网站管理权限最好的网络营销软件
目录
引言
1 Docker仓库基础概念
1.1 仓库(Registry)定义
1.2 镜像(Image)与仓库的关系
1.3 仓库的类型
2 Docker仓库工作原理
2.1 仓库架构概览
2.2 镜像上传与下载流程
2.2.1 镜像上传流程
2.2.2 镜像下载流程
3 Docker仓库的高级特性
3.2 镜像签名与验证
3.2 仓库镜像扫描
3.3 仓库访问控制
4 总结
引言
在Docker的世界里,仓库(Registry)是一个至关重要的概念,它作为Docker镜像的存储和分发中心,极大地简化了应用的部署和分发流程。理解Docker仓库的工作原理和核心概念,对于掌握Docker技术栈、优化镜像管理以及实现高效的CI/CD流程至关重要。
1 Docker仓库基础概念
1.1 仓库(Registry)定义
Docker仓库(Registry)是一个存储和分发Docker镜像的服务,它允许用户上传(push)镜像到仓库,也可以从仓库下载(pull)镜像到本地。仓库可以是公开的,也可以是私有的,任何人都可以访问其中的镜像;私有仓库则通常用于企业内部,限制访问权限。
1.2 镜像(Image)与仓库的关系
Docker镜像是一个轻量级、独立的、可执行的软件包,它包含了运行某个软件所需的所有内容,包括代码、运行时、库、环境变量和配置文件。镜像被存储在仓库中,通过仓库进行分发,每个镜像都有一个唯一的标识符,通常包括仓库名、标签(tag)和镜像ID。
1.3 仓库的类型
