热转印 东莞网站建设建设银行论坛网站首页
菲亚特克莱斯勒汽车Fiat Chrysler Automobiles(FCA)是一家全球性汽车制造商,主营产品包括轿车、SUV、皮卡车、商用车和豪华车等多种车型。其旗下品牌包括菲亚特、克莱斯勒、道奇、Jeep、Ram、阿尔法·罗密欧和玛莎拉蒂等。
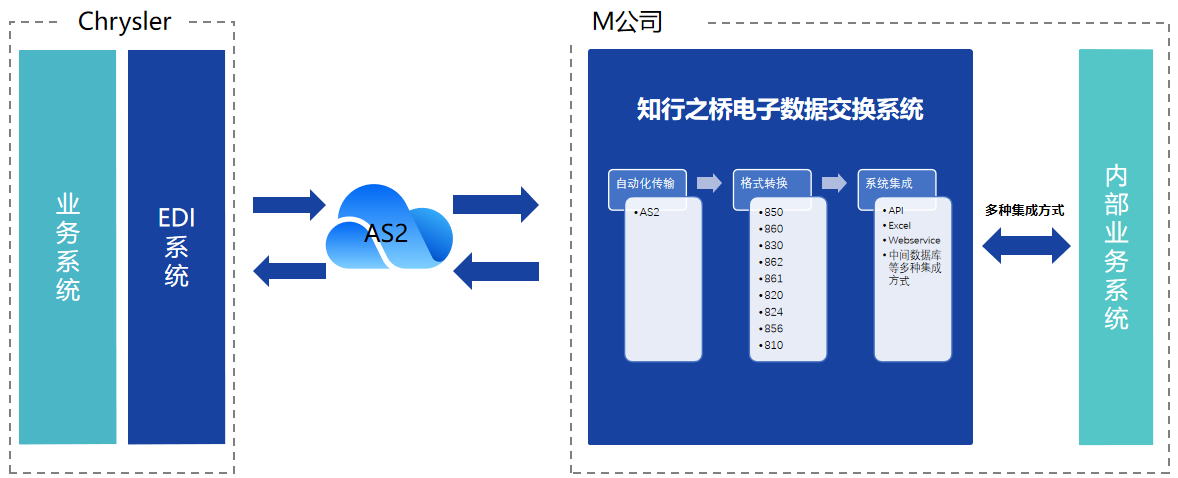
Chrysler通过EDI来优化订单处理、交付通知、货物收据以及发票处理等业务流程,从而加快订单处理速度,更好的协调交货时间,追踪其供应链中货物的运输情况,加快付款速度,避免出现错误和延误。
EDI 需求概览
EDI 传输协议
Chrysler支持SFTP以及AS2。与SFTP相比,AS2有一个独特的功能:它允许用户请求一个文件处理通知(MDN),一旦文件被收件人收到并解密,就会提醒发件人。这种收据(也称为NRR,即不可否认的收据)被创建、签署,并在解密后返回给发件人,给他们提供法律证据,证明文件在运输过程中没有被改变。
