东莞集团网站建设理财公司网站建设方案
1. 准备模板渲染规格数据
使用Vite快速创建一个Vue项目,在项目中添加请求插件axios,然后新增一个SKU组件,在根组件中把它渲染出来,下面是规格内容的基础模板

<script setup>
import { onMounted, ref } from 'vue'
import axios from 'axios'
// 商品数据
const goods = ref({})
const getGoods = async () => {// 1135076 初始化就有无库存的规格// 1369155859933827074 更新之后有无库存项(蓝色-20cm-中国)const res = await axios.get('http://pcapi-xiaotuxian-front-devtest.itheima.net/goods?id=1369155859933827074')goods.value = res.data.result
}
onMounted(() => getGoods())</script><template><div class="goods-sku"><dl v-for="item in goods.specs" :key="item.id"><dt>{{ item.name }}</dt><dd><template v-for="val in item.values" :key="val.name"><!-- 图片类型规格 --><img v-if="val.picture" :src="val.picture" :title="val.name"><!-- 文字类型规格 --><span v-else>{{ val.name }}</span></template></dd></dl></div>
</template><style scoped lang="scss">
@mixin sku-state-mixin {border: 1px solid #e4e4e4;margin-right: 10px;cursor: pointer;&.selected {border-color: #27ba9b;}&.disabled {opacity: 0.6;border-style: dashed;cursor: not-allowed;}
}.goods-sku {padding-left: 10px;padding-top: 20px;dl {display: flex;padding-bottom: 20px;align-items: center;dt {width: 50px;color: #999;}dd {flex: 1;color: #666;>img {width: 50px;height: 50px;margin-bottom: 4px;@include sku-state-mixin;}>span {display: inline-block;height: 30px;line-height: 28px;padding: 0 20px;margin-bottom: 4px;@include sku-state-mixin;}}}
}
</style>
2. 选中和取消选中实现
基本思路:
- 每一个规格按钮都拥有自己的选中状态数据-selected,true为选中,false为取消选中
- 配合动态class,把选中状态selected作为判断条件,true让active类名显示,false让active类名不显示
- 点击的是未选中,把同一个规格的其他取消选中,当前点击项选中;点击的是已选中,直接取消
<script setup>
// 省略代码// 选中和取消选中实现
const changeSku = (item, val) => {// 点击的是未选中,把同一个规格的其他取消选中,当前点击项选中,点击的是已选中,直接取消if (val.selected) {val.selected = false} else {item.values.forEach(valItem => valItem.selected = false)val.selected = true}
}</script><template><div class="goods-sku"><dl v-for="item in goods.specs" :key="item.id"><dt>{{ item.name }}</dt><dd><template v-for="val in item.values" :key="val.name"><img v-if="val.picture" @click="changeSku(item, val)" :class="{ selected: val.selected }" :src="val.picture":title="val.name"><span v-else @click="changeSku(val)" :class="{ selected: val.selected }">{{ val.name }}</span></template></dd></dl></div>
</template>
3. 规格禁用功能实现
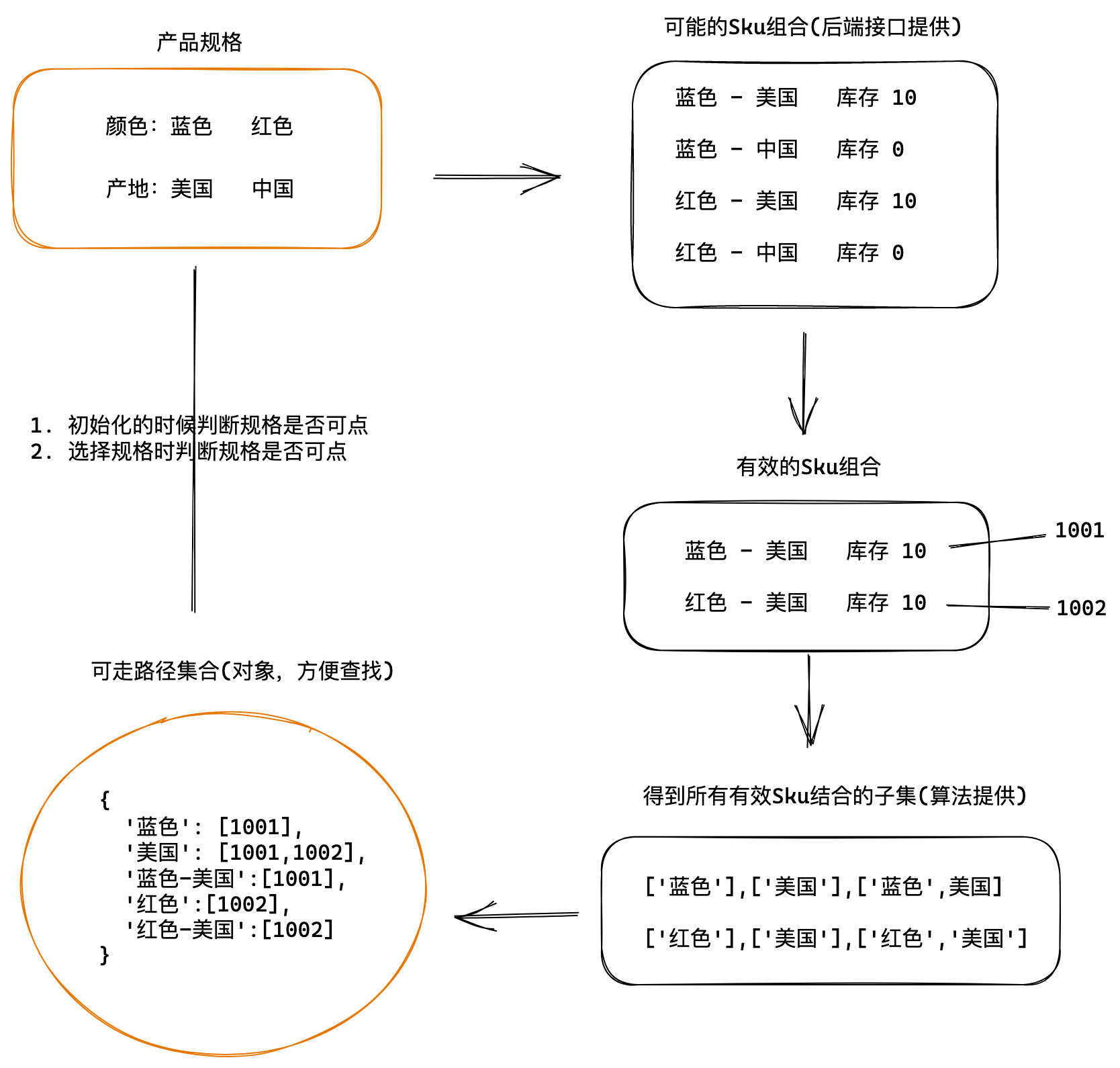
3.1 生成路径字典
幂等算法 power-set.js
export default function bwPowerSet (originalSet) {const subSets = []// We will have 2^n possible combinations (where n is a length of original set).// It is because for every element of original set we will decide whether to include// it or not (2 options for each set element).const numberOfCombinations = 2 ** originalSet.length// Each number in binary representation in a range from 0 to 2^n does exactly what we need:// it shows by its bits (0 or 1) whether to include related element from the set or not.// For example, for the set {1, 2, 3} the binary number of 0b010 would mean that we need to// include only "2" to the current set.for (let combinationIndex = 0; combinationIndex < numberOfCombinations; combinationIndex += 1) {const subSet = []for (let setElementIndex = 0; setElementIndex < originalSet.length; setElementIndex += 1) {// Decide whether we need to include current element into the subset or not.if (combinationIndex & (1 << setElementIndex)) {subSet.push(originalSet[setElementIndex])}}// Add current subset to the list of all subsets.subSets.push(subSet)}return subSets
}
获取有效路径字典:
<script setup>
import {onMounted, ref} from 'vue'
import axios from 'axios'
import powerSet from './power-set.js'
// 商品数据
const goods = ref({})
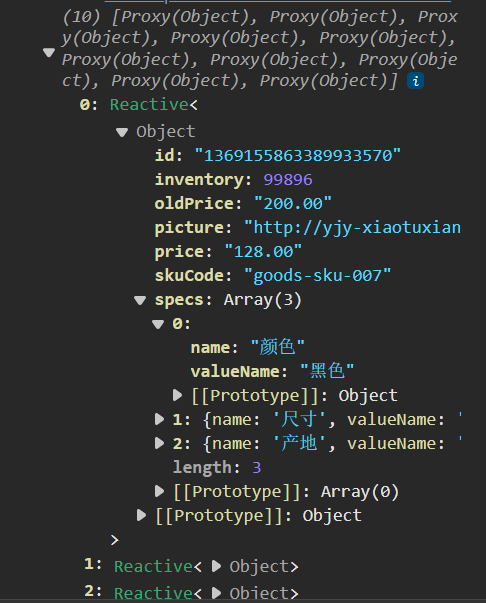
const getGoods = async () => {// 1135076 初始化就有无库存的规格// 1369155859933827074 更新之后有无库存项(蓝色-20cm-中国)const res = await axios.get('http://pcapi-xiaotuxian-front-devtest.itheima.net/goods?id=1369155859933827074')goods.value = res.data.resultconst pathMap = getPathMap(goods.value)console.log(pathMap)
}
onMounted(() => getGoods())
const changeSelectedStatus = (item, val) => {if (val.selected) {val.selected = false} else {item.values.forEach(val => val.selected = false)val.selected = true}
}
// 创建生成路径字典对象函数
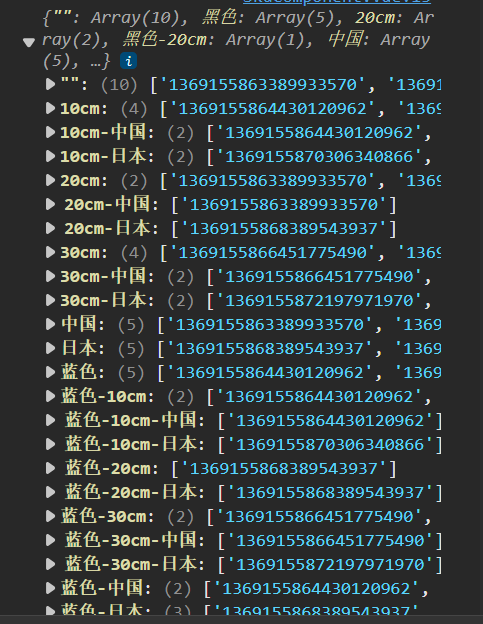
const getPathMap = (goods) => {const pathMap = {}// 1. 得到所有有效的Sku集合const effectiveSkus = goods.skus.filter(sku => sku.inventory > 0)console.log(effectiveSkus)// 2. 根据有效的Sku集合// 使用powerSet算法得到所有子集 [1,2] => [[1], [2], [1,2]]effectiveSkus.forEach(sku => {// 2.1 获取可选规格值数组const selectedValArr = sku.specs.map(val => val.valueName)// 2.2 获取可选值数组的子集const valueArrPowerSet = powerSet(selectedValArr)// 3. 根据子集生成路径字典对象// 3.1 遍历子集 往pathMap中插入数据valueArrPowerSet.forEach(arr => {// 根据Arr得到字符串的key,约定使用-分割 ['蓝色','美国'] => '蓝色-美国'const key = arr.join('-')// 给pathMap设置数据if (pathMap[key]) {pathMap[key].push(sku.id)} else {pathMap[key] = [sku.id]}})})return pathMap
}
</script><template><div class="goods-sku"><dl v-for="item in goods.specs" :key="item.id"><dt>{{ item.name }}</dt><dd><template v-for="val in item.values" :key="val.name"><!-- 图片类型规格 --><img v-if="val.picture" :src="val.picture" :title="val.name"><!-- 文字类型规格 --><span :class="{selected: val.selected}" v-else @click="changeSelectedStatus(item,val)">{{ val.name }}</span></template></dd></dl></div>
</template><style scoped lang="scss">
@mixin sku-state-mixin {border: 1px solid #e4e4e4;margin-right: 10px;cursor: pointer;&.selected {border-color: #27ba9b;}&.disabled {opacity: 0.6;border-style: dashed;cursor: not-allowed;}
}.goods-sku {padding-left: 10px;padding-top: 20px;dl {display: flex;padding-bottom: 20px;align-items: center;dt {width: 50px;color: #999;}dd {flex: 1;color: #666;> img {width: 50px;height: 50px;margin-bottom: 4px;@include sku-state-mixin;}> span {display: inline-block;height: 30px;line-height: 28px;padding: 0 20px;margin-bottom: 4px;@include sku-state-mixin;}}}
}
</style>
console.log(effectiveSkus)
console.log(pathMap)
3.2 根据路径字典设置初始化状态
思路:判断规格的name属性是否能在有效路径字典中找到,如果找不到就禁用
// 1. 定义初始化禁用状态
// specs:商品源数据 pathMap:路径字典
const initDisabledState = (specs, pathMap) => {// 约定:每一个按钮的状态由自身的disabled进行控制specs.forEach(item => {item.values.forEach(val => {// 路径字典中查找是否有数据 有-可以点击 没有-禁用val.disabled = !pathMap[val.name]})})
}// 2. 在数据返回后进行初始化处理
let patchMap = {}
const getGoods = async () => {// 1135076 初始化就有无库存的规格// 1369155859933827074 更新之后有无库存项(蓝色-20cm-中国)const res = await axios.get('http://pcapi-xiaotuxian-front-devtest.itheima.net/goods?id=1135076')goods.value = res.data.resultpathMap = getPathMap(goods.value)// 初始化更新按钮状态initDisabledState(goods.value.specs, pathMap)
}// 3. 适配模板显示
<img :class="{ selected: val.selected, disabled: val.disabled }"/>
<span :class="{ selected: val.selected, disabled: val.disabled }">{{val.name }}</span>
3.3 根据路径字典设置组合禁用状态
思路:
- 根据当前选中规格,生成顺序规格数组 => [‘黑色’, undefined, undefined ]
- 遍历每一个规格按钮
如何规格按钮已经选中,忽略判断
如果规格按钮未选中,拿着按钮的name值按顺序套入匹配数组对应的位置,最后过滤掉没有值的选项,通过-进行拼接成字符串key, 去路径字典中查找,没有找到则把当前规格按钮禁用
// 获取选中匹配数组 ['黑色',undefined,undefined]
const getSelectedValues = (specs) => {const arr = []specs.forEach(spec => {const selectedVal = spec.values.find(value => value.selected)arr.push(selectedVal ? selectedVal.name : undefined)})return arr
}const updateDisabledState = (specs, pathMap) => {// 约定:每一个按钮的状态由自身的disabled进行控制specs.forEach((item, i) => {const selectedValues = getSelectedValues(specs)item.values.forEach(val => {if (val.selected) returnconst _seletedValues = [...selectedValues]_seletedValues[i] = val.nameconst key = _seletedValues.filter(value => value).join('*')// 路径字典中查找是否有数据 有-可以点击 没有-禁用val.disabled = !pathMap[key]})})
}
4. 产出 prop 数据
const changeSku = (item, val) => {// 省略...// 产出SKU对象数据const index = getSelectedValues(goods.value.specs).findIndex(item => item === undefined)if (index > -1) {console.log('找到了,信息不完整')} else {console.log('没有找到,信息完整,可以产出')// 获取sku对象const key = getSelectedValues(goods.value.specs).join('*')const skuIds = pathMap[key]console.log(skuIds)// 以skuId作为匹配项去goods.value.skus数组中找const skuObj = goods.value.skus.find(item => item.id === skuIds[0])console.log('sku对象为', skuObj)}
}