鞍山制作公司网站的公司网站建设佛山
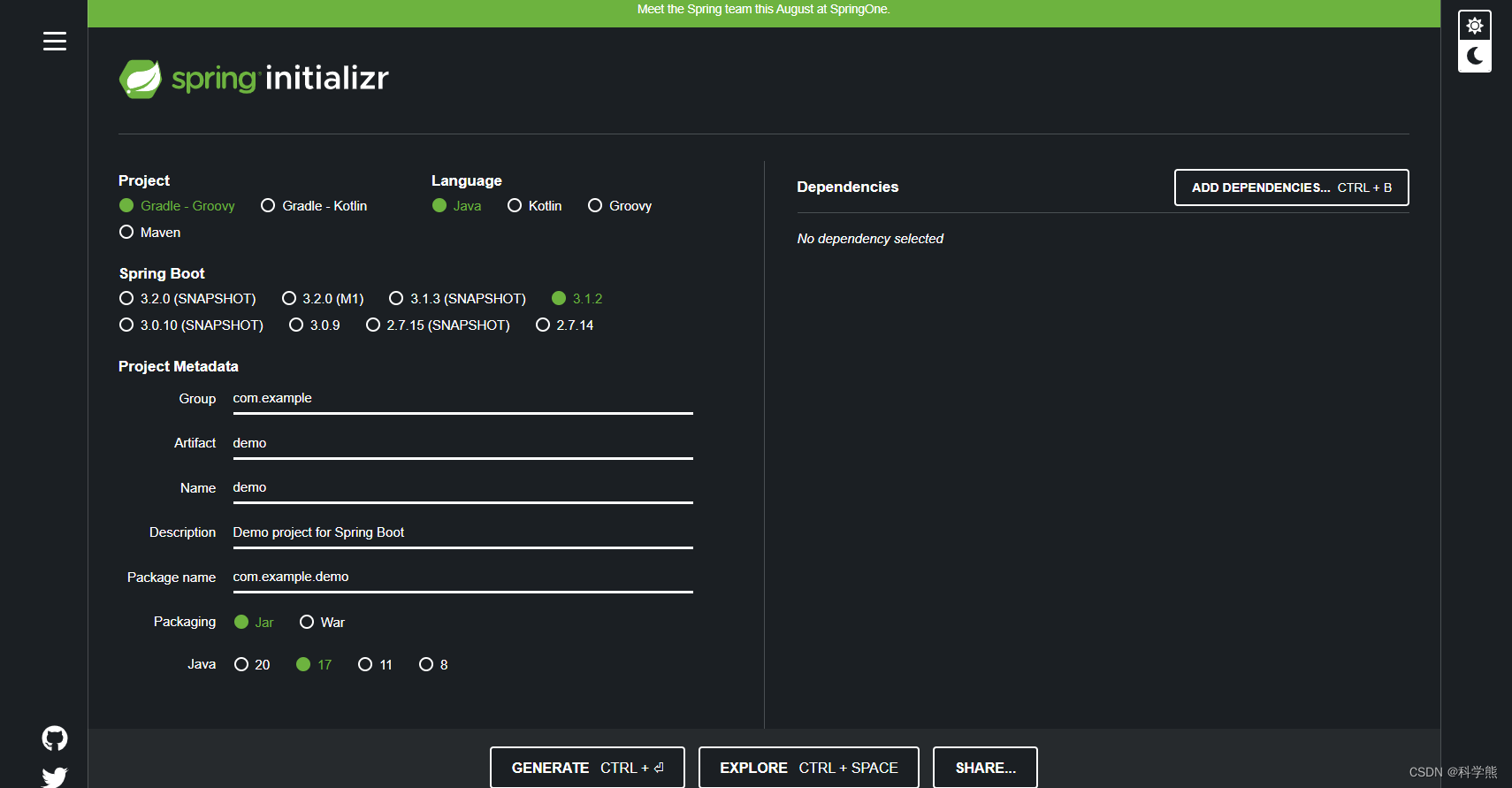
Springboot配置生成初始化项目代码可以通过mvn的mvn archetype:generate 和阿里云原生应用脚手架(地址)、spring官方提供的start初始化生成页面(地址)。
1、mvn archetype:generate
通过mvn选择对应的脚手架可以快速生成初始化代码:
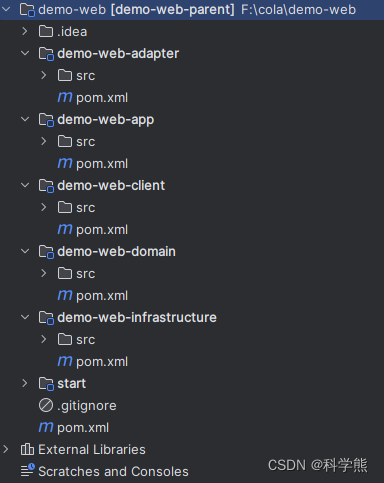
下面是COLA架构快速生成示例
COLA 是 Clean Object-Oriented and Layered Architecture的缩写,代表“整洁面向对象分层架构”。COLA项目地址
