怎么解决360导航的网站建设做招聘信息的网站有哪些内容
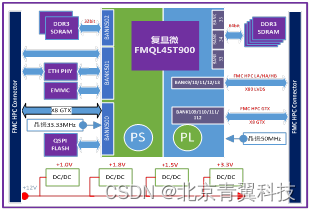
TES745D是一款基于上海复旦微电子FMQL45T900的全国产化ARM核心板。该核心板将复旦微的FMQL45T900(与XILINX的XC7Z045-2FFG900I兼容)的最小系统集成在了一个87*117mm的核心板上,可以作为一个核心模块,进行功能性扩展,能够快速的搭建起一个信号平台,方便用户进行产品开发。核心板上分布了DDR3 SDRAM、EMMC、SPI FLASH、以太网PHY芯片等。通过两个板对板连接器FMC实现PL端IO的扩展。
FMQL45T900是复旦微电子研制的全可编程融合芯片,在单芯片上集成了基于具有丰富特点的四核处理器的处理系统(Processing System,PS)和可编程逻辑(Programmable Logic,PL),基于最先进的28纳米工艺。配合相应的开发软件,可实现一体化软硬件平台,方便用户开发,缩短开发周期,节约生产成本。
技术指标
1、板载复旦微FPGA可编程融合芯片:
1) FPGA型号:复旦微FMQL45T900;
2) 片上系统(PS):四核处理器、最高主频1GHz;
3) 逻辑资源(PL):逻辑单元350K,块RAM 19.2Mb;
4) 逻辑资源(PL):GTX 16个,DSP 900个;
2、模块主要存储与接口资源:
1) PS端缓存:1组DDR3 SDRAM,32位,容量1GByte;
2) PS端其他存储资源:1片EMMC(8GByte)、1片SPI Flash(256Mbit容量);
3) PS端网络:1路1000BASE-T自适应千兆以太网;
4) PS端时钟:1个33.333MHz晶振,系统时钟
5) PL端缓存:1组DDR3 SDRAM,64位,容量2GByte;
5) PL端时钟:1个50MHz晶振,逻辑时钟;
6) 板卡支持看门狗复位;
3、 互联接口:
1)接口连接器:2个FMC连接器;
2) FMC1:8路GTX,17对LVDS,28路PS MIO;
3) FMC2:8路GTX,80对LVDS;
4、 物理与电气特征
1) 板卡尺寸:87 x 117mm
2) 板卡供电:2A max@+12V(±5%)
3) 散热方式:自然风冷散热
5、 环境特征
1) 工作温度:-40°~﹢85°C;
2) 存储温度:-55°~﹢125°C;
3) 工作湿度:5%~95%,非凝结
软件支持
1、 集成板级软件开发包(BSP):
1)支持PS端开发技术支持;
2) 支持PL端扩展应用与支持;
2、 可根据客户需求提供定制化算法与系统集成:
应用范围
l 工控信号处理;
l 智能信号处理;