建公司网站建设明细报价表wordpress管理页面密码忘记
添加页眉页脚
页眉
首先在页面上端页眉区域双击,即可出现“页眉和页脚”设置页面:
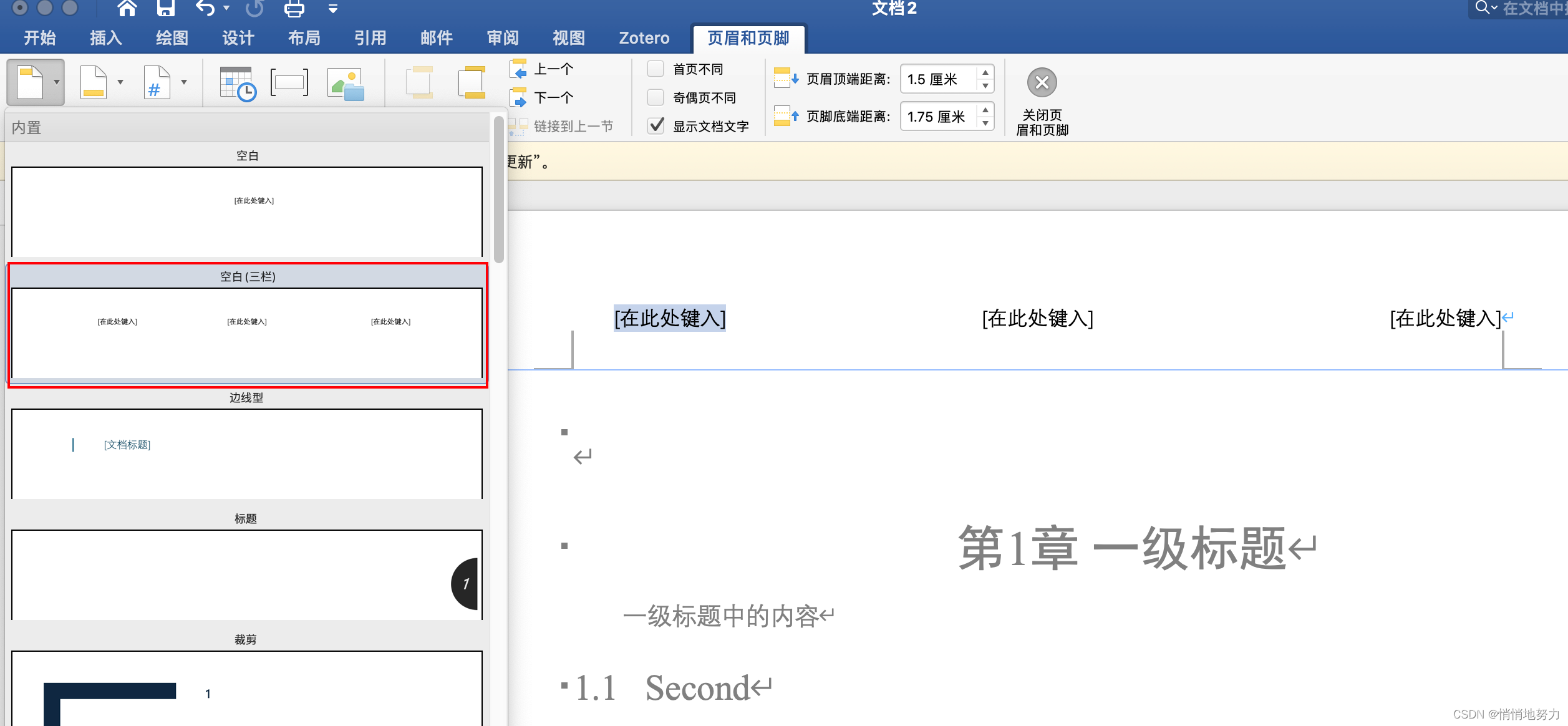
页眉左右两端对齐
如果想要页眉页脚左右两端对齐,可以选择添加三栏页眉,然后将中间那一栏删除,即可自动实现左右两端对齐:
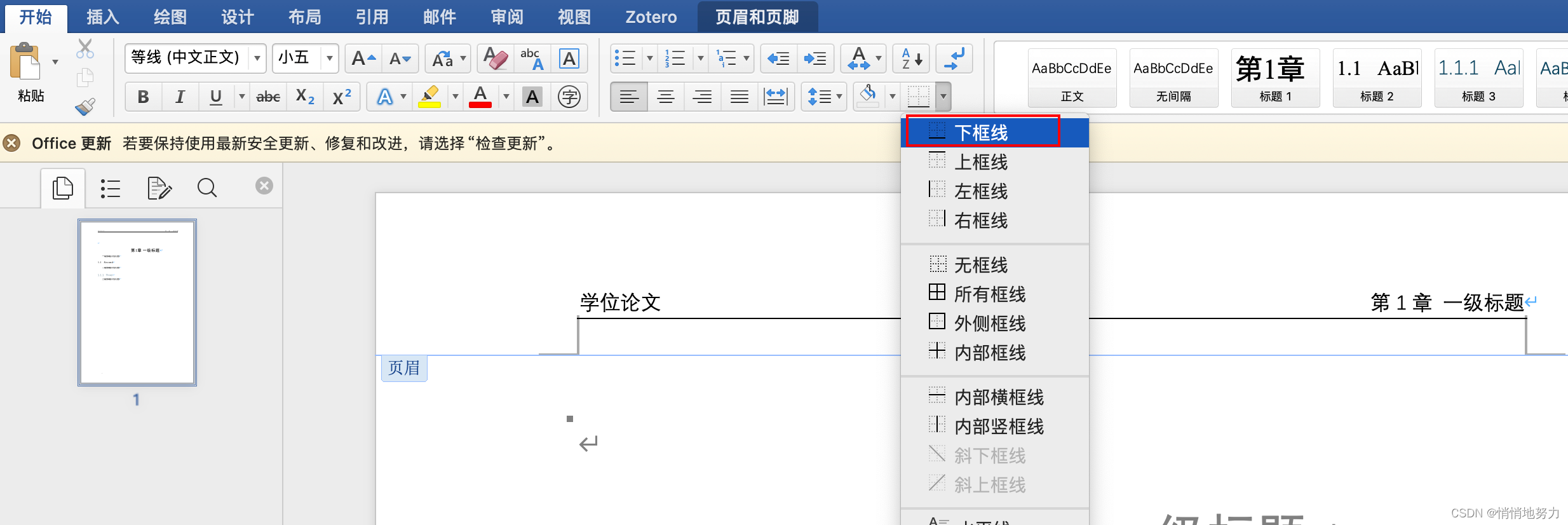
添加/删除页眉下面的横线
通过开始菜单中的表格框线进行调整:
设置不同章页眉内容不同
- 首先插入分节符:“布局” -> “分隔符” -> “下一页”:
