房子网站有哪些龙岩网站设计招聘网
合集 ChatGPT 通过图形化的方式来理解 Transformer 架构
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习一
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习二
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习三
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习四
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习五
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习六

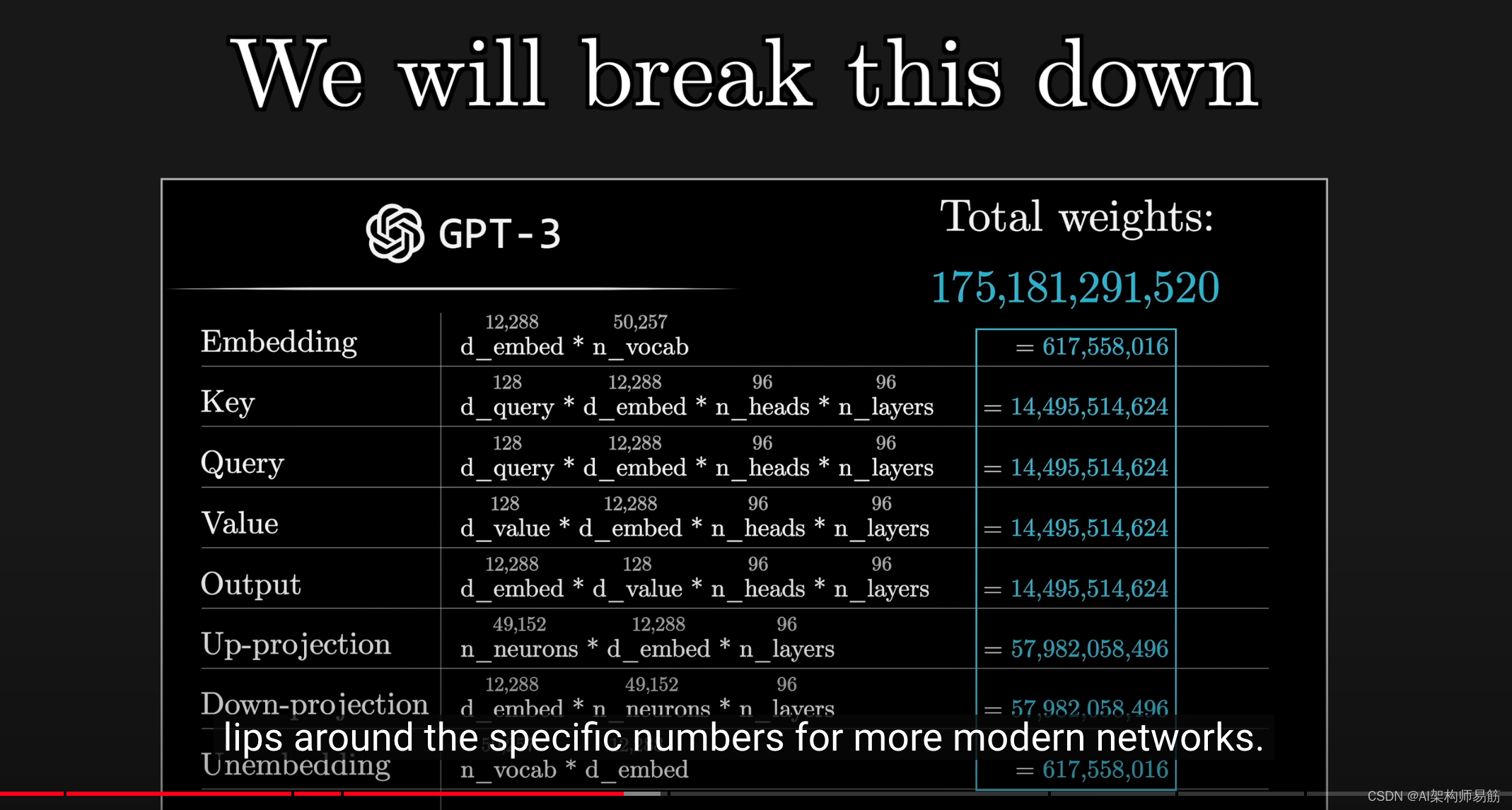
例如,GPT-3中的1750亿个权重

被组织成大约28000个不同的矩阵。

这些矩阵然后被分为8个不同的类别,

你和我要做的就是一个一个地理解每一个类别,了解每种类型的功能。

接下来的过程将非常有趣,我们将查看GPT-3的具体数据,以弄清楚1750亿是如何分配的。

尽管现在有更大更好的模型可用,但GPT-3模型仍然具有独特的魅力,作为第一个吸引全球关注的大型语言模型,其影响不限于机器学习社区。
事实上,对于更现代的模型,公司往往对具体数据保持更严格的保密。

在这里,我想说明的是,当你深入研究像ChatGPT这样的工具的内部工作原理时,
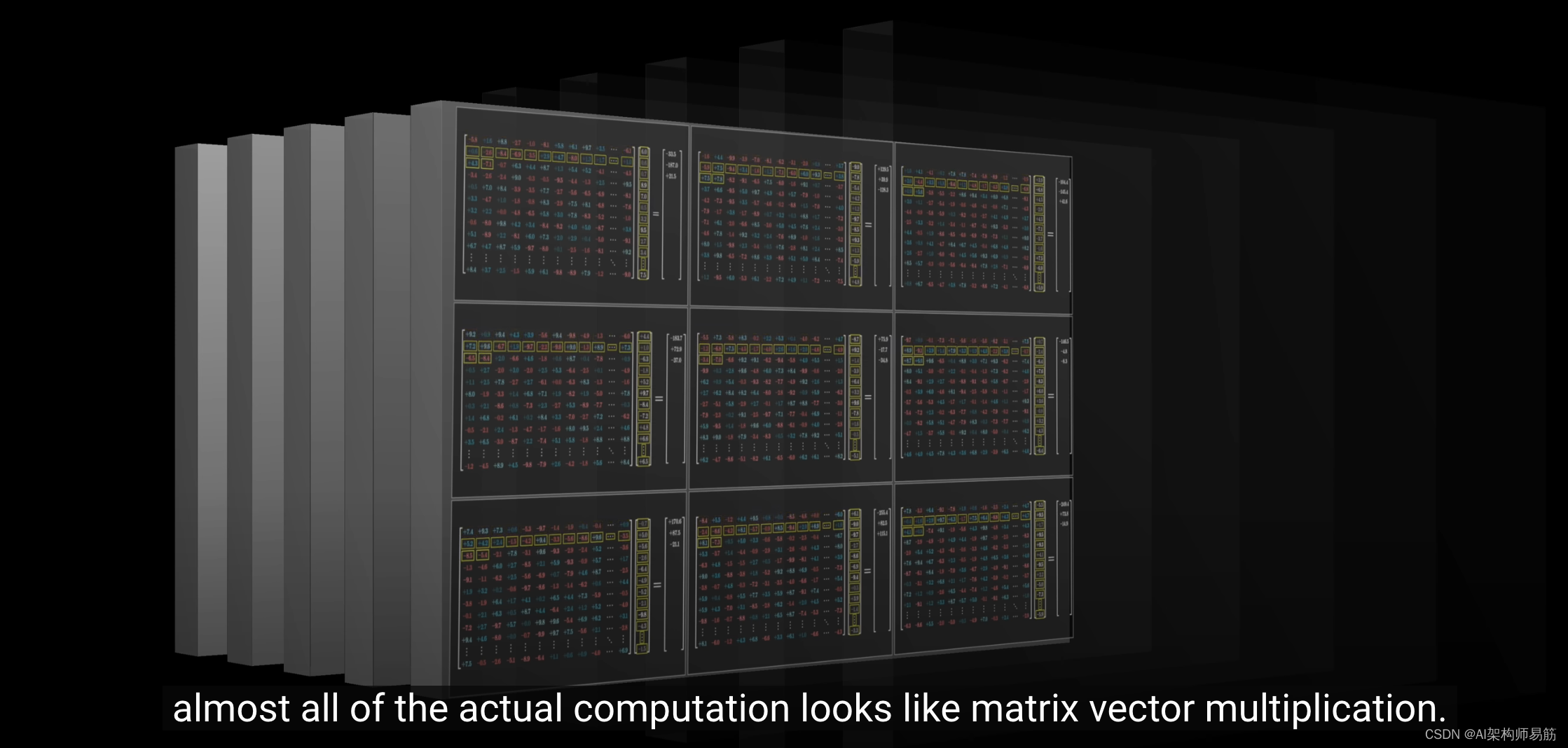
你会发现几乎所有的计算过程都体现为矩阵和向量的乘积。

在大量的数字中很容易迷失方向,
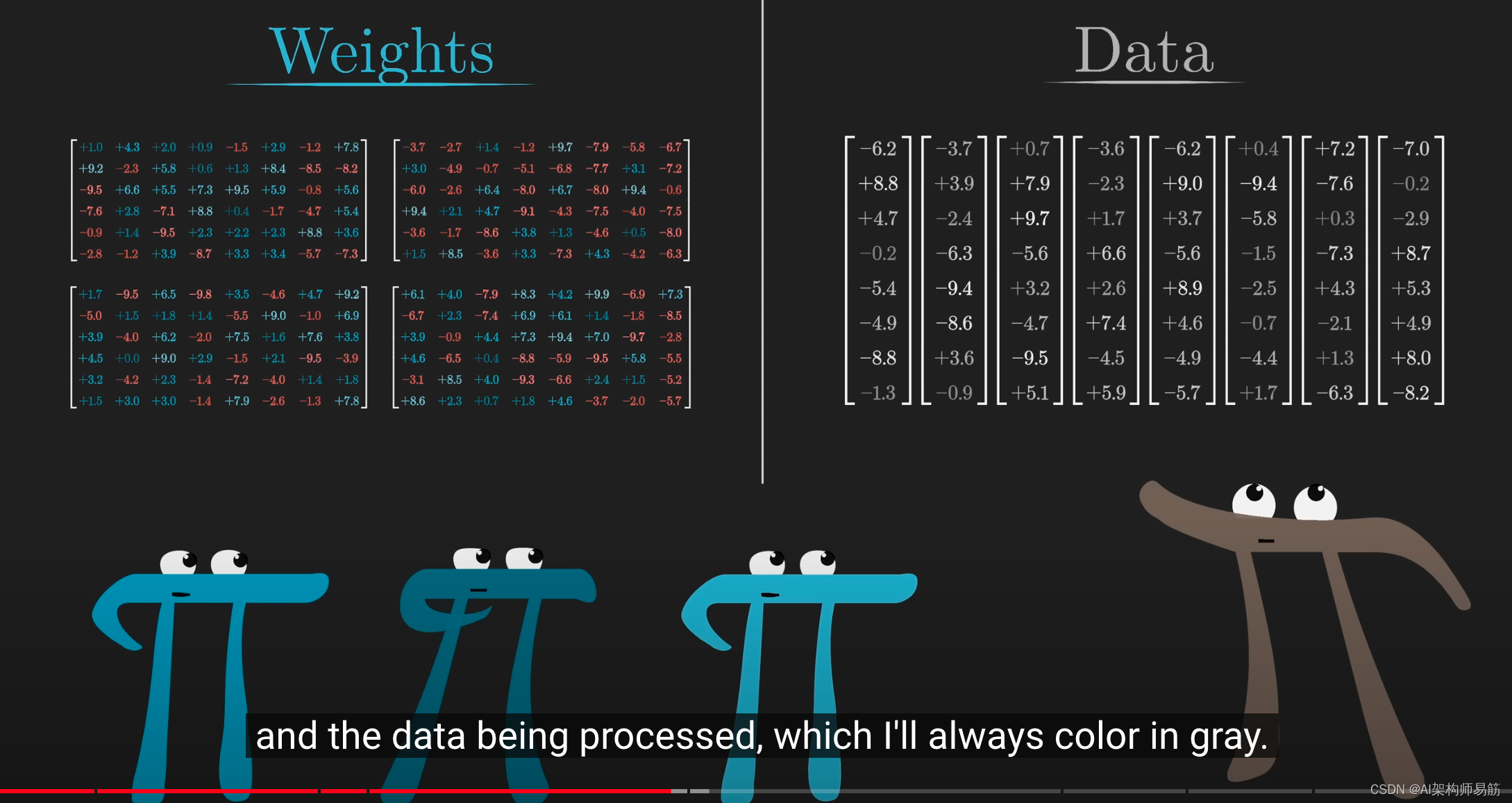
但你需要在脑海中清楚地区分两个概念:模型的权重(我用蓝色或红色表示)和你正在处理的数据(我用灰色表示)。
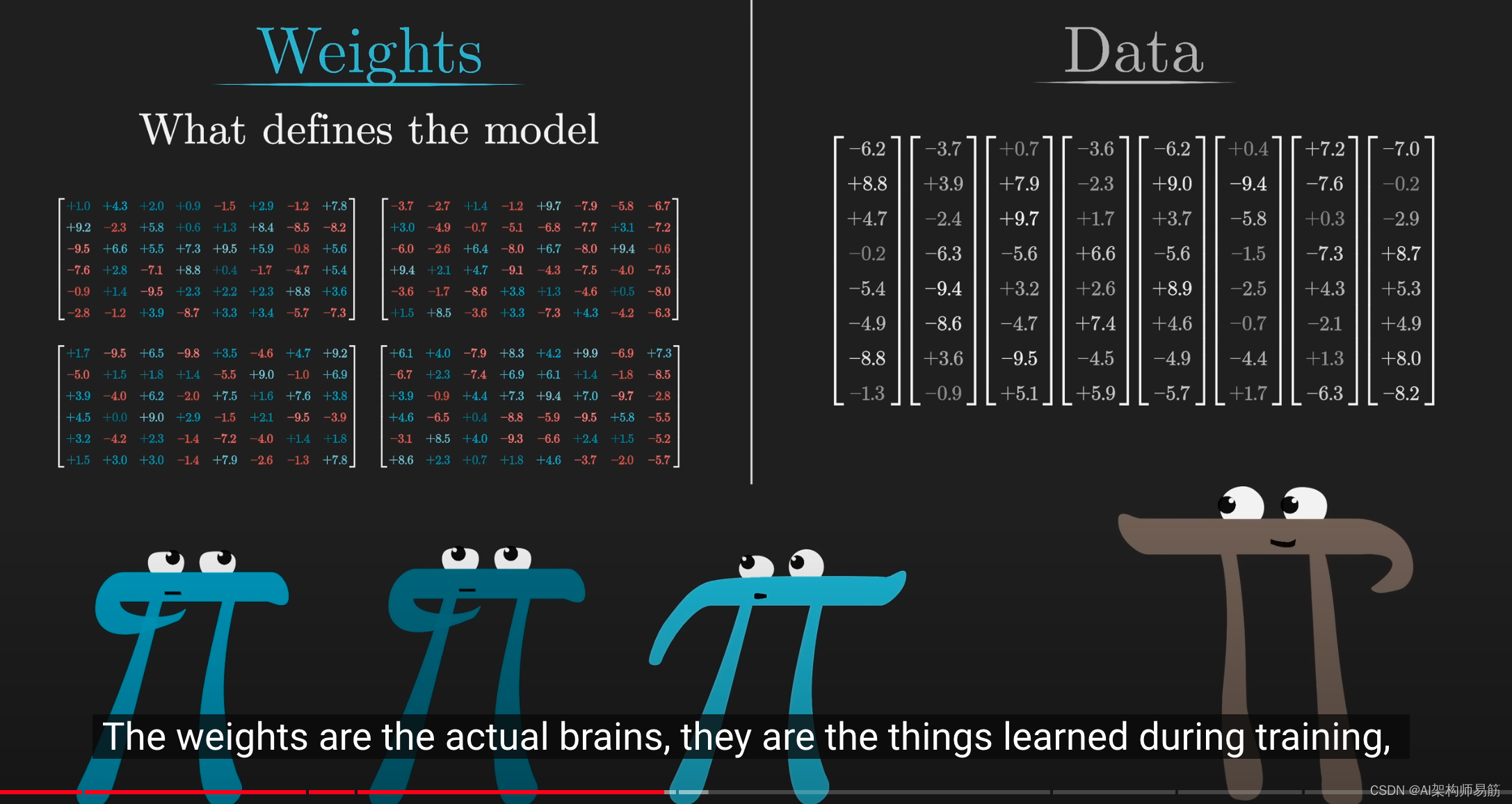
权重是模型的"大脑"。
这些是在训练期间学习的,它们决定了模型的行为模式。