因此M公司选择使用AS2最为其EDI传输协议,AS2(Applicability Statement 2)是一种用于在网络上安全、可靠地传输数据的协议。它建立在HTTP(Hypertext Transfer Protocol)和SMTP(Simple Mail Transfer Protocol)的基础上,采用了加密和数字签名等安全机制,确保数据的机密性和完整性。
EDI 报文标准
Chrysler选择的EDI报文标准为X12,涉及到的业务单据以及传输方向如下所示:
| 业务类型 | 业务含义 | 传输方向 |
|---|---|---|
| 850 | 采购订单 | Chrysler发送给 M 公司 |
| 860 | 采购订单变更 | Chrysler发送给 M 公司 |
| 830 | 物料需求预测 | Chrysler发送给 M 公司 |
| 862 | 交付计划 | Chrysler发送给 M 公司 |
| 861 | 接收通知或验收证书文件格式 | Chrysler发送给 M 公司 |
| 820 | 汇款通知 | Chrysler发送给 M 公司 |
| 824 | 应用程序通知 | Chrysler发送给 M 公司 |
| 856 | 发货通知 | M 公司发送给Chrysler |
| 810 | 采购订单 | M 公司发送给Chrysler |
实施方案
考虑到内部业务系统尚未开发完成,M公司与知行沟通后决定采用Excel方案作为临时替代方案,后期业务系统开发完毕之后,再切换集成方案。
Excel方案是EDI报文和Excel之间的数据转换。它的基本思路是:在接收到交易伙伴发来的EDI报文,并在EDI平台内部完成格式的转换之后,将数据直接呈现在Excel中。用户可以直观地看到接收到的数据;手动在Excel上录入数据之后,将Excel上传至EDI平台,EDI平台在内部做字段映射,将表格中的数据映射到固定的EDI字段上,最终生成EDI报文发送给交易伙伴。
基于知行之桥EDI系统对接 Chrysler EDI
实现与Chrysler的EDI对接需要在知行之桥EDI系统中搭建如下所示的工作流:
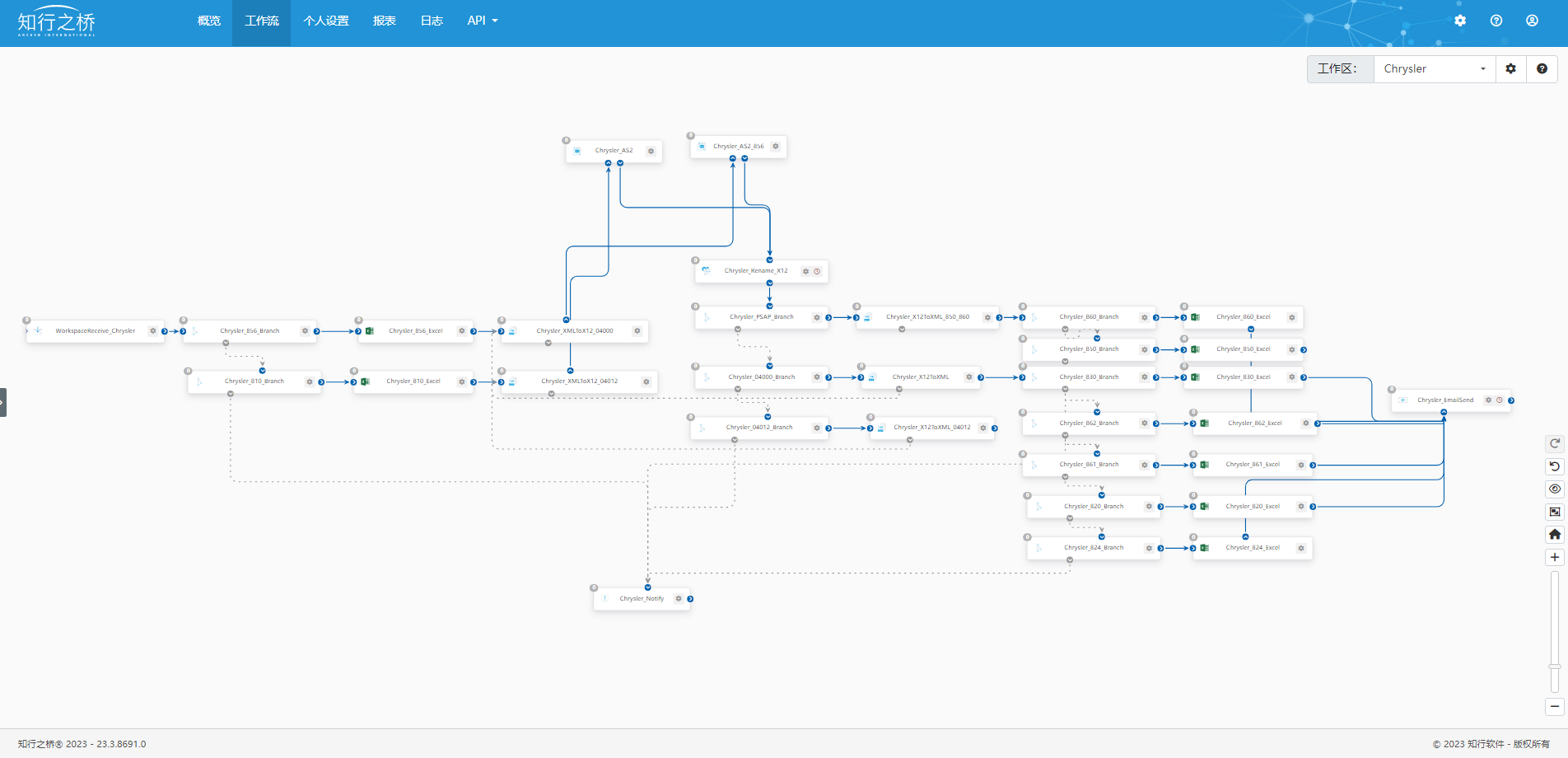
建立 AS2 连接
