长安微网站建设优秀个人网页
需求
最近遇到个小程序异步解码的需求,采用了WebAssembly,涉及大量的计算。由于小程序的双线程模型只有一个线程处理数据,因此智能寻求其它的解决方案。查看小程序的文档,发现小程序还提供一个异步线程的Worker方案,可以并行的。于是尝试采用Worker来进行异步运算,看了下文档,貌似只能有一个Worker异步进行,但是聊胜于无,能多一个线程并行计算,页面逻辑不会卡住就已经很不错了。
由于本人采用uniapp来进行小程序开发,由于引入了uniapp编译,导致整个开发过程更加复杂,本文记录了本人采用uni-best框架使用Worker过程遇到的一排深坑以及爬坑方案
小广告
uni-best不愧为2024年最佳的uni-app开发框架,uniapp+vue3+ts+unocss+uni-helper,typescript语言,体验极致的开发效率。本次项目就是在unibest生成的项目里进行uniapp开发
unibest最好用的 uniapp 开发模板![]() https://codercup.github.io/unibest-docs/
https://codercup.github.io/unibest-docs/
整合过程
下面按照官方的整合过程走一遍
创建目录
在src项目下创建workers目录,并建立index.js。这里是坑A,注意小程序Worker的引入必须显式的指定为.js,因此即使ts能够自动的编译为js,但是由于书写的原因。index文件必须为javascript而不是typeScript,但是index.js再引入的文件,是可以使用typescript格式的
引入文件
在页面采用一个按钮,点击开始进行异步的计算。按钮点击的代码如下:
在App.vue onShow里初始化
onShow(() => {const createNewWorker = () => wx.createWorker('workers/index.js', { useExperimentalWorker: true }) // 开启编码多线程let worker = createNewWorker()worker.onProcessKilled(() => {// 重新创建一个workerworker = createNewWorker()})
})
按照微信的文档,在某些情况下异步线程会被系统杀死。因此在这里采用了开启useExperimentalWorker保活机制
编写调用
下面按照微信官方的说明结合本人的项目开始编写
异步线程接收事件
下一步开始编写index.js,开启异步线程接口
worker.onMessage((obj) => {if (obj.event === 'add') {worker.postMessage({ event: 'addResult', data: obj.data.a + obj.data.b })}
})解释下为什么这样写:
因为worker的调用是采用统一的调用接口,因此需要设计自己的消息格式,本人的消息格式设计如下
export interface IWorkderMessage {event: stringparams: any
}
event承载不同的消息给Worker,这样Worker可以做不同的事情。这里的例子只使用一个简单的调用,把消息参数里的a和b在异步线程相加,然后返回给主线程相加的结果
主线程发起事件
主线程的调用,在本人的结构里是采用mitt全局消息模型的,这样在统一的入口注册后。任何单元代码的任何地方都可以随时对异步线程发起调用。
utils.on(Global.CC_WORKER_MESSAGE, (data: IWorkderMessage) => {worker.postMessage(data)})
页面发起异步调用
function doWorker() {utils.emit(Global.CC_WORKER_MESSAGE, { event: 'add', data: { a: 2, b: 3 } })
}按微信官方的说法,在worker.onMessage里打印到console,理应看到输出(实际不是)。姑且先不管运行的结果,我们先按微信官方文档说明把代码写完。
主线程接收异步线程结果
主线程同样是采用worker.onMessage来接收异步线程的返回结果。我们加入到startWorker方法里,写成这样
onShow(() => {const createNewWorker = () => wx.createWorker('workers/index.js', { useExperimentalWorker: true }) // 开启编码多线程let worker = createNewWorker()worker.onProcessKilled(() => {// 重新创建一个workerworker = createNewWorker()})worker.onMessage((obj: Record<string, any>) => {// 异步线程全局消息转发utils.emit(obj.event, obj.data)})})
这里的utils.emit是我引入mitt后的全局消息模式,这样可以把返回的消息通过全局消息模型转发到对应的页面里
说明下这里为什么obj类型用Record<string,any>而不是IWorkderMessage,因为在小程序定义的d.ts里,已经把类型定义为Record,因此只能这样写
然后在对应界面写个全局的事件接收,这里仅打印下接收结果
utils.on('addResult', (c) => {console.log(`addResult is ${c}`)})坑来了
坑B
[worker] Uncaught Error: module 'workers/index.js' is not defined, require args is 'workers/index.js'
看到这里本人起初也是一头雾水的,啥叫index.js没定义,需要index.js。经过了一圈排查,才发现。我的编译后的dist\dev\mp-weixin目录里,没有workers目录!心态炸了,这叫什么错误,其它的文件都在,为毛单对workers过不去?
时间一分一秒过去,经过数小时冷静后。突然想到一个问题,vue3默认开启了Tree Shaking来优化代码,是不因为编译优化不认识worker机制,把从workders入口开始的整个代码链给弄丢了呢?按腾讯文档说,worker代码独立运行,会自动从createWorker开始运行,实时不是TreeShaking不认这一套,没代码调用的模块全部扫出家门了呢。之前require引入代码也不认,TreeShaking也给弄丢了,估计也是一个德行。
想完说干就干,修改下workers/index.js,做个简单的默认导出
worker.onMessage((obj) => {if (obj.event === 'add') {worker.postMessage({ event: 'addResult', data: obj.data.a + obj.data.b })}
})export default 'workers'然后在App.vue导入,啥其它都不干,就打印下,这下编译器应该认为该模块是有用的吧
import workers from '@/workers'
console.log(workers)
然后开启调试,内牛满面,workers目录出现了,遗憾的是,继续出现错误了
坑C
估计很多人爬到这里,就会爬不动了。小程序上还是显示错误
app.js错误:
Error: module 'workers/index.js' is not defined, require args is './workers/index.js'
看起来错误和前面的一样,但是仔细看又不一样。前面的是worker报错,是在启动worker的时候找不到模块,这里是app.js错误,而且仔细看是./workers/index.js找不到。那这个'workers/index.js' is not defined又是哪门子毛病呢?
经过数小时排查,发现编译后的app.js有这样一句代码:
但是如果我修改为workers/index.js就直接编译报错了

在这个地方卡了数小时。各种方法试过,一气之下想既然导入不对,干脆不要导入算了。于是把编译后的app.js的c=require("./workers/index.js")直接修改为c="hahaha",然后直接导入小程序模拟器运行。竟然成功了!
也就是说,对于最终编译的app.js,如果我把坑B产生的代码在最终编译结果去掉的话,代码就可以正常运行了。TMD VUE,TMD编译器优化!!!
但是不能每次都这样每编一次手动改一次呀,还不得把人累死,于是有了下一步
自动处理导入
既然是在编译阶段处理,那么我们应该是可以通过插件解决的,例如scss等插件都是可以对最终结果进行处理。于是想自己写个插件,对于从没写过插件的我来说难度又上了一个等级,幸好有GPT帮助,在折磨一阵子GPT后,再参考下其他类似代码。于是有了这个插件:
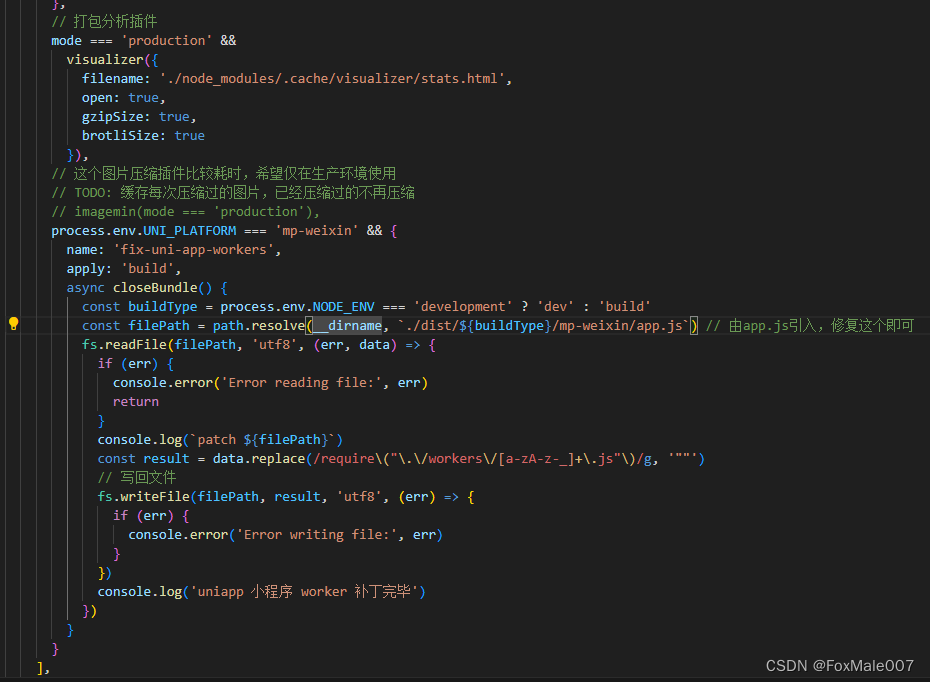
图片里vite.config.ts里的代码(顶部记得import fs from 'node:fs'):
process.env.UNI_PLATFORM === 'mp-weixin' && {name: 'fix-uni-app-workers',apply: 'build',async closeBundle() {const buildType = process.env.NODE_ENV === 'development' ? 'dev' : 'build'const filePath = path.resolve(__dirname, `./dist/${buildType}/mp-weixin/app.js`) // 由app.js引入,修复这个即可fs.readFile(filePath, 'utf8', (err, data) => {if (err) {console.error('Error reading file:', err)return}console.log(`patch ${filePath}`)const result = data.replace(/require\("\.\/workers\/[a-zA-z-_]+\.js"\)/g, '""')// 写回文件fs.writeFile(filePath, result, 'utf8', (err) => {if (err) {console.error('Error writing file:', err)}})console.log('uniapp 小程序 worker 补丁完毕')})}}解释下这个插件干了啥。
它在判断微信编译时(留着以后H5可以用编译开关写页面的Worker)开启,对编译目标目录的app.js进行处理。因此你的引用代码必须写到app.js。即
import workers from '@/workers'
console.log(workers)
这个是写在App.vue的,写到其它文件别怪我没提醒
然后对生成的文件做替换,把里面所有引入的js文件入口
=require("./workers/XXXXX.js")都替换成了="",这样都是打印空字符串,不会报错
对于workders里其它文件,也需要在app.js里通过写console.log的 方式注册,否则还是会出诡异的require args报错,这个正则把所有workers里的引入都替换成了常量字符
这样uniapp使用小程序的Workers就可以正常工作了🎉🎉🎉

按钮调用:
function doWorker() {utils.emit(Global.CC_WORKER_MESSAGE, { event: 'add', data: { a: 2, b: 3 } })
}日志打印:
![]()
功能已经正常!!!