正在处理的数据只是对模型在一次操作中接收的特定输入进行编码,例如一段文本。
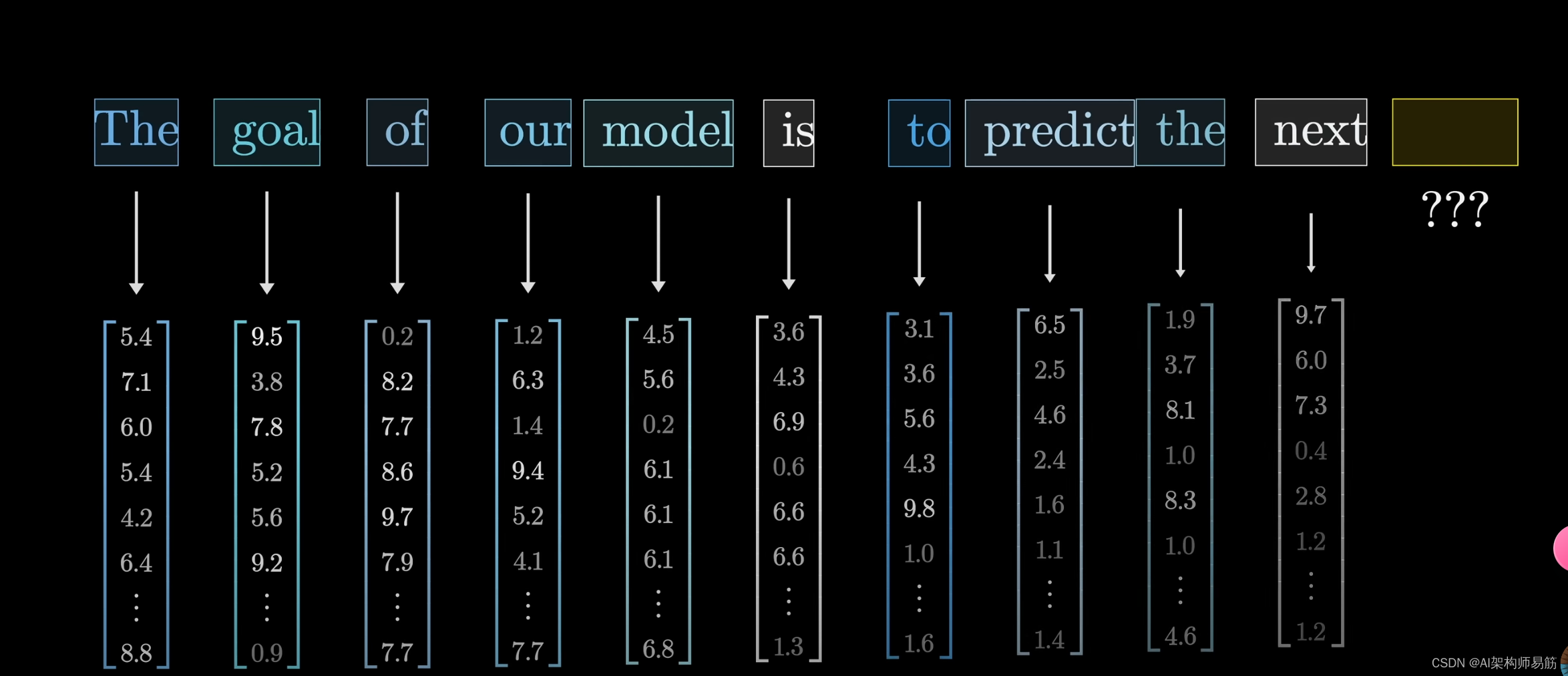
记住上面的基础知识,让我们探索文本处理示例的第一步:将输入分割成小片段并将这些片段转换为向量。

我之前提到过,这些小片段被称为tokens,它们可能是单词的一部分或标点符号,但在本章中,特别是在下一章中,我倾向于简化理解,假设它们对应于完整的单词。
因为我们人类是用词来思考的,通过参考小例子并解释每一步,我们可以让这个过程更容易理解。

该模型预设了一个包含所有可能单词的词汇表,比如说有50000个。
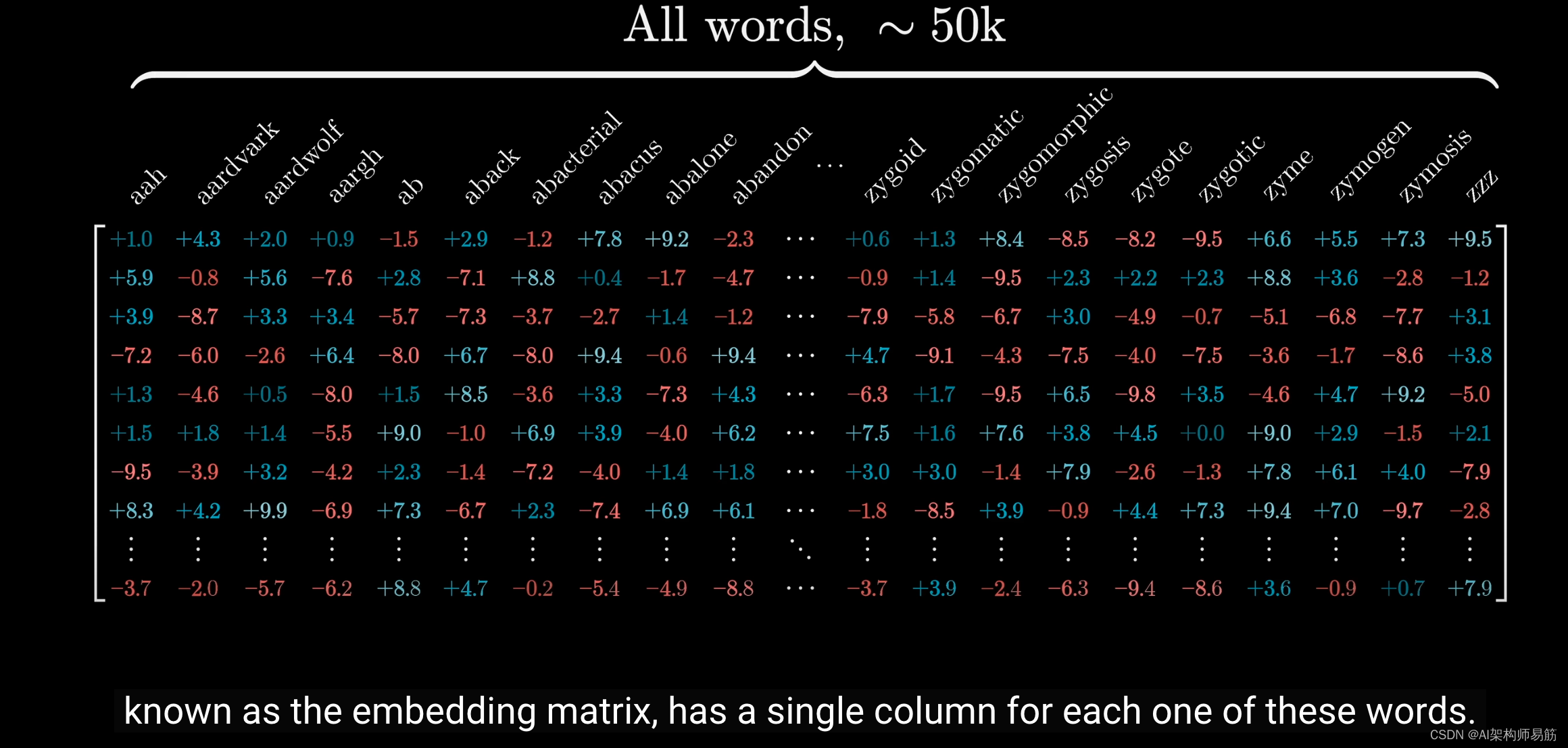
我们要遇到的第一个矩阵称为嵌入矩阵(embedding matrix),它为每个单词分配了一个单独的列。