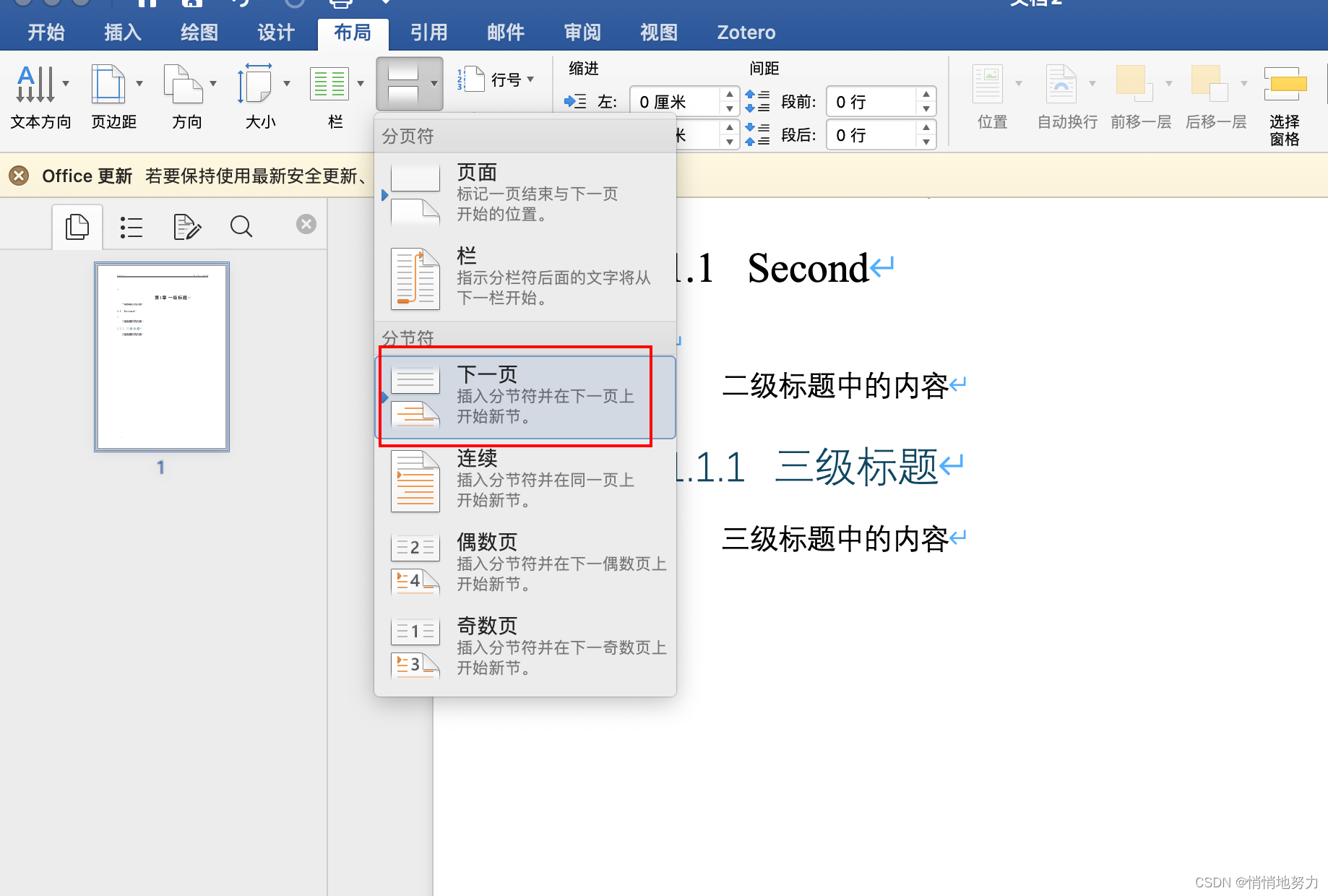
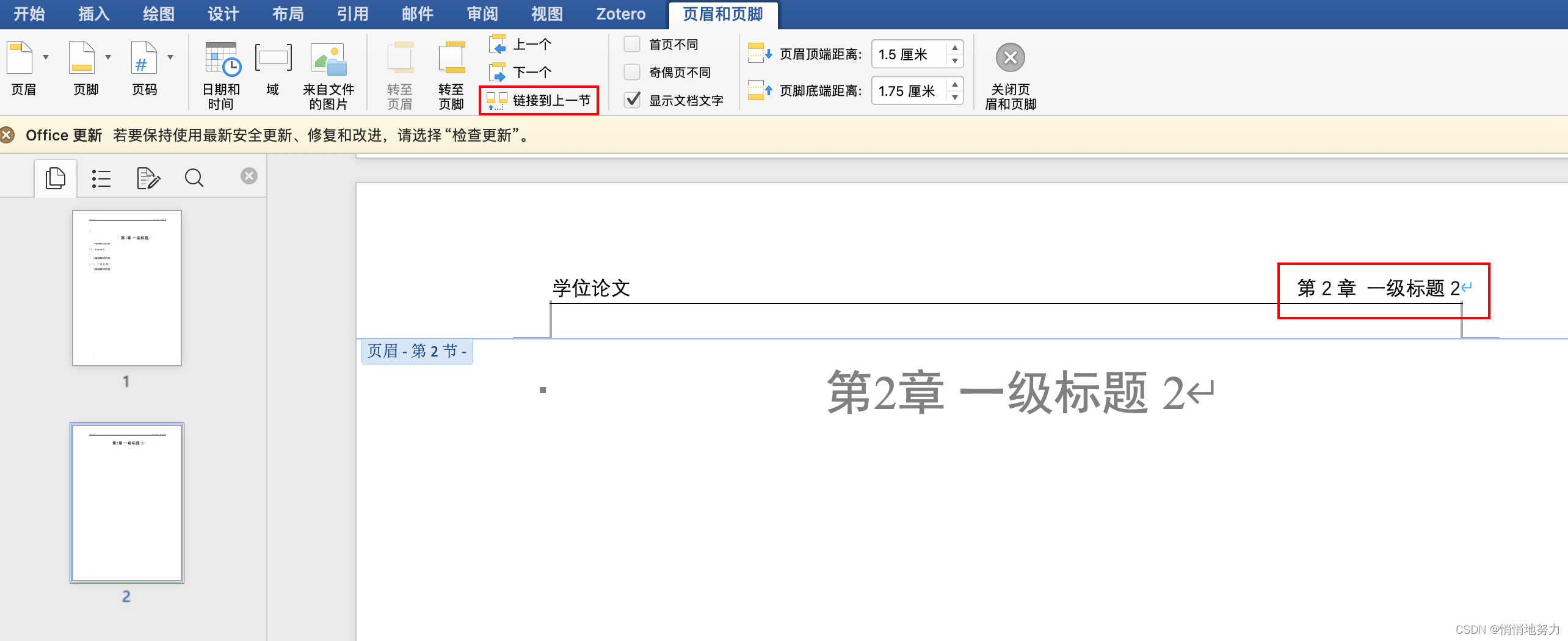
- 将“链接到上一节”取消勾选,然后按需修改本章的页眉内容即可:
页脚
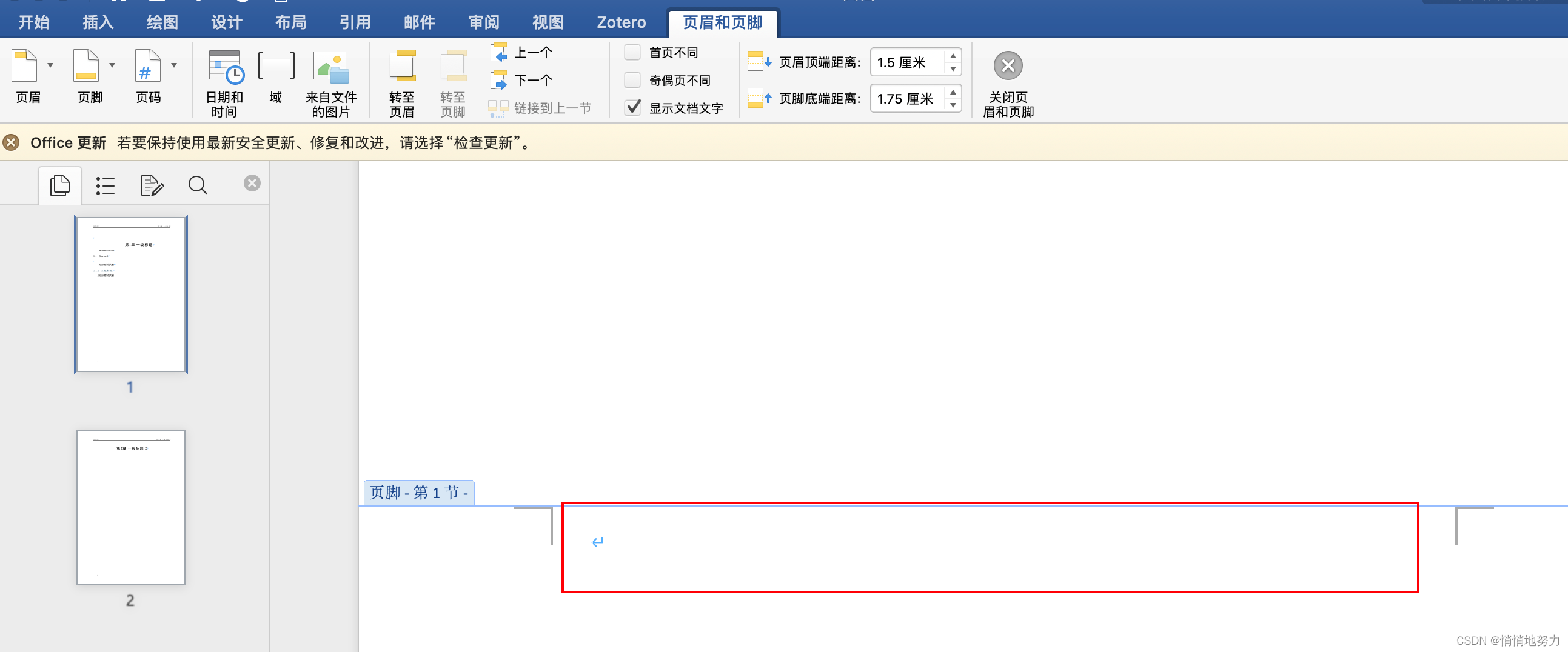
首先在页面下端页脚区域双击,即可出现“页眉和页脚”设置页面:
添加页码
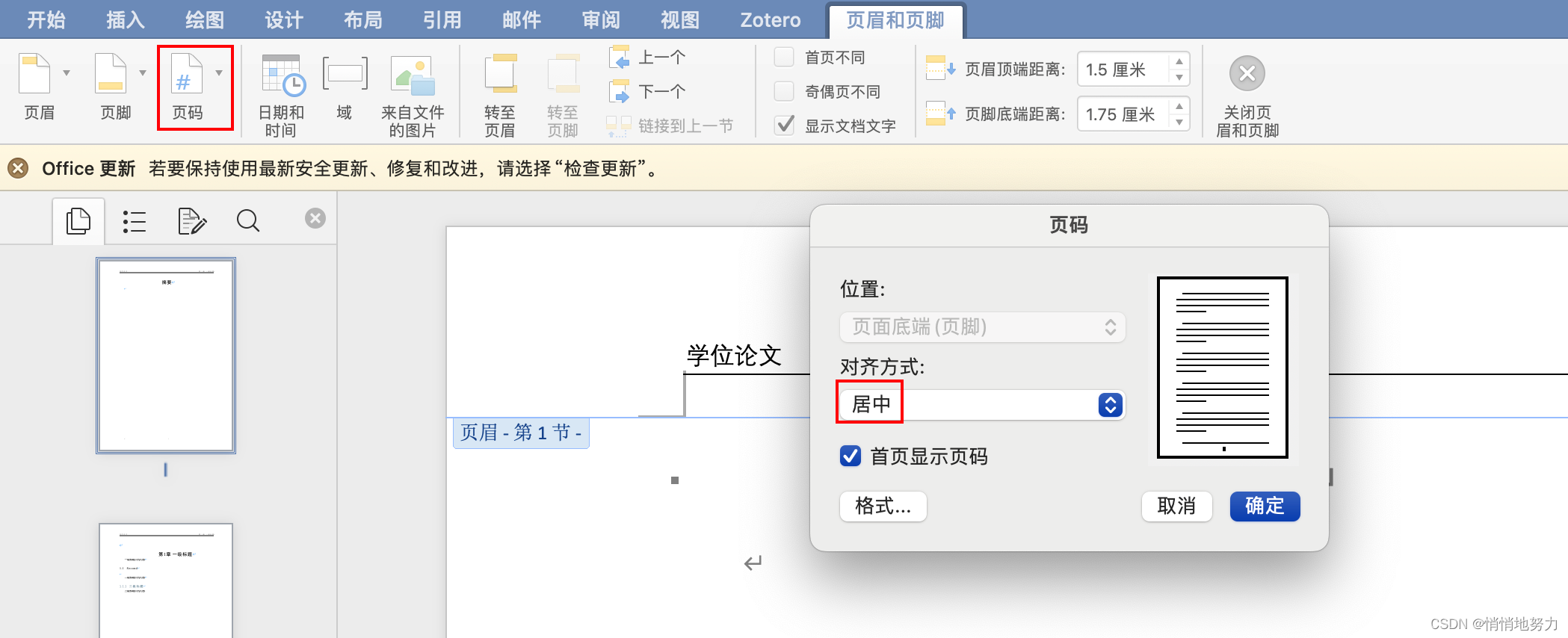
按需选择 “页眉和页脚” -> “页码” -> “居中”:
页码格式
-
按序点击:“页码” -> “设置页码格式”:
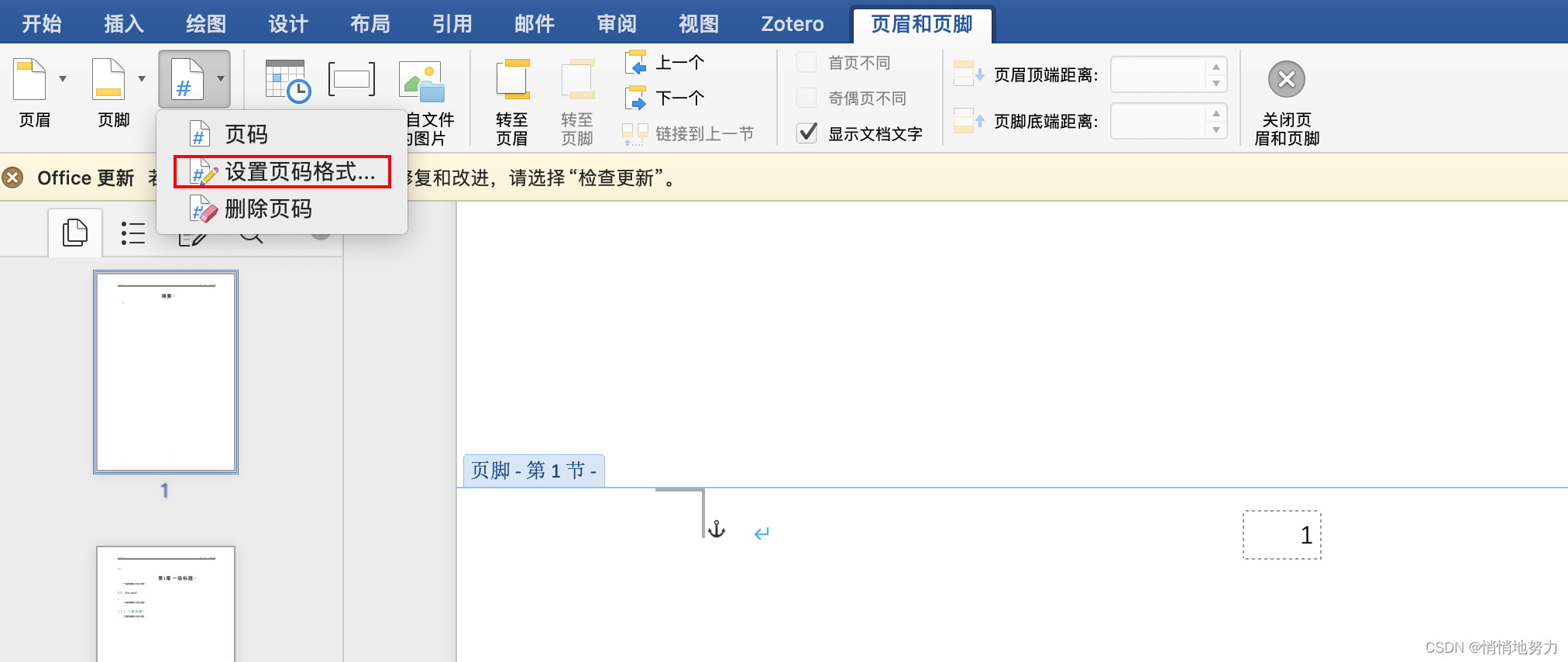