- 公共仓库:提供了海量的官方和第三方镜像,用户可以直接拉取镜像,也可以将自己创建的镜像推送上去分享给其他用户
- 私有仓库:企业或个人为了安全和管理的需要,常常会搭建自己的私有仓库,私有仓库可以部署在企业内部网络中,只有授权的用户才能访问和操作镜像,确保了镜像的安全性和私密性。常见的私有仓库搭建方案有Harbor、Nexus等。
2 Docker仓库工作原理
2.1 仓库架构概览
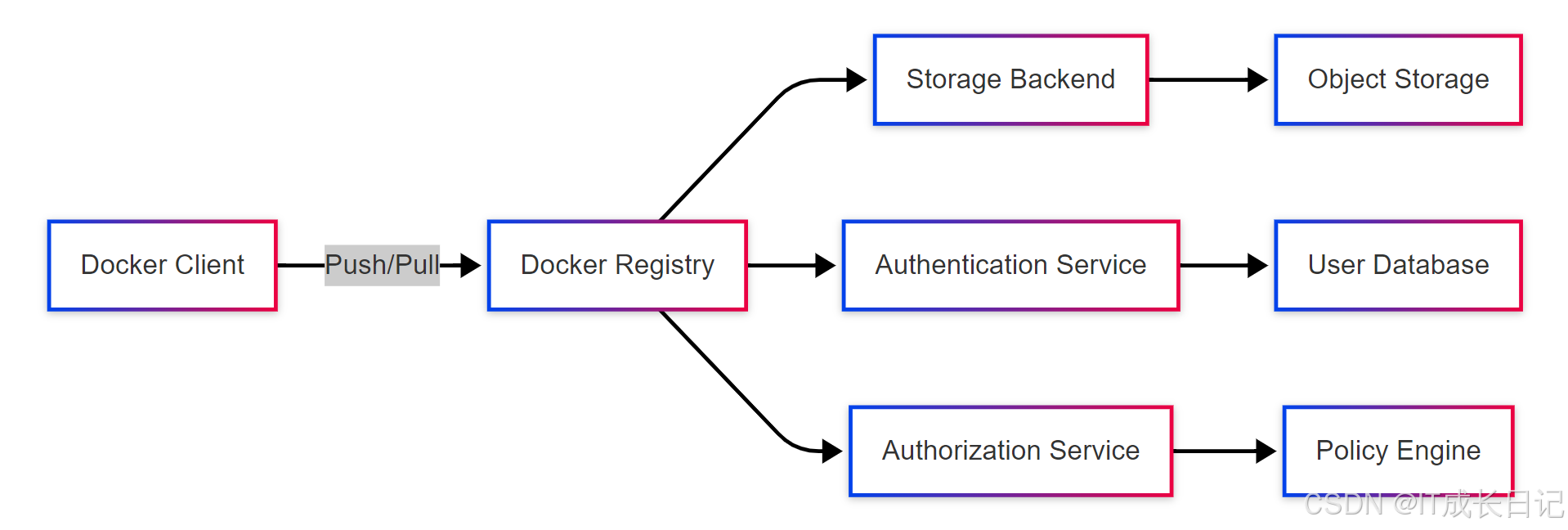
- Docker Client:用户通过Docker命令行工具或API与仓库交互
- Docker Registry:仓库的核心服务,负责处理镜像的上传、下载、查询等操作
- Storage Backend:仓库的存储后端,可以是本地文件系统、对象存储用于实际存储镜像文件
- Authentication Service:认证服务,验证用户的身份,确保只有授权用户才能访问仓库
- Authorization Service:授权服务,根据用户的权限和策略,决定用户可以执行哪些操作
- Object Storage:对象存储,是Storage Backend的一种实现方式,提供高可用、可扩展的存储服务
- User Database:用户数据库,存储用户信息,包括用户名、密码、权限等
- Policy Engine:策略引擎,根据预定义的规则和策略,控制用户对仓库的访问和操作
2.2 镜像上传与下载流程
2.2.1 镜像上传流程
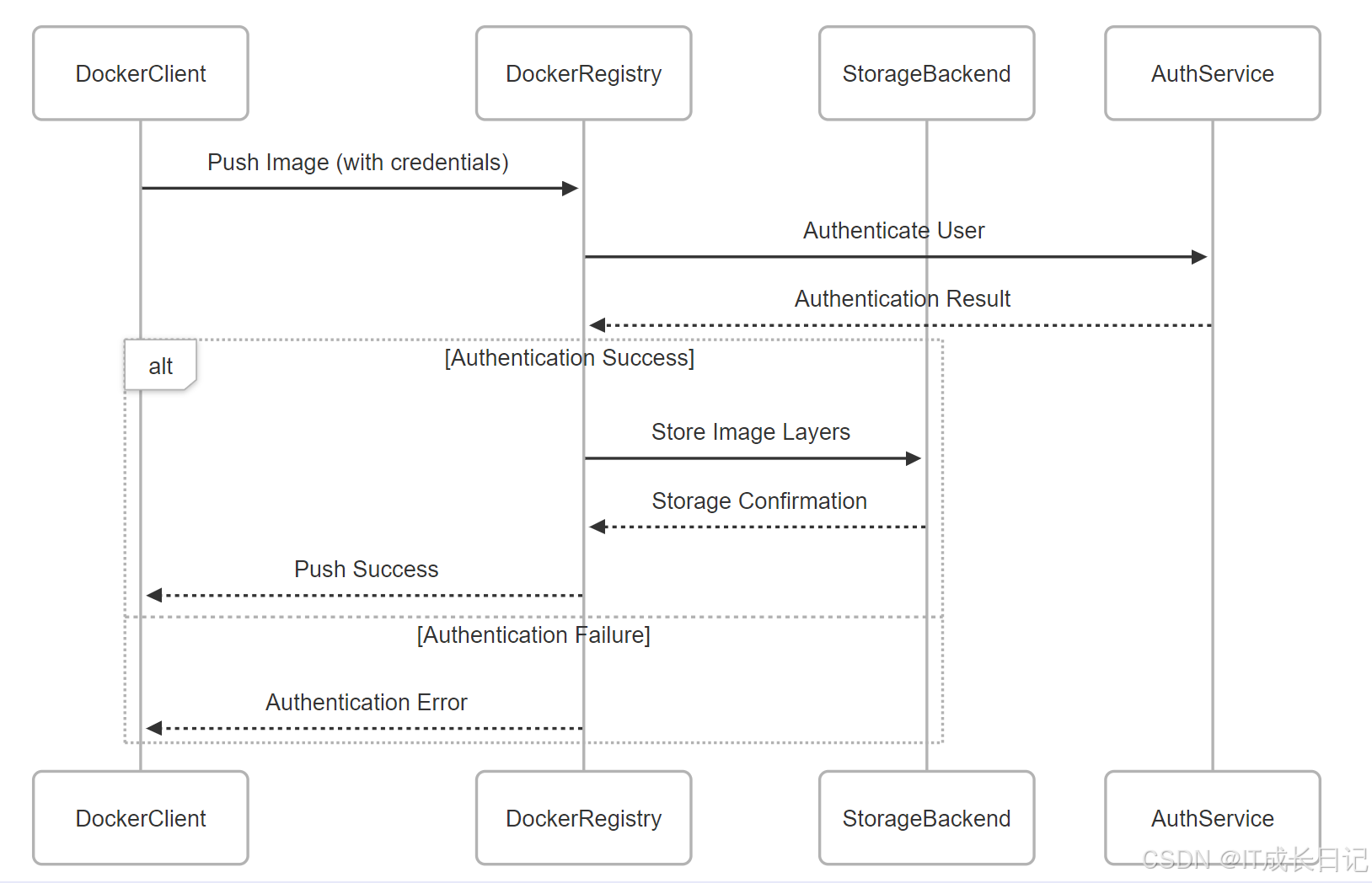
- Docker客户端向仓库发起镜像上传请求,并附带认证信息