这些列定义了第一步中每个单词转换成的向量。

我们称之为 W E W_E WE,就像我们看到的所有其他矩阵一样,

它的初始值是随机的,

但会根据数据进行学习和调整。
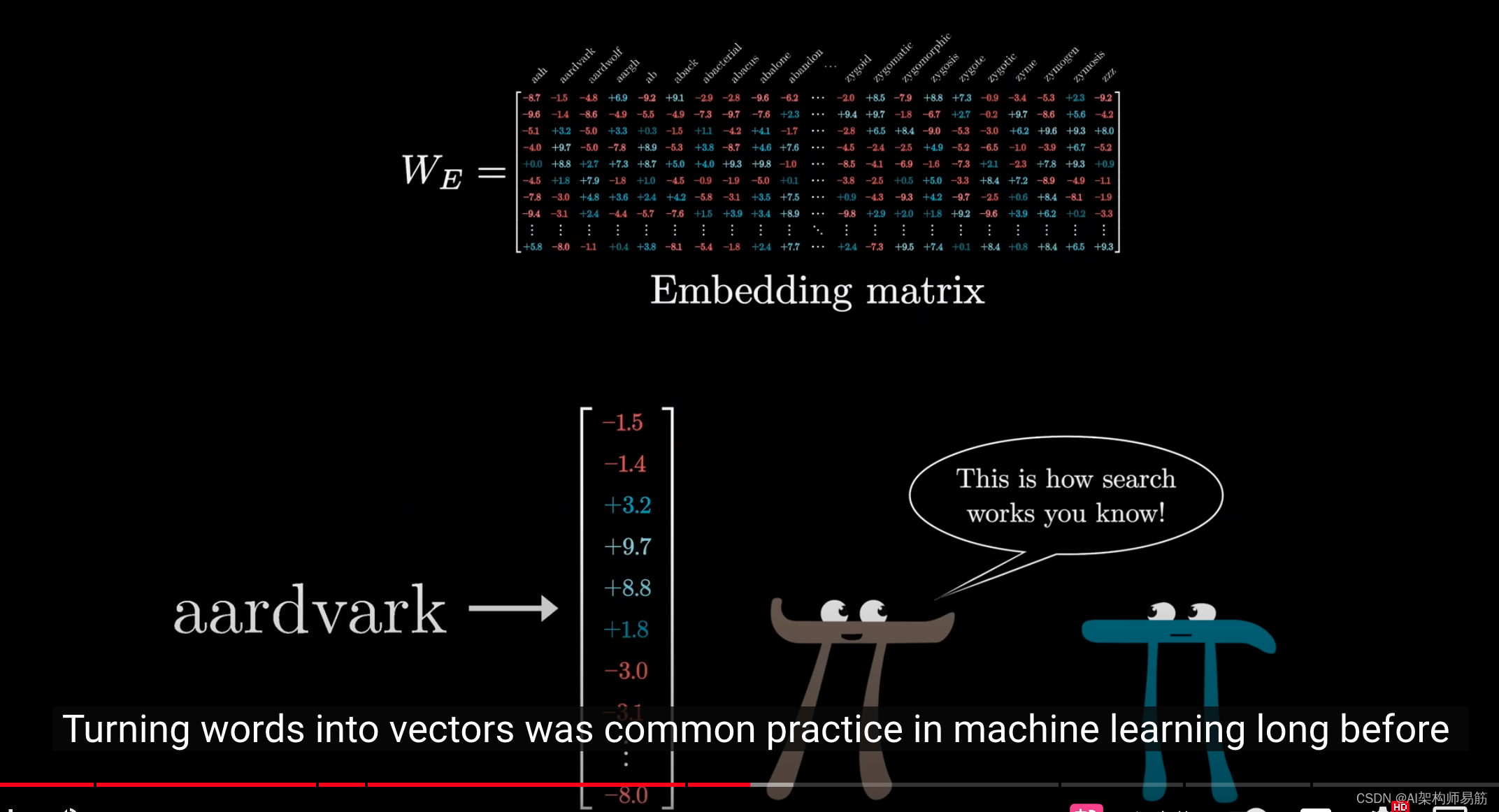
在Transformer出现之前,将单词转换为向量的做法在机器学习中已经很普遍,
虽然对于第一次接触的用户来说这可能看起来很奇怪,但它为接下来的一切奠定了基础,所以需要花一些时间来熟悉它。
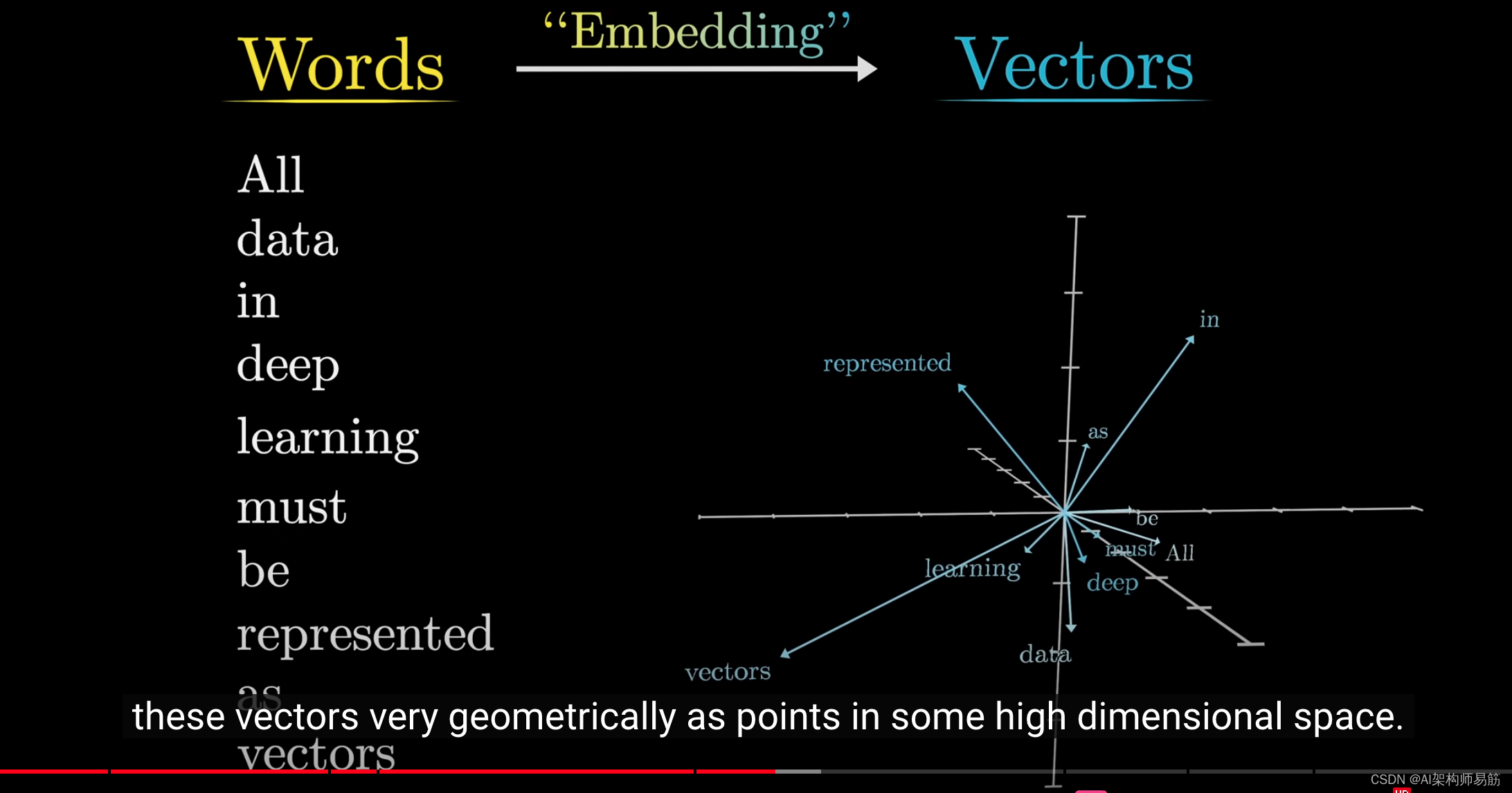
我们通常将这种转换称为词嵌入(word embedding),它是一种表示,允许你从几何角度理解这些向量,将它们视为高维空间中的点。
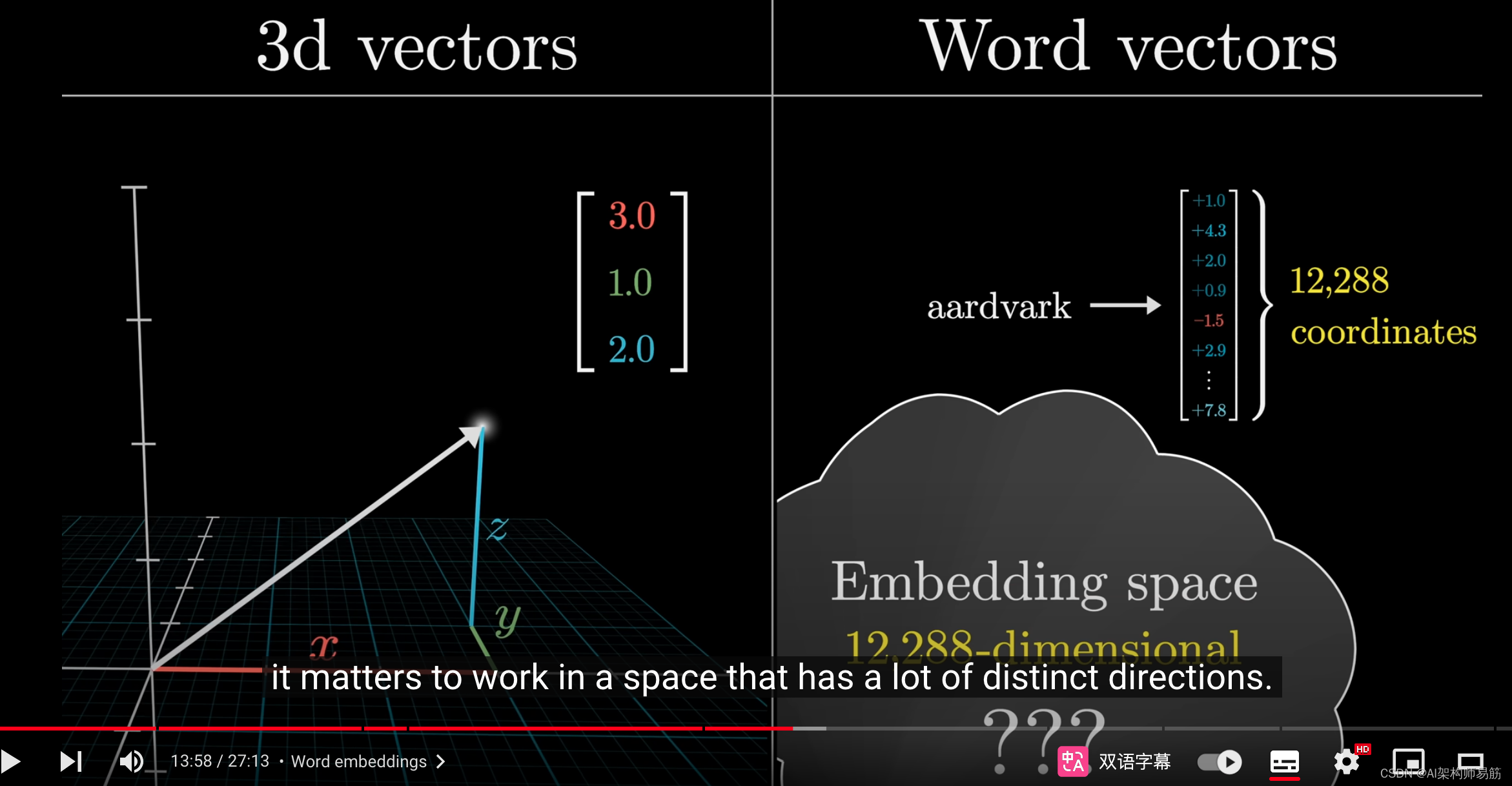
将三个数字视为三维空间中的坐标很容易,但词向量的维度远远超过这个数量。
在GPT-3中,它们有惊人的12288个维度,正如你所看到的,选择一个有很多不同方向的空间来工作是很重要的。
