网站建设公司销售技巧石家庄做外贸的网站推广
1. 初识 SpringMVC,运行配置第一个Spring MVC 程序
文章目录
- 1. 初识 SpringMVC,运行配置第一个Spring MVC 程序
- 1.1 什么是 MVC
- 2. Spring MVC 概述
- 2.1 Spring MVC 的作用:
- 3. 运行配置第一个 Spring MVC 程序
- 3.1 第一步:创建Maven模块
- 3.2 第二步:添加 web 支持
- 3.3 第三步:配置 web.xml文件
- 3.4 第四步:编写控制器 FirstController
- 3.5 第五步:配置springmvc-servlet.xml文件
- 3.6 第六步:根据自行定义好的视图解析器(的配置),提供视图
- 3.7 第七步:控制器 FirstController 处理请求返回逻辑视图名称
- 3.8 第八步:运行 Tomcat 测试
- 3.9 执行流程总结:
- 4. 第一个 Spring MVC 程序优化:
- 4.1 在web.xml 配置文件中 ,手动自定 spring mvc 的配置文件
- 4.2 配置 thymeleaf 翻译为 html 的模板
- 4.3 编写 IndexController 定义个“首页”
- 4.4 测试
- 5. 总结:
- 6. 最后:
1.1 什么是 MVC
MVC 是一种软件架构模式(是一种软件架构设计思想,不仅仅是Java开发中用到,其它语言也需要用到),它将应用分为三块。
- M: Model (模型)
- V:View (视图)
- C:Controller (控制器)
应用为什么要被分为三块,优点是什么?
- 低耦合,扩展能力增强
- 代码复用性增强
- 代码可维护性增强
- 高内聚,让程序员更加专注业务的开发。
MVC 将应用分为三块,每一块各司其职,都有自己专注的事情要做,它们属于分工协作,互相配合:
- Model :负责业务处理及数据的收集
- View:负责数据的展示
- Controller:负责调度,它是一个调度中心,它来决定什么时候调用Model 来处理业务,什么时候调用 View 视图来展示数据。
MVC 架构图模式如下:所示
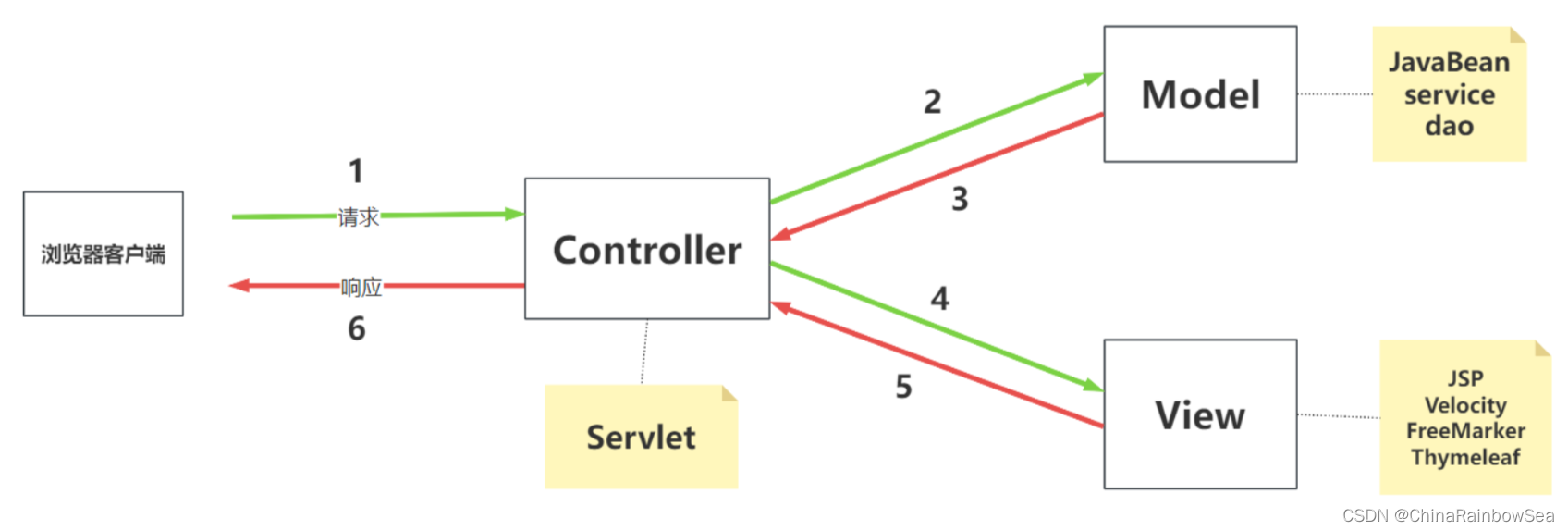
MVC 架构模式的描述:前端浏览器发送请求给 Web 服务器,Web 服务器中的 Controller 接收到用户的请求,Controller 负责将前端提交的数据进行封装,然后 Controller 调用 Model 来处理业务,当Model 处理完业务后,会返回处理之后的数据给 Controller,Controller 再调用 View 来完成数据的展示,最终将结果响应给浏览器,浏览器进行渲染展示页面的内容。
面试题:什么是三层模型,并说一说MVC架构模式与三层模型的区别?
