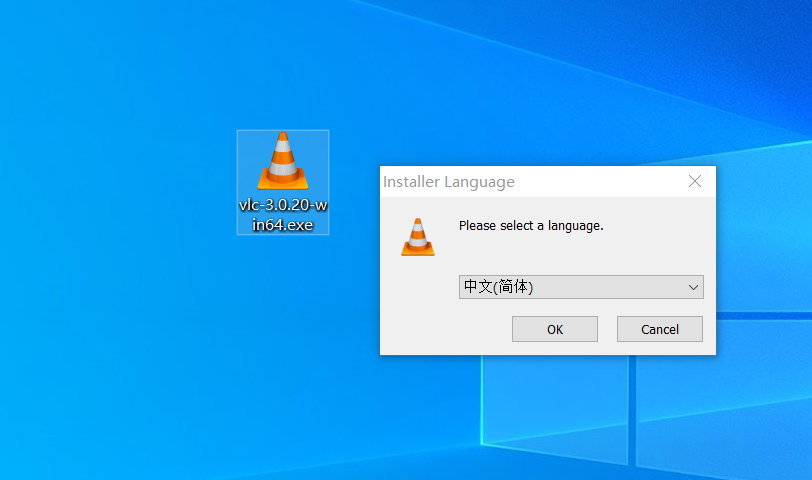
建设厅教育培训网站网站建设灬金手指科杰
一、简介
VLC播放器(全称VideoLAN Client)是一款开源的多媒体播放器,由VideoLAN项目团队开发。它支持多种音视频格式,并能够在多种操作系统上运行,如Windows、Mac OS X、Linux、Android和iOS等。VLC播放器具备播放文件、光盘、摄像头、设备及流媒体等多媒体内容的强大能力,而且不需要安装额外的编解码器包;
全称VideoLAN Client媒体播放器,是一个开源的跨平台媒体播放器和多媒体框架。VLC最初由法国的École Centrale Paris的学生开发,旨在提供一种能够播放多种格式的音频和视频文件的轻量级播放器。
VLC以其强大的功能和广泛的兼容性而闻名。它支持播放几乎所有主流的视频和音频格式,包括MPEG-2、MPEG-4、H.264、DivX、MP3、AAC等。VLC还支持DVD、音频CD、VCD等不同的媒体格式。无论是本地文件还是网络流媒体,VLC都可以轻松处理。
作为开源软件,VLC得到了全球各地开发者的贡献和支持。它在不同操作系统上都能够运行,包括Windows、MacOS、Linux、Android等。用户可以轻松地在官方网站上免费下载并安装VLC,享受其无限制的功能。
VLC不仅是一个简单的媒体播放器,还具有许多高级的功能。它支持网络流媒体、视频捕捉、转码、字幕加载、屏幕录制等功能。用户可以自定义播放界面、调整各种参数,并且可以通过插件扩展功能。
在用户友好方面,VLC也做得相当不错。它拥有简洁直观的用户界面,使用户可以轻松地导航和控制播放。同时,VLC还提供了丰富的用户文档和帮助文档,以便用户更好地了解和使用这款软件。
软件平台
-
Windows
-
Mac OS X
