广州建站模板搭建升腾d9116 做网站
博客主页:🏆看看是李XX还是李歘歘 🏆
🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺
💗点关注不迷路,总有一些📖知识点📖是你想要的💗
⛽️今天的内容是 Leetcode 206. 反转链表 ⛽️💻💻💻
206. 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
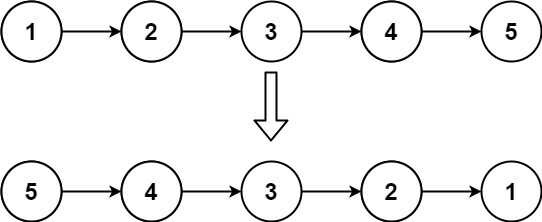
输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]
示例 2:
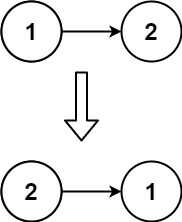
输入:head = [1,2] 输出:[2,1]
示例 3:
输入:head = [] 输出:[]
提示:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
原地反转
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:tmp = Noneres = Nonewhile head is not None :tmp = head.nexthead.next = resres = headhead = tmpreturn res