-
由于摘要部分的页码为大写,所以选择 “编号格式” 为大写字母编号:
-
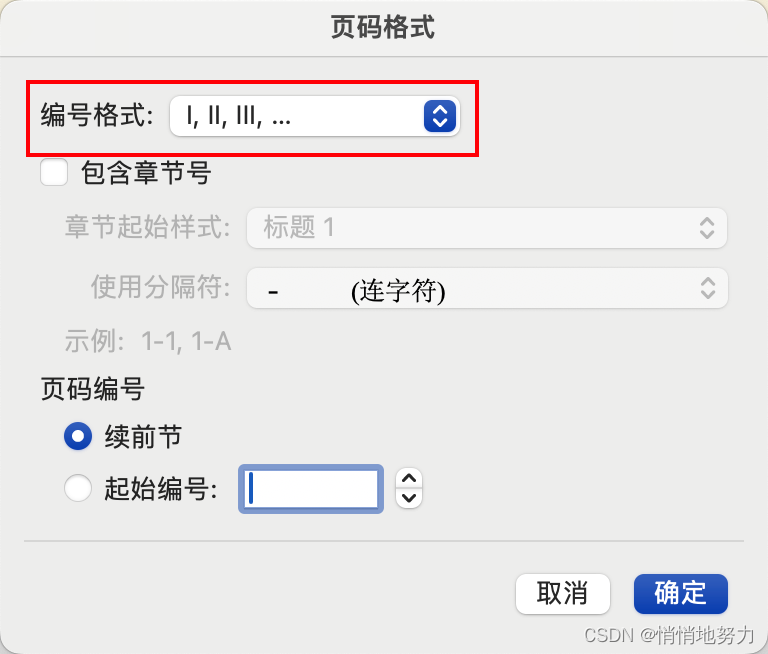
然后在正文部分按序点击:“页码” -> “设置页码格式” -> “编号格式” 选择阿拉伯数字编号 -> 起始编号为 “1”:
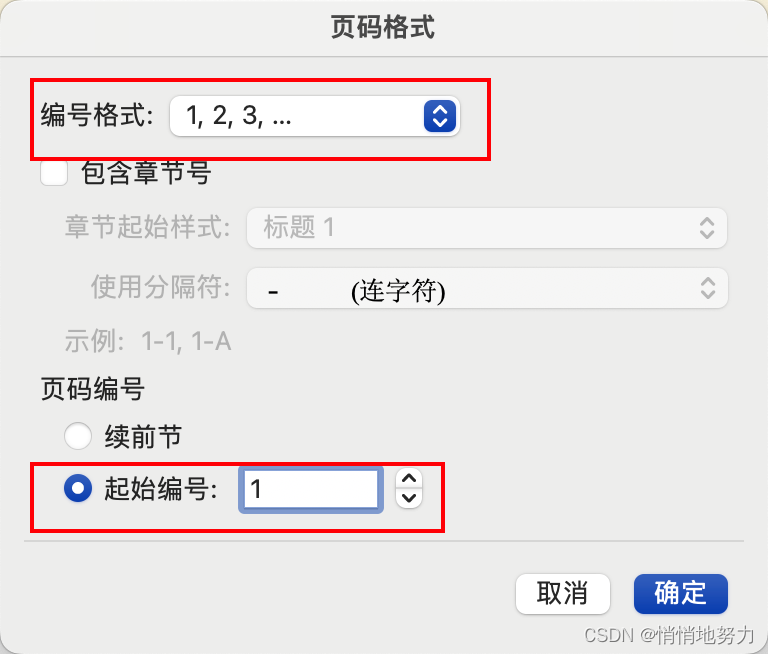
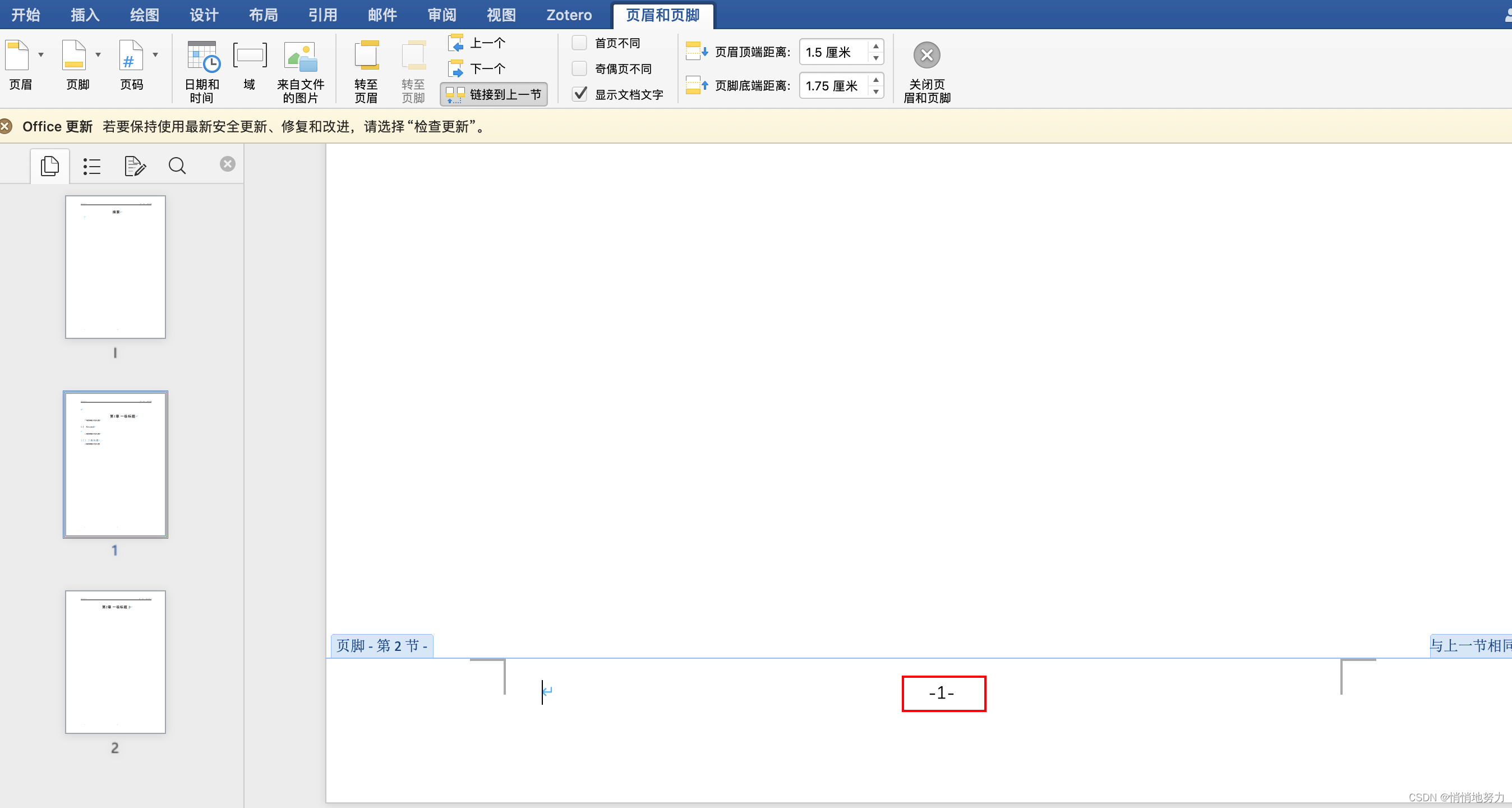
页脚中的页码格式为 -1-,生成目录的页码格式为 1
如果要实现页脚中的页码格式为 -1-,生成目录的页码格式为 1,只需:
- 设置页码格式时选择 1,2,3,…
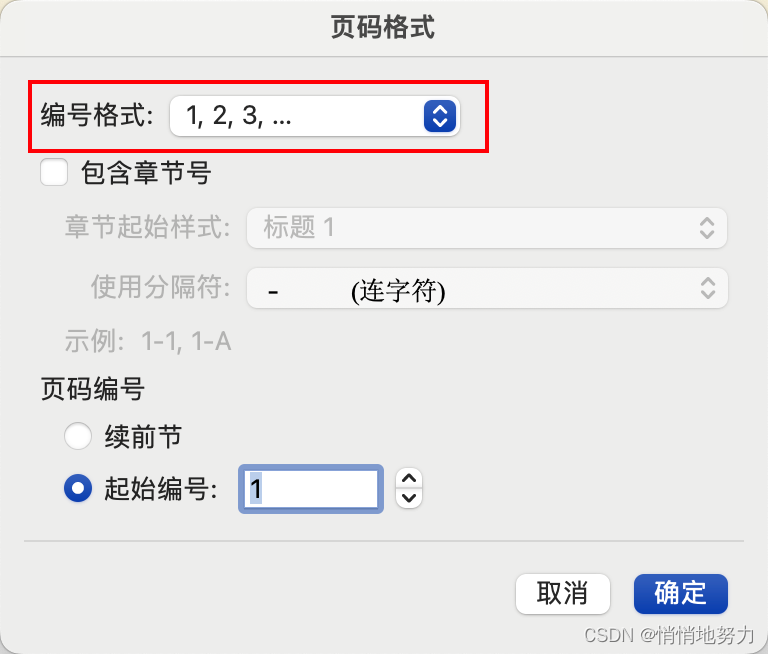
- 然后手动在页码前后加上 -,这样目录中生成的页码前后就不会有 - 了。
目录
自动生成的目录想实现以下效果:
- 标题1
- 黑体
- 小三号字
- 标题 2 和 标题 3
- 宋体
- 小四号字
- 1.5 倍行距
- 依此点击:引用 -> 目录 -> 自定义目录
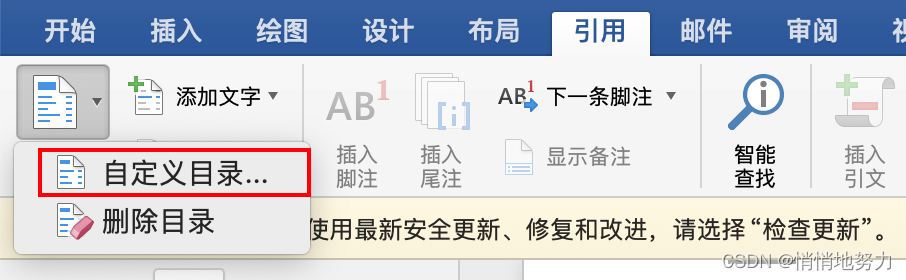
- 点击“修改”:
- 选中 TOC1 表示标题1,然后点击“修改”:
按照同样的步骤选择 TOC2 修改标题 2,选择 TOC3 修改标题 3 的样式即可。