本次对接Chrysler的EDI项目中使用了两个AS2端口,被分别命名为Chrysler_AS2以及Chrysler_AS2_856。这是由于Chrysler方使用单独的AS2 ID传输EDI 856 发货通知,其他报文则使用另一个AS2 ID进行传输。
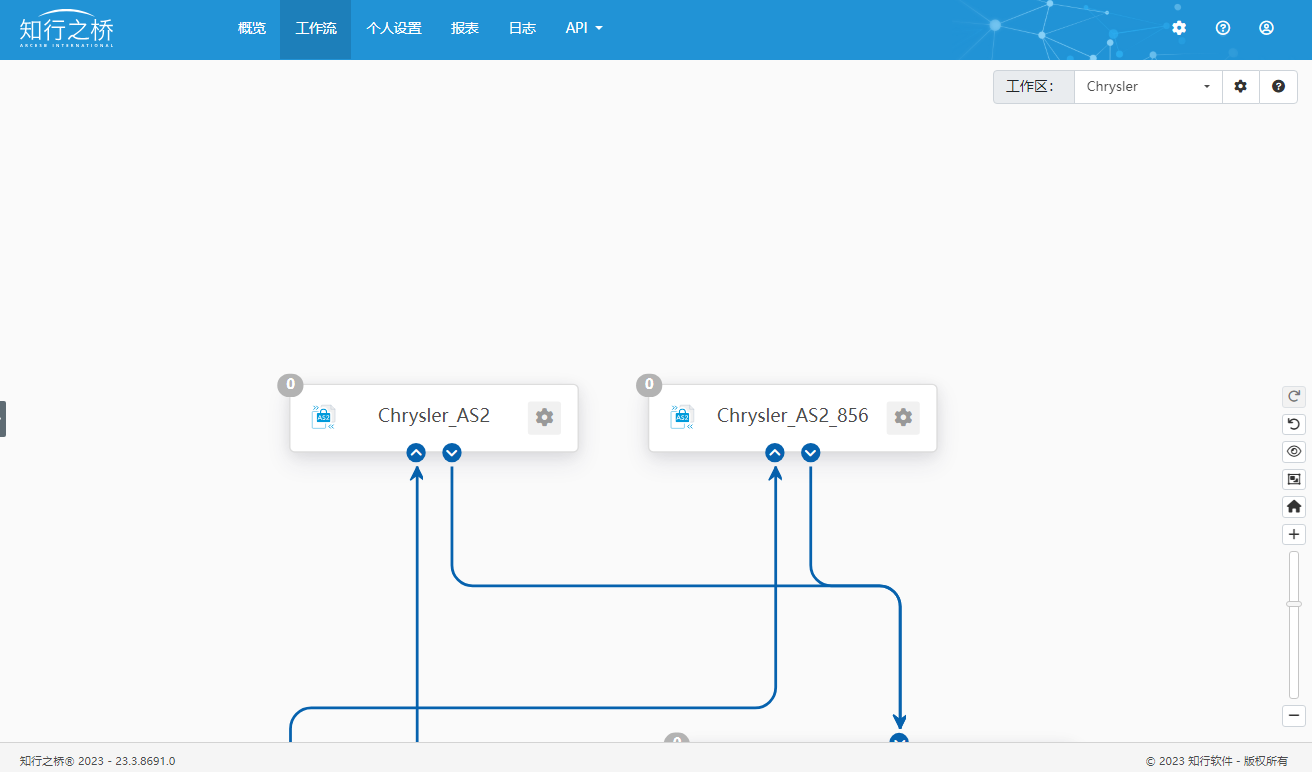
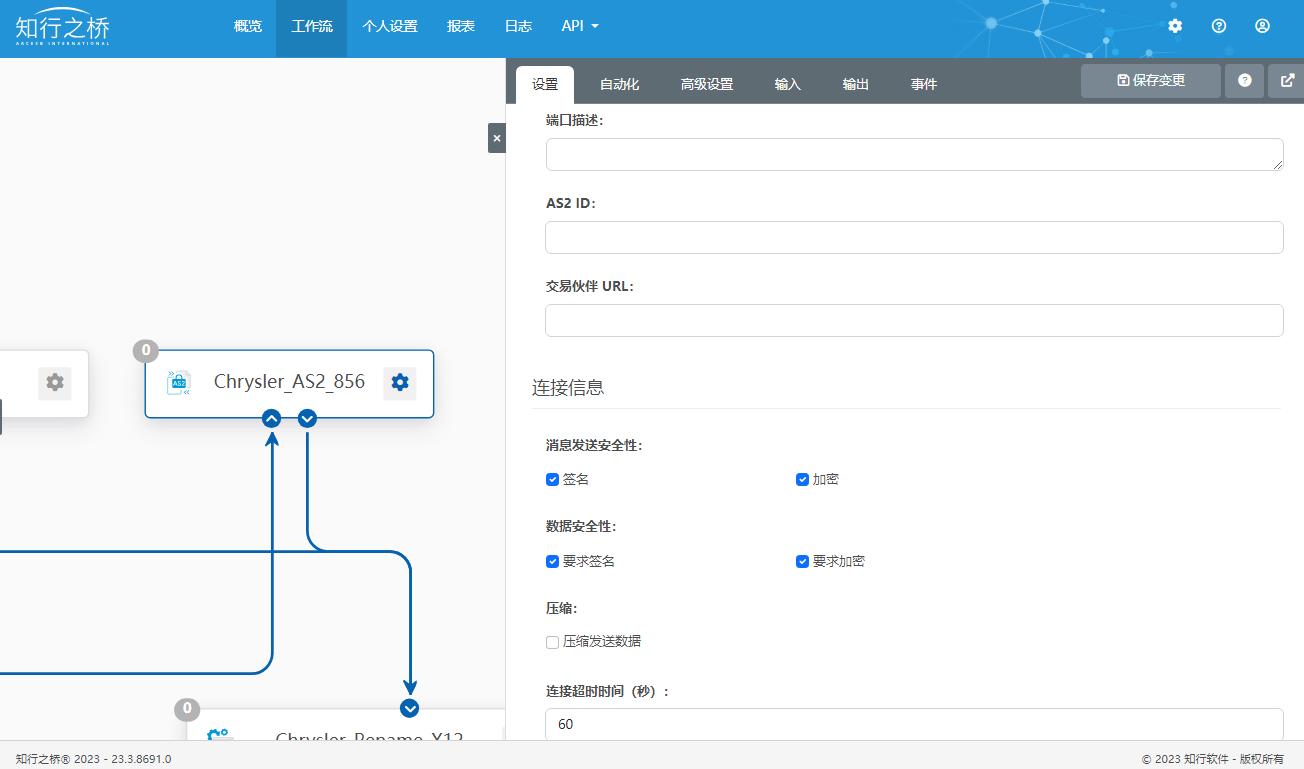
Chrysler将会提供两套 AS2连接信息,在配置的过程中,M公司需要注意辨别。需要分别在这两个AS2端口中配置Chrysler提供的AS2 ID、交易伙伴URL以及交易伙伴证书等信息。
与Chrysler的EDI测试流程
本次对接Chrysler的EDI项目是帮助M公司使用知行之桥EDI系统切换国外某EDI系统,项目中需要传输的单据此前都已做过测试,对于这种切换项目,Chrysler方提出只需要进行连接测试即可,无需再做额外的业务测试。
整体测试流程如下:
1.进入Stellantis 的EMTS网站,选择需要的EDI连接方式。由于是切换项目,因此需要选择 Modify Existing Account,填写AS2信息以及供应商信息。