- 仓库接收到请求后,向认证服务验证用户身份
- 如果认证成功,仓库将镜像层存储到存储后端
- 存储后端确认存储成功后,仓库向客户端返回上传成功消息
- 如果认证失败,仓库向客户端返回认证错误消息
2.2.2 镜像下载流程
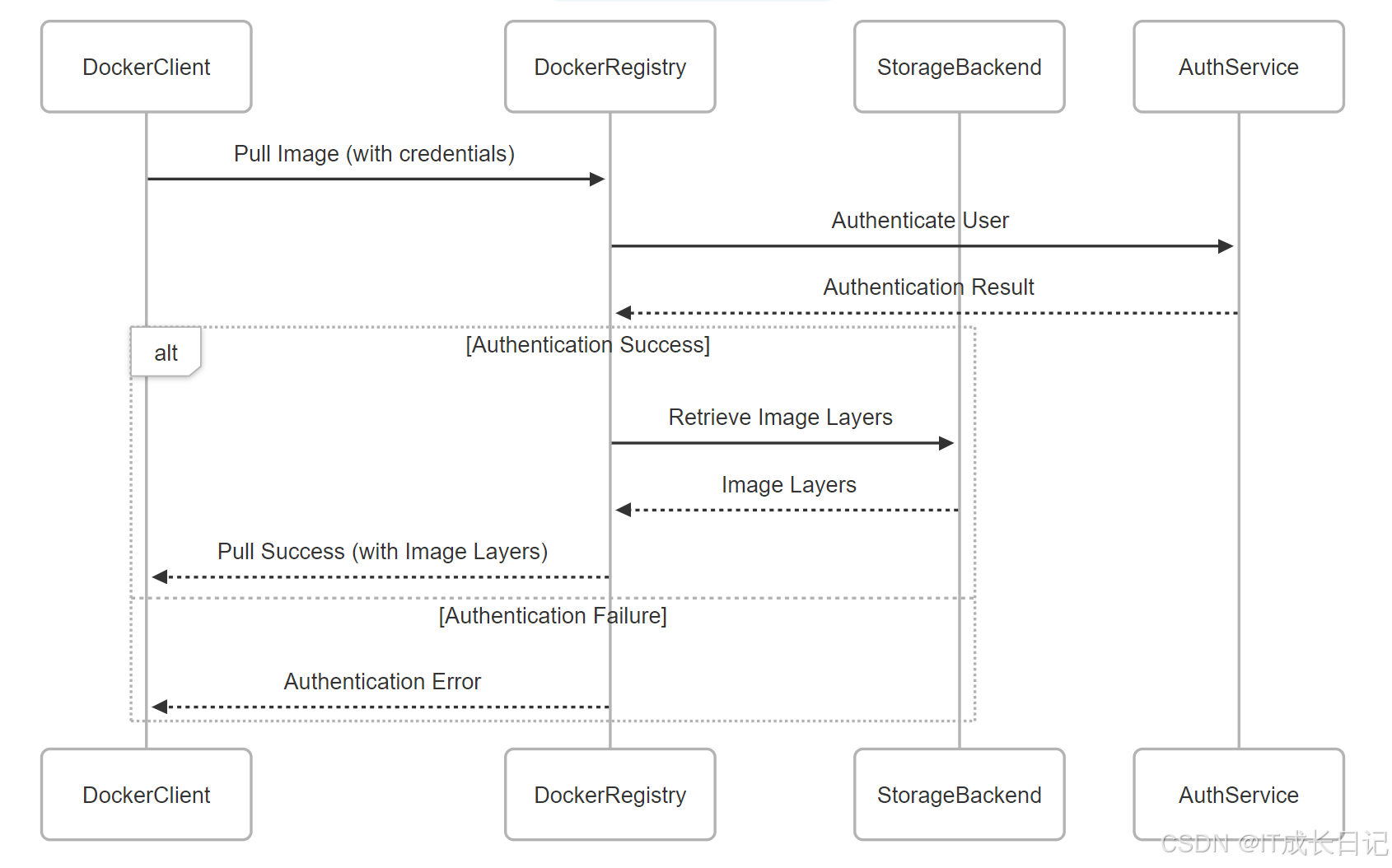
- Docker客户端向仓库发起镜像下载请求,并附带认证信息
- 仓库接收到请求后,向认证服务验证用户身份
- 如果认证成功,仓库从存储后端检索镜像层
- 仓库将检索到的镜像层返回给客户端,客户端完成镜像的下载和构建
- 如果认证失败,仓库向客户端返回认证错误消息
3 Docker仓库的高级特性
3.2 镜像签名与验证
为了确保镜像的完整性和来源可信,Docker仓库支持镜像签名功能,镜像签名允许用户对镜像进行数字签名,并在下载时验证签名的有效性。这有助于防止恶意镜像的传播和滥用。
3.2 仓库镜像扫描
许多仓库服务提供了镜像扫描功能,可以自动检测镜像中包含的漏洞和安全问题,通过定期扫描镜像,用户可以及时发现并修复潜在的安全风险,提高应用的安全性。
3.3 仓库访问控制
仓库访问控制是确保仓库安全性的重要手段,通过配置访问控制策略,用户可以限制对仓库的访问权限,确保只有授权用户才能执行特定的操作。
4 总结
Docker仓库作为Docker镜像的存储和分发中心,在Docker技术栈中扮演着至关重要的角色。通过深入理解Docker仓库的核心概念、工作原理以及高级特性,用户可以更好地管理镜像、优化部署流程并提高应用的安全性。