广州网站开发创意设计公司中小企业网站开发
前言:
为什么要整合apache和tomcat
apache对静态页面的处理能力强,而tomcat对静态页面的处理不如apache,整合后有以下好处
- 提升对静态文件的处理性能
- 利用 Web 服务器来做负载均衡以及容错
- 更完善地去升级应用程序
jk整合方式介绍(较为普遍的方式)
- jk是通过 AJP 协议与 Tomcat 服务器进行通讯
- Tomcat 默认的 AJP Connector 的端口是 8009(在tomcat的server.xml文件中默认被注释掉)
- JK 本身提供了一个监控以及管理的页面 jkstatus,通过 jkstatus 可以监控 JK 目前的工作状态以及对到tomcat 的连接进行设置
目录
一.准备apache、tomcat、jk环境
1.apache和tomcat配置专栏其它文章有介绍,不过多阐述
2.编译安装jk环境
二.配置jk模块以实现整合
1.以我的安装路径为例首先将/usr/local/src/tomcat-connectors-1.2.48-src/native/apache-2.0/mod_jk.so这个文件拷贝到/etc/httpd/modules
2.配置mod_jk.conf文件,我同意放在/etc/httpd/conf下的
3.配置workers.properties,上面定义的在那个位置就创建在哪个位置
4.更改/etc/httpd/conf/httpd.conf
三.更改tomcat的server.xml配置
1.按照自己的tomcat安装位置查找该文件
2.在文件中找到AJP的这个位置,将Connector原有注释取消掉并进行配置
注意:
四.创建测试界面(谨慎使用中文)
1.apache测试文件,这里以默认的html目录为例
2.tomcat测试文件,放在你tomcat安装目录中的webapps/ROOT目录下
五.测试
一.准备apache、tomcat、jk环境
1.apache和tomcat配置专栏其它文章有介绍,不过多阐述
[root@localhost native]# yum install -y httpd httpd-devel.x86_64 gcc gcc-c++ make2.编译安装jk环境
可以到镜像网站下载包
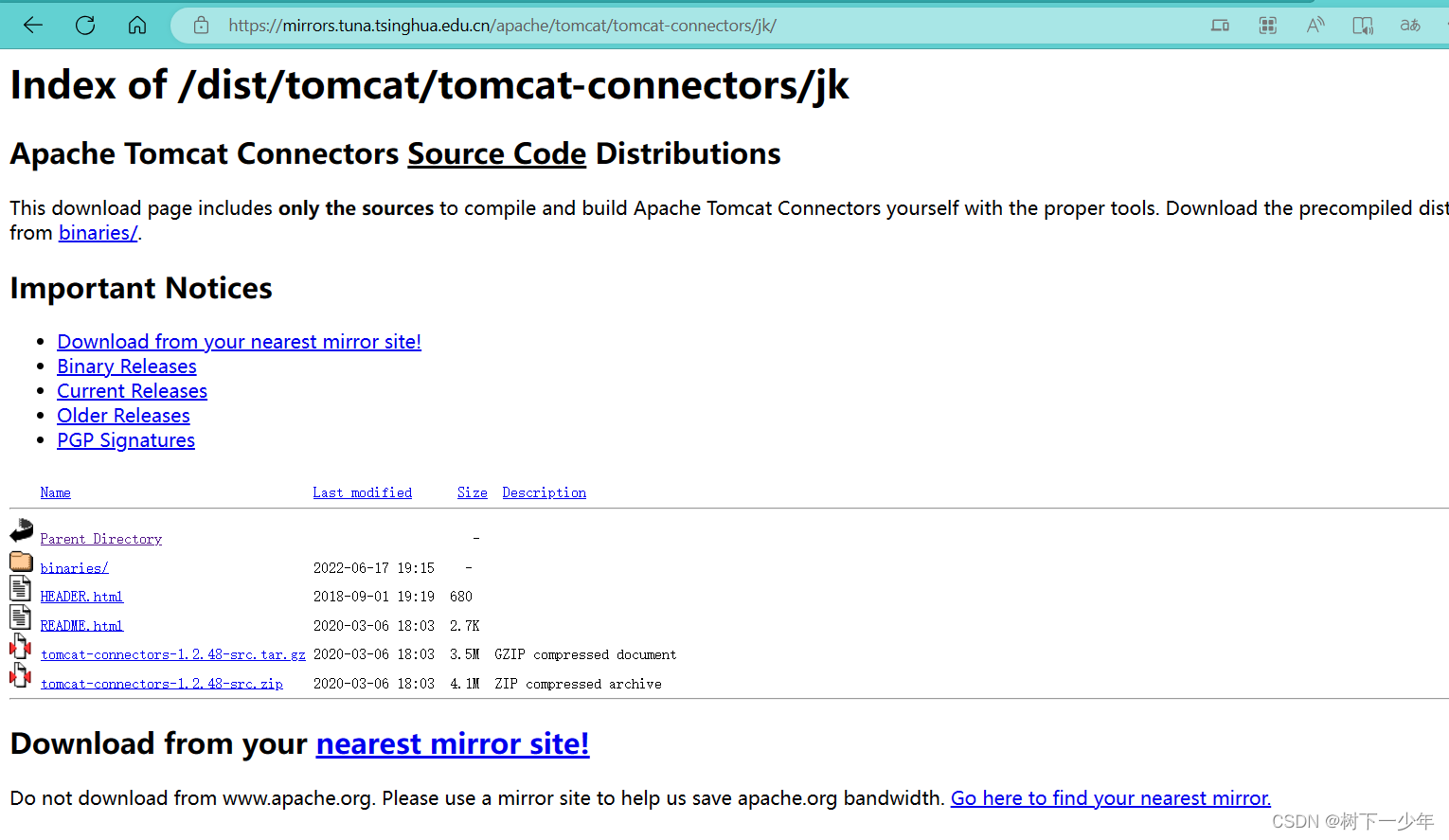
[root@localhost jk]# tar -zvxf tomcat-connectors-1.2.48-src.tar.gz -C /usr/local/src/
[root@localhost native]# pwd
/usr/local/src/tomcat-connectors-1.2.48-src/native
[root@localhost native]# whereis apxs #查看apxs位置
apxs: /usr/bin/apxs /usr/share/man/man1/apxs.1.gz
[root@localhost native]# ./configure --with-apxs=/usr/bin/apxs
#使用上面查到的apxs进行编译安装
[root@localhost native]# make
[root@localhost native]# make install二.配置jk模块以实现整合
1.以我的安装路径为例首先将/usr/local/src/tomcat-connectors-1.2.48-src/native/apache-2.0/mod_jk.so这个文件拷贝到/etc/httpd/modules
[root@localhost apache-2.0]# pwd
/usr/local/src/tomcat-connectors-1.2.48-src/native/apache-2.0
[root@localhost apache-2.0]# cp mod_jk.so /etc/httpd/modules/2.配置mod_jk.conf文件,我同意放在/etc/httpd/conf下的
一定注意文件的路径,不确定就写绝对路径
[root@localhost conf]# pwd
/etc/httpd/conf
[root@localhost conf]# vim mod_jk.conf