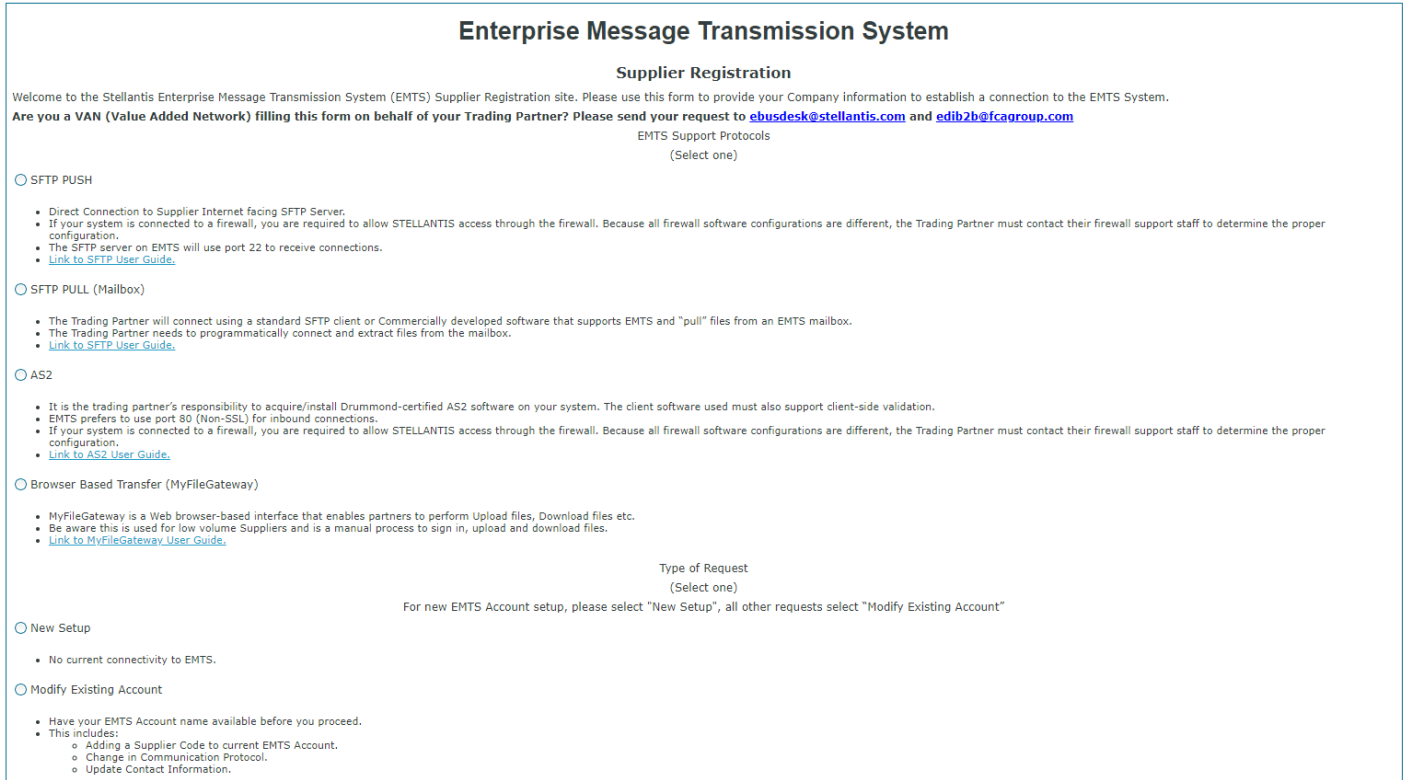
2.向Chrysler发送邮件,告知对方EMTS网站上的内容已填写完成。并提供M公司的AS2连接信息(包括证书等信息)。
3.与Chrysler进行Loop test,需要确认M公司的供应商类型(如:MOPAR、PAY AS BILL以及PRODUCTION等),这里支持多选。
4.Chrysler提供的AS2连接信息中没有提到AS2 ID,这里需要结合供应商类型来匹配AS2 ID。AS2 连接测试分为 测试和生产两部分。
5.接下来Chrysler将会给M公司分配 Signup 账号。后期供应商可以登录EMTS网站查看业务单据的处理情况。
6.由于切换项目Chrysler并不参与EDI业务测试,因此需要M公司的业务人员和知行EDI实施顾问一起进行业务测试,将系统生成各业务单据与此前成功上线的业务单据进行比对。
项目回顾
1.解决发送方ID不同时的文件分流