mvn archetype:generate \-DgroupId=com.alibaba.cola.demo.web \-DartifactId=demo-web \-Dversion=1.0.0-SNAPSHOT \-Dpackage=com.alibaba.demo \-DarchetypeArtifactId=cola-framework-archetype-web \-DarchetypeGroupId=com.alibaba.cola \-DarchetypeVersion=4.3.2
生成的代码:
2、阿里云原生应用脚手架
主要是基于阿里云原生应用的整套解决方案的支持较多,和spring官网提供的初始化配置页面参不多。
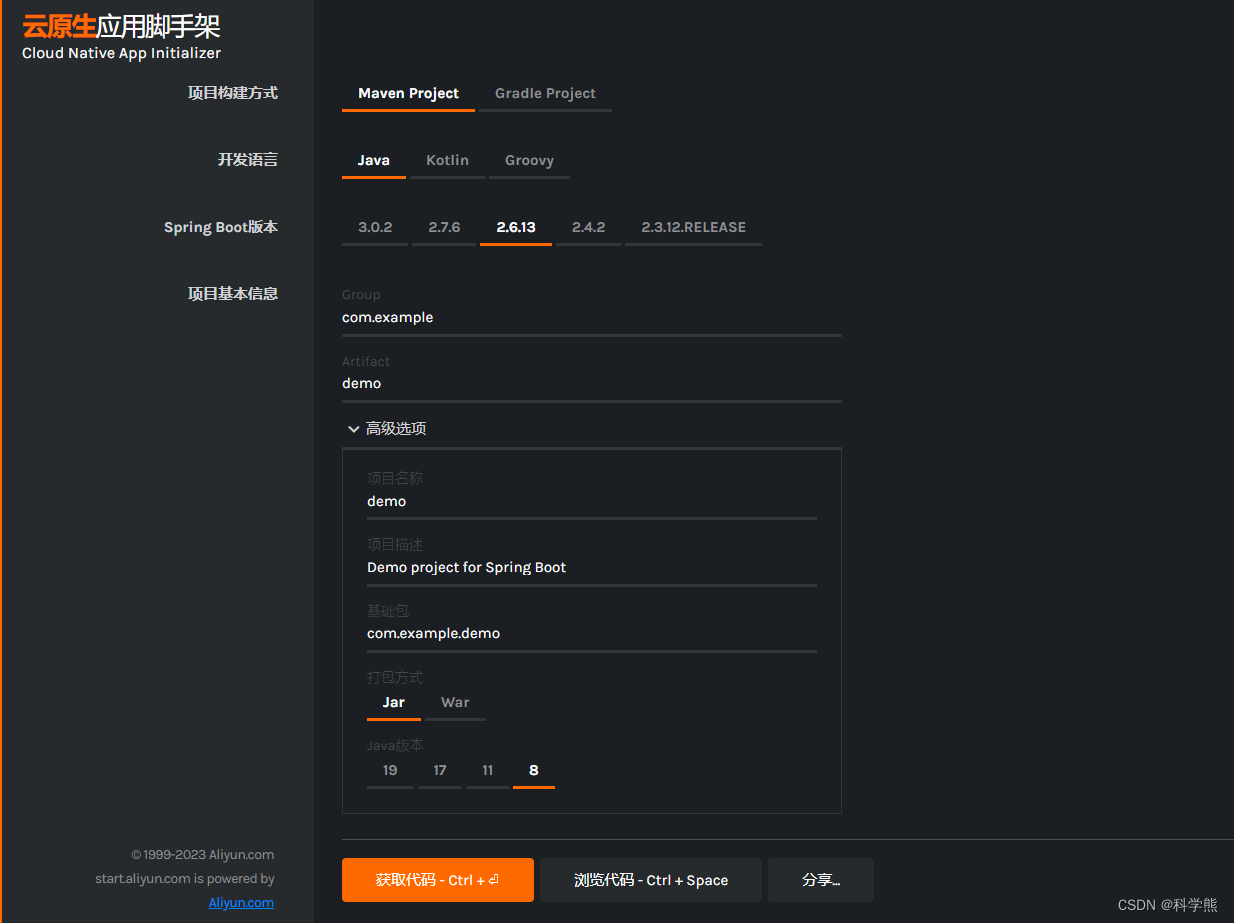
阿里云提供的云原生方案:
3、spring官方提供的start初始化生成页面