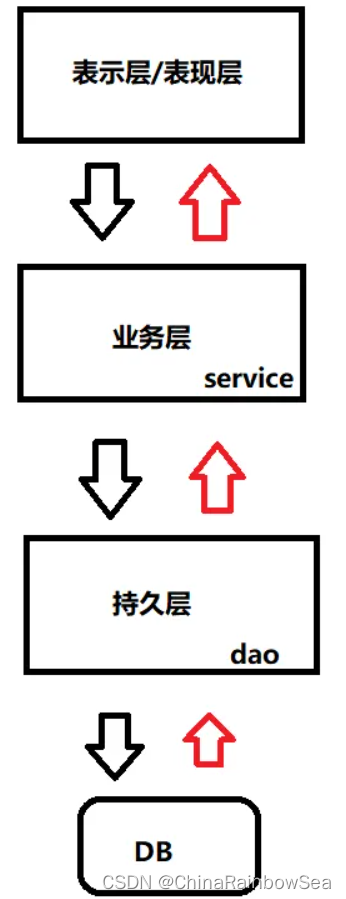
MVC 和 三层模型都采用了分层结构来设计应用程序,都是降低耦合度,提高扩展力,提高组件复用性,区别在于:它们的关注点不同,三层模型更关注业务逻辑组件的划分。
MVC 架构模式关注的是整个应用程序的层次关系和分离思想。现代的开发方式大部分都是 MVC 架构模式结合三层模型一起用的。
更多关于 MVC 架构的内容大家可以移步至:✏️✏️✏️ MVC 三层架构案例详细讲解_mvc三层架构-CSDN博客
2. Spring MVC 概述
Spring MVC 是一个实现了MVC架构模式的 Web 框架,底层基于 Servlet 实现。
Spring MVC 已经将MVC架构模式实现了,因此只要我们基于 Spring MVC 框架写代码,编写的程序就是符合 MVC架构模式的。(MVC的架子已经为我们搭好了,我们只需要添添补补即可)
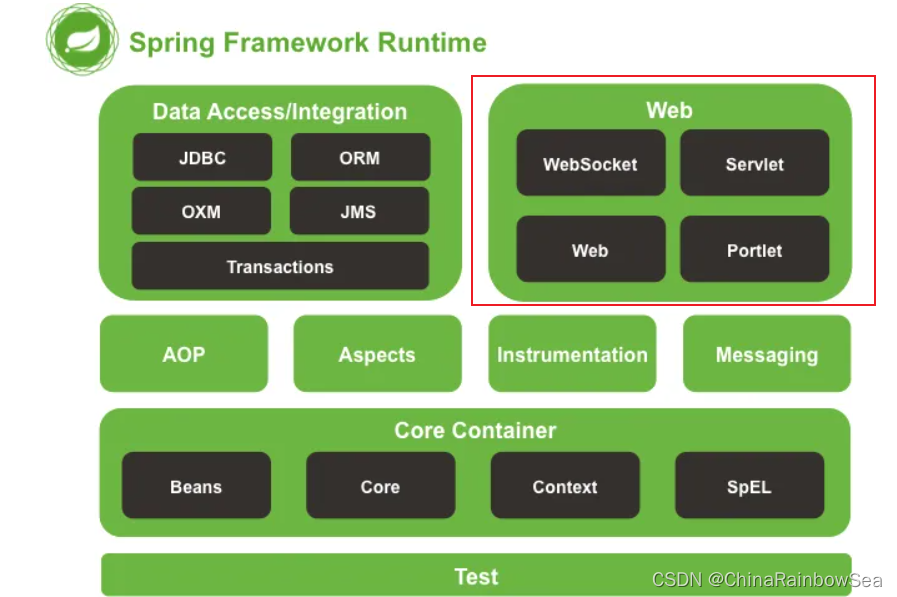
Spring 框架中有一个子项目叫做:Spring Web,Spring Web 子项目当中包含很多模块,例如:
- Spring MVC
- Spring WebFlux
- Spring Web Services
- Spring Web Flow
- Spring WebSocket
- Spring Web Services Client
可见 Spring MVC 是 Spring Web 子项目当中的一个模块,因此也可以说 Spring MVC 是Spring 框架的一部分。