-
GNU/Linux
-
Android
-
iOS
-
Unix
特色
-
跨平台支持
-
无需安装编解码器
-
播放多种格式
使用技巧及注意事项
-
VLC支持播放未下载完成的视频文件部分内容
-
VLC有一个好的功能,就是可以播放某些没有下载完成的视频文件
-
从版本0.8.2开始,VLC提供了一个ActiveX的扩充包,使用户可以在Internet Explorer下播放某些多媒体文件
-
VLC的ActiveX扩充包在1.0.5版本后不再使用js接口调用
-
VLC还支持硬件加速解码
-
VLC支持播放列表、媒体库、本地网络和互联网媒体源
-
VLC播放器截图快捷键为Shift+S,默认保存位置为用户的图片文件夹
-
VLC播放器还提供了录制、截图、循环播放等多种高级控制功能
主要模块与功能组件
-
核心模块: 包含主事件循环、播放控制、播放列表等功能
-
模块加载器: 包含各种解码器、格式解复用器、过滤器等
-
跨平台兼容层: 提供跨平台支持
-
用户界面: 提供不同操作系统的原生使用体验
-
测试与工具: 用于VLC播放器开发的测试和辅助工具
播放速度控制
-
播放速度控制涉及到多个模块,如输入线程、音频输出模块和视频输出模块
-
解码器也与播放速度控制有关,如音频解码器中的Pitch Shifting功能
二、下载
1、下载地址:
官方下载:VLC media player,最棒的开源播放器 - VideoLAN
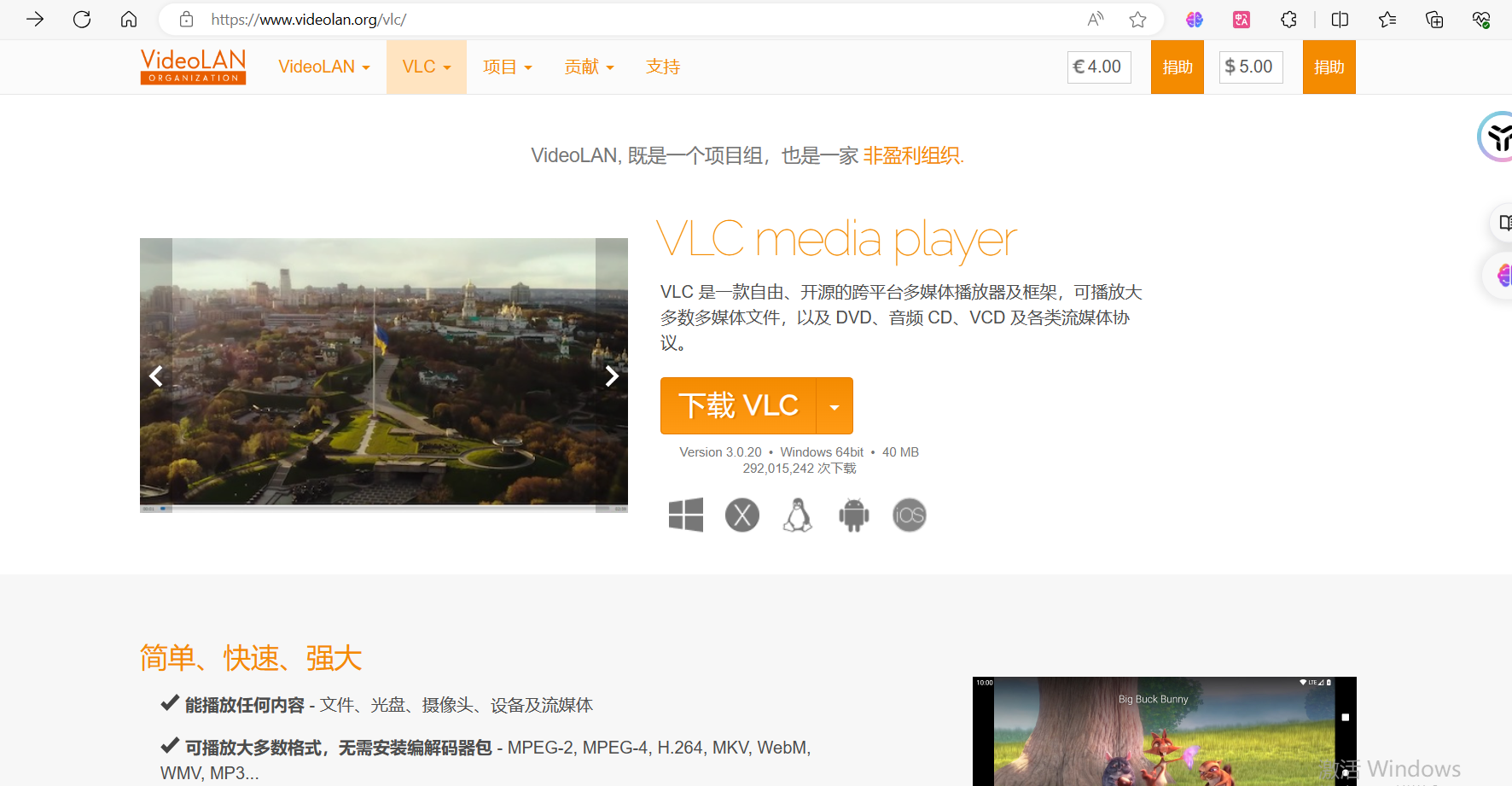
2、根据自己需要的版本,点击下载即可

3、选择简体中文安装,即可安装成功;将视频拖入或者设置为默认播放器即可播放(麻烦咚咚咚,动动小手给个关注收藏小三连,我将继续努力为大家寻找以及保存更好的软件以及操作手册,谢谢各位哥哥姐姐们啦!!)