校园视频网站建设网站建设公司财务预算

Kotlin设计模式:深入理解桥接模式
在软件开发中,随着系统需求的不断增长和变化,类的职责可能会变得越来越复杂,导致代码难以维护和扩展。桥接模式(Bridge Pattern)是一种结构型设计模式,它通过将类的实现和抽象分离来解决这一问题,从而使它们可以独立变化。本文将详细介绍桥接模式的用途、优点、缺点以及一个实际的示例代码,帮助开发者更好地理解和应用这一设计模式。
为什么使用桥接模式?
桥接模式的主要目的是将一个类拆分为两个独立的层次结构,使它们可以独立地增长和扩展。通过将一个类的职责分离到多个具有单一职责的类中,我们可以更好地管理和维护代码。
使用桥接模式的优点
- 职责分离:通过将不同的职责分离到独立的类中,可以更容易地找到并修改代码片段。
- 单一职责原则:每个类只有一个职责,使代码更简洁和易于维护。
- 开闭原则:可以引入新的层次结构而不改变现有的代码。
- 线性增长:代码库的增长是线性的,而不是指数级的。
- 代码封装:通过使用抽象而不是具体类,可以更好地封装代码。
使用桥接模式的缺点
- 类的高耦合:类之间可能变得过于紧密,降低了代码的重用性。
- 增加复杂性:引入额外的抽象层可能会使代码库变得更复杂。
示例
假设你正在开发一个项目,任务是实现桌子和椅子的生产功能。桌子和椅子可以由木头或金属制成。你需要确保添加新的家具类型或材料不会干扰现有的功能。这正是桥接模式的一个完美应用场景。
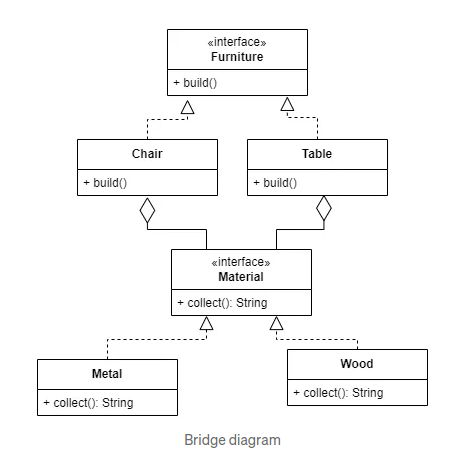
定义材料接口和实现类
首先,我们定义一个 Material 接口,并创建两个实现类 Wood 和 Metal。
interface Material {fun collect(): String
}class Wood : Material {override fun collect() = "wood"
}class Metal : Material {override fun collect() = "metal"
}
定义家具接口和实现类
接下来,我们定义一个 Furniture 接口,并创建两个实现类 Chair 和 Table,它们使用不同的材料来建造。
interface Furniture {fun build()
}class Chair(private val material: Material) : Furniture {override fun build() {println("Building Chair from " + material.collect())}
}class Table(private val material: Material) : Furniture {override fun build() {println("Building Table from " + material.collect())}
}
使用桥接模式
现在,我们可以使用桥接模式来创建不同材料的家具对象。
fun main() {val woodenTable: Furniture = Table(material = Wood())val metalTable: Furniture = Table(material = Metal())woodenTable.build() // 输出:Building Table from woodmetalTable.build() // 输出:Building Table from metalval woodenChair: Furniture = Chair(material = Wood())val metalChair: Furniture = Chair(material = Metal())woodenChair.build() // 输出:Building Chair from woodmetalChair.build() // 输出:Building Chair from metal
}
通过这种方式,我们成功地将家具类型和材料类型分离,使得它们可以独立地扩展。添加新的材料或家具类型不需要修改现有的代码,只需实现相应的接口即可。
结论
桥接模式是一个强大的设计模式,通过将类的实现和抽象分离,使它们可以独立地变化,解决了类职责过于复杂的问题。虽然引入了额外的抽象层,可能增加了一些复杂性,但它带来的代码可维护性和扩展性显然是值得的。通过本文的示例,希望读者能更好地理解和应用桥接模式,为自己的项目带来更多的灵活性和可维护性。
希望这篇文章能帮助你更好地理解桥接模式,并能在实际开发中灵活应用。Happy Coding!