所以学习 Spring MVC 框架之前要先学习 Spring 框架中的 IOC 和 AOP 等内容。
另外,使用Spring MVC 框架的时候,同样也可以始于 IOC 和 AOP 。
关于 Spring的学习内容,大家可以移步至:✏️✏️✏️ Spring_ChinaRainbowSea的博客-CSDN博客
下面是 Spring 官方给出的 Spring 架构图,其中的 Web 中的 Servlet 指的就是 Spring MVC 部分
2.1 Spring MVC 的作用:
Spring MVC 框架能帮我们做什么,与 纯粹的 Servlet 开发有什么区别?
- 入口控制:Srping MVC 框架通过 DispatcherServlet 作为 入口控制器,负责接收请求和分发请求。而在 Servlet 开发中,需要自己编写 Servlet 程序,并在
web.xml进行配置,才能接受和处理请求。 - 在 Spring MVC 中,表单提交时,可以自动将表单数据绑定到相应的 Java Bean 对象中,只需要在控制器方法的参数列表中声明该JavaBean对象即可,无需手动获取和赋值表单数据。而在纯粹的 Servlet 开发中,这些都是需要自己手动完成的。
- IOC容器:SpringMVC 框架通过IOC容器管理对象,只需要在配置文件中进行相应的配置即可,获取实例对象,而在 Servelt 开发中需要手动创建对象实例。
- 统一处理请求:Spring MVC 框架提供了拦截器,异常处理器等统一处理请求的机制,并且可以灵活地配置这些处理器。而在 Servelt 开发中,需要自动编写过滤器,异常处理器等,增加了代码的复杂度和开发难度。
- 视图解析:Spring MVC 框架提供了多种视图模块,如:JSP,Freemarker,Velocity等,并且支持国际化,主题等特性。而在Servlet开发中需要手动处理视图层,增加了代码的复杂度。
总之,与 Servelt 开发相比,Spring MVC 框架可以帮我们节省很多时间和精力,减少代码的复杂度,更加专注于业务开发。同时,也提供了更多的功能和扩展性,可以更好地满足企业级应用的开发需求。
3. 运行配置第一个 Spring MVC 程序
3.1 第一步:创建Maven模块
第一步:创建Empty Project,起名:springmvc。
第二步:设置springmvc工程的JDK版本:Java21。
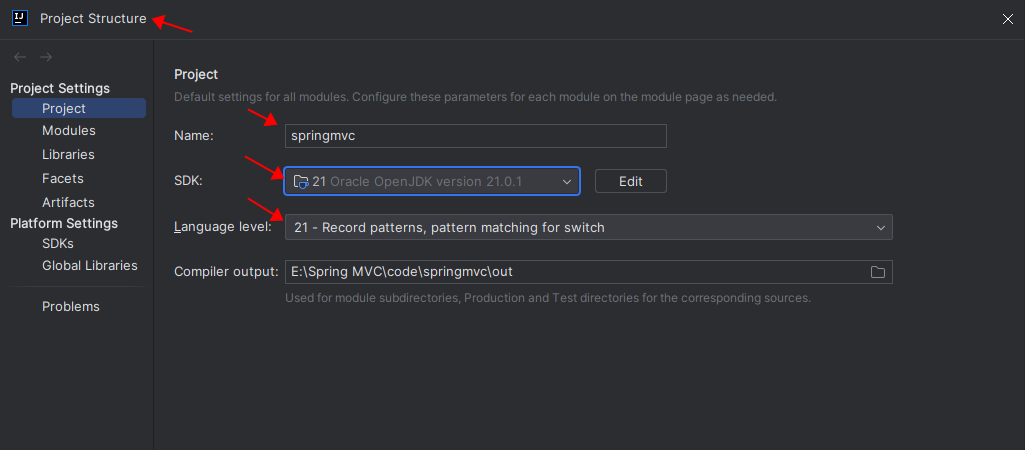
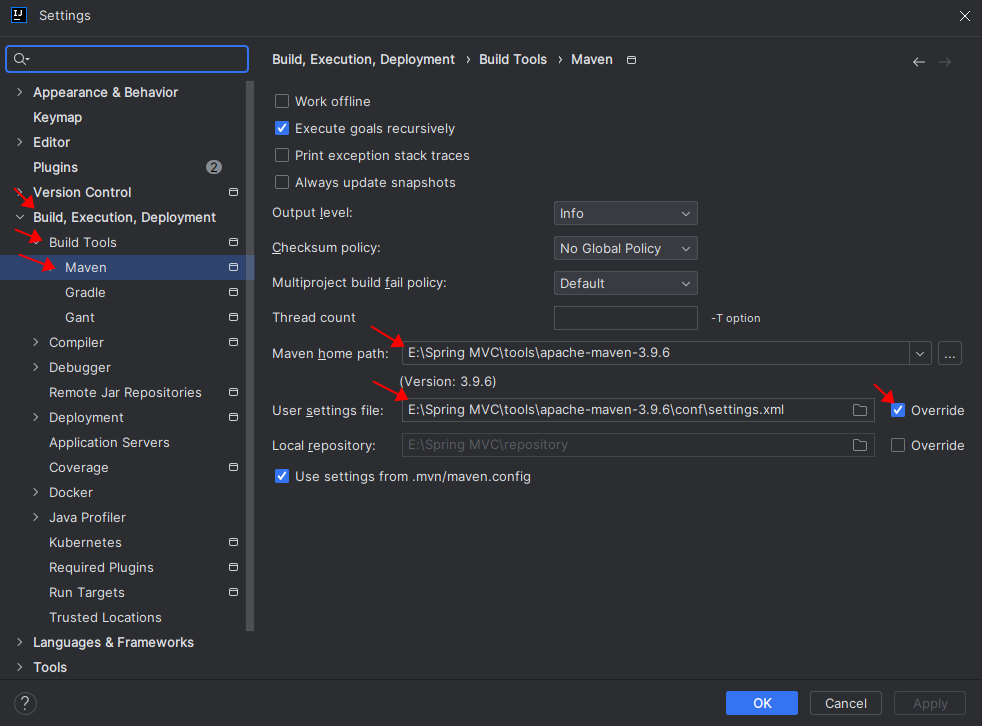
第三步:设置maven。
第四步:创建Maven模块
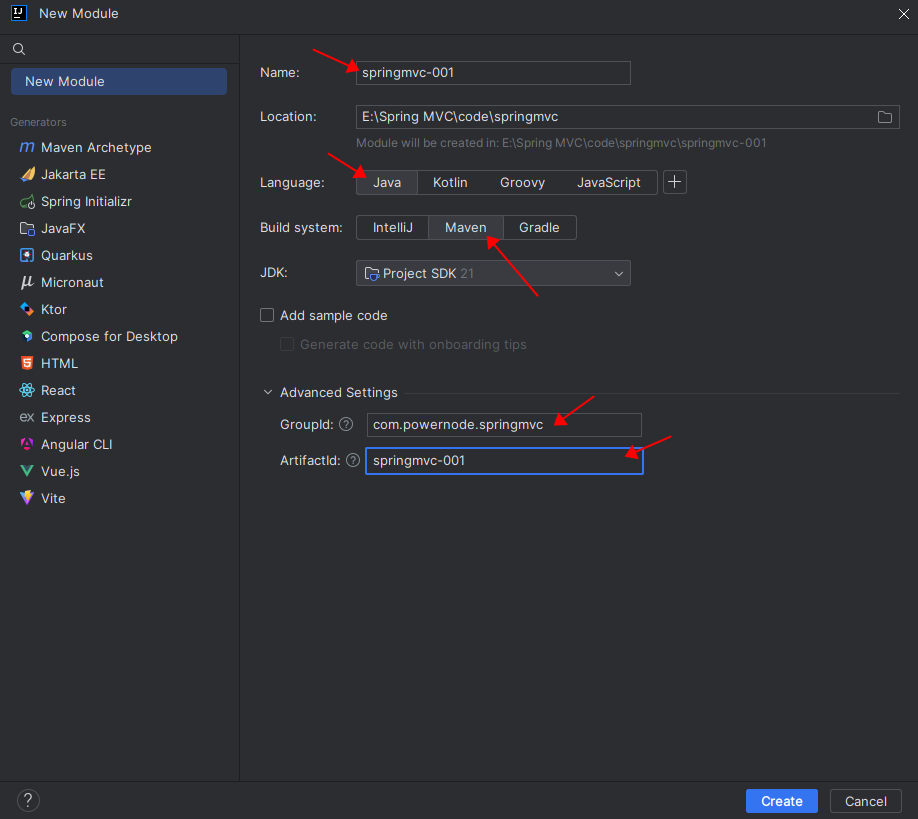
第五步:将pom.xml文件中的打包方式修改为 war
<packaging>war</packaging>
第六步:添加以下依赖
- Spring MVC依赖
- 日志框架Logback依赖
- Servlet依赖
- Spring6和Thymeleaf整合依赖
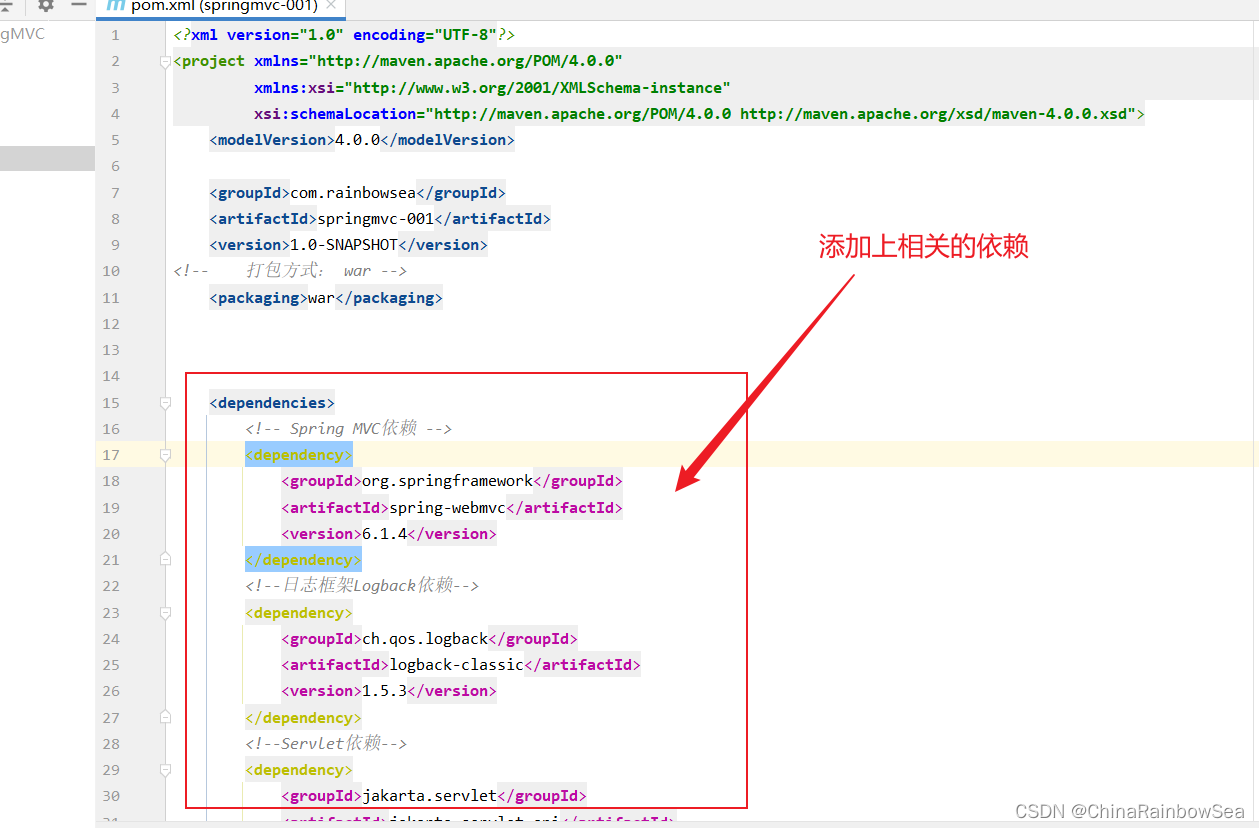
注意点:
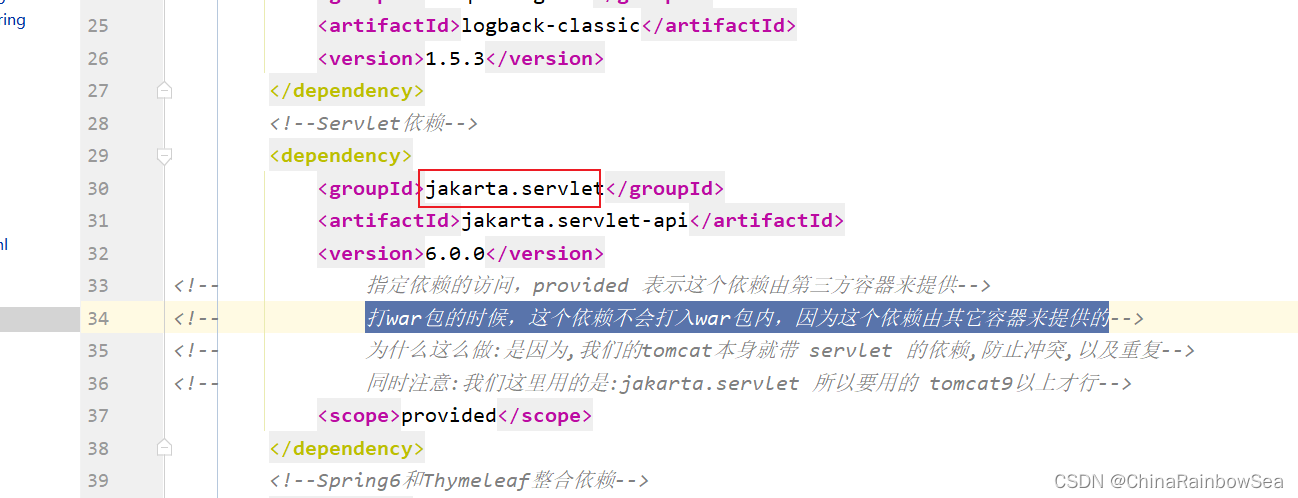
这里我们是在一个单独的 Spring MVC 框架的容器中,配置的 Servlet依赖 ,而我们的 web 项目是运行在 Tomcat 服务器当中的,Tomcat 服务器本身就带 servlet 的依赖,防止冲突,以及重复,占用不必要的资源。所以我们在:Servlet依赖 jar 包下,设置: <scope>provided</scope> 指定依赖的访问,provided 表示这个依赖由第三方容器来提供,打war包的时候,这个依赖不会打入war包内,因为这个依赖由其它容器来提供的。就避免了在 Tomcat 当中重复了。同时注意:我们这里用的是:jakarta.servlet 包下的 Servlet 依赖,所以要用的 tomcat9以上才行,至于为什么要 Tomcat9以上(这里我使用的是 Tomcat 10 ),大家可以移步至:✏️✏️✏️ javaEE Web(Tomcat)深度理解 和 Servlet的本质_jakarta ee 部署 web server-CSDN博客
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.rainbowsea</groupId><artifactId>springmvc-001</artifactId><version>1.0-SNAPSHOT</version>
<!-- 打包方式: war --><packaging>war</packaging><dependencies><!-- Spring MVC依赖 --><dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>6.1.4</version></dependency><!--日志框架Logback依赖--><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.5.3</version></dependency><!--Servlet依赖--><dependency><groupId>jakarta.servlet</groupId><artifactId>jakarta.servlet-api</artifactId><version>6.0.0</version>
<!-- 指定依赖的访问,provided 表示这个依赖由第三方容器来提供-->
<!-- 打war包的时候,这个依赖不会打入war包内,因为这个依赖由其它容器来提供的-->
<!-- 为什么这么做:是因为,我们的tomcat本身就带 servlet 的依赖,防止冲突,以及重复-->
<!-- 同时注意:我们这里用的是:jakarta.servlet 所以要用的 tomcat9以上才行--><scope>provided</scope></dependency><!--Spring6和Thymeleaf整合依赖--><dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf-spring6</artifactId><version>3.1.2.RELEASE</version></dependency></dependencies></project>
3.2 第二步:添加 web 支持
第一步:在 main 目录下创建一个 webapp目录。注意:目录名必须是:