黔江网站建设免费做期中考试的网站
欢迎来CILMY23的博客
本篇主题为 探索 Python 编程世界:常量、变量及数据类型解析
个人主页:CILMY23-CSDN博客
Python系列专栏:http://t.csdnimg.cn/HqYo8
上一篇博客: http://t.csdnimg.cn/SEdbp
C语言专栏: http://t.csdnimg.cn/hQ5a9
感谢观看,支持的可以给个一键三连,点赞关注+收藏。
文章目录
一、常量
二、变量
2.1 变量概述
2.2 变量的命名
2.3 变量的使用
2.4 多变量的使用
2.5 理解python是动态类型语言
三、python中的数据类型
3.1 数字类型
3.1.1 整型
3.1.2 浮点型
3.1.3 布尔类型
3.2 组合数据
3.2.1 字符串
3.2.2 list 列表
3.2.3 tuple 元组
3.2.4 set 集合
3.2.5 dict 字典
本文前言
在上期我们讲解完一些python中的剩下语法后,本篇将开始python中的基础,常量和变量以及各种数据类型的详解
一、常量
在过去我写C语言的时候是这么介绍常量的

在python中有点类似又有点差别, 常量一般指不需要改变也不能改变的常数或常量,如一个数字3、一个字符串"火星"、等等
在 Python 中,虽然没有严格意义上的常量,但可以通过约定来表示常量,通常使用全大写字母命名的变量来表示常量,并在程序中不修改它们的值。这样的约定可以让其他开发者或者自己更容易理解和识别代码中的常量。但是其本质还是个变量。
例如:
PI = 3.1415926
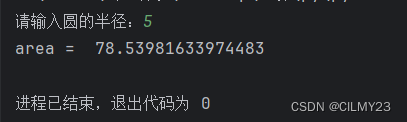
r = float(input("请输入圆的半径:"))
area = PI * r * r
print("area = ", area)当然对这段代码我们也可以用python中自带的库来解决pi的赋值
import mathPI = math.pi
r = float(input("请输入圆的半径:"))
area = PI * r * r
print("area = ", area)结果如下:
二、变量
在过去我们讲解C语言的变量的时候,我们说变量需要先定义后使用的

而在python中,我们并不需要声明,也不需要数据类型,python中的变量会自动识别数据类型。
2.1 变量概述
变量是程序中用于存储数据的一种容器,它可以用来表示各种不同类型的值,如数字、字符串、列表等。Python是一种强制类型语言,也是一种动态类型的语言,Python解释器会根据赋值或运算来推断变量类型,变量的类型是随着其值随时变化的。这意味着我们可以在程序运行过程中为变量赋予不同类型的值。
2.2 变量的命名
python中变量的命名遵循标识符的命名,经常用的还是驼峰命名法,有需要回顾的可以看编程初探1 http://t.csdnimg.cn/Fm69q
2.3 变量的使用
在使用变量的时候,我们并不需要像C语言那样先定义后使用,只需要给这个变量赋值即可。
x = 5
name = "John"
print(x)
print(name)结果如下:

2.4 多变量的使用
在过去我们使用c语言给多变量赋值的形式通常是这样的
int a, b, c;
a = 1;
b = 2;
c = 3;
或者这样
int a, b, c;
a = 1, b = 2, c = 3;
现在我们可以逐个进行赋值:
a = 1
b = 2
c = 3
也可以在同一行赋值
a, b, c = 1, 2, 3
2.5 理解python是动态类型语言
在Python中,变量的类型是在运行时动态确定的,而不是在编译时静态确定的。我们将其理解为动态类型
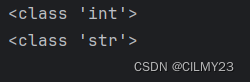
x = 5
name = "John"
print(type(x))
print(type(name))结果如下所示
动态类型检查: 在Python中,变量的类型是动态检查的,这意味着变量的类型会在运行时进行检查。如果尝试对变量进行不兼容的操作,Python会在运行时引发类型错误。
例如:
x = 5
print(x + "hello")