通常情况下,接收同一个交易伙伴发来的EDI报文只会出现一个发送方ID。但由于本次对接Chrysler的EDI项目需要对接Chrysler多条业务线,因此会出现多个发送方ID,需要进行文件分流。
在知行之桥EDI系统中我们可以在Script端口的设置选项卡下编写RSB脚本来实现对文件名的修改。
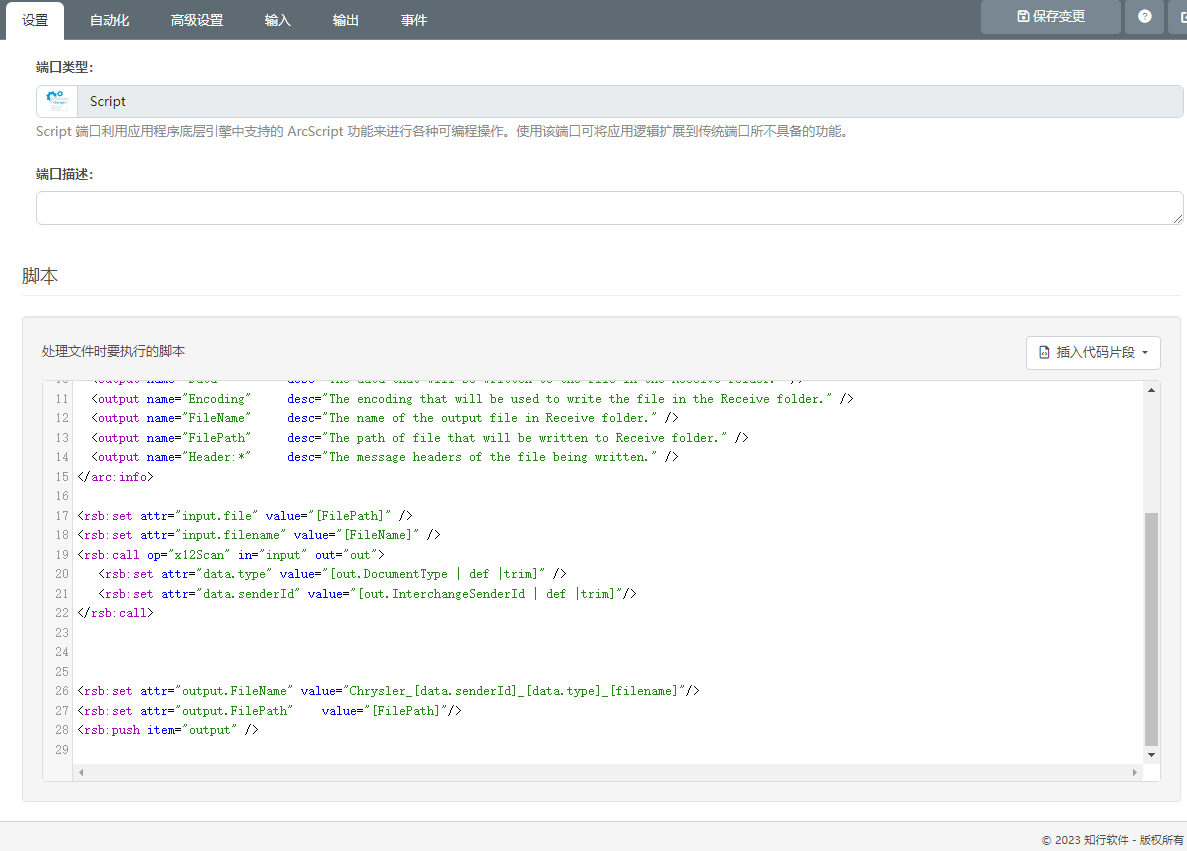
代码如下:
<rsb:set attr="input.file" value="[FilePath]" />
<rsb:set attr="input.filename" value="[FileName]" />
<rsb:call op="x12Scan" in="input" out="out"><rsb:set attr="data.type" value="[out.DocumentType | def |trim]" /><rsb:set attr="data.senderId" value="[out.InterchangeSenderId | def |trim]"/>
