厦门建网站品牌移动端网站怎么做
开源License介绍
通俗来讲,开源许可证就是一种允许软件使用者在一定条件内按照需要自由使用和修改软件及其源代码的的法律条款。借此条款,软件作者可以将这些权利许可给使用者,并告知使用限制。这些许可条款可以由个人、商业公司或非赢利组织起草。
概述
从整体上看,开源许可证大致分为宽松式(Permissive)许可证和著作权(copyleft)许可证两类。两者的差别主要在于宽松度以及使用开源软件组件相关的要求和许可权限的多少。
比如说Copyleft类型的license,拥有该类型license的开源组件可以免费使用,但是一旦代码中使用了这类组件,在将该代码分发给其他人时,就必须开放你的源代码。GPL许可证族就是这类许可证的代表。
与之相对的是宽松式许可证,它保证了使用、修改和重新分发的自由,几乎没有任何限制条件,如MIT。
除去这两大类别的差异,每一类下许可证和许可证族也会因为一些附加参数而产生具体差异。每个开源许可证都有自己独特的限制、条件和权限。
Copyleft许可证
非赢利性许可证中(名称取与copyright相反之意),比较有代表性的是Eclipse开源许可证(EPL)和GNU GPL开源许可证。GNU GPL许可证族有强制性的Copyleft条款,即无论用户代码中包含多少GPL代码,在分发其软件时都要公开完整源代码。
而EPL则是一种较弱的Copyleft许可证,它不要求用户共享其整个软件项目,而只需要在以源代码形式分发时开源任何包含EPL组件的源码。
随着开源的使用愈发普遍,拥有Copyleft许可证的开源组件在商业组织中的流行度也越来越低。
Permissive许可证
宽松式许可证中,比较有名的有MIT,BSD和Apache 2.0。其中,MIT算是最宽松的许可证,几乎没有任何使用限制。
而BSD也是一种高度宽松的许可证,允许用户以任何形式修改和重新分发使用了BSD许可证的软件。
早期版本的Apache许可证与BSD许可证类似,但Apache 2.0增加了一些关键的差异,使得这两种许可证区别开来。
主流license
在开源许可证中,最常被授予权限的行为涉及商业使用、分发、修改和私人使用。
注意,如果软件只在个人、团队、甚至是公司内部使用,这么这些软件源码应当适用于私人使用许可,不属于分发的情况。
主流的开源license按宽松度从高到低介绍如下:
| 名称 | 描述 | 限制 |
|---|---|---|
| MIT | MIT是麻省理工学院的简写,也出自于此,又称为X License或X11 License。用户差不多可以随心所欲地使用遵循该许可证的软件 | 几乎没有任何限制,只要不修改原许可协议即可 |
| BSD | 由加州大学伯克利分校发布。该许可一共有5个变种,分别是BSD 4-Clause “Original” or “Old” License、BSD 3-Clause “New” or “Revised” License、BSD 3-Clause Clear License、BSD 2-Clause “Simplified” License和BSD Zero Clause License。用户可以使用、修改和重新发布遵循该许可的软件,并可以将该软件作为商业软件发布和销售 | 不能修改原BSD许可协议; 如果再发布的只是二进制类库/软件,需要在文档和版权声明中包含原来代码中的BSD协议;不允许以原始开源软件的名称、作者名或者机构名来进行市场推广 |
| Apache | 该许可和BSD类似,同样适用于商业软件,鼓励代码共享和尊重原作者的著作权。包括Apache License 1.0, Apache License 1.1 和Apache License 2.0版本 | 如果修改了源代码,需要在文档中进行声明;不能修改原许可协议和其他声明;如果再发布的软件中有声明文件,则需在此文件中标注Apache许可协议及其他 |
| MPL | 该许可为Mozilla Public License推出,允许复制,分发和修改源代码。与GPL不同的是,MPL不具有传染性 | 如果对源代码进行修改,则修改后的代码仍然要使用MPL协议,且代码版权归原作者所有 |
| LGPL | GNU Lesser General Public License的缩写。与GPL类似,但许可条款更为宽松,分为LGPLv1, LGPLv2和LGPLv3。LGPL允许在非开源软件中使用或链接LGPL许可证的代码库,而不要求整个程序必须遵循LGPL许可。 | 如果对使用了LGPL的源代码进行修改,则修改后的代码必须使用LGPL协议;适合作为第三方类库使用 |
| GPL | GPL协议又分为GPLv1,GPLv2,GPLv3三个版本。GPL协议来源于自由软件联盟GNU,侧重于代码和衍生代码的开源与免费使用。GPL是传染性协议,只要软件中包含了遵循GPL协议的产品或代码,该软件就必须也遵循GPL许可 | 软件中包含遵循GPL的代码,则该软件必须也使用GPL协议,在分发时也需要开源 |
总结一下,MIT是最自由的,几乎没有任何限制,甚至可以以原作者名义来进行商业推广。
BSD和Apache许可也很自由,可以修改源码之后闭源。但不允许用原作者名义进行商业推广,保护原作者版权。
GPL则是最严格的许可,具有强烈的传染性,任何软件只要使用了拥有GPL许可的代码,则软件本身也需要使用GPL许可。
License检测
在Maven管理的项目中,一般使用license-maven-plugin插件来对第三方库的License进行检测。
该插件在maven default生命周期的主要目标描述如下:
- license:add-third-party:针对单个项目生成一个包含所有第三方依赖包的license的文件。
- license: aggregate-add-third-party: 对多模块项目生成一个包含所有第三方依赖包的license的文件。
- license: download-license: 下载每个依赖关联的license文件
- license: aggregate-download-licenses: 下载多模块项目每个依赖关联的license文件
- license: license-list: 列出所有的liencese文件
除此之外,还有一些其他如check-file-header, update-file-header等目标,具体可见参考文档[2]。
该插件在maven的site生命周期的report目标如下:
- license: third-party-report: 生成项目的第三方包报告
- license: aggregate-third-party-report: 生成聚合的第三方包报告,其中包括所有子模块的依赖
目标
如果某些依赖没有license声明,你可以通过自定义方式生成license元数据,这就是所谓的missing文件。
该文件用于将maven坐标规范映射到许可证描述,如下所示:
# <groupId>--<artifactId>--<version> = <license name>
org.codehaus.mojo.license.test--test-add-third-party-global-db-misc-dep--1=The Apache Software License, Version 2.0
add-third-party
该目标用于生成第三方license文件。
本目标默认绑定到maven的default生命周期的generate-resources阶段(在compile之前)。
该目标有两个必要参数以及其他可选参数。
outputDirectory
必要参数,生成license文件的输出路径,默认值为${project.build.directory}/generated-sources/license,用户属性(命令行使用)为license.outputDirectory。
thirdPartyFilename
必要参数,生成license文件的文件名,默认值为THIRD-PARTY.txt,用户属性为license.thirdPartyFilename。
includedLicenses
可选参数,指定包含在内的licenses。
如果在指定了该参数和failOnBlacklist情况下,有license不在白名单内,则本次构建会失败。
从1.4版本之后,有三种方式指定此参数,如
<includedLicenses>licenseA|licenseB</includedLicenses>
还可以在includedLicenses配置下增加多个includedLicense单项配置。
自1.15版本之后,可以通过一个包含license白名单的url指定:<includedLicenses>http://my.license.host.com/my-whitelist</includedLicenses>。
file://开头的地址也是url,因此白名单url可以指定本地文件。
excludedLicenses
可选参数,黑名单license,可与failOnBlacklist配合使用。配置方式与白名单license参数一样。
licenseMergesUrl
合并之后的licenses文件url。
每一个license都有不同的写法,比如ASF 2.0或Apache v2,同一个license的不同写法都配置到同一行,用|来分隔,其中第一个写法为最终版本,并最终生成到thirdPartyFilename文件中。
missingFile
对于没有license信息的第三方依赖,通过此文件中的设置将license信息添加到最终生成的license文件中,格式由fileTemplate指定。
fileTemplate
生成最终license文件的模板。该模板文件使用了freemarker。既可以指定单个文件,也可以指定单个资源。
默认值为/org/codehaus/mojo/license/third-party-file.ftl。
excludedGroups
一个正则表达式(非通配符模式)。所有groupId与该表达式匹配的组件将被排除在license检测之外。
正则表达式可以是部分匹配的,如^org\.。默认情况下,被排除的组件的间接依赖不会被排除。如果想将其间接依赖也排除掉,可参考excludeTransitiveDependencies参数。
includedArtifacts
一个正则表达式(非通配符模式)。只有artifactId与该表达式匹配的组件才在license检测范围之内。
默认情况下,对于匹配的组件,其间接依赖也包含在检测范围以内。如果想禁用此机制,可以参考includeTransitiveDependencies 参数。
failIfWarning
如果检测到某个依赖没有license,则本次构建失败。默认值为false。
从1.14版本之后该参数废弃,建议使用failOnMissing或failOnBlacklist。
failOnBlacklist
当某个组件的license不在白名单或者在黑名单中,本次构建失败。
failOnMissing
当某个组件的license缺失时,本次构建失败。
示例
在Springboot模版生成的代码中添加上license检测插件,配置示例如下:
<plugin><groupId>org.codehaus.mojo</groupId><artifactId>license-maven-plugin</artifactId><executions><execution><id>add-third-party</id><goals><goal>add-third-party</goal></goals><phase>process-resources</phase></execution></executions><configuration><includedLicenses>file:${project.basedir}/build/license/compliance-license.txt</includedLicenses><licenseMergesUrl>file:${project.basedir}/build/license/merge-license.txt</licenseMergesUrl><missingFile>${project.basedir}/build/license/third-party-missing.properties</missingFile><useMissingFile>true</useMissingFile><fileTemplate>${project.basedir}/build/license/license-as-csv.ftl</fileTemplate><outputDirectory>${project.basedir}/target/generated-sources/license</outputDirectory><thirdPartyFilename>license_${project.artifactId}.csv</thirdPartyFilename><failOnBlacklist>true</failOnBlacklist><failOnMissing>true</failOnMissing></configuration>
</plugin>
并添加两个第三方依赖:
<dependency><groupId>commons-logging</groupId><artifactId>commons-logging</artifactId><version>1.1.1</version>
</dependency><dependency><groupId>commons-primitives</groupId><artifactId>commons-primitives</artifactId><version>1.0</version>
</dependency>
在根目录下创建对应的文件目录和文件,每个文件均为空。由于add-third-party目标绑定在process-resources阶段,因此只要执行mvn clean compile命令即可自动执行该插件目标。控制台输出如下:
[INFO] Missing file /Users/howe/workSpace/PremissDemo/build/license/third-party-missing.properties is up-to-date.
[WARNING] There is 1 dependency with no license :
[WARNING] - commons-primitives--commons-primitives--1.0
[INFO] Writing third-party file to /Users/howe/workSpace/PremissDemo/target/generated-sources/license/license_PremissDemo.csv
[INFO] Regenerate missing license file /Users/howe/workSpace/PremissDemo/build/license/third-party-missing.properties
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
由于commons-primitives库缺少license,而插件配置了failOnMissing参数,因此本次构建失败。
查看missing文件如下:
# Generated by org.codehaus.mojo.license.AddThirdPartyMojo
#-------------------------------------------------------------------------------
# Already used licenses in project :
# - Apache License 2.0
# - Apache License, Version 2.0
# - BSD License 3
# - BSD-3-Clause
# - EDL 1.0
# - EPL 2.0
# - Eclipse Distribution License - v 1.0
# - Eclipse Public License - v 1.0
# - Eclipse Public License v2.0
# - GNU Lesser General Public License
# - GPL2 w/ CPE
# - MIT License
# - The Apache License, Version 2.0
# - The Apache Software License, Version 2.0
# - The MIT License
#-------------------------------------------------------------------------------
# Please fill the missing licenses for dependencies :
#
#
#Wed Nov 29 14:22:15 CST 2023
commons-primitives--commons-primitives--1.0=设置missing文件
指定该组件的license如下:
commons-primitives--commons-primitives--1.0=Apache License 2.0
再次执行mvn clean compile,构建成功。本来应该将生成的license信息写入目标文件,但由于模版文件为空,因此实际生成的目标文件也为空。
设置模板文件
下面使用模板[3]如下:
<#-- To render the third-party file.URL: https://gist.github.com/matthesrieke/8819894Available context :- dependencyMap a collection of Map.Entry withkey are dependencies (as a MavenProject) (from the maven project)values are licenses of each dependency (array of string)- licenseMap a collection of Map.Entry withkey are licenses of each dependency (array of string)values are all dependencies using this license
-->
<#function licenseFormat licenses><#assign result><#list licenses as license>[${license}]<#if (license_has_next)> - </#if></#list></#assign><#assign result = "\"" + result + "\","/><#return result>
</#function>
<#function artifactFormat p><#if p.name?index_of('Unnamed') > -1><#return "\"" + p.artifactId + "\",\"" + p.groupId + ":" + p.artifactId + ":" + p.version + "\",\"" + (p.url!"no url defined") + "\""><#else><#return "\"" + p.name + "\",\"" + p.groupId + ":" + p.artifactId + ":" + p.version + "\",\"" + (p.url!"no url defined") + "\""></#if>
</#function>
<#if dependencyMap?size == 0>
The project has no dependencies.
<#else>
"License","Name","Artifact","URL"<#list dependencyMap as e><#assign project = e.getKey()/><#assign licenses = e.getValue()/>
${licenseFormat(licenses)}${artifactFormat(project)}</#list>
</#if>
再次执行maven命令,在target/generated-sources/license目录下就可以看到已经生成license信息了:
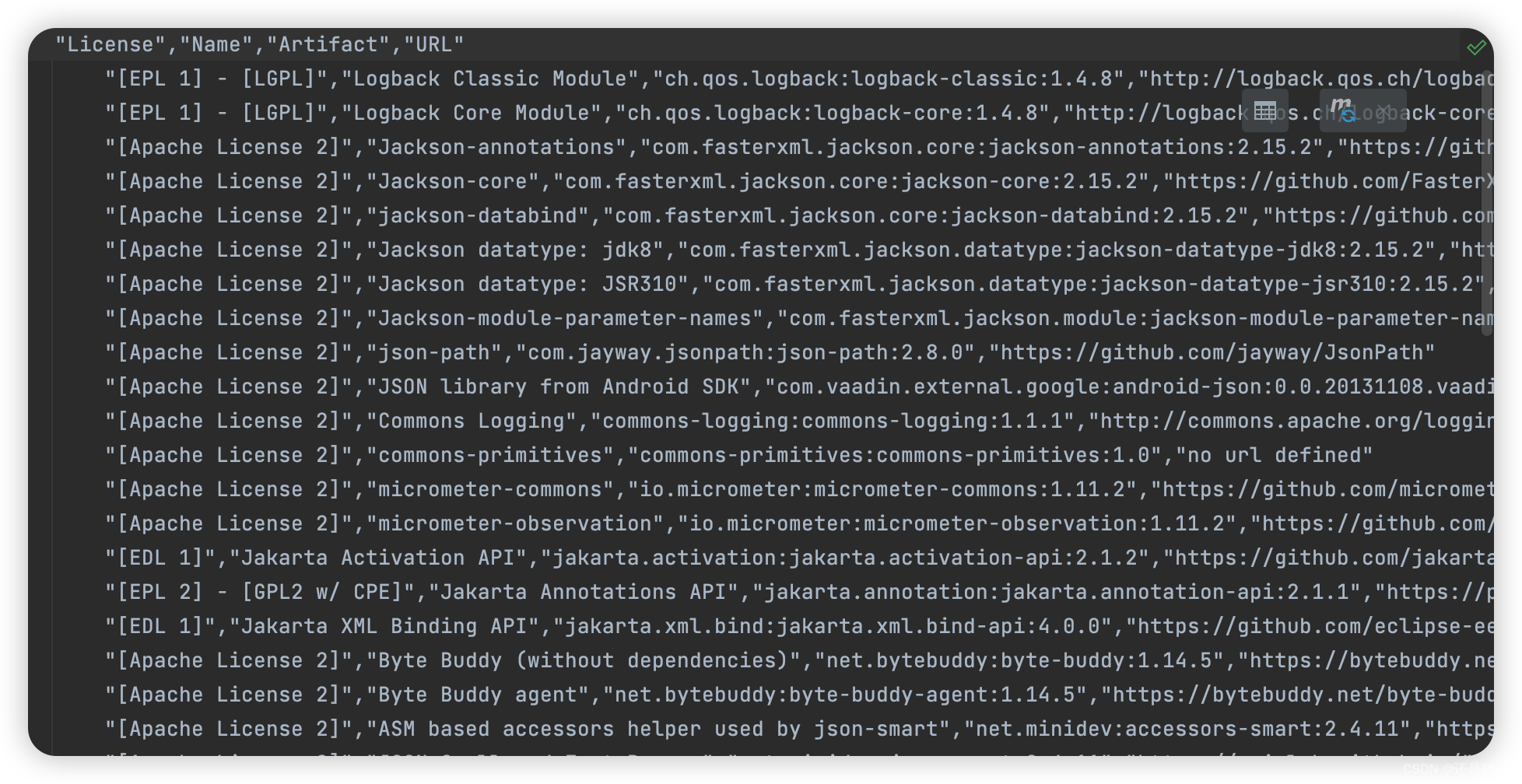
其中有一条:
"[Apache License 2.0]","commons-primitives","commons-primitives:commons-primitives:1.0","no url defined"
这是由于在missing文件中指定了commons-primitives插件使用Apache License 2.0,所以才生成如此。
注意到,由于license白名单为空,也没有配置黑名单,因此failOnBlacklist参数实际上就没有什么意义了。每次执行都会成功。
设置白名单
下面设置license白名单:
Apache License 2.0
MIT License
BSD License 3
再次执行maven命令,输出如下:
[INFO] --- license-maven-plugin:2.3.0:add-third-party (add-third-party) @ PremissDemo ---
[INFO] Load missingFile /Users/howe/workSpace/PremissDemo/build/license/third-party-missing.properties
[INFO] Missing file /Users/howe/workSpace/PremissDemo/build/license/third-party-missing.properties is up-to-date.
[INFO] Included licenses (whitelist): [Apache License 2.0, MIT License, BSD License 3]
[WARNING] There are 12 forbidden licenses used:
[WARNING] License: 'EDL 1.0' used by 1 dependencies:-Jakarta Activation API (jakarta.activation:jakarta.activation-api:2.1.2 - https://github.com/jakartaee/jaf-api)
[WARNING] License: 'The Apache License, Version 2.0' used by 2 dependencies:-org.apiguardian:apiguardian-api (org.apiguardian:apiguardian-api:1.1.2 - https://github.com/apiguardian-team/apiguardian)-org.opentest4j:opentest4j (org.opentest4j:opentest4j:1.2.0 - https://github.com/ota4j-team/opentest4j)
[WARNING] License: 'BSD-3-Clause' used by 1 dependencies:
...
有很多license不在白名单中,而failOnBlacklist参数为true的情况下,此种情况构建会失败,也不会生成最终的license信息。
同时注意到,我们已经将BSD License 3添加到白名单了,但仍然提示BSD-3-Clause非法。这就是上文说的,同一个license可以有不同的叫法。为了解决这种情况,我们就需要在merge文件中设置license别名了。
合并license
设置license别名,如下所示:
BSD License 3 | BSD-3-Clause
MIT License | The MIT License
Apache License 2 | Apache License 2.0 | Apache License, Version 2.0 | The Apache License, Version 2.0 | The Apache Software License, Version 2.0
EPL 1 | Eclipse Public License - v 1.0
EPL 2 | Eclipse Public License v2.0 | EPL 2.0
EDL 1 | Eclipse Distribution License - v 1.0 | EDL 1.0
LGPL | GNU Lesser General Public License
如此配置后,每一行都表示是同一个license,且使用第一个名称。如果第一个名称不在白名单内,同样会构建失败。因此需要将白名单补充完整:
Apache License 2
MIT License
BSD License 3
EPL 1
EPL 2
EDL 1
再次执行maven命令,构建成功。
执行mvn clean compile license:third-party-report命令,还可以看到生成的license报告了。
可以从报告中看到,commons-primitives组件的license信息来自于missingFile文件,其他所有组件的license信息均来自于各自的pom文件。
参考资料
[1].https://cloud.tencent.com/developer/article/2141158
[2].https://www.mojohaus.org/license-maven-plugin/
[3].https://gist.github.com/rogelio-blanco/bd2e2a544f7ff1f0263b2bdefd86b883