做网站好不好大型网站制作平台
随着信息时代的不断发展,数据采集成为了各行业获取关键信息的重要手段。在这个领域,AI技术的应用为数据采集注入了新的活力,提高了效率和准确性。本文将向您推荐三款优秀的AI数据采集软件,其中包括了147免费采集软件,让您在信息爆炸的时代中更轻松、更智能地获取所需数据。
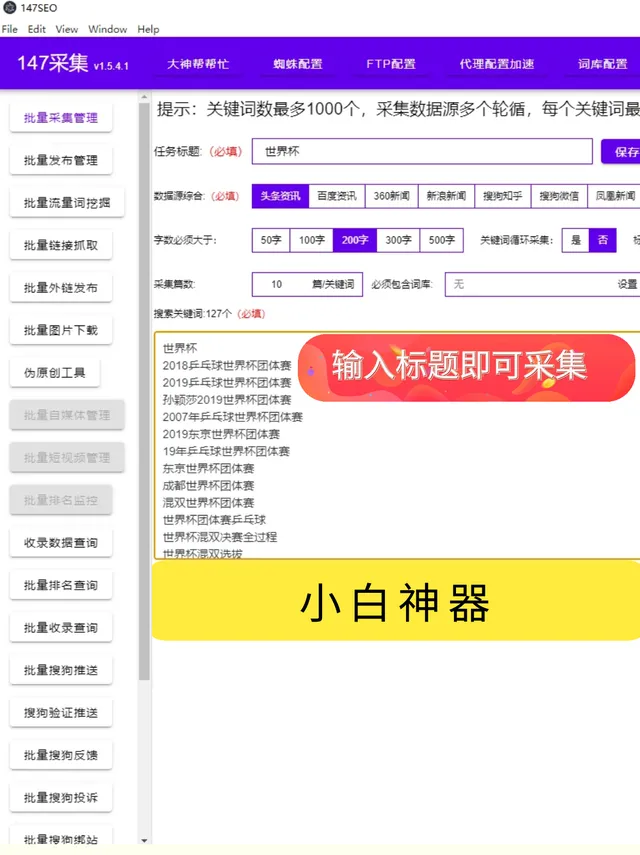
第一款:147免费采集软件
147免费采集软件是一款功能强大的AI数据采集工具,其最大的特点是支持输入关键词即可全网抓取文章。这使得用户能够通过简单的关键词设定,轻松获取全网相关信息,提高了数据获取的效率。此外,该软件还支持指定任意网站抓取,为用户提供了更多灵活的选择。监控实时抓取网站信息是其另一个亮点,用户可以随时随地查看抓取进度,确保数据采集的实时性。设置好后,软件将全自动进行抓取,大大减轻了用户的操作负担,使得数据采集变得更为便捷和高效。
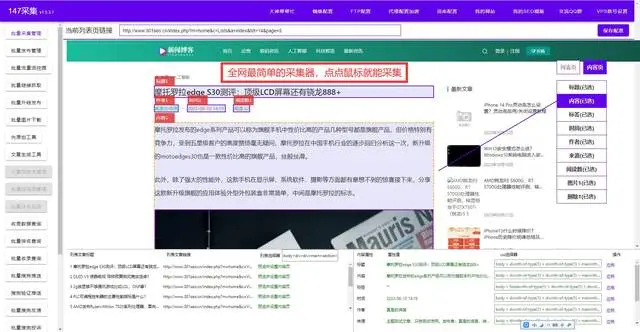
第二款:智能抓取助手
智能抓取助手是一款专为非技术人员设计的AI数据采集软件。它具有友好的操作界面,让用户即使没有编程知识也能轻松上手。这款软件支持基于关键词的全网抓取,用户只需设定好关键词,软件将自动搜索相关信息。更为重要的是,智能抓取助手能够通过AI技术自动分析网页结构,实现智能抓取,提高了数据的准确性。用户可以方便地设定定时任务,实现自动化抓取,确保数据采集的及时性。这一点对于需要持续关注某些信息的用户尤为重要。
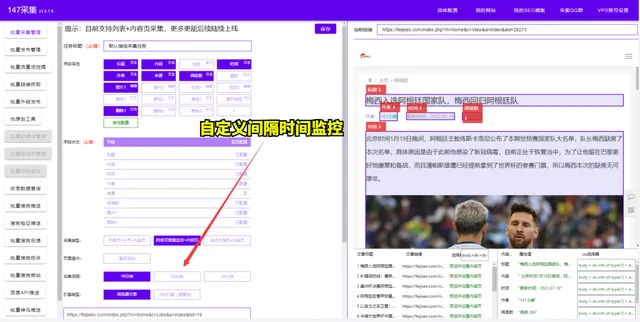
第三款:数据之眼
数据之眼是一款以深度学习为核心的AI数据采集软件。它具有强大的自动化功能,支持全网数据的智能抓取。数据之眼在数据清洗和筛选方面表现出色,能够通过深度学习技术自动识别和清理无效数据,确保用户获得的信息质量更高。此外,该软件还具备高级的定制化功能,用户可以根据自身需求进行个性化设置,灵活控制数据采集的方向。数据之眼的实时监控功能也相当强大,用户可以实时查看抓取进度,并在需要的时候进行手动干预。这一点在对数据及时性要求较高的场景中显得尤为重要。
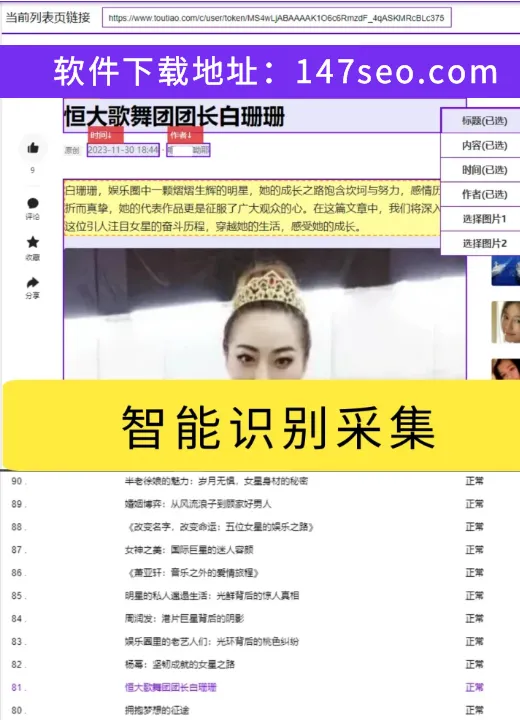
总结
在信息大爆炸的时代,AI数据采集软件为用户提供了更加智能、高效的数据获取解决方案。其中,147免费采集软件以其全网抓取和实时监控的特点,成为了不可忽视的选择。智能抓取助手的友好操作和自动分析网页结构的功能使得数据采集变得更加简单。数据之眼则通过深度学习技术提高了数据的准确性,并具备了高级的定制化功能。选择适合自己需求的AI数据采集软件,将为您的数据获取工作注入新的活力。在未来,随着AI技术的不断发展,我们可以期待更多更先进的数据采集工具的涌现,为用户提供更全面、更高效的服务。