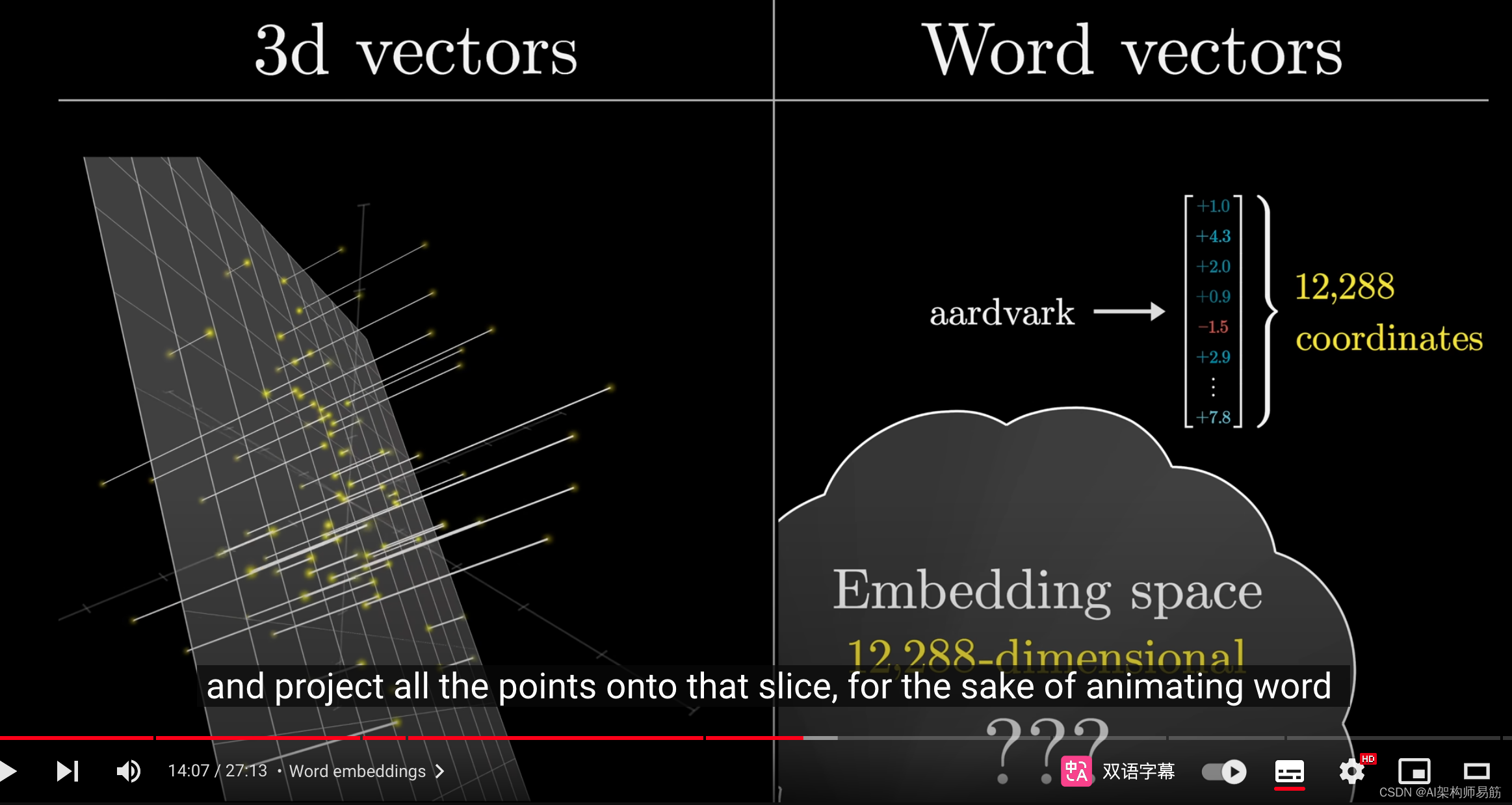
就像你可以在三维空间中选择一个二维切片,并将所有点投影到这个切片上一样,为了使一个简单模型输出的词向量能够动态显示,
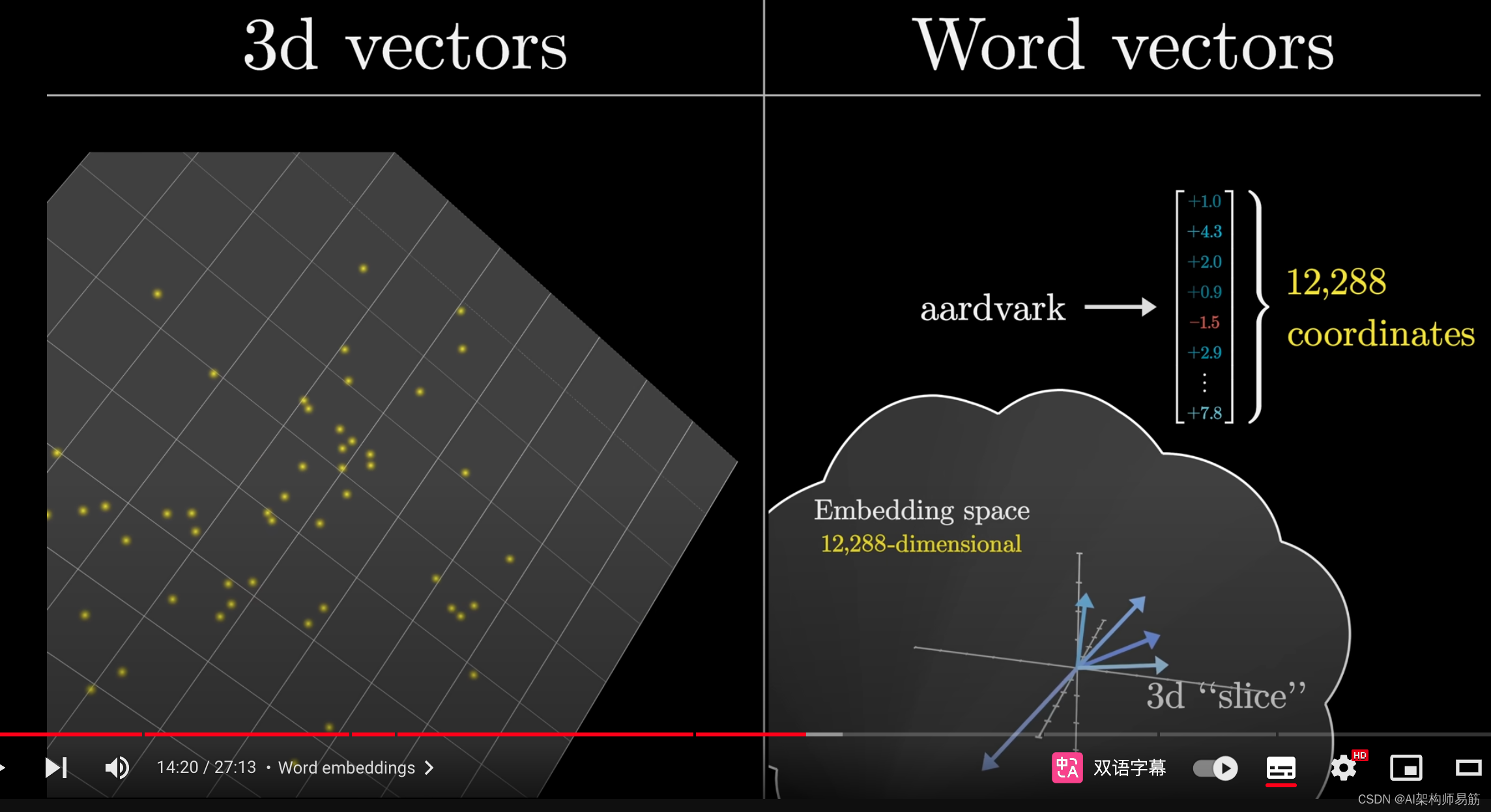
我采取了类似的方法,在高维空间中选择一个三维"切片",并将词向量映射到这个切片上进行显示。
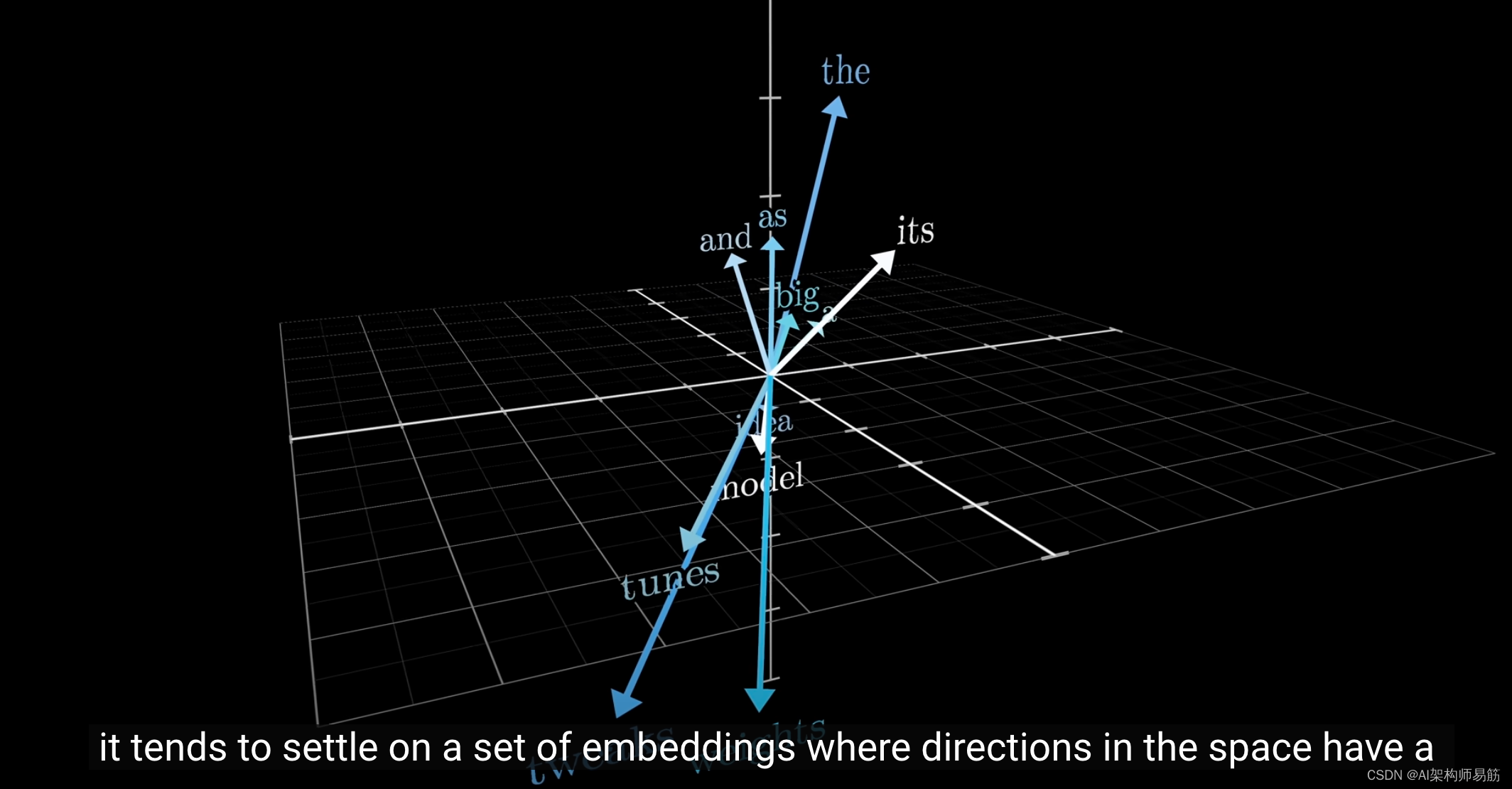
这里的关键思想是,模型在训练过程中调整和微调权重,以确定单词如何具体嵌入为向量,并且它倾向于找到一组嵌入,使得这个空间中的方向具有特定的语义含义。
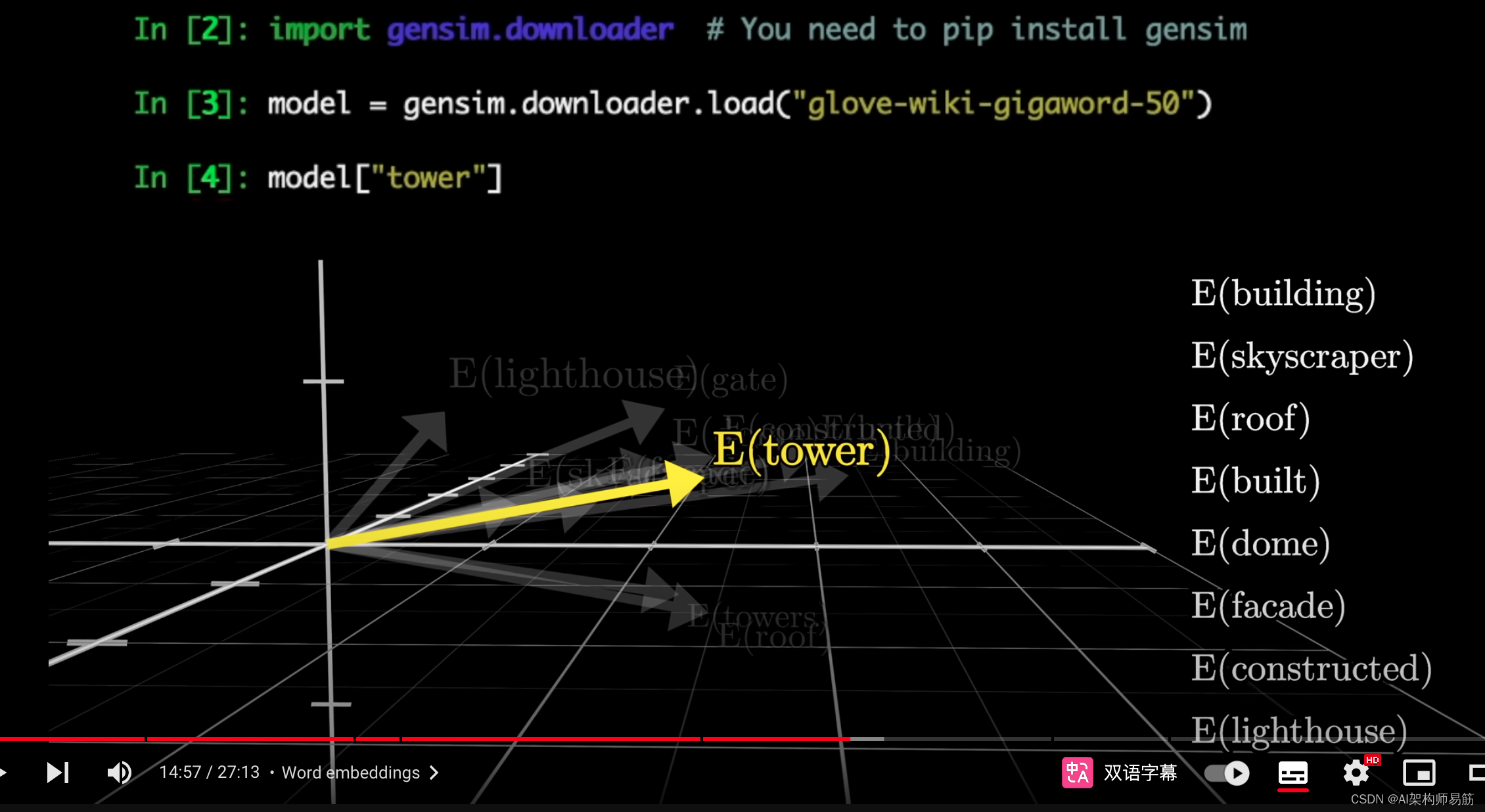
对于到目前为止我运行的这个简单的词向量模型,如果我搜索并找到与"tower"最相似的所有词向量,你会发现它们都有类似的"tower感"。
如果你想在家用Python试一试,这就是我用来制作动画的模型。
虽然它不是一个Transformer模型,但它足以说明空间中的方向能够传达特定的语义这一点。
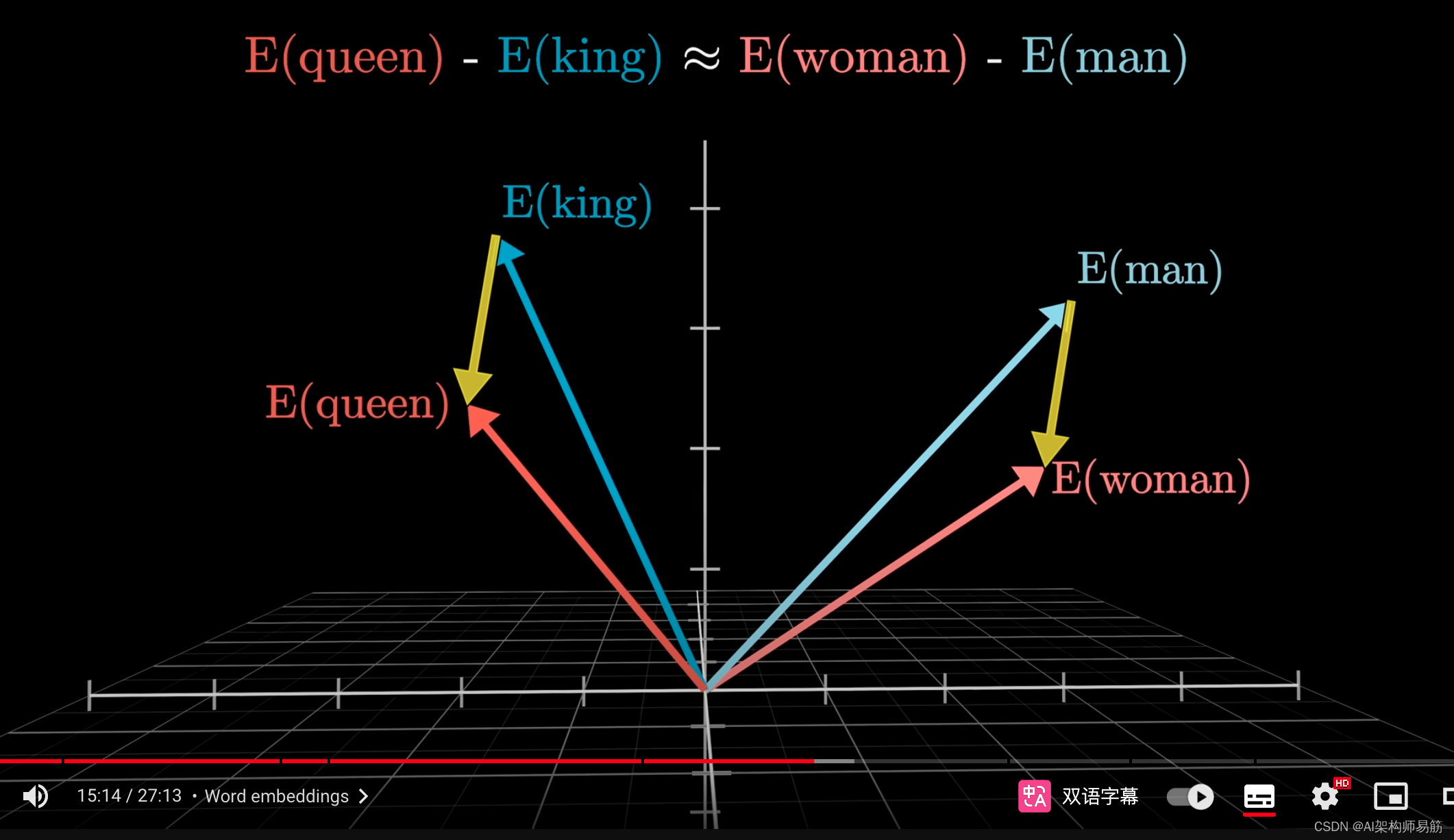
一个经典的例子是,如果你计算"woman"和"man"向量之间的差异,你会发现这个差异可以可视化为连接一个词的尖端到另一个词的尖端的空间中的一个小向量,而这个差异与"king"和"queen"之间的差异非常相似。
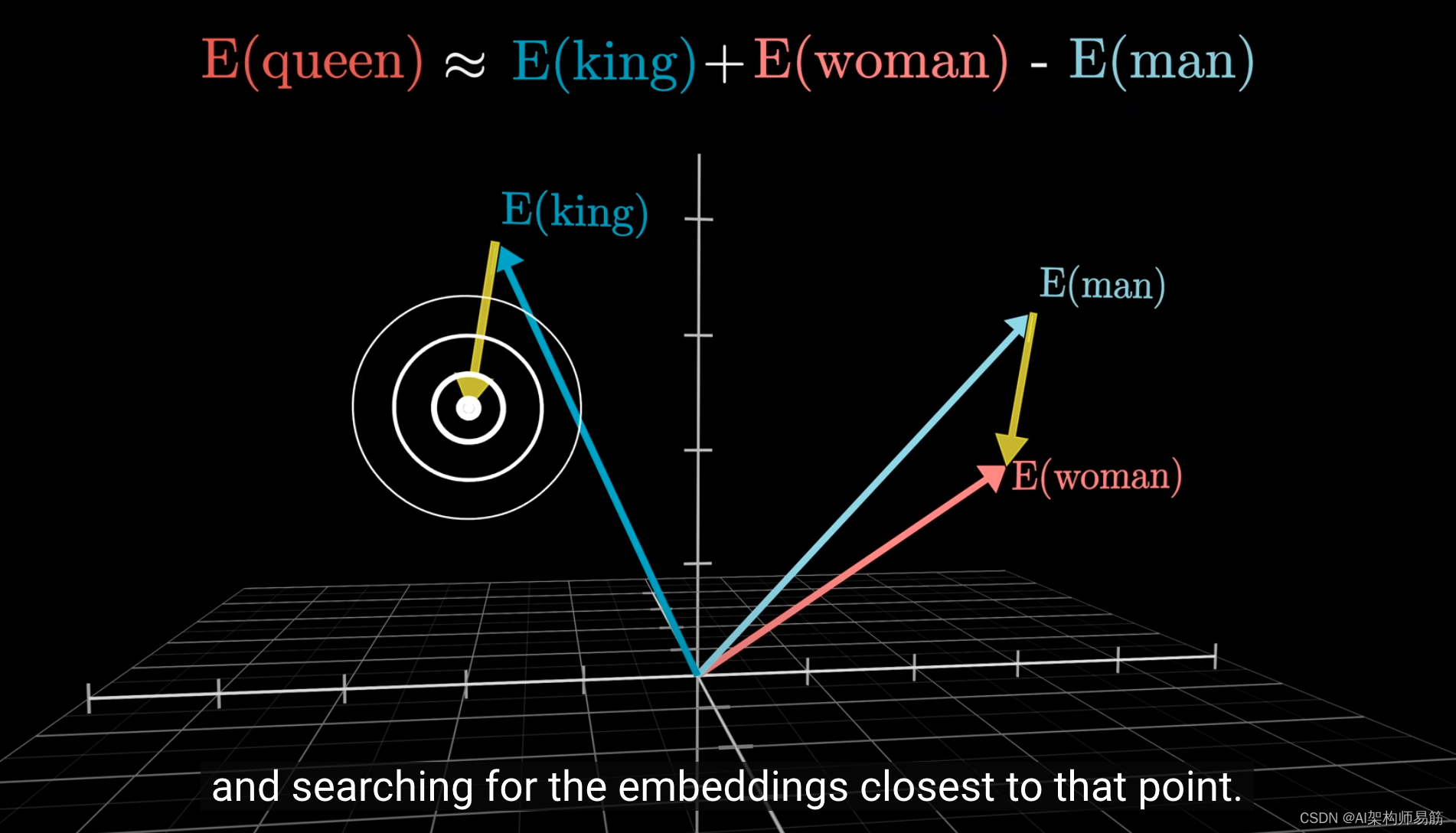
因此,假设你不知道表示"女性君主"的词,你可以通过将"woman减去man"的方向加到"king"向量上,并搜索最接近该点的词向量来找到它。
至少在理论上是这样。
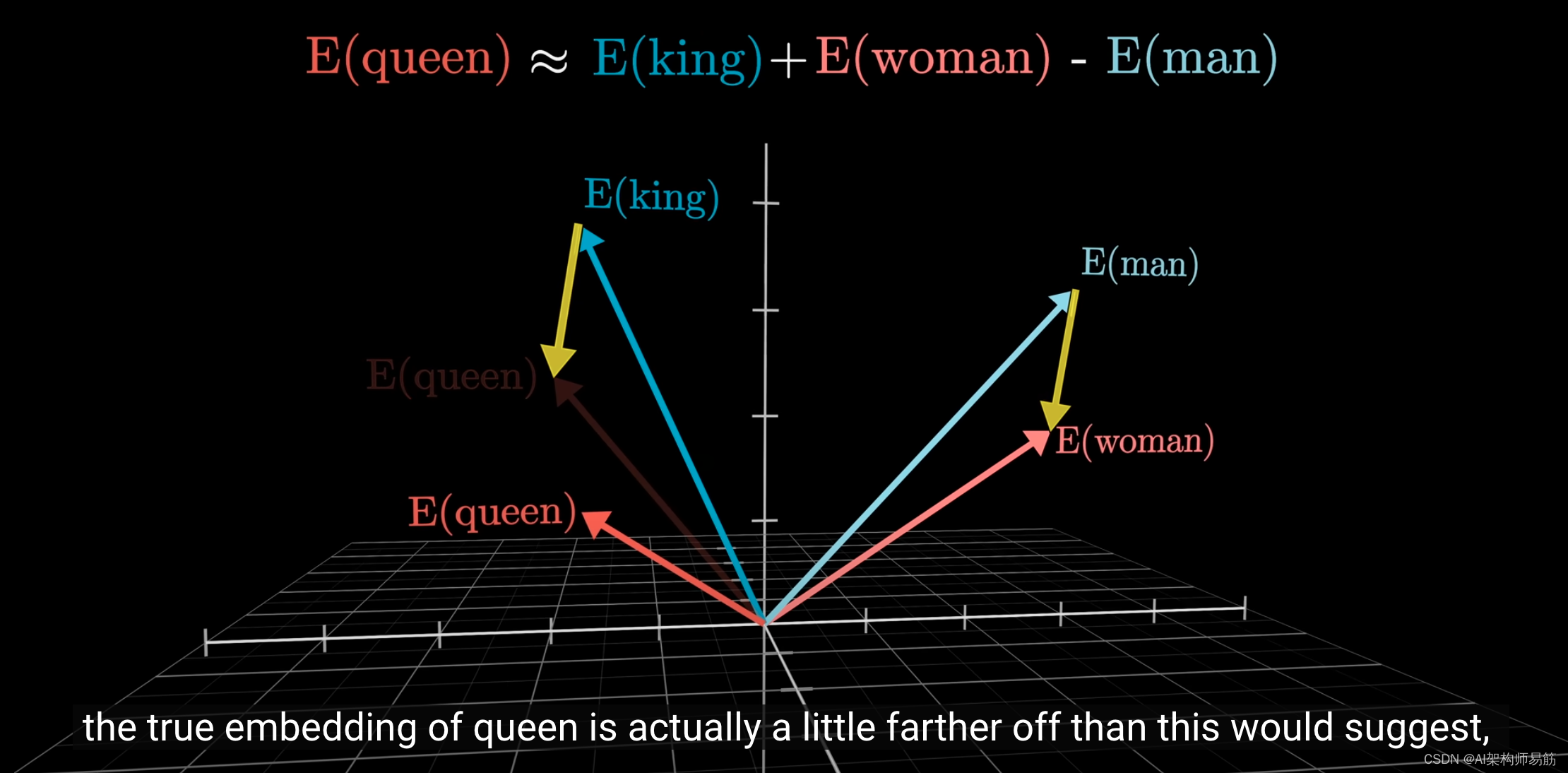
虽然这是我正在研究的模型的一个经典例子,但真正的"queen"嵌入实际上比这种方法可能设想的要远一些,
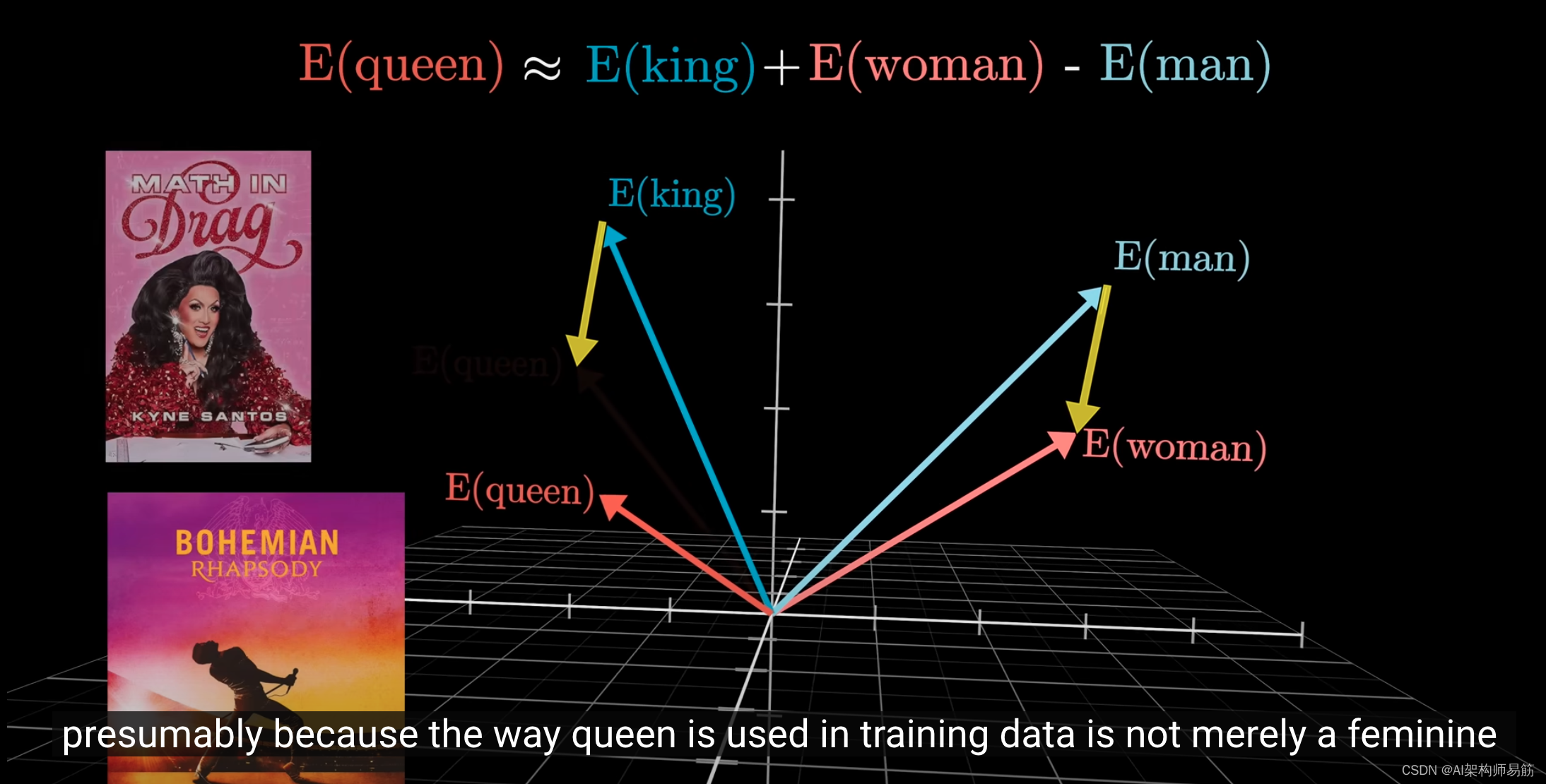
可能是因为在训练数据中,"queen"不仅仅是"king"的女性版本。
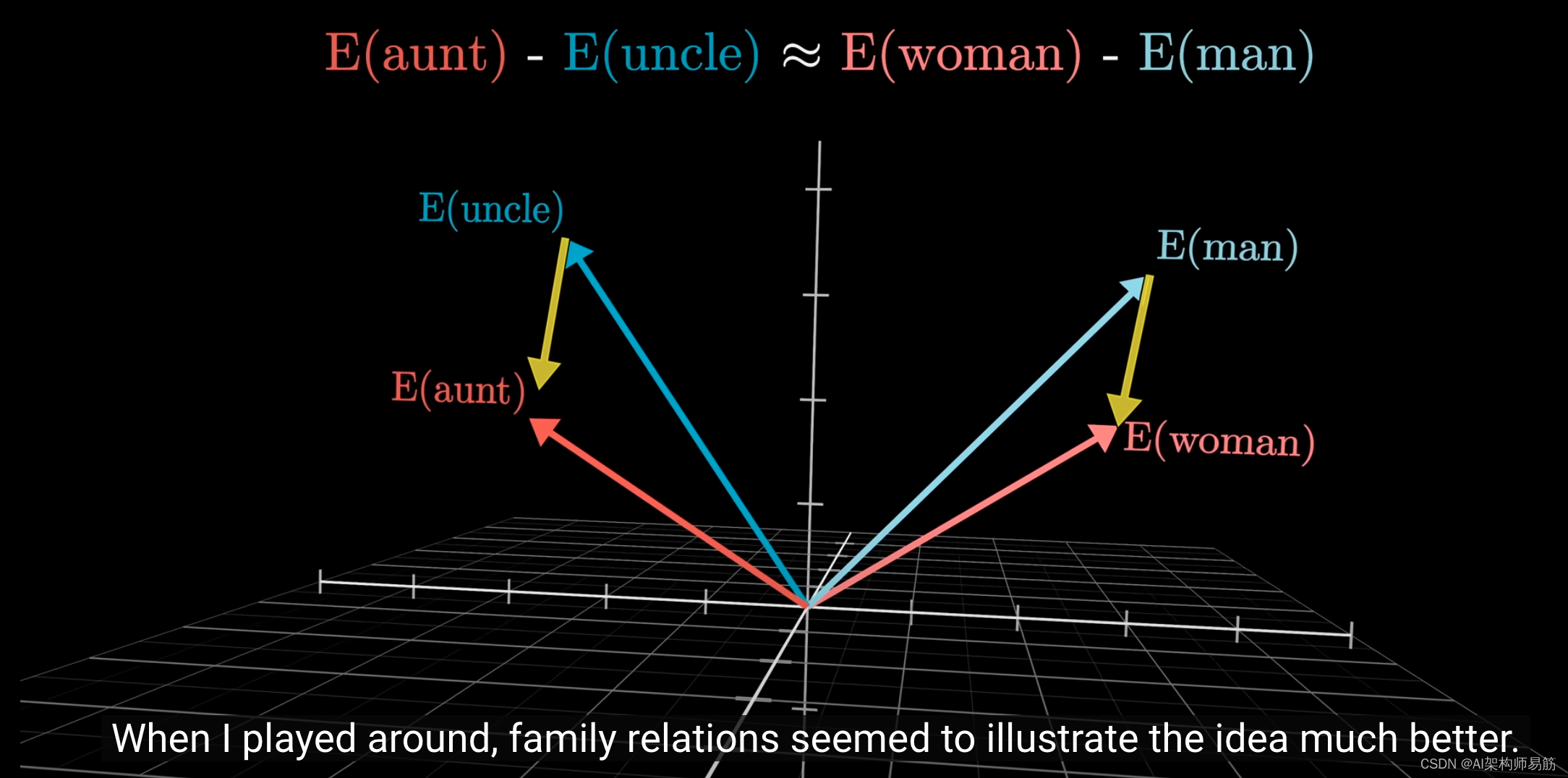
当我深入研究时,我发现似乎用家庭关系来解释这种现象更合适。
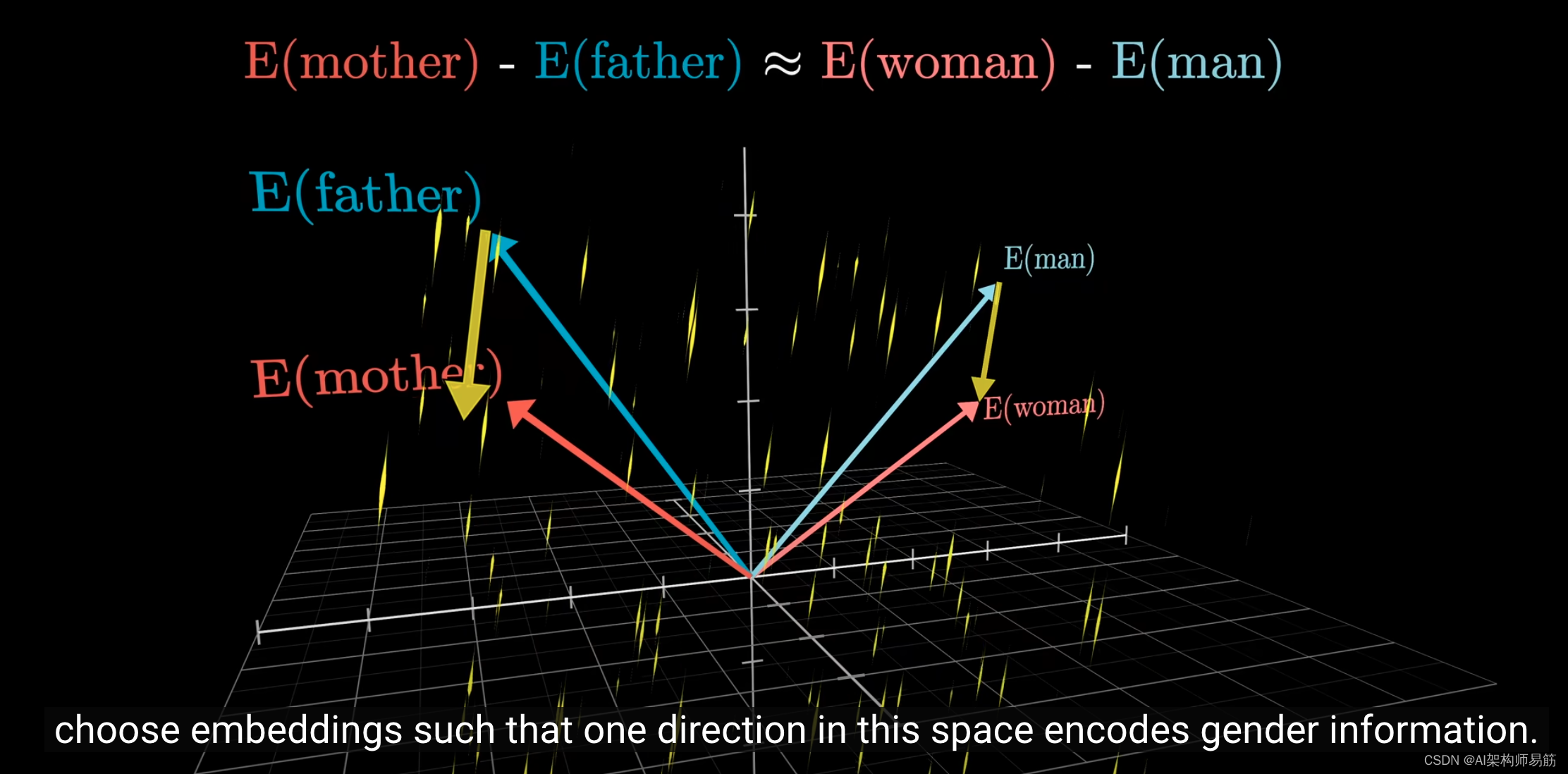
关键是,在训练过程中,模型发现采用这种嵌入方法更有利,即空间中的一个方向可以编码性别信息。
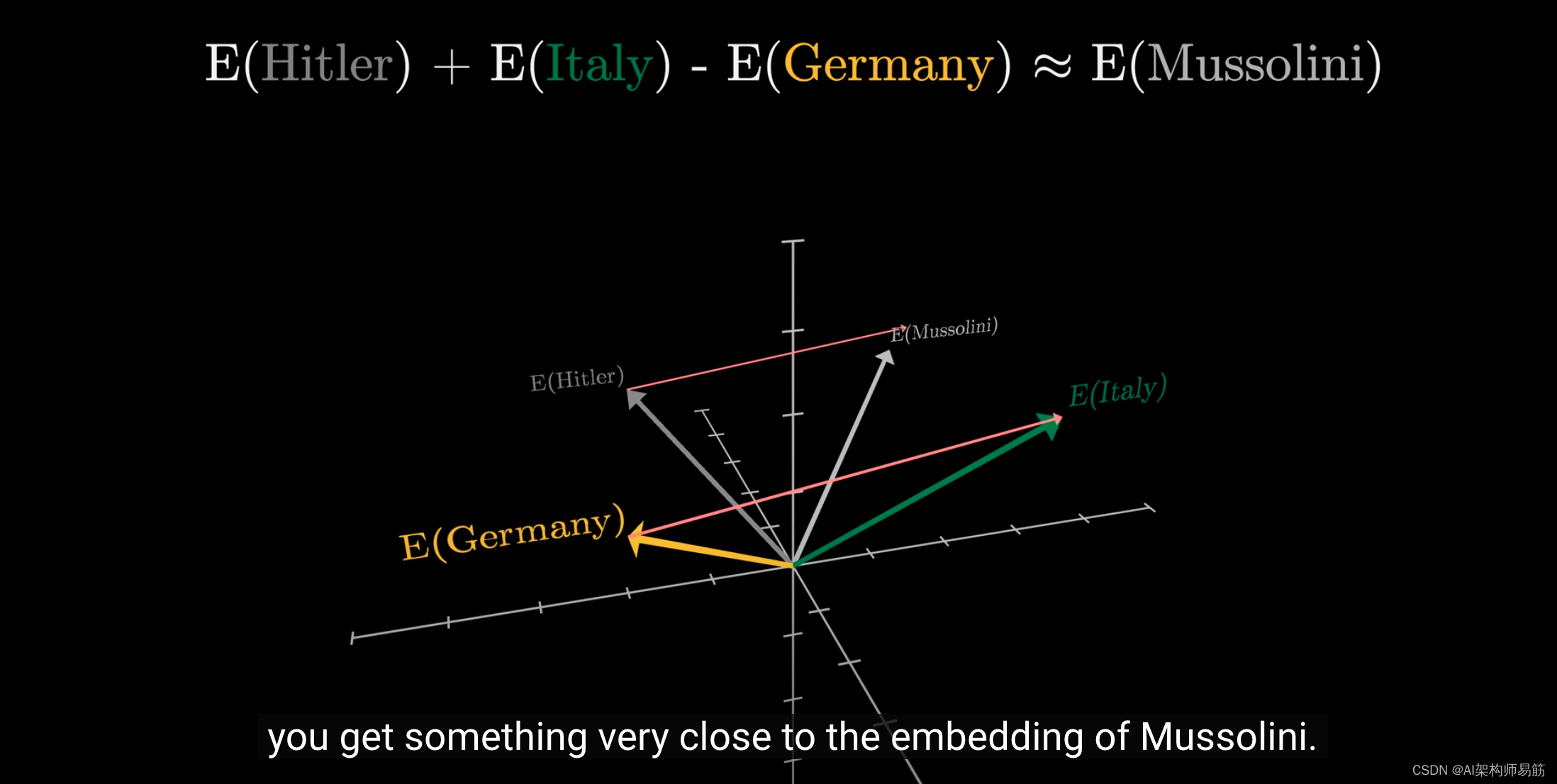
另一个例子是,如果你用意大利的向量表示减去德国的向量表示,再加上希特勒的向量表示,结果非常接近墨索里尼的向量表示。
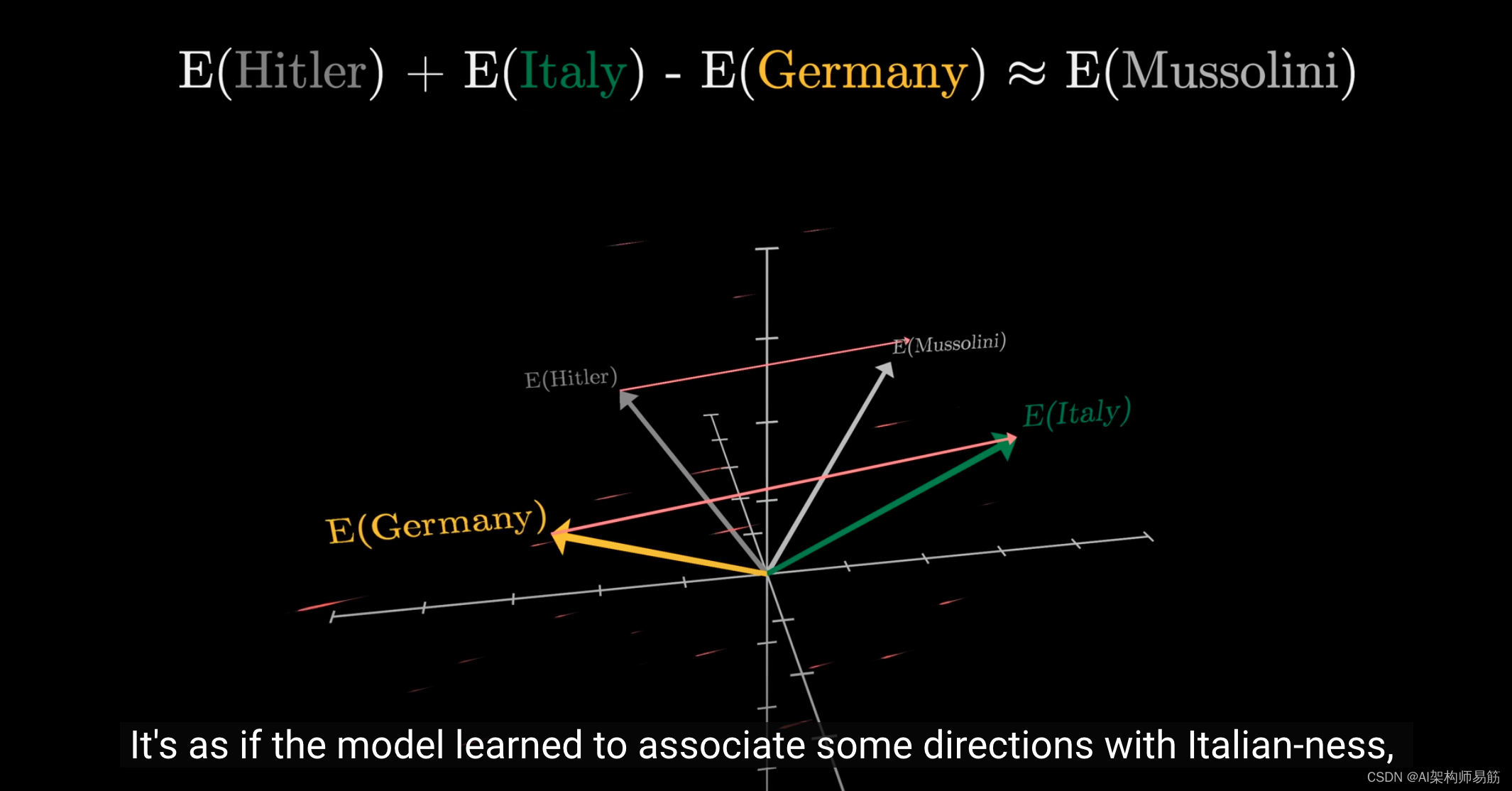
就好像模型学会了将某些方向与"意大利"特征相关联,
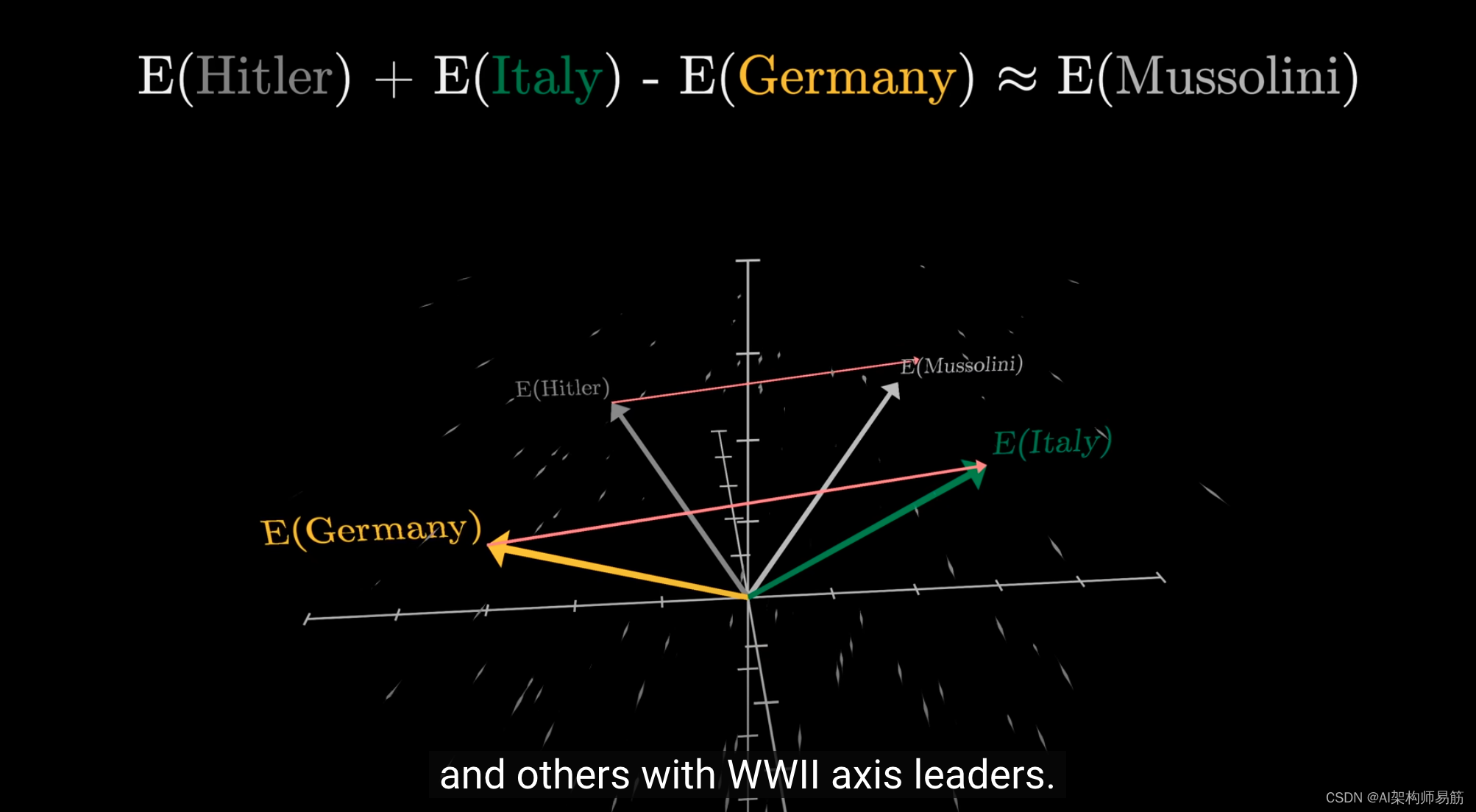
而将其他方向与二战轴心国领导人相关联。
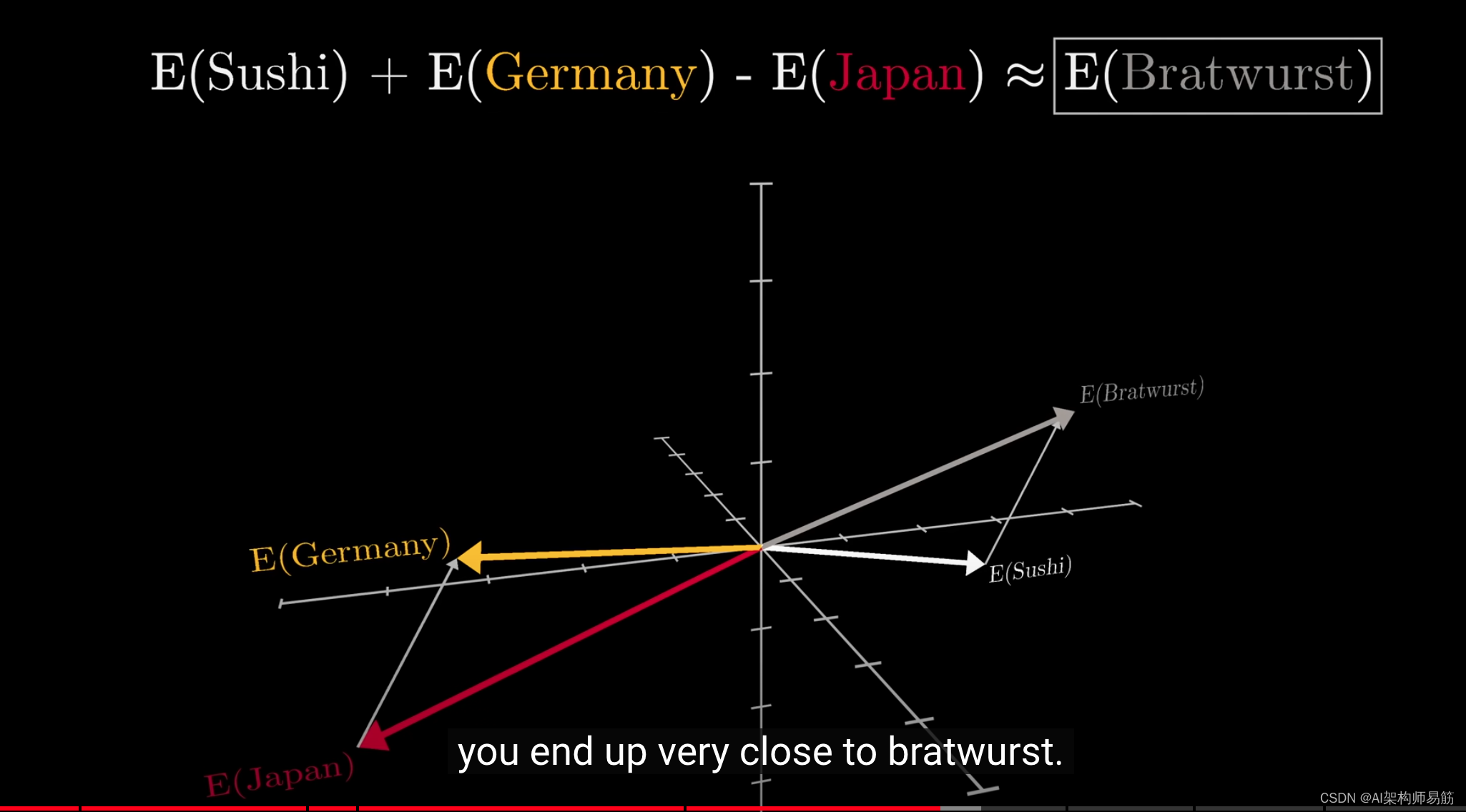
我个人最喜欢的一个例子是,在某些模型中,如果你计算"德国"和"日本"向量之间的差异,然后加上"寿司"的向量,你会得到一个非常接近"德国香肠"的结果。
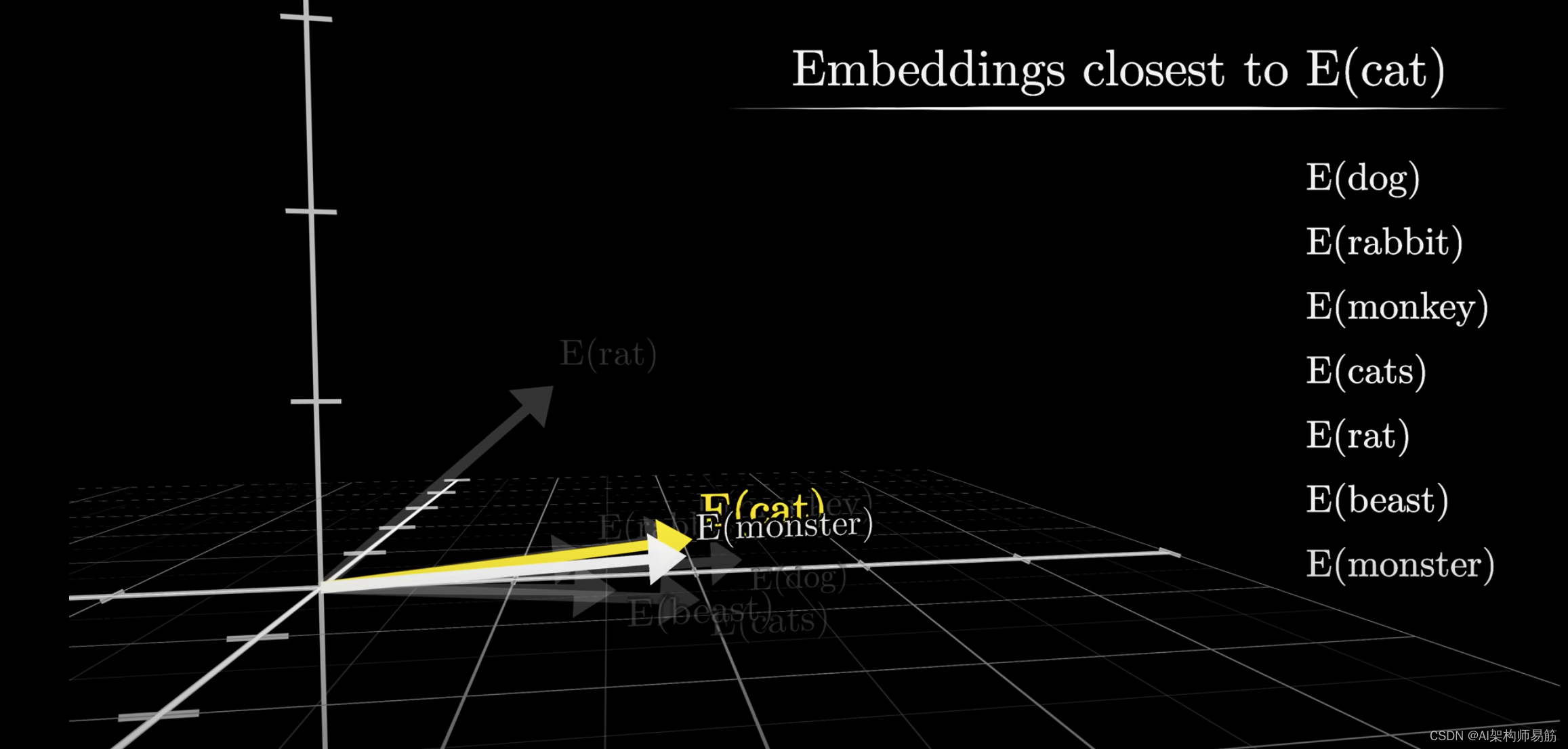
此外,在搜索最近邻的过程中,我惊喜地发现"猫"与"野兽"和"怪物"非常接近。
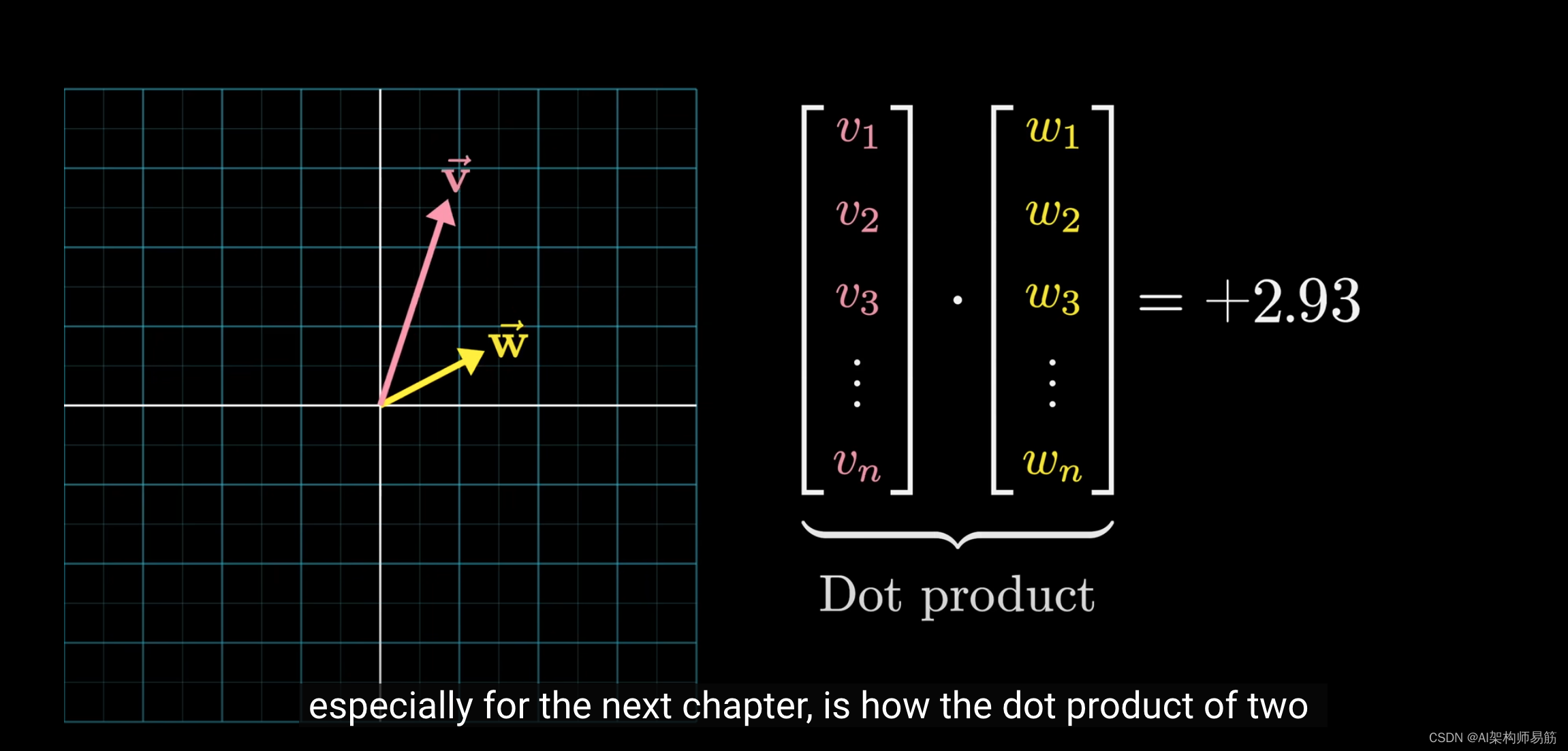
一个有用的数学概念,特别是对于接下来的章节,是两个向量的点积
可以被看作是衡量它们是否对齐的一种方式。
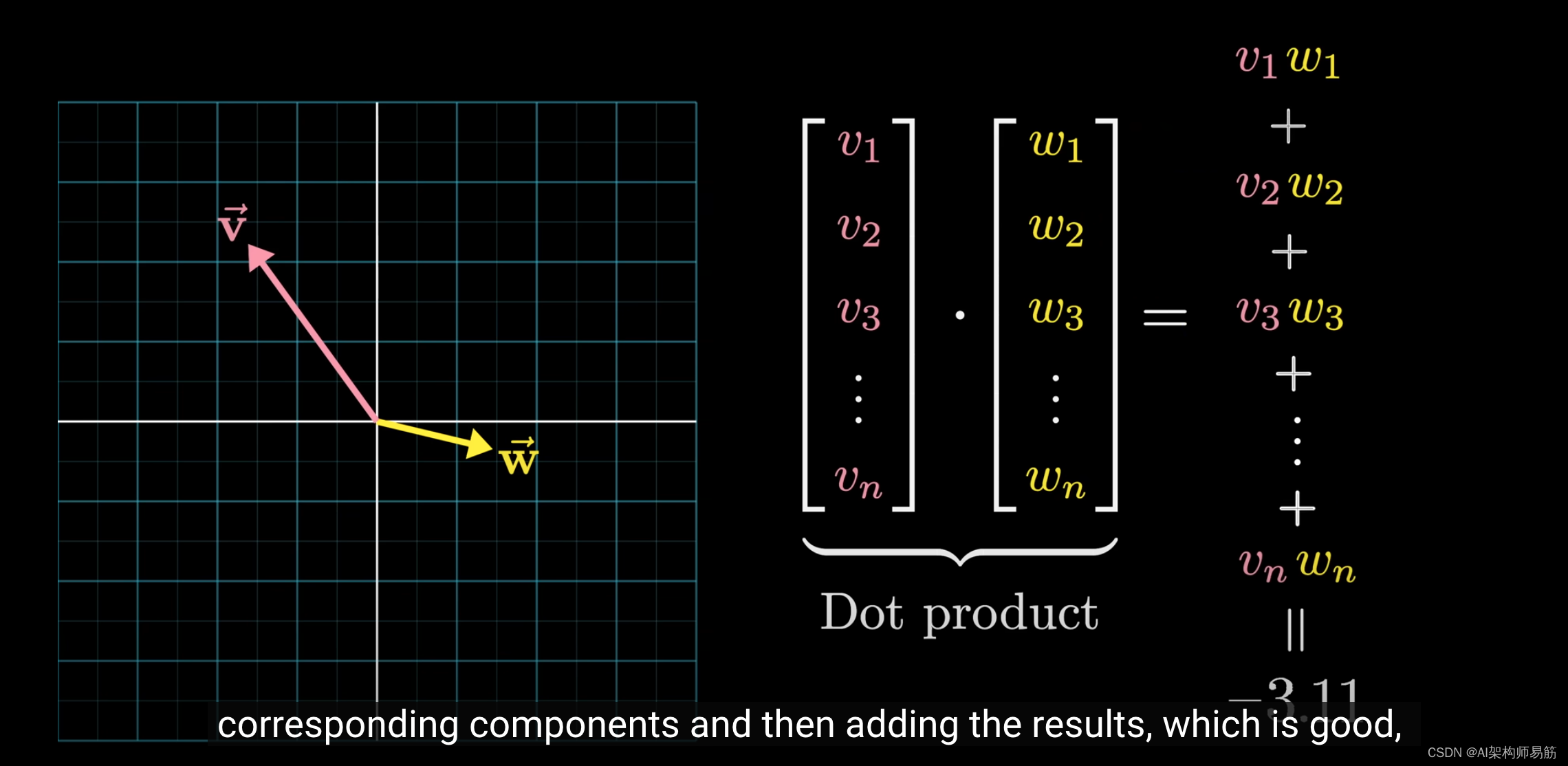
从计算的角度来看,点积涉及将对应的元素逐一相乘,然后求和,这很好,因为我们的很多计算看起来都像是权重的总和。
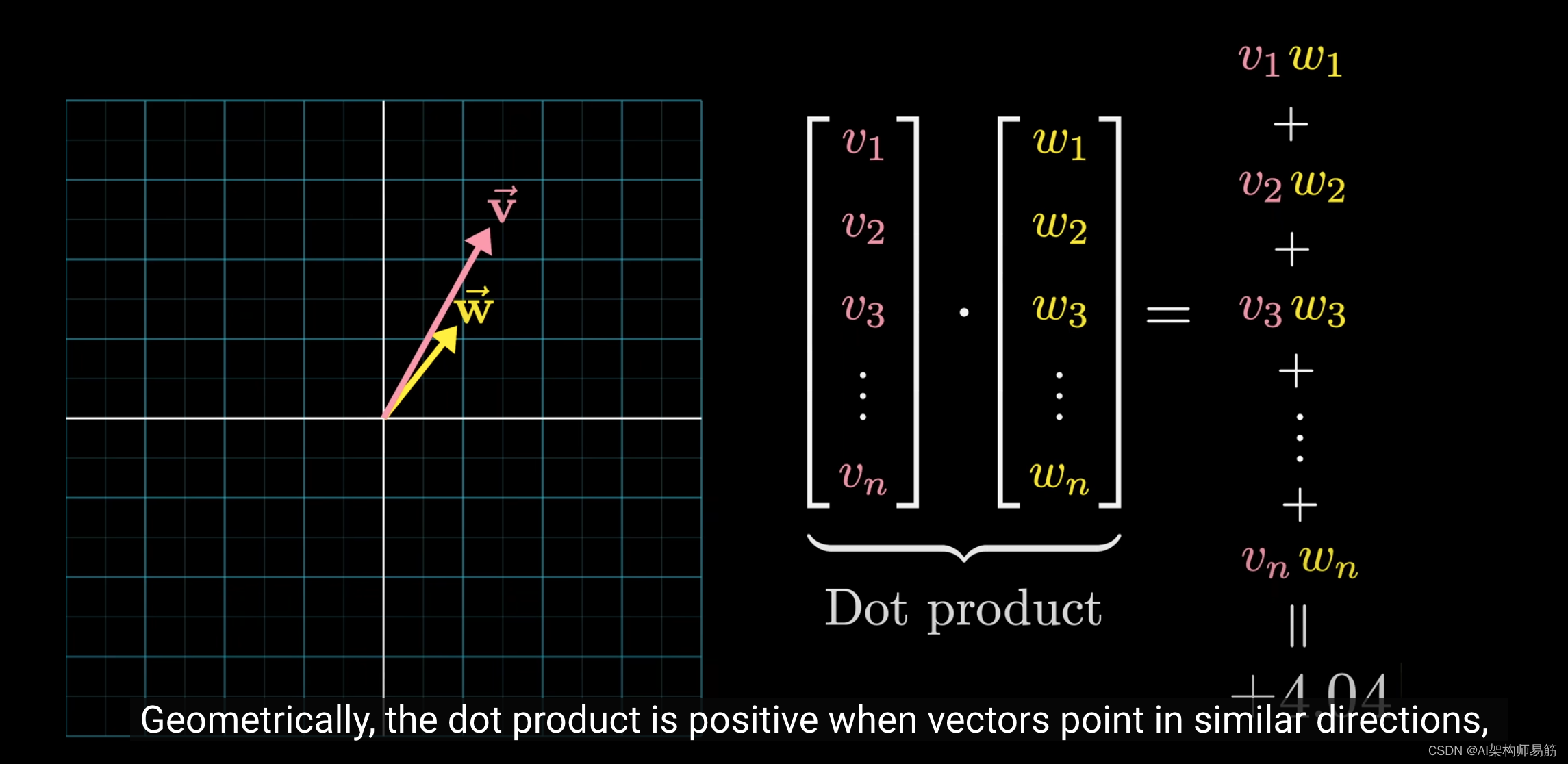
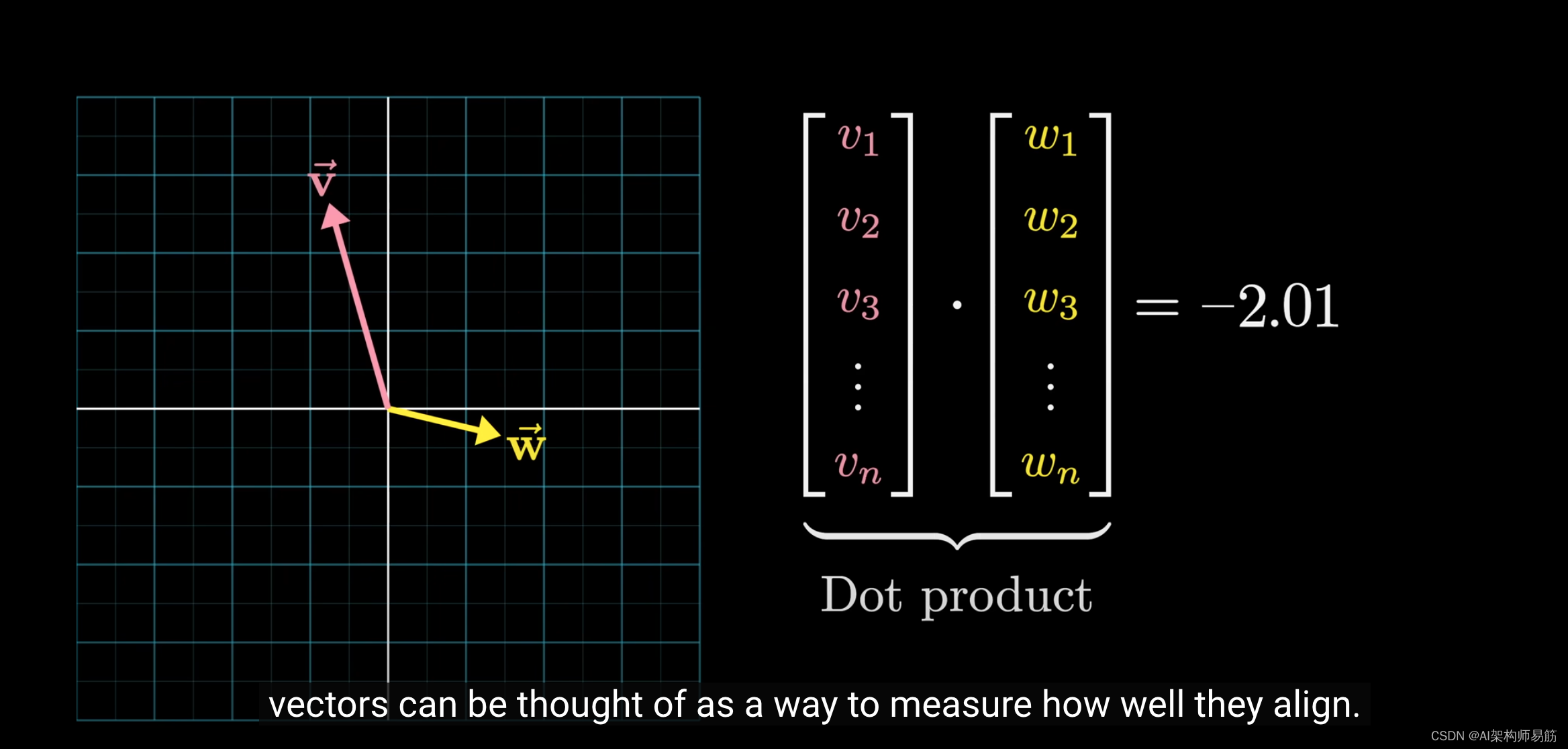
从几何的角度来看,当两个向量指向相似的方向时,点积为正;
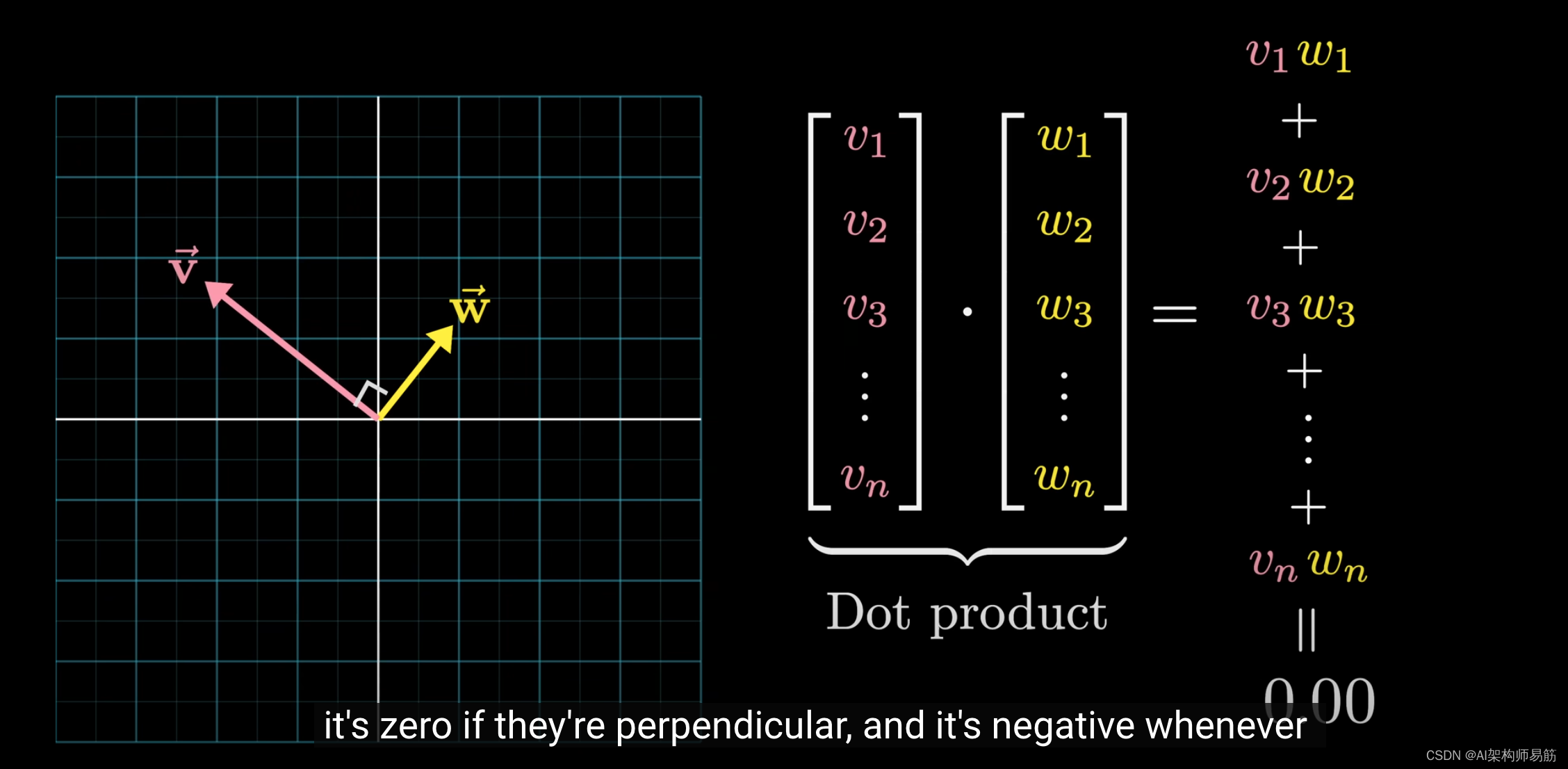
如果它们垂直,点积为零;
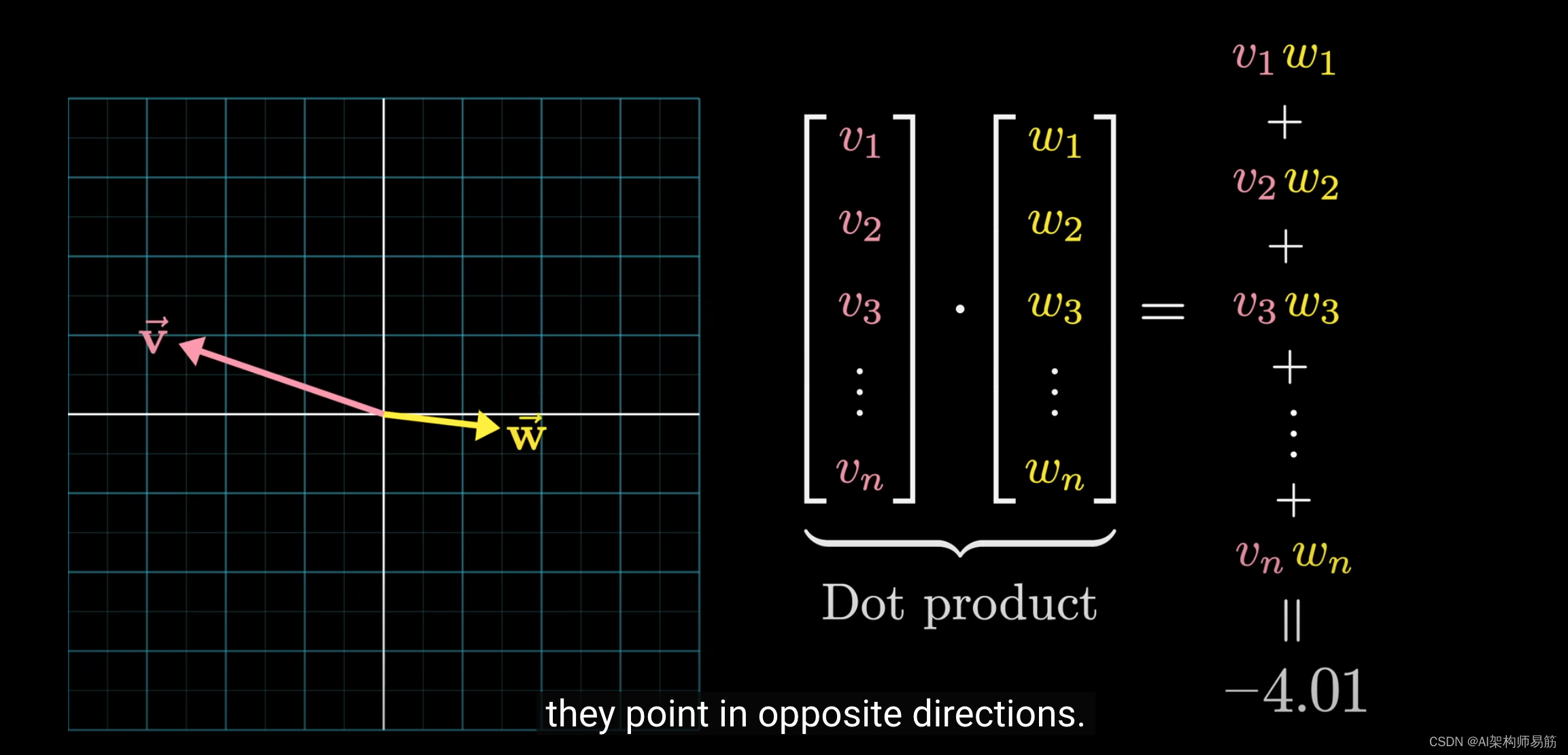
当它们指向相反的方向时,点积为负。

例如,假设你正在测试这个模型,通过从"cats"的向量表示中减去"cats"的向量表示。
有可能在这个空间中找到代表复数概念的方向。

为了测试这一点,我将计算一些特定单数名词的嵌入向量的点积,并将其与相应复数名词的点积进行比较。

如果你尝试一下,你会发现复数名词的点积通常高于单数名词,这表明它们在某个方向上更紧密地对齐。

更有趣的是,如果你将这个点积应用于像"one"、“two”、"three"等词的嵌入,你可以看到结果值逐渐增加,就像我们可以定量地衡量模型认为一个词有多"复数"一样。
参考
参考
https://youtu.be/wjZofJX0v4M?si=DujTHghH5dYM3KpZ