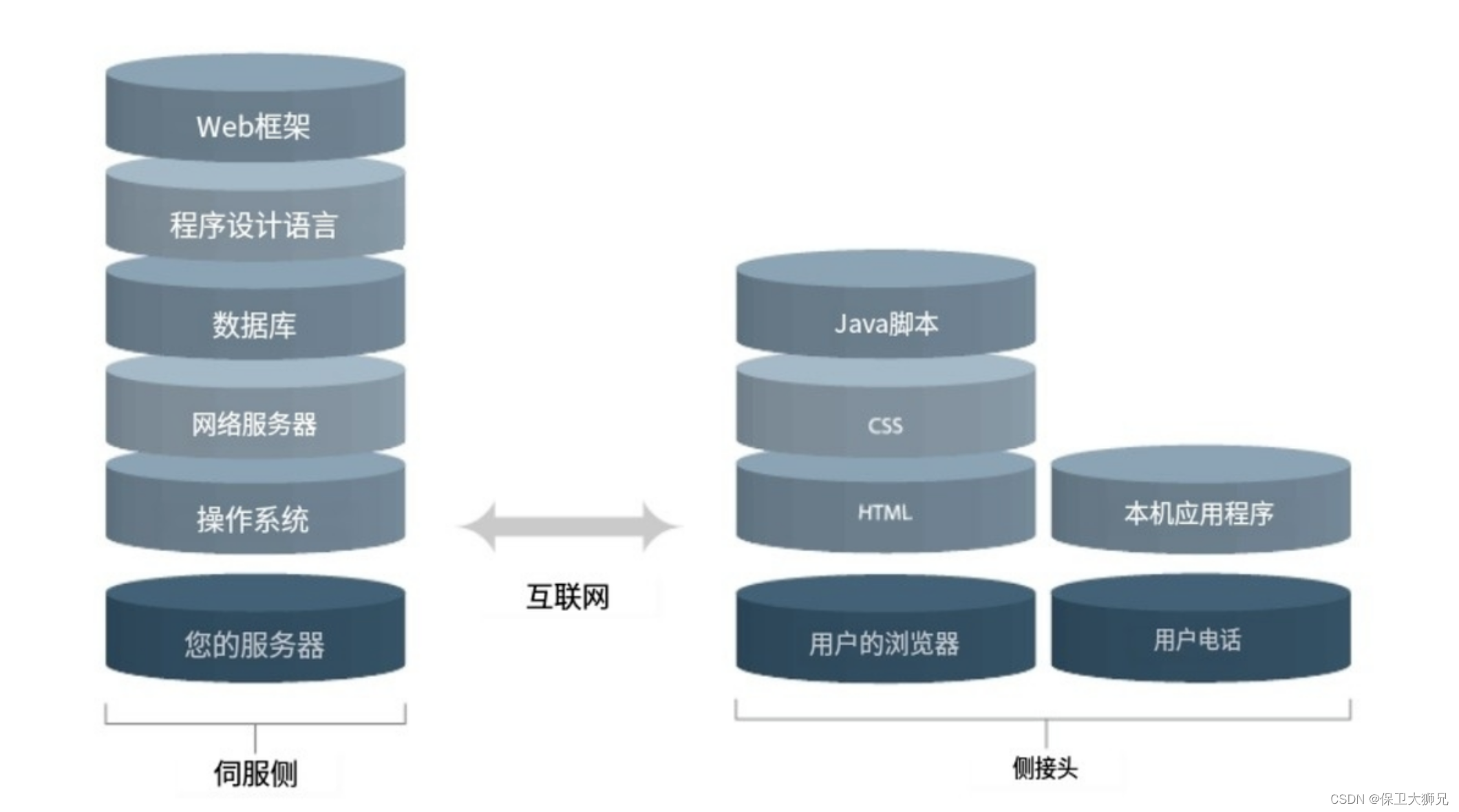
(1)基础设施
服务器端说白了就是内部信息交换。
举个例子,如果用户的业务使用简道云SaaS云服务平台,我们就必须保护云存储提供商与用户的软件平台之间的每个信息交换点。
(2) 网络
所谓网络是指服务器端和客户端之间的信息交换是通过互联网完成的。
网络其实是每个 SaaS 业务中最脆弱的一层,同样也是大部分企业最为关心的一部分。
SaaS安全的有效性与数据加密方法的完整性以及通过互联网实时监控信息交换的能力成正比。
以简道云为例,我们进行了严格的网络安全访问控制——
所有生产环境服务器按照逻辑分组之间,使用安全组(防火墙)进行隔离,每个安全组之间的互访都定义了严格的流入和流出规则。所有生产环境服务器都无法通过外部网络直接访问。
(3)应用程序和软件
应用程序和软件是 SaaS 安全的最后一层。
如上所述,一次数据泄露很可能导致空前的用户流失。因此,要保证用户数据的安全,就必须部署坚不可摧的SaaS安全措施。
我们必须确保用户使用的所有第三方应用程序和软件受到持续监控。此外,客户端环境的不可预测性要求比传统方法更高标准的安全措施。
以简道云为例,简道云从4个方面对用户数据进行了全方位保护——
- 1)物理安全
- 2)网络安全
- 3)数据安全
- 4)运维安全
详情见:数据安全与管理 - 简道云 - 帮助文档 (jiandaoyun.com)
03 有哪些企业在用SaaS?——案例背书
以简道云为例,各行各业都在用简道云进行企业应用搭建及管理,比如——
在传统制造行业中——以西门子、视源股份、东方日升等为代表的制造企业都在用简道云进行数字化转型升级。
在建筑行业中——以绿城、国基建设、中铁十二局等为代表的建筑企业都在用简道云管理业务。
在教育领域——从幼儿园到小学到中学甚至到大学,都有非常多的学校在用简道云做信息化管理。

甚至在政府单位——也有大量的单位选择简道云。
零售、服务、交通运输、医疗医药这些领域都有简道云的影子......
全部案例指路:https://www.jiandaoyun.com
最后的最后,如果你还是觉得SaaS不安全或者是有部分公司有强硬要求,说必须本地部署,那么可以考虑尝试简道云“独享版”!
以上,希望本文对大家有所帮助!