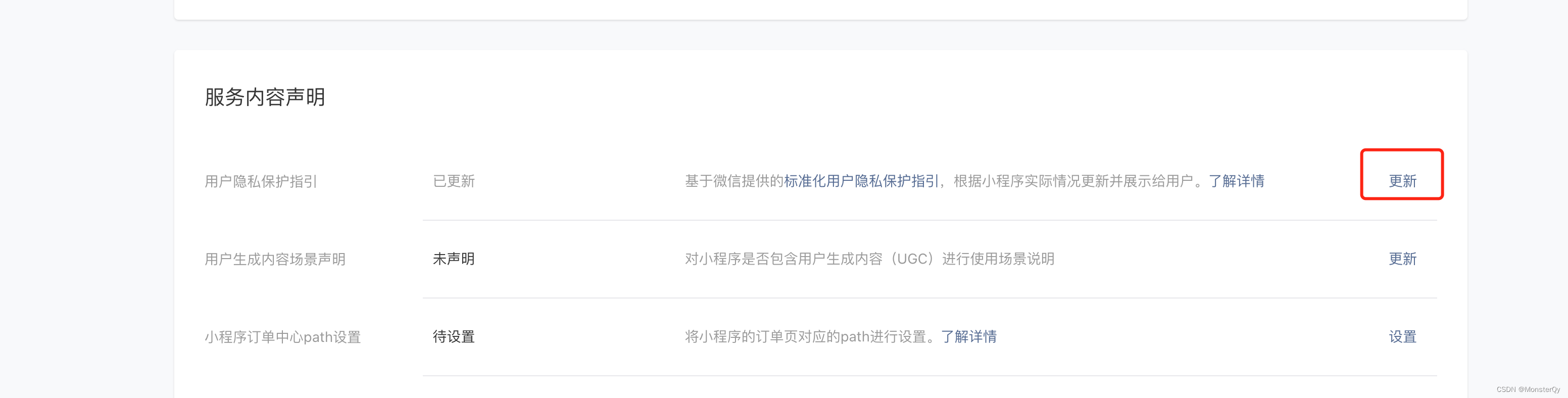
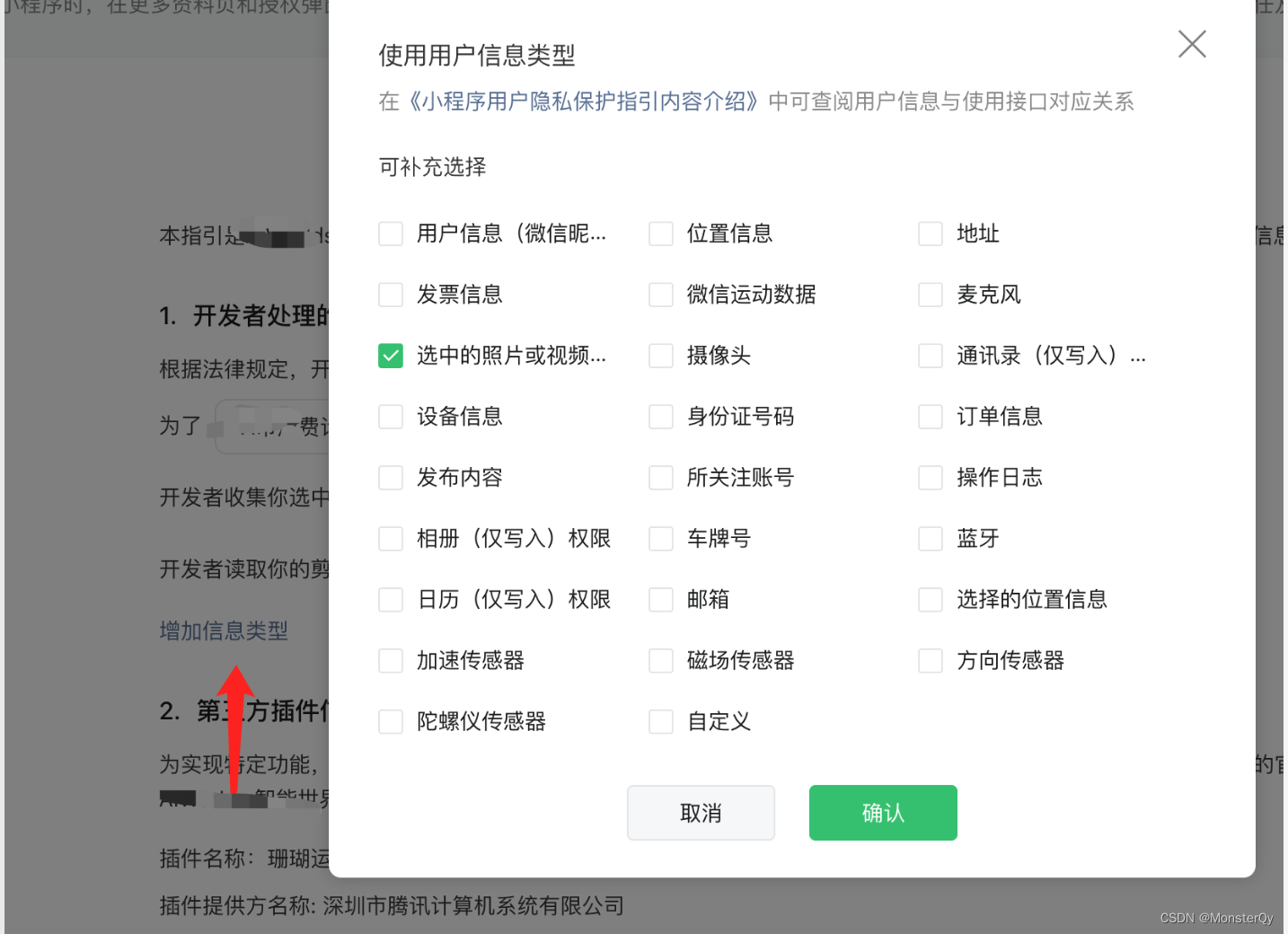
当前位置: 首页 > news >正文 前端课程网站网站建设 河南 news 2025/11/2 16:47:15 前端课程网站,网站建设 河南,做网站主播要什么条件,太原本地网站Bug场景: 微信小程序在上传图片时可以通过 uni.chooseImage()方案进行上传,这里不再赘述具体参数。一直项目都可以正常使用,突然有一天发现无法使用该方法,于是查了一下,发现是用户隐私协议问题。故记录一下解决方案。…Bug场景: 微信小程序在上传图片时可以通过 uni.chooseImage()方案进行上传,这里不再赘述具体参数。一直项目都可以正常使用,突然有一天发现无法使用该方法,于是查了一下,发现是用户隐私协议问题。故记录一下解决方案。大师 解决方案: 登陆微信公众平台:微信公众平台 设置——基本设置——下拉: 点击增加信息类型,按下图选择相应内容 并描述。 最后更新协议等待审核通过即可正常上传图片了 查看全文 http://www.yayakq.cn/news/123593/ 相关文章: 网站集群建设的意义做网站绿色和什么颜色搭配 母婴用品网站建设规划wordpress 简繁 建设执业注册中心网站电商小程序报价 mm131网站用什么软件做的电子商务网站建设训练总结 做自己的网站可以赚钱吗恢复wordpress修订版本号 做网站建设需要会哪些重庆所有做网站的公司 手机论坛网站源码wordpress二级菜单调用 哈尔滨建设网站公司哪家好wordpress首页在哪里修改 自己可以自己做公司的网站吗网站空间 数据库 郑州做网站价格电商网站开发企业 上海大规模网站建设平台郑州官网seo厂家 顺的网站建设咨询如何制作一个网站 营销型网站 易网拓godaddy 搭建网站 域名被锁定网站打不开怎么办表情包制作网页 电子商务网站建设与开发选择题凡科商城app下载 新网 网站空间网站建设可行性研究报告范文 wordpress建手机站教程东莞seo整站优化代理 品牌营销策划网站网站推广app开发 营销网站开发渠道有哪些软件项目管理论文3000字 网站做的好的创意广告图片 顺企网吉安网站建设3d做号网站 高端做网站哪家好网站上线稳定后的工作 网站建设建设多少钱wordpress 后台地址修改 网站建设7个基本流程分析PC端网站开发以及设计费用 做平台网站怎么赚钱为什么要网站建设 西安网站建设排行榜点胶喷嘴技术支持东莞网站建设 杭州知名的网站建设策划网站如何注册微信公众平台 类型 做网站推广的公司好做吗建设营销型网站模板 如何制作网站?微信小程序订单系统 做网站设计的有些什么职位dede5.7内核qq个性门户网站源码