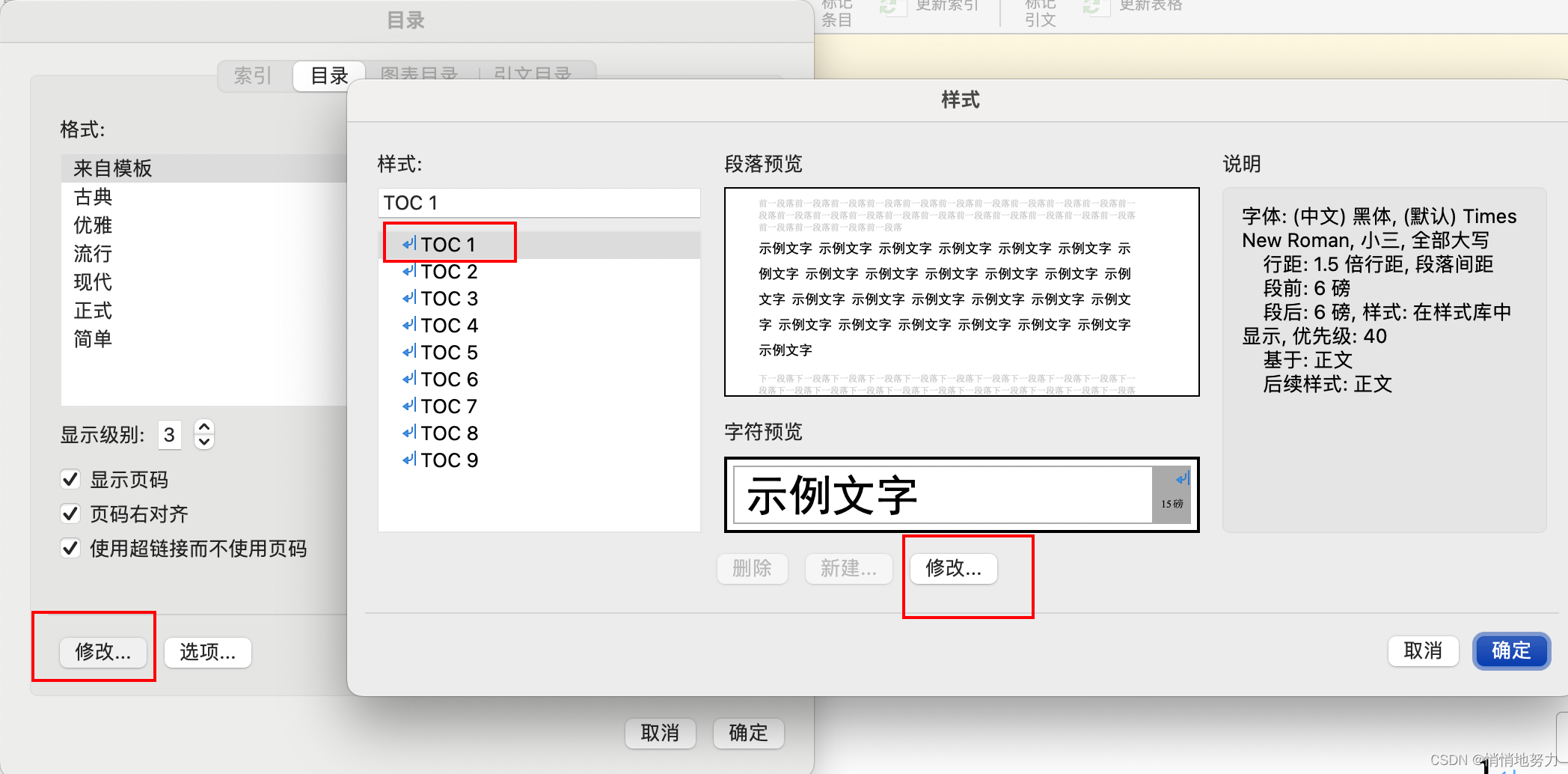
修改目录中标题的字体、字号
- 调整标题 1 为黑体,小三号字:
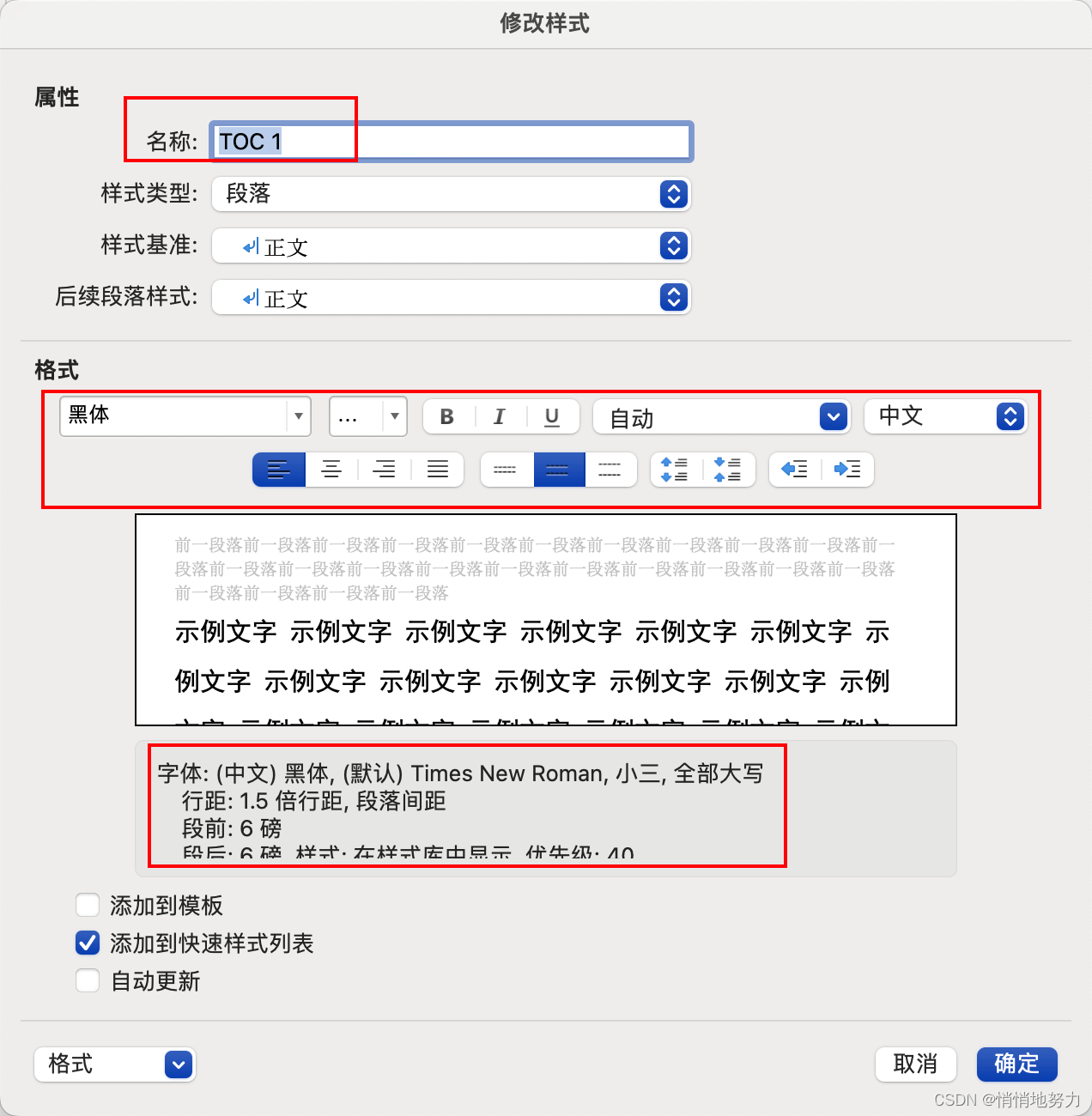
修改目录中的行间距
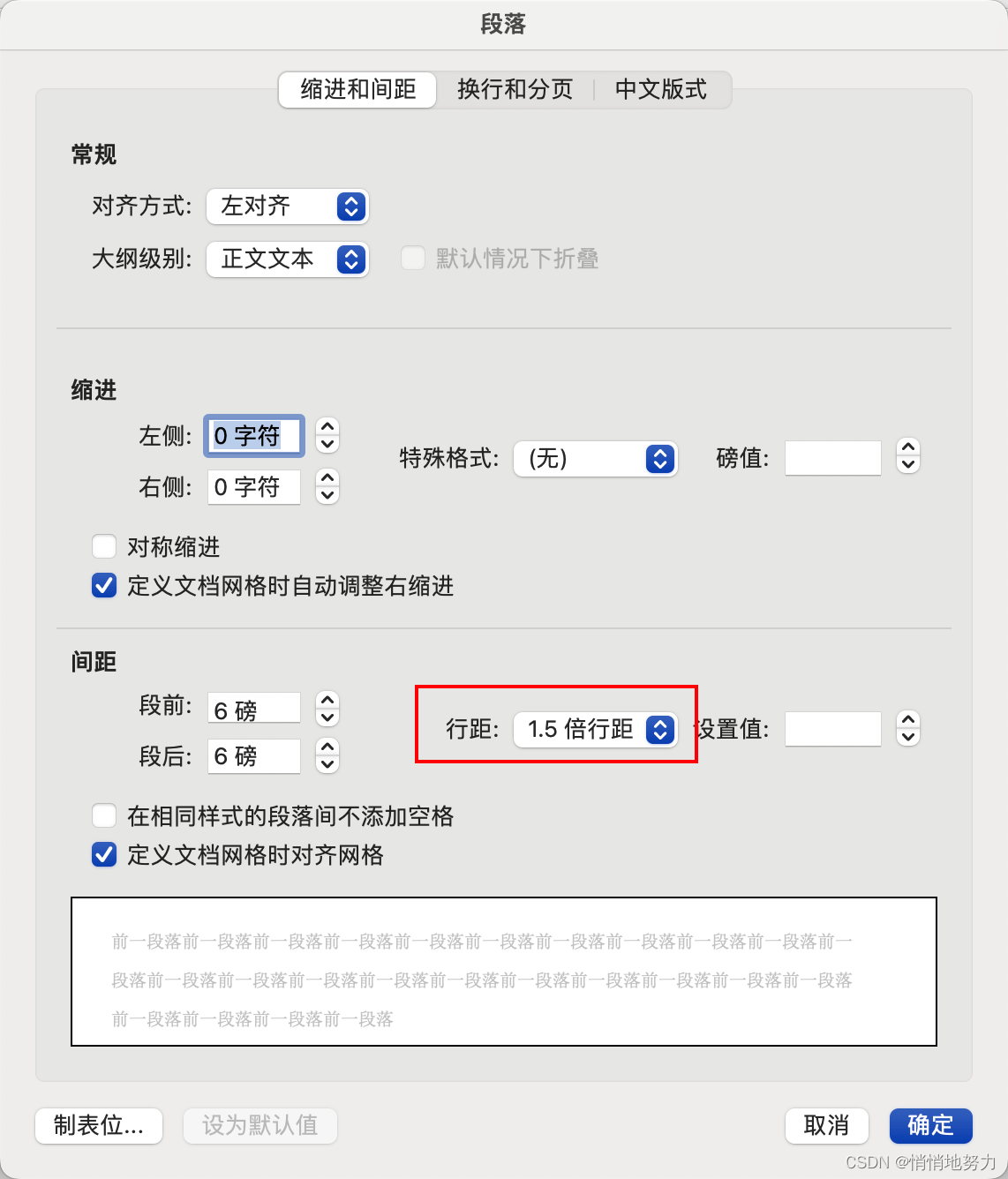
- 依此点击“格式” -> “段落”
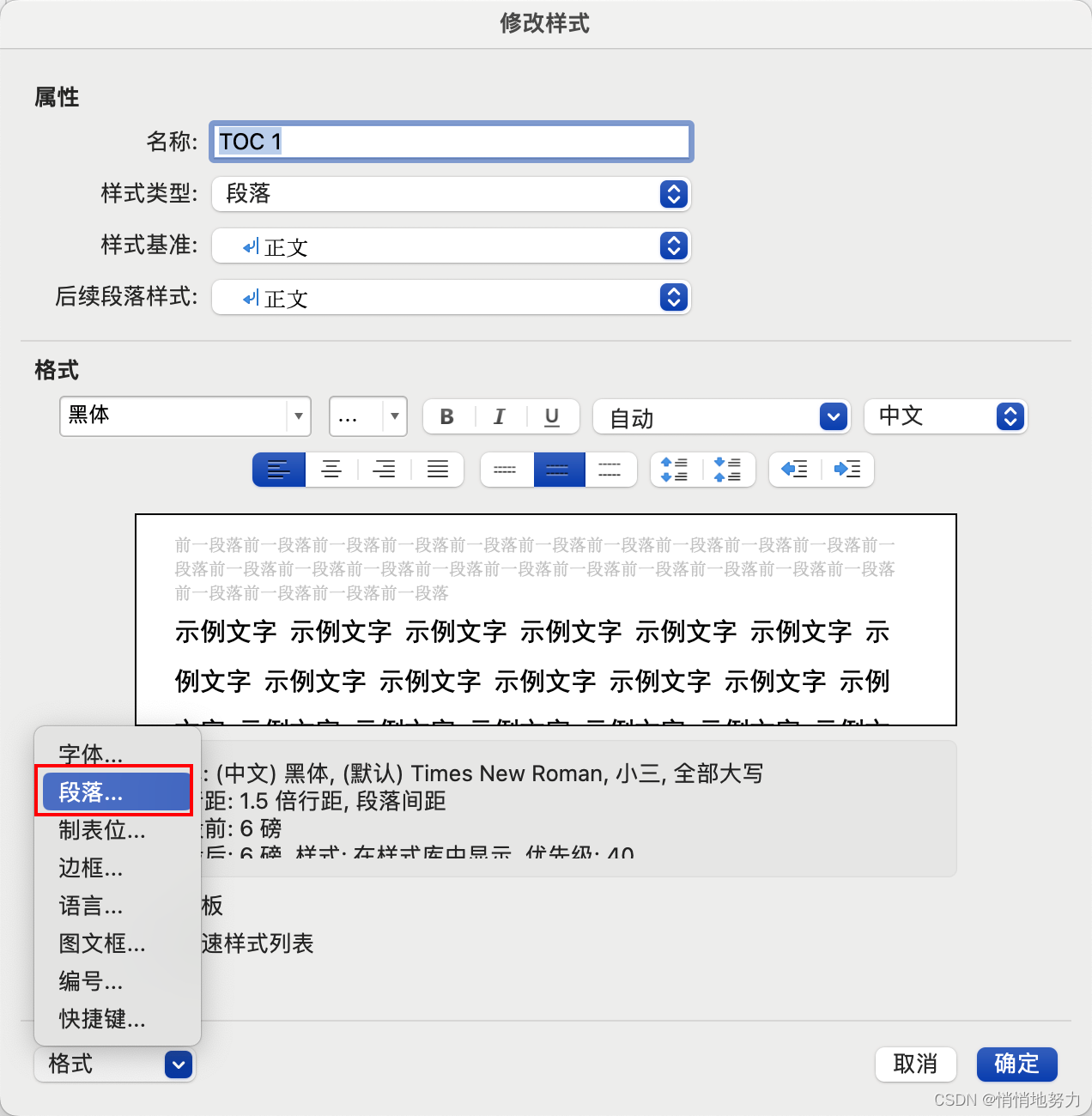
- 调整行间距为 1.5 倍:
标题自动编号
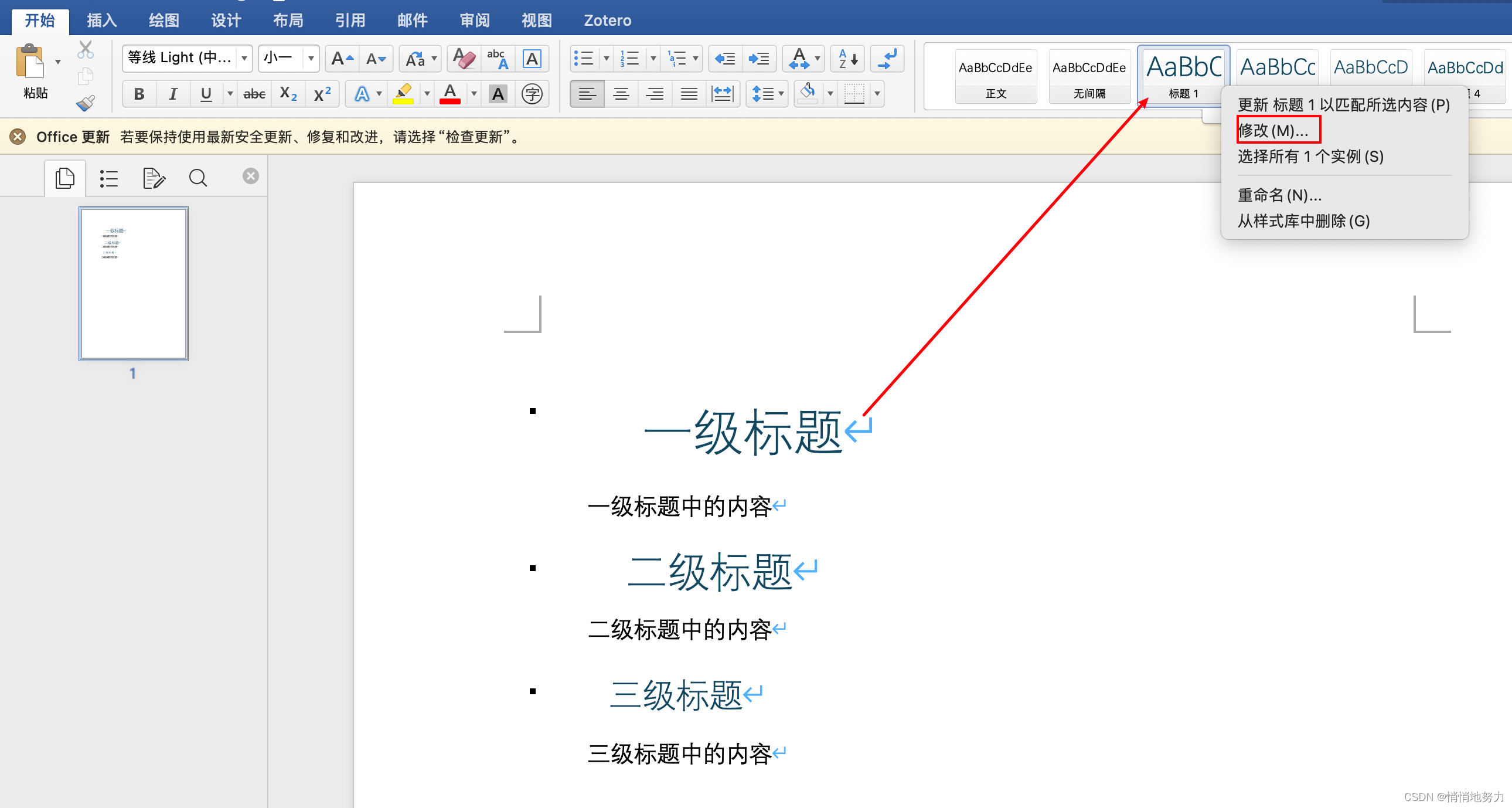
标题1
