东莞容桂网站制作专做项目报告的网站
目录
一、labelme安装指令
二、使用教程
三、 快捷键
一、labelme安装指令
win+R之后在弹出的对话框中输入cmd按回车进入终端
conda activate 虚拟环境名称
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple/二、使用教程
安装成功之后在终端输入labelme可以直接打开标注界面

打开后出现如下界面

1、选择要标注的图片文件夹
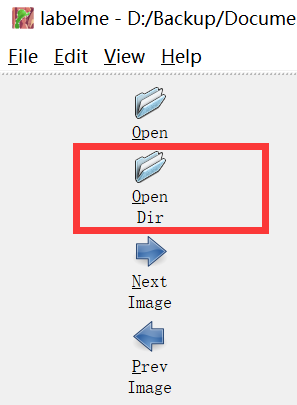
2、选择json文件要保存的文件夹,并设置为自动保存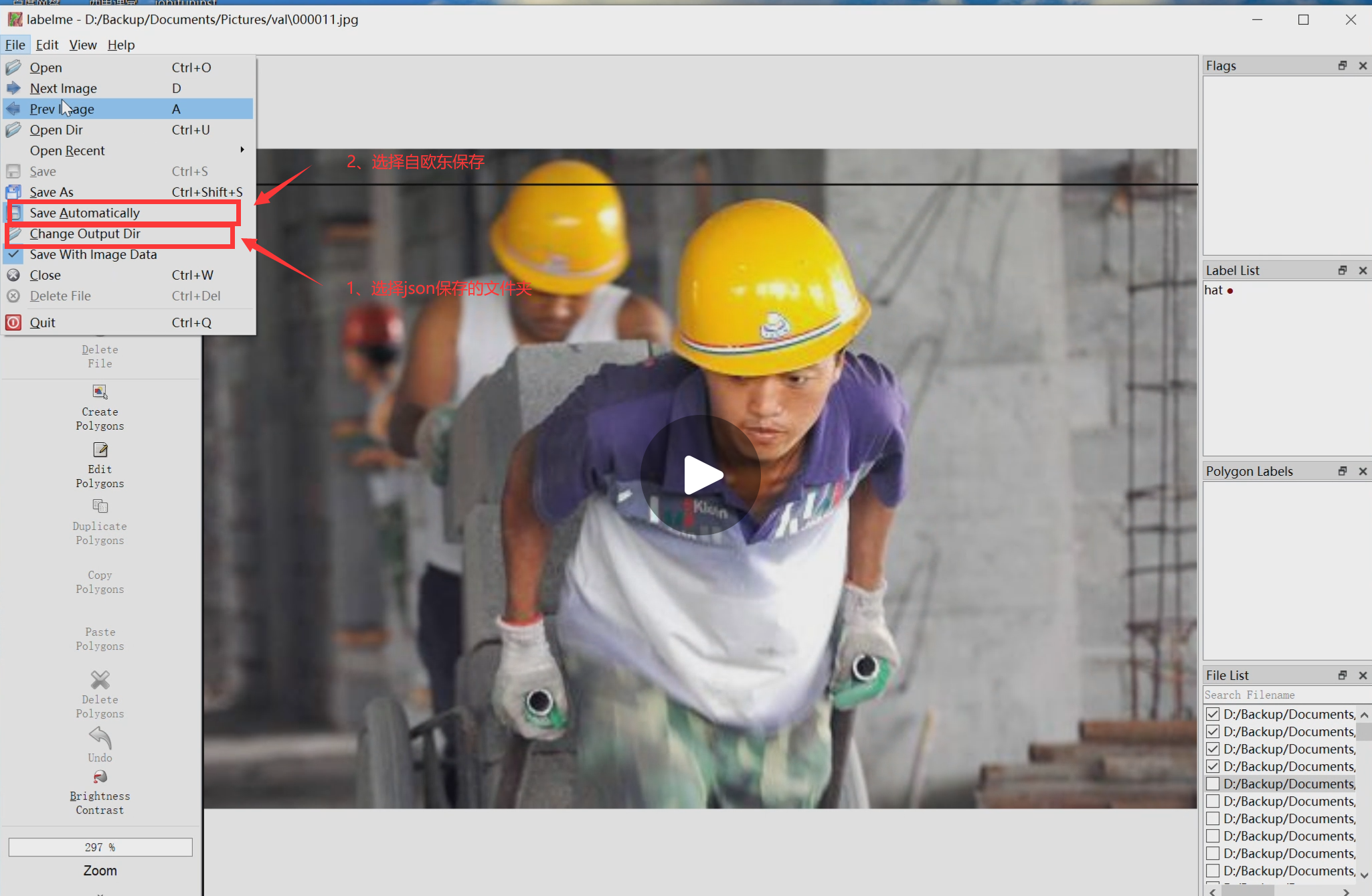
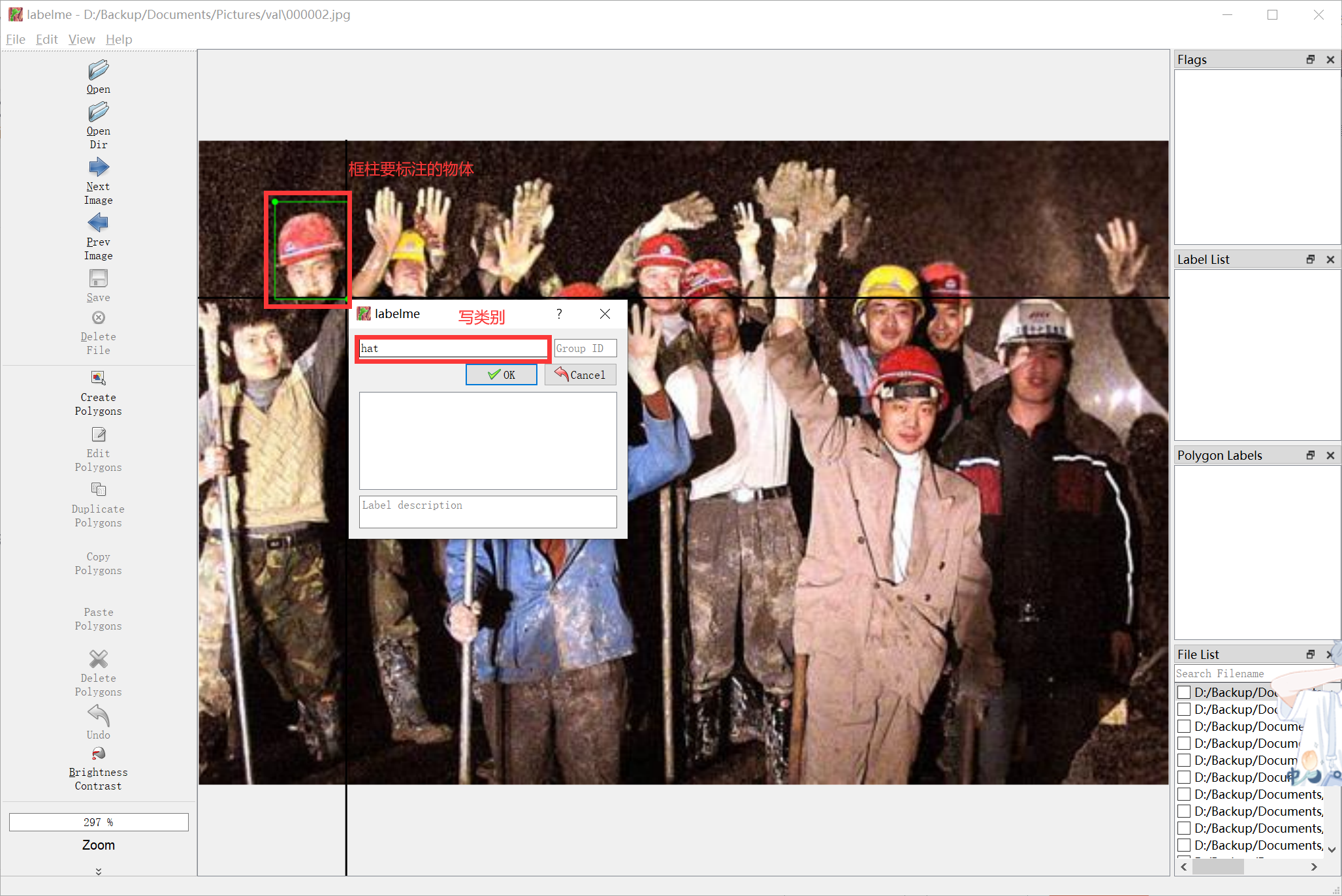
3、 选择创建 长方形,同时按住ctrl+R,框选物体,并写类别
4、下一章图片继续标注
三、 快捷键
d 下一章图片
a 前一张图片
ctrl+U 打开文件夹
ctrl+shift+s 另存为
ctrl+s 保存
ctrl+q 退出