这段代码会引发类型错误(TypeError),因为在Python中,不能对整数和字符串进行直接的加法操作。
动态分配内存: Python会根据变量的值动态分配内存空间,而不需要在编写代码时提前指定内存大小或类型。这使得Python在处理变量时更加灵活和简便。
三、python中的数据类型
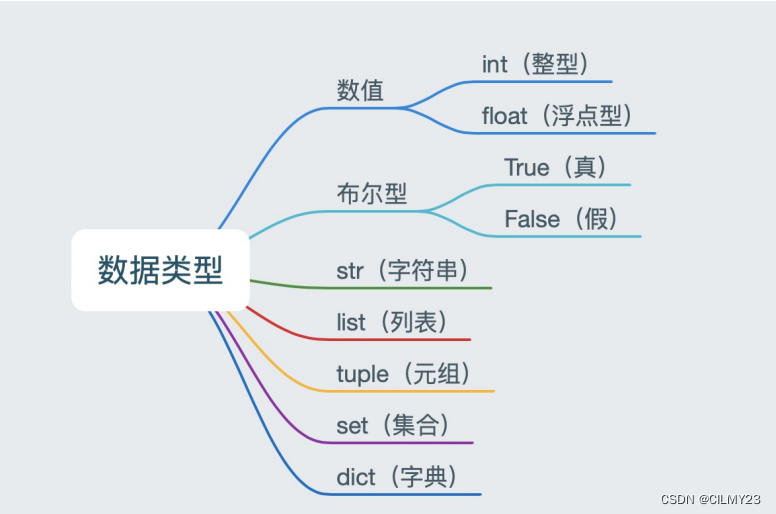
Python中的基本数据类型可以分为两类:数字和组合数据,数字包括整型,浮点数,布尔值和复数,组合数据包括字符串,列表,元组,字典,集合。接下来我们将具体讲解各个类型
3.1 数字类型
3.1.1 整型
整型(Int)又称为整数。整型可以用来存储任意大小的整数值,包括负整数、零和正整数。整型对象是不可变的,这意味着一旦创建了整型对象,就无法修改其值。整型不限制大小,在python 3.12版本中没有像C语言当中这些长整型,短整型这些数据类型。
x = 123 # 正整数
y = -456 # 负整数
z = 0 # 零
整型可以用其他进制的数来表示
B = 0b1010 # 二进制表示法,等于十进制的10
O = 0o777 # 八进制表示法,等于十进制的511
H = 0xFF # 十六进制表示法,等于十进制的255
Python提供了几个内置函数来进行不同进制之间的相互转换,其中包括bin(),int(),oct()和hex()函数。
- bin(): 将其他进制数转换成二进制数。
- oct(): 将其他进制数转换成八进制数。
- hex(): 将其他进制数转换成十六进制数。
- int(): 将其他进制数转换成十进制数。
在这里就不详细举例子了,感兴趣的可以自己探索
3.1.2 浮点型
在实际应用中,仅仅使用整数来描述数字信息是远远不够的,还需要引入浮点数进入补充,浮点型(Float),用于表示带有小数点的数值。浮点型数据可以用来存储任意大小的浮点数,包括正数、负数和零。
浮点数采用双精度浮点数格式表示,通常占据64位(8个字节)内存空间。浮点型数据可以使用整数+小数来表示,也可以使用科学计数法表示大数值。同样在python中没有像在C语言中还有分double这些浮点类型,python中只有Float类型。
浮点型的输出:
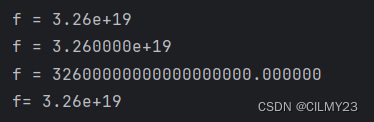
f = 32.6e18
print("f =", f)
print("f = %e" % f)
print("f = %f" % f)
print(f"f= {f}")结果如下:
浮点型数据支持基本的数学运算,包括加法、减法、乘法、除法和取模等操作。然而,由于浮点数在计算机中是以二进制形式表示的,因此可能会出现精度丢失的问题。这意味着在进行浮点数运算时,可能会出现舍入误差,需要特别注意。
3.1.3 布尔类型
布尔类型(Bool)是一种基本的数据类型,用于表示逻辑值。布尔类型有两个取值:True(真)和False(假)。布尔类型通常用于条件判断和逻辑运算中,以控制程序的流程和行为。
布尔类型的值True和False是内置的关键字,它们不仅代表了逻辑上的真和假,还可以作为整数的1和0来进行运算。
在Python中,布尔类型通常与条件语句(如if语句)和逻辑运算符(如and、or、not等)一起使用,用于控制程序的流程和逻辑。(现在看不懂也没关系可以学到后面再来回顾)
x = True
y = False
if x:print("x is True")
else:print("x is False")
布尔类型的值:
print(True == 1)
print(False == 0)
以上代码的结果,其中 == 是表示等于的意思,在后面学习运算符的时候会讲解