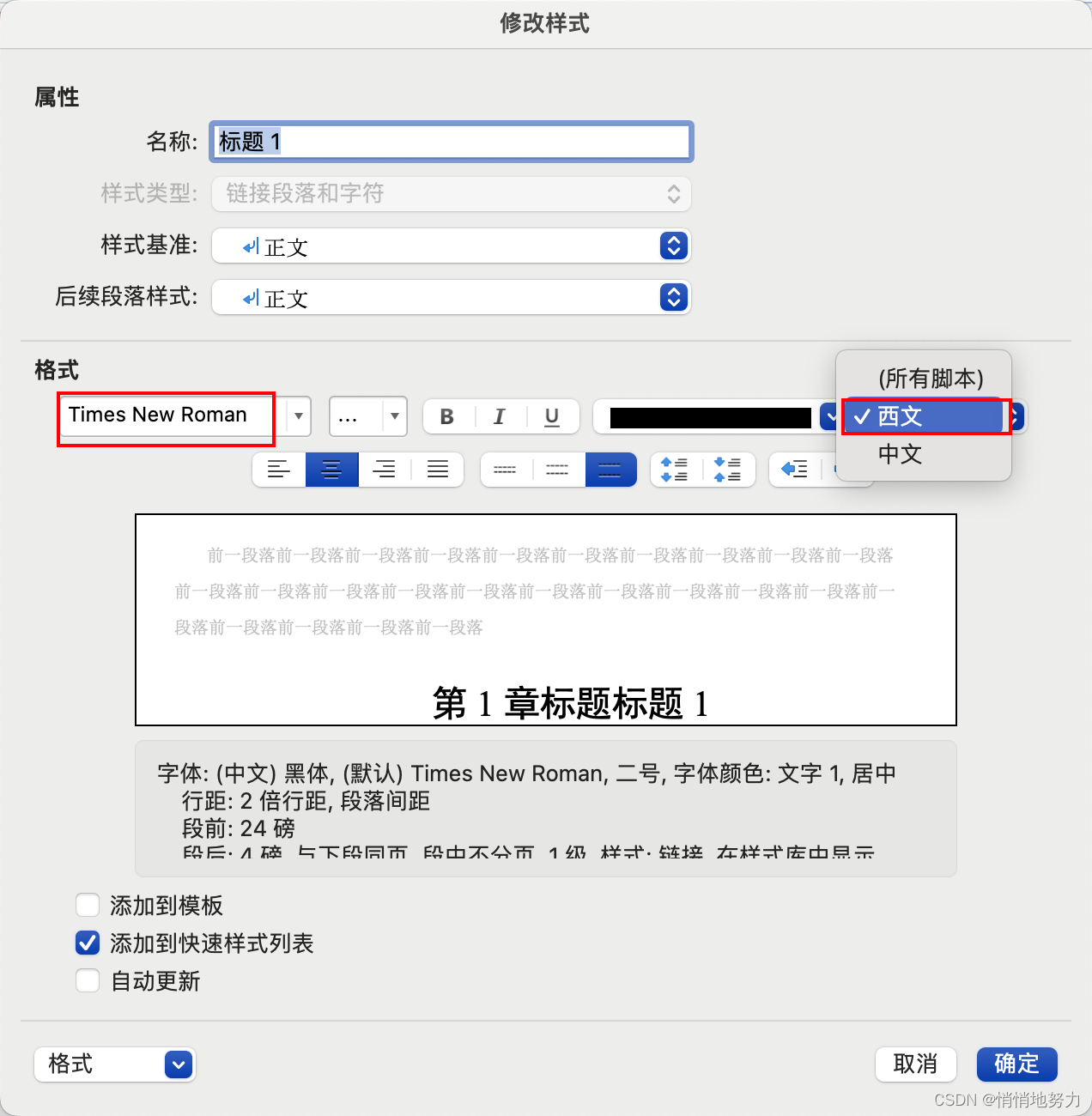
- 首先选中标题1,然后点击 “开始” -> “标题1” -> 鼠标右键 -> 点击“修改”:
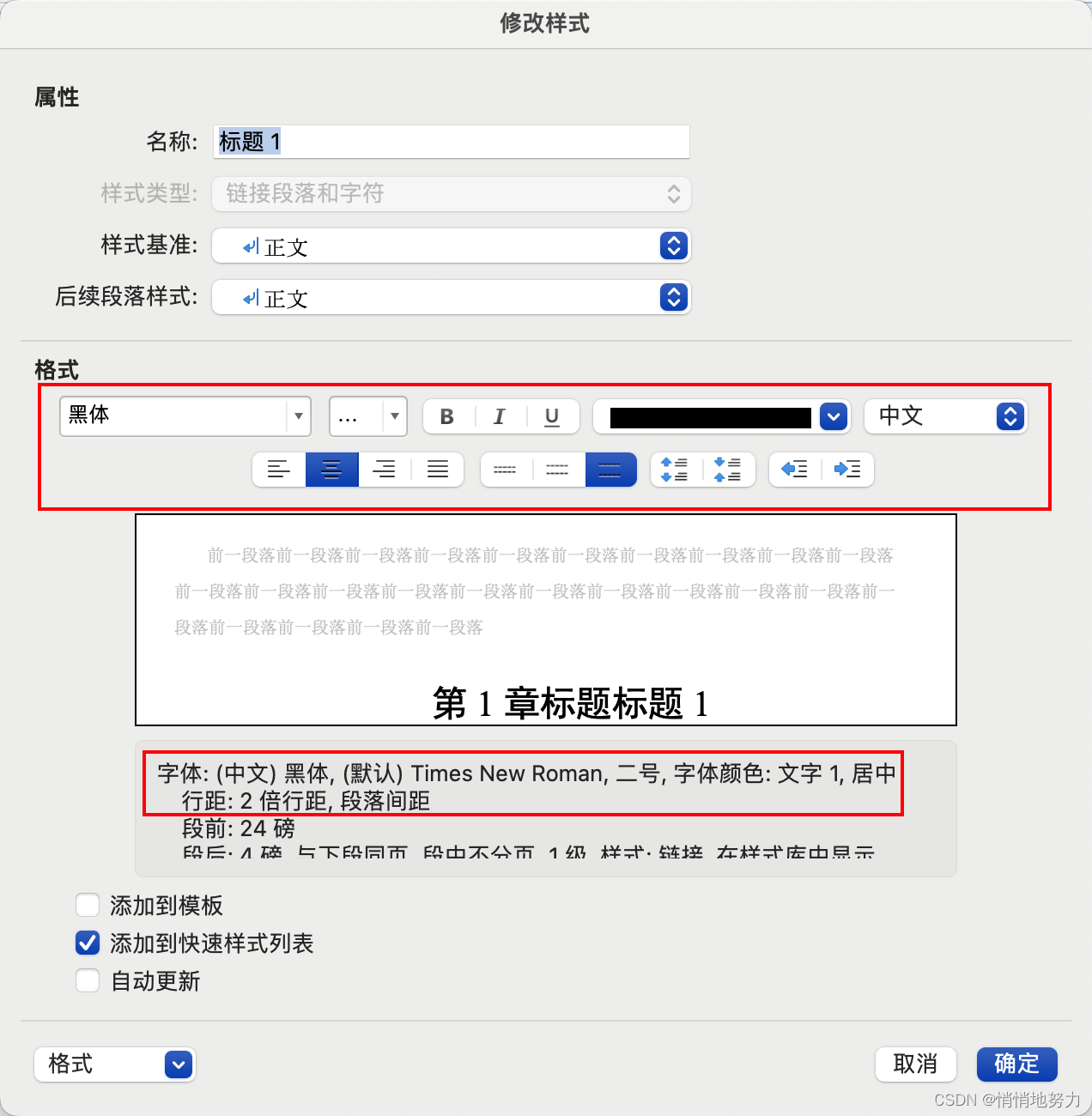
字体字号
- 按照如下设置标题1的中文字体为“黑体”,字号为“二号”,颜色为“黑色”,“居中”显示,行距为 “2倍”:
如果有需要,可以按照如下设置标题1的英文字体为“Times New Roman”:
多级编号
-
然后设置标题自动编号。点击左下角的“格式” -> “编号”
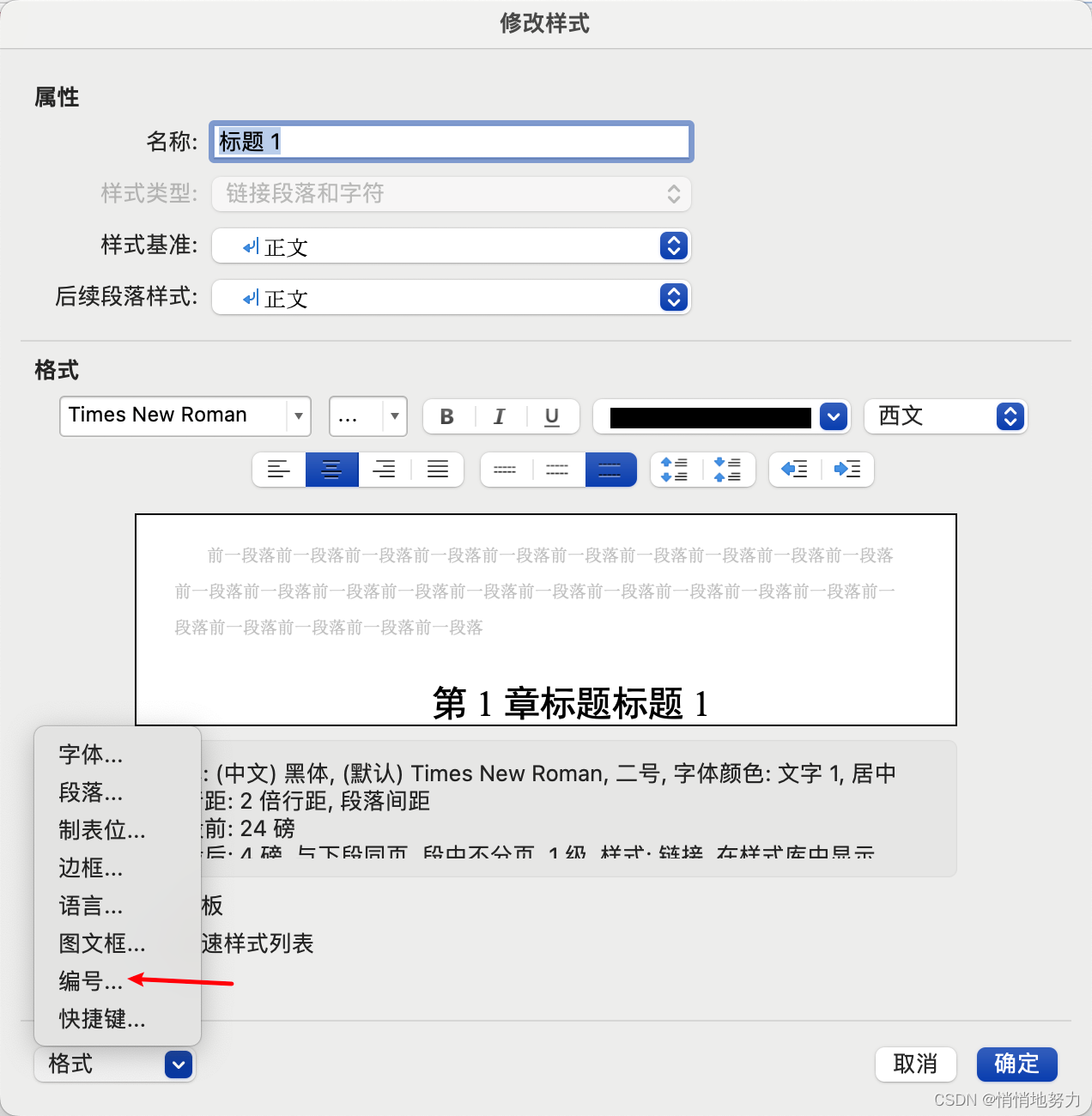