LoadModule jk_module modules/mod_jk.so #导入刚才移过来的mod_jk.so模板
JkWorkersFile /etc/httpd/conf/workers.properties #稍后需要创建的tomcat的工作文件
JkLogFile /var/log/httpd/mod_jk.log #自定义,重启后会自动创建
JkLogLevel info #日志等级
JkLogStampFormat "[%a %b %d %H:%M:%S %Y]"
JkOptions +ForwardKeySize +ForwardURICompatUnparsed -ForwardDirectories
JkRequestLogFormat "%w %V %T" #一些日志格式
JkMount /*.jsp worker1 #重要参数,将以".jsp"结尾的文件交给worker1处理,worker1也是稍后workers.properties工作文件中的主要参与者#这里可以定义多个任务分配,按实际需求定义
workers.properties
JkMount /* worker1
JkMount /*.jsp worker1
JkMount /servlet/* worker1
JkMount /*.do worker1
JkMount /*.action worker1
JkMount /*.class worker1
JkMount /*.jar worker1
JkMount /jkstatus status # 状态页3.配置workers.properties,上面定义的在那个位置就创建在哪个位置
[root@localhost conf]# vim workers.properties
workers.tomcat_home=/usr/local/tomcat/ #定义tomcat工作目录
workers.java_home=/usr/java//usr/java/jdk1.8.0_371 #定义jdk工作目录
worker.list=worker1 #处理请求的“工作者”
worker.worker1.type=ajp13 #固定模板
worker.worker1.host=192.168.2.190 #该“工作者”主机地址
worker.worker1.port=8009 #该“工作者”服务端口#如果在mod_jk.so中定义了状态页,需要
#worker.list = status
#worker.status.type=status4.更改/etc/httpd/conf/httpd.conf
添加上这行

三.更改tomcat的server.xml配置
1.按照自己的tomcat安装位置查找该文件
[root@localhost conf]# pwd
/usr/local/tomcat/apache-tomcat-8.5.70/conf
[root@localhost conf]# vim server.xml
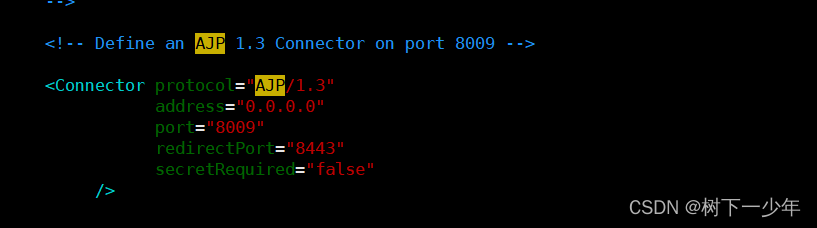
2.在文件中找到AJP的这个位置,将Connector原有注释取消掉并进行配置
注意:
如果在使用jk整合apache和tomcat后续测试时出现“503 Service Unavailable”,需要将address处修改为虚拟机IP地址或“0.0.0.0”,新增secretRequired="false"这行,并重启测试
四.创建测试界面(谨慎使用中文)
1.apache测试文件,这里以默认的html目录为例
[root@localhost html]# pwd
/var/www/html
[root@localhost html]# vim index.html
apache2.tomcat测试文件,放在你tomcat安装目录中的webapps/ROOT目录下
[root@localhost ROOT]# pwd
/usr/local/tomcat/apache-tomcat-8.5.70/webapps/ROOT
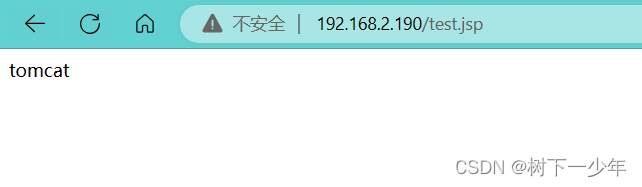
[root@localhost ROOT]# vim test.jsp
tomcat五.测试