Bug场景: 微信小程序在上传图片时可以通过 uni.chooseImage()方案进行上传,这里不再赘述具体参数。一直项目都可以正常使用,突然有一天发现无法使用该方法,于是查了一下,发现是用户隐私协议问题。故记录一下解决方案。大师 解决方案: 登陆微信公众平台:微信公众平台 设置——基本设置——下拉: 点击增加信息类型,按下图选择相应内容 并描述。 最后更新协议等待审核通过即可正常上传图片了 查看全文 http://www.yayakq.cn/news/123593/ 相关文章: 网站集群建设的意义做网站绿色和什么颜色搭配 母婴用品网站建设规划wordpress 简繁 建设执业注册中心网站电商小程序报价 mm131网站用什么软件做的电子商务网站建设训练总结 做自己的网站可以赚钱吗恢复wordpress修订版本号 做网站建设需要会哪些重庆所有做网站的公司 手机论坛网站源码wordpress二级菜单调用 哈尔滨建设网站公司哪家好wordpress首页在哪里修改 自己可以自己做公司的网站吗网站空间 数据库 郑州做网站价格电商网站开发企业 上海大规模网站建设平台郑州官网seo厂家 顺的网站建设咨询如何制作一个网站 营销型网站 易网拓godaddy 搭建网站 域名被锁定网站打不开怎么办表情包制作网页 电子商务网站建设与开发选择题凡科商城app下载 新网 网站空间网站建设可行性研究报告范文 wordpress建手机站教程东莞seo整站优化代理 品牌营销策划网站网站推广app开发 营销网站开发渠道有哪些软件项目管理论文3000字 网站做的好的创意广告图片 顺企网吉安网站建设3d做号网站 高端做网站哪家好网站上线稳定后的工作 网站建设建设多少钱wordpress 后台地址修改 网站建设7个基本流程分析PC端网站开发以及设计费用 做平台网站怎么赚钱为什么要网站建设 西安网站建设排行榜点胶喷嘴技术支持东莞网站建设 杭州知名的网站建设策划网站如何注册微信公众平台 类型 做网站推广的公司好做吗建设营销型网站模板 如何制作网站?微信小程序订单系统 做网站设计的有些什么职位dede5.7内核qq个性门户网站源码