-
然后根据需要选择多级编号,然后点击“自定义”:
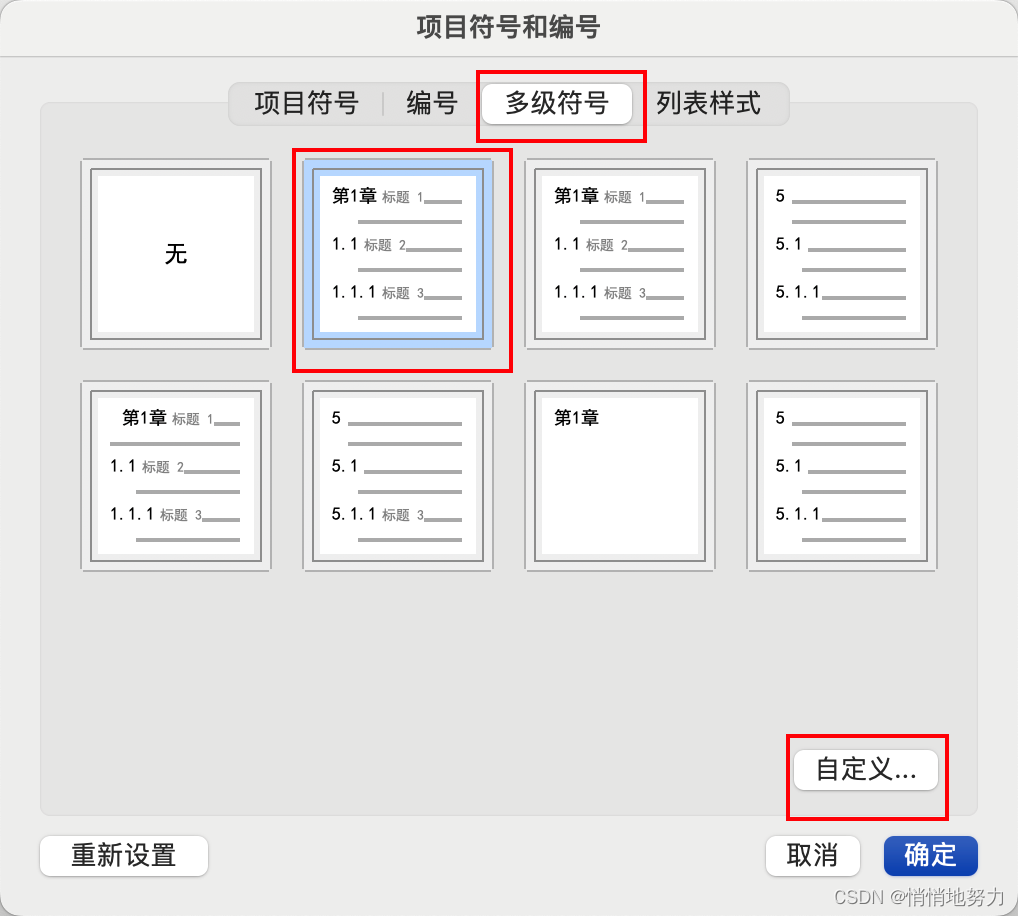
-
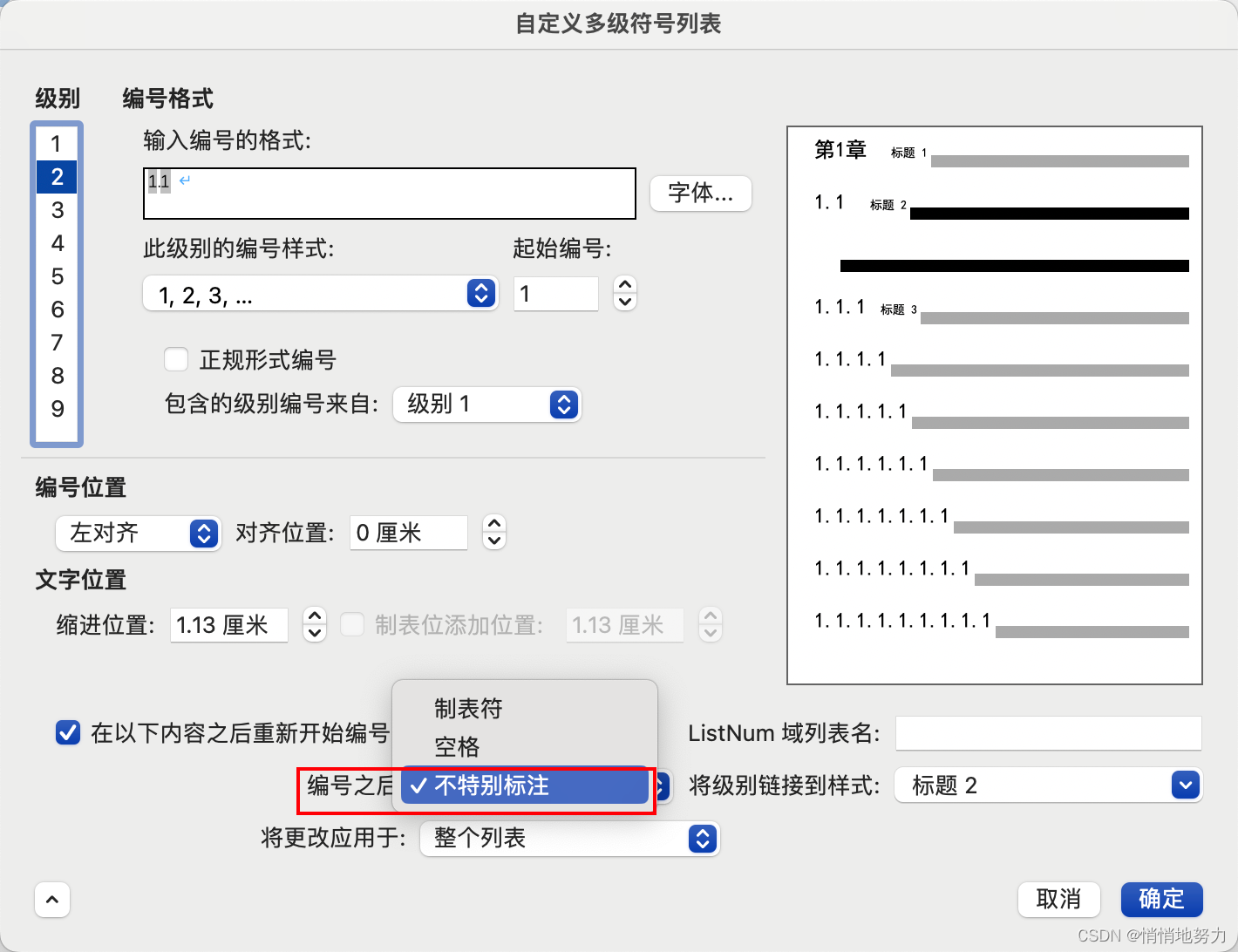
设置一级标题的编号:
- 内容为第x章,x编号从1开始
- 编号之后:不特别标注
- 如果自动编号生成的标题序号与文字之间间隔过大,可以通过这样设置来改变
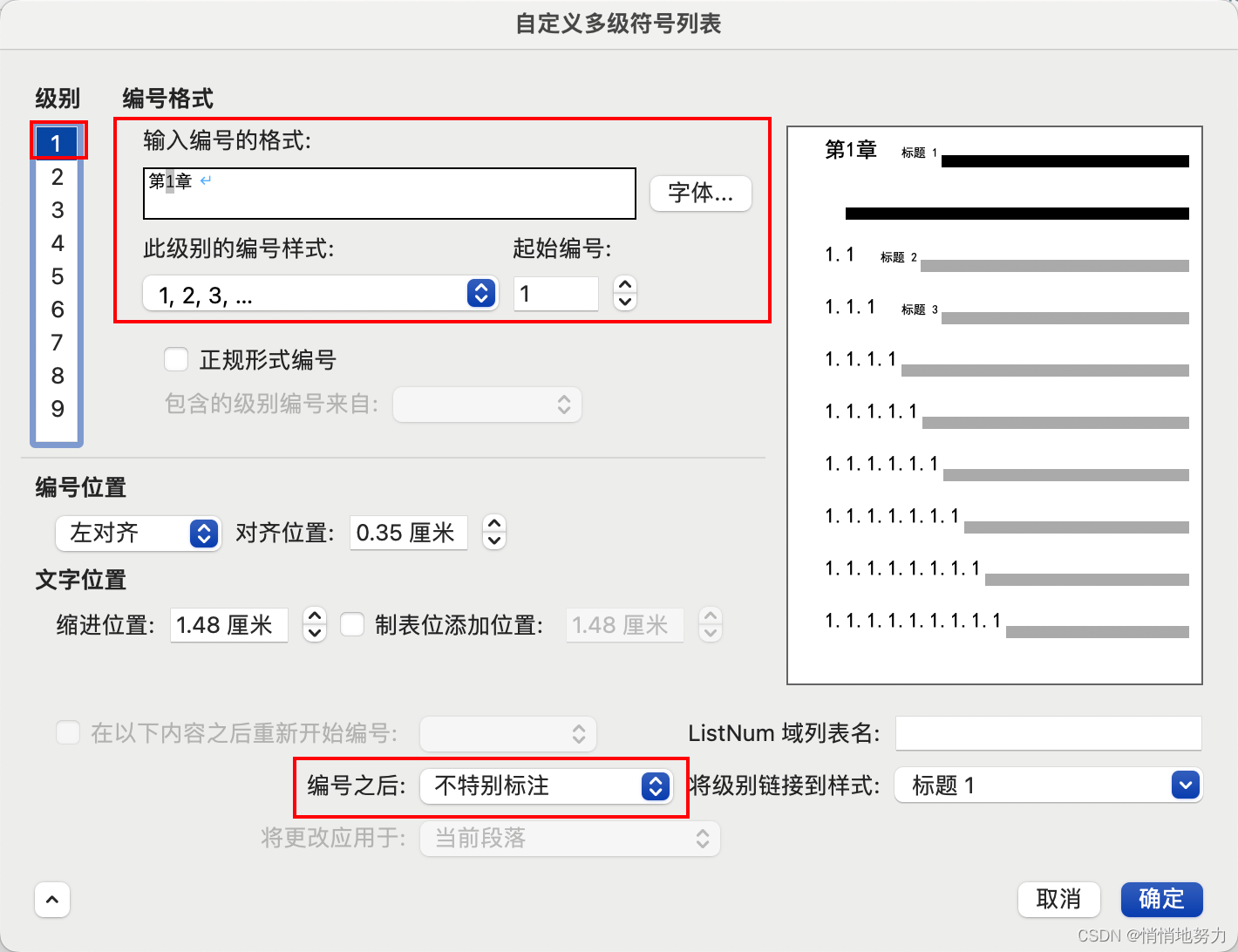
- 如果自动编号生成的标题序号与文字之间间隔过大,可以通过这样设置来改变
段落
- 依此点击“格式” -> “段落”:
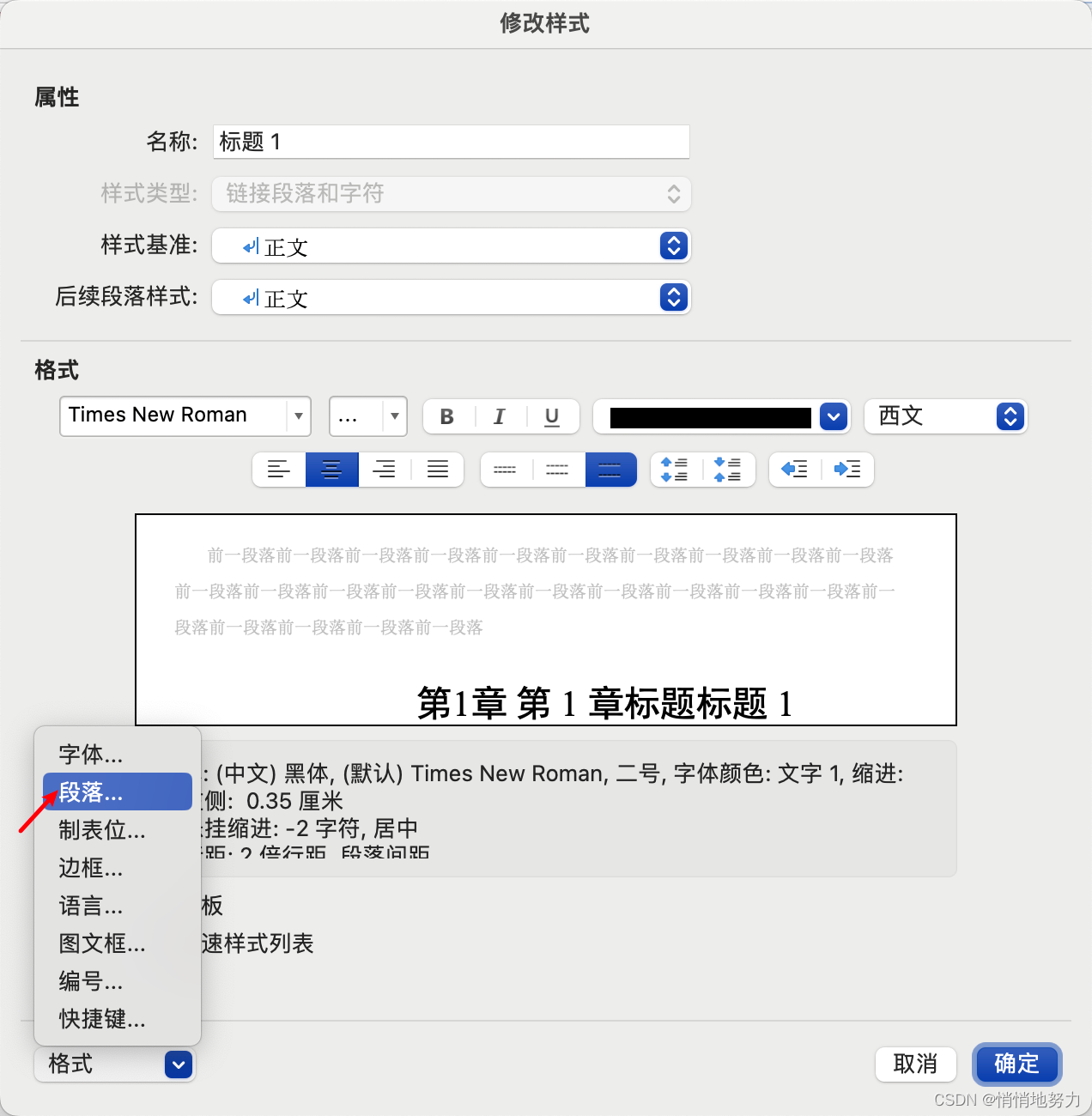
- 按照需要设置段落格式即可:

标题2、3同理
相关问题说明
调整标题缩进
如果发现设置的标题2前面的缩进很大,如下所示:

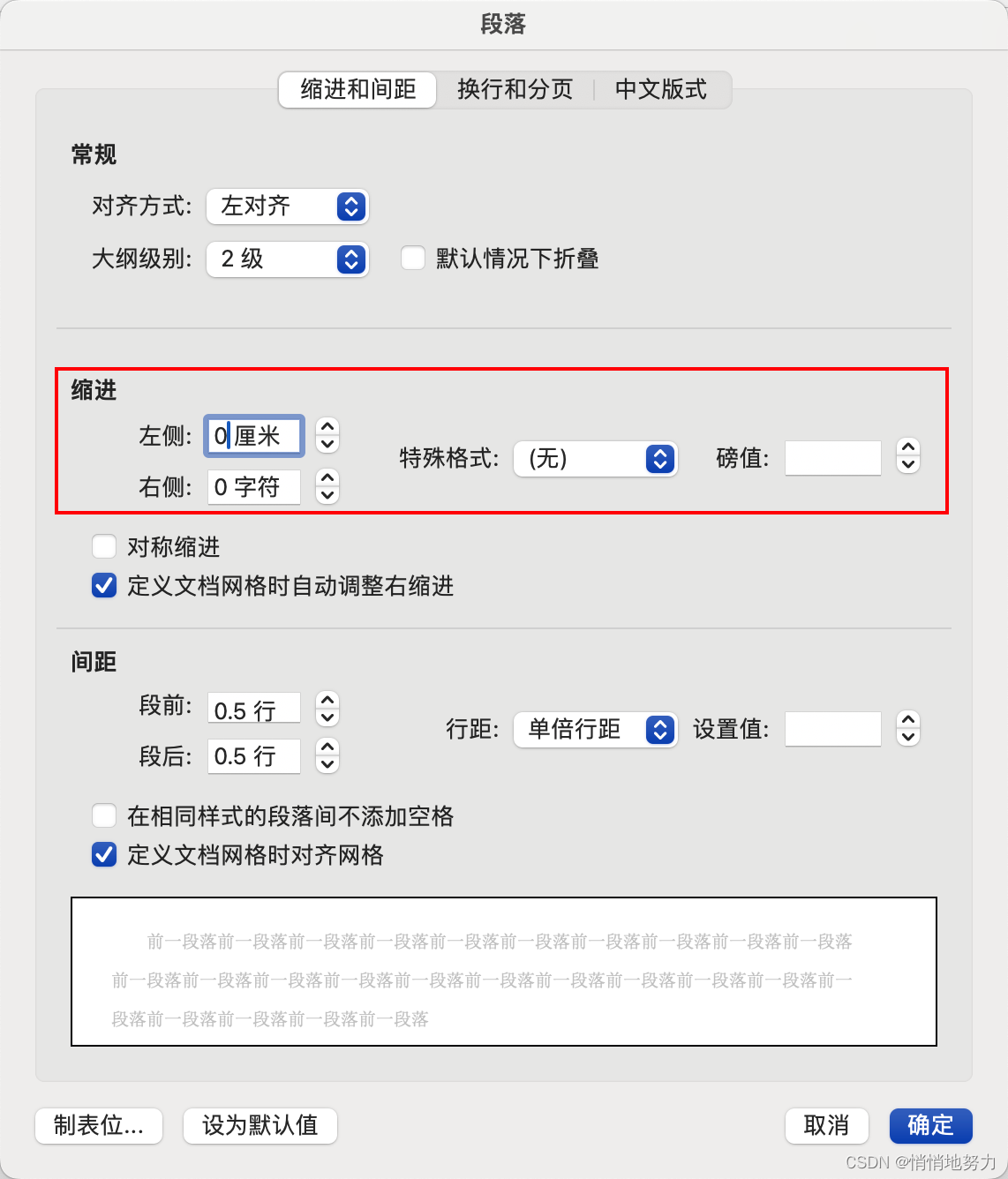
只需选中序号 -> 右键 -> 点击“段落”:

然后按需调整缩进的值即可:
编号与文字之间空隙过大
如果自动编号生成的标题序号与文字之间间隔过大,可以通过这样设置来改变:
选中序号 -> 右键 -> 点击“项目符号和列表”:
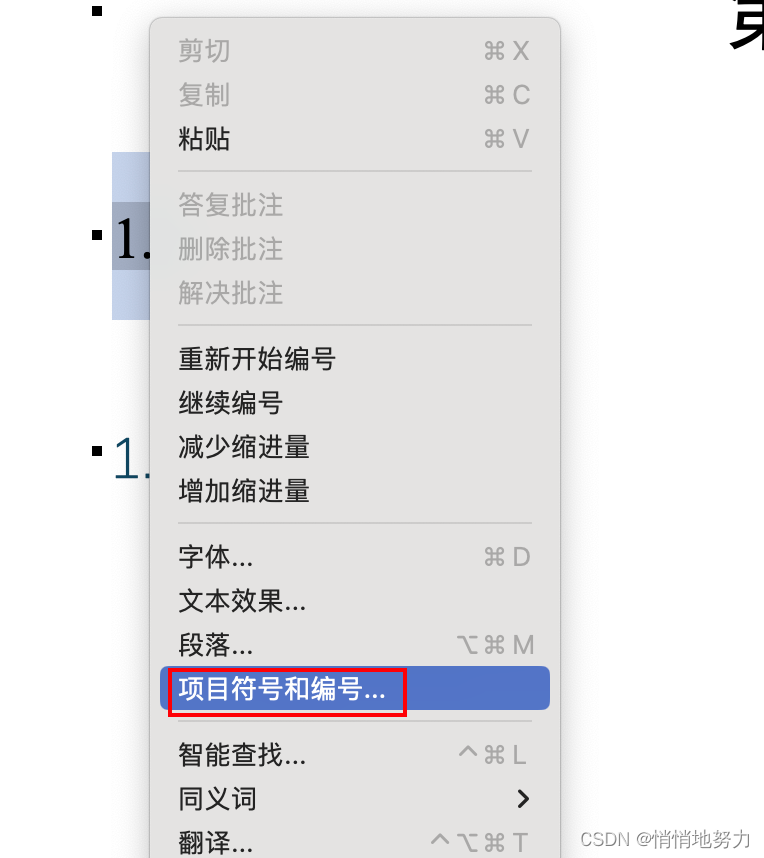
然后设置 “编号之后” 为 “不特别标注”: