昆明网站建设首选互维做自己的程序设计在线测评网站
ubuntu与centos系统不同,默认root开机不能登录。
1、输入一下命令创建root密码,根据提示输入新密码
sudo passwd root
2、打开gdm-autologin文件,将auth required pam_succeed_if.so user != root quiet_success这行注释掉,这行就是设置开机不可登录root
sudo gedit /etc/pam.d/gdm-autologin
3、打开gdm-password文件,将auth required pam_succeed_if.so user != root quiet_success 这行注释掉,这行就是设置开机不可登录root
sudo gedit /etc/pam.d/gdm-password
4、将/root/.profile文件里的mesg n 2> /dev/null || true这行注释掉,添加内容:tty -s&&mesg n || true
sudo gedit /root/.profile
5、用reboot命令进行重启
6、以上步骤修改后开机默认root登录界面,如果要开机默认用户登录界面,而不是root登录界面,在文件后面添加2行
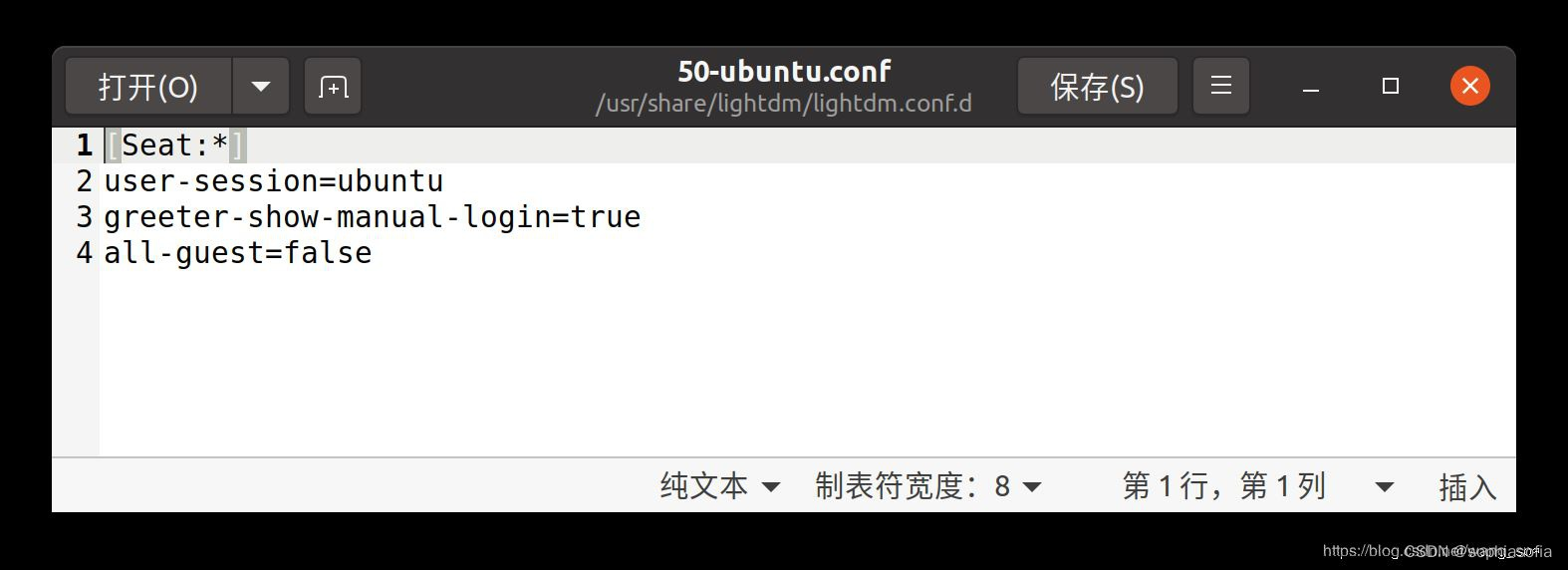
$sudo gedit /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf
在50-ubuntu.conf文件添加如下2行内容:
greeter-show-manual-login=true
all-guest=false
开启ssh远程登录方法:
1、编辑/etc/ssh/sshd_config
sudo vi /etc/ssh/sshd_config
2、找到#PermitRootLogin prohibit-password,在下面添加一行PermitRootLogin yes
#PermitRootLogin prohibit-password
PermitRootLogin yes
3、重启ssh服务
sudo service ssh restart