</rsb:call><rsb:set attr="output.FileName" value="Chrysler_[data.senderId]_[data.type]_[filename]"/>
<rsb:set attr="output.FilePath" value="[FilePath]"/>
<rsb:push item="output" />上述代码能够根据发送方ID对文件进行分流,本次EDI项目中会出现三个不同的发送方ID,因此主要将文件分为三组:
第一组包括:EDI 850、EDI 860;
第二组包括:EDI 830、EDI 862、EDI 861、EDI 820以及EDI824;
第三组包括:针对接收到的 EDI 810回复的EDI 997,功能性确认。
2.跨工作区的文件传输
在上述工作流中,M公司向Chrysler发送EDI 856 以及EDI 810时,M公司的业务人员需要填写相应的Excel模板,并将其发送至指定邮箱中。这里理应创建一个EmailReceive端口,用于配置收件箱信息。但工作流中使用了WorkspaceReceive端口,如下图所示:
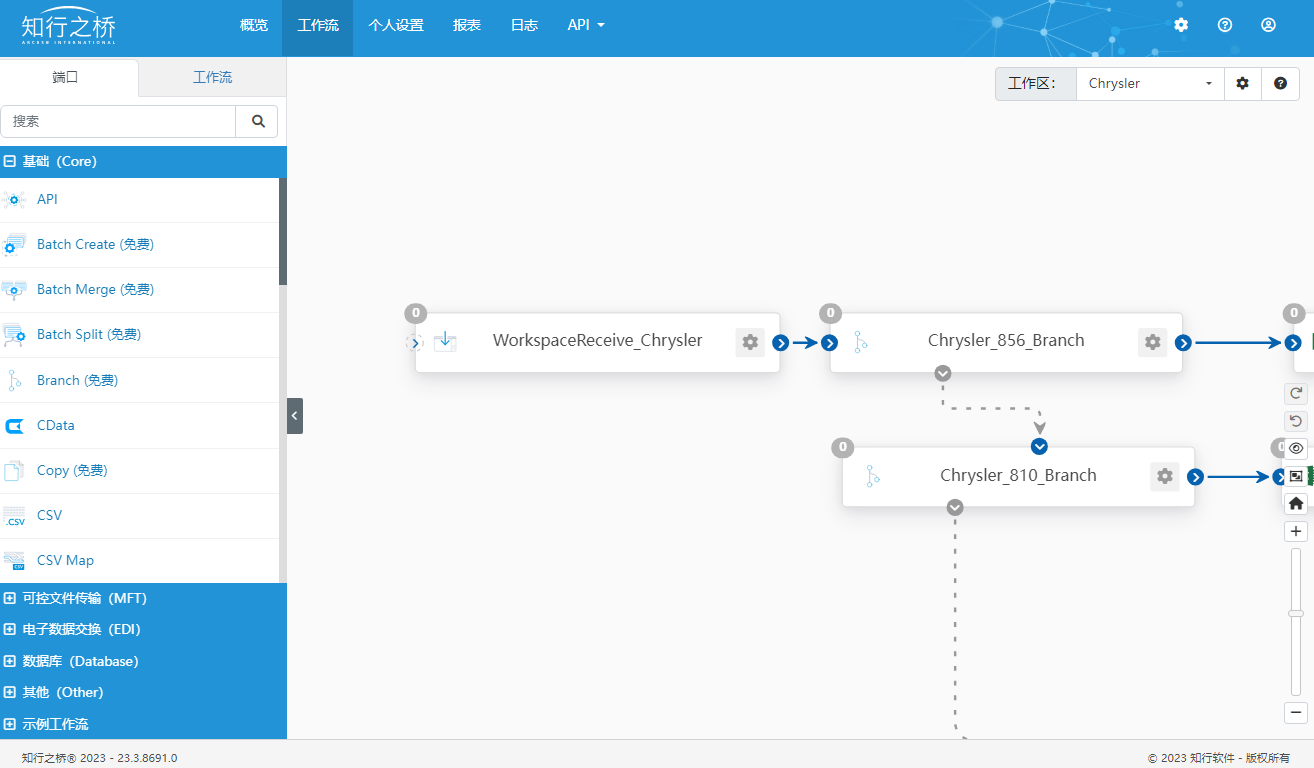
M公司使用知行之桥EDI系统对接多个交易伙伴,可以在工作流界面右上角创建不同的工作区来区分不同的交易伙伴。
但所有交易伙伴如果都使用一个收件箱,则可以通过WorkspaceReceive端口以及WorkspaceSend这两个免费端口实现跨工作区的文件传输,尽可能减少付费端口的使用,节约成本。
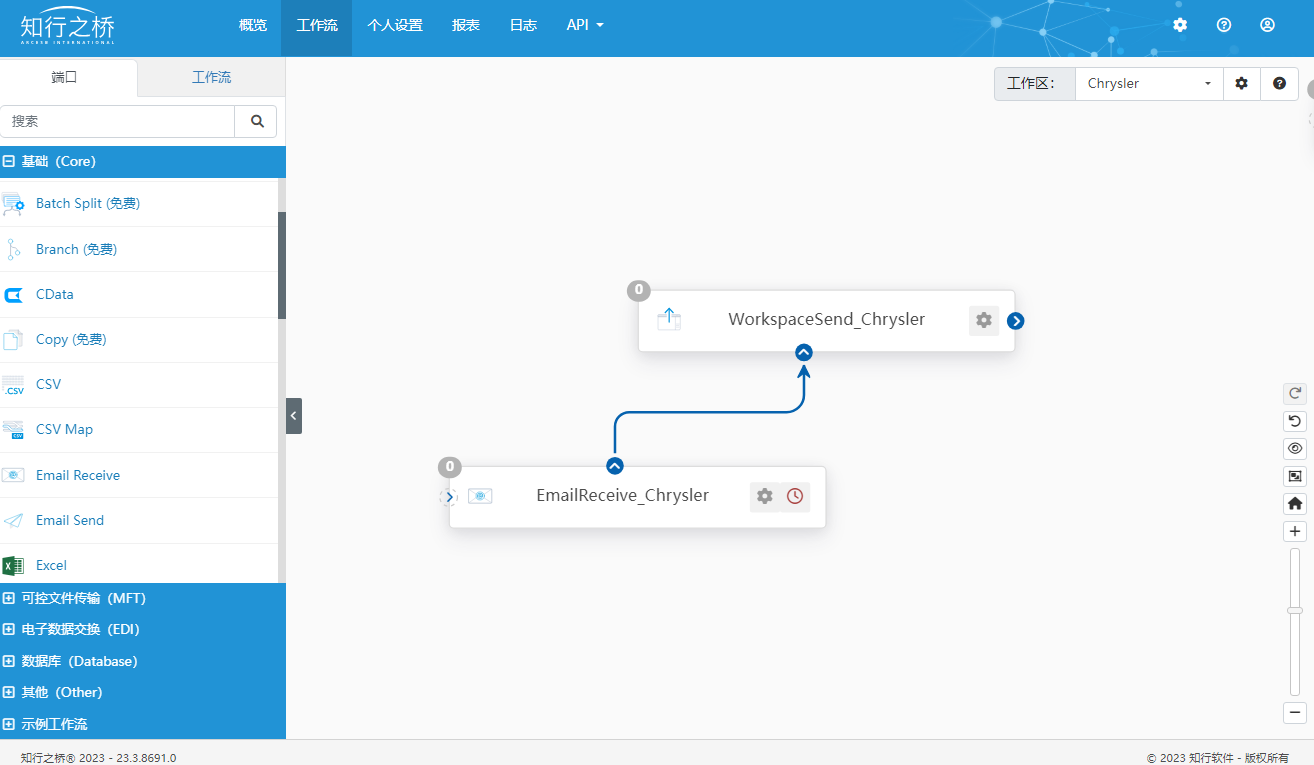
可以在工作流中搭建上述工作流,给每个交易伙伴都创建一个WorkspaceSend端口,如下图所示:
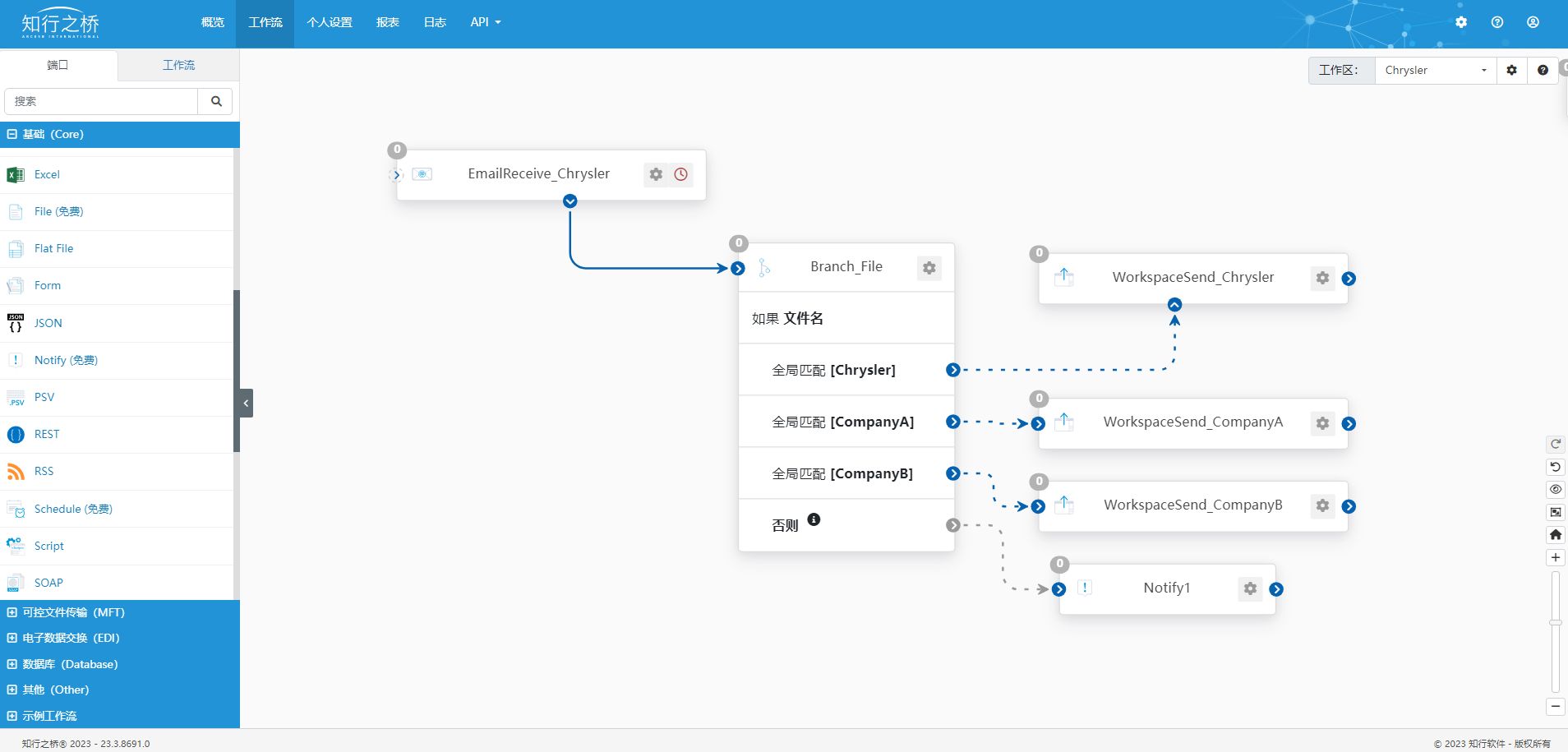
搭建上述工作流即可以让多个Chrysler以及CompanyA、CompanyB共同使用一个EmailReceive端口了。
关于如何配置Workspace Receive 以及 Workspace Send 端口,请参考:Workspace Receive 以及 Workspace Send 端口介绍
扩展阅读:EDI是什么?