3.2 组合数据
3.2.1 字符串
字符串(String)是一种在编程语言中用来表示文本数据的数据类型。字符串是一系列字符的序列,可以包含字母、数字、特殊字符和空格等。字符串可以使用单引号(')或双引号(")来表示,python还允许使用三引号(''')或('''''')创建跨多行的字符串,这种字符串中可以换行符、制表符及其他特殊字符,所以其实之前的注释本质上还是个字符串
例如:
str1 = 'Hello, World!'
str2 = "Python Programming"
在python中,并没有像c语言那样分字符串和单字符,而是将这些全都归为字符串。
Python又为字符串中的每个字符分配一个数字来指代这个元素的位置,即索引。第一个元素的索引是0,第二个元素的索引是1。(有点类似C语言中的下标),同时,字符串还支持反向索引,字符串中最后一个字符的索引是-1,倒数第二个字符的索引是-2……
例如:
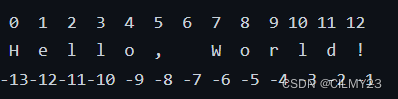
通过字符索引我们可以获取不同字符
s = "Hello, World!"print(s[0]) # 输出:H
print(s[-1]) # 输出:!
print(s[7:12]) # 输出:World
print(s[:-7]) # 输出:Hello,
print(s[::-1]) # 输出:!dlroW ,olleH(字符串反转)
字符串索引在Python中非常常用,它们可以用于访问、修改和操作字符串中的内容。
3.2.2 list 列表
列表(List)是Python中最常用的数据结构之一,用于存储一系列有序的元素集合。列表可以包含任意类型的元素,包括整数、浮点数、字符串、布尔值、甚至其他列表等。
列表是可变的,这意味着可以修改列表的内容,包括添加、删除和修改元素。(就有点像C语言里的数组),列表使用方括号[]来表示,列表中的元素可以通过索引访问,索引从0开始递增。
例如:
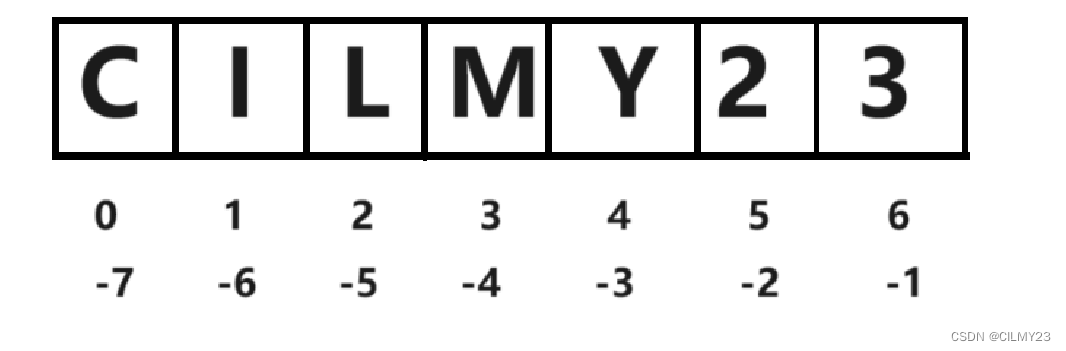
my_list = ['C', 'I', 'L', 'M', 'Y', 2, 3]
print(my_list[0])
print(my_list[1])
print(my_list[2])
print(my_list[-4])
print(my_list[-3])打印结果如下所示:

示意图如下:
列表可以进行切片操作,通过指定起始索引和结束索引来获取子列表。切片操作返回一个新的列表,包含指定范围内的元素,是一个左闭右开区间。
例如:
my_list = ['C', 'I', 'L', 'M', 'Y', 2, 3]
print(my_list[1:4])打印结果:
![]()
除了基本的访问和切片操作外,列表还支持多种方法和函数,用于添加、删除、修改和查询元素,如
append()、insert()、remove()、pop()、index()等。
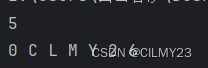
my_list = ['C', 'I', 'L', 'M', 'Y', 2, 3]my_list.append(6) # 在列表末尾添加元素
my_list.insert(0, 0) # 在指定位置插入元素
my_list.remove(3) # 删除指定元素
my_list.pop(2) # 删除指定索引处的元素
print(my_list.index(2)) # 查找指定元素的索引for i in my_list:print(i,end=" ")
结果如下:
3.2.3 tuple 元组
元组(Tuple)是Python中的一种有序、不可变的数据结构,类似于列表,但元组中的元素不能被修改、添加或删除。元组可以包含任意类型的元素,包括整数、浮点数、字符串等。
元组使用圆括号
()来表示,元素之间用逗号分隔,同样可以使用索引来访问
my_tuple = ('C', 'I', 'L', 'M', 'Y', 2, 3)print(my_tuple[0])
print(my_tuple[2:4]) 结果如下:
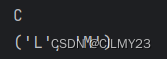
元组通常用于存储不可变的数据集合,例如函数返回多个值时会以元组的形式返回。在需要保持数据不可变性的场景下,使用元组比列表更合适。 (就有点类似于C语言中指针加了个const修饰,我们不希望本身的内容被修改,从而让const修饰指针,读不懂没有关系,只需要知道这条性质)
def get_num():return (3.5, 7.2)x, y = get_num()
print("x num:", x)
print("y num:", y)虽然元组不可变,但其中的元素可以是可变对象,例如列表。这样就可以创建包含可变数据的元组,但仍无法修改元组本身的结构。
change_tuple = ([1, 2], [3, 4])
change_tuple[0].append(3)
print(change_tuple) 结果如下:
![]()
3.2.4 set 集合
集合(Set)是Python中的一种无序、不重复的数据集合,类似于数学中的集合概念。集合中的元素是唯一的,不存在重复的元素,并且集合是无序的,不支持通过索引来访问元素。
集合使用花括号
{}来表示,元素之间用逗号分隔。
例如:
my_set = {1, 2, 3, 4, 5}集合可以进行交集、并集、差集等操作,也支持添加、删除、更新等操作,但不支持索引访问。
# 集合支持交集并集等等操作
set1 = {1, 2, 3}
set2 = {3, 4, 5}# 求交集
same = set1 & set2
print(same) # 求并集
union = set1 | set2
print(union) # 求差集
dif= set1 - set2
print(dif) # 添加元素
my_set.add(6)
print(my_set) # 删除元素
my_set.remove(3)
print(my_set)
结果如下:

集合通常用于去除重复元素、判断元素是否存在以及数学运算等场景。由于集合中的元素是唯一的,因此可以高效地进行去重操作。
3.2.5 dict 字典
字典(Dict)是一种可变的、无序的数据结构,用于存储键值对。字典中的每个元素都由一个键(key)和对应的值(value)组成,键必须是唯一的,但值可以重复。(个人理解有点像C语言中的结构体)
字典使用花括号
{}来表示,每个键值对之间用冒号:分隔,键和值之间用逗号分隔。
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}

在字典中,可以通过键来访问对应的值,这类似于在列表和元组中通过索引来访问元素。但字典中的键不是按顺序存储的,因此无法通过索引来访问。
print(my_dict['name'])
print(my_dict['age']) 结果如下:
字典是可变的,可以添加、删除和修改键值对。可以使用赋值语句来修改现有的键值对,使用del关键字来删除指定的键值对,使用update()来添加新的键值对或更新现有的键值对。
# 修改键值对
my_dict['age'] = 31# 删除键值对
del my_dict['city']# 添加新的键值对
my_dict['gender'] = 'female'print(my_dict) 结果如下:

总结:
字典可以包含任意类型的键和值,甚至可以包含其他字典或列表作为值。键通常是不可变的类型,如整数、字符串、元组等,而值可以是任意类型的对象。
感谢各位同伴的支持,本期python就讲解到这啦,下期博客会扩展输入输出的用法和如何转换数字类型,以及一些特殊的数字类型,如果你觉得写的不错的话,可以给个一键三连,点赞,关注+收藏,若有不足,欢迎各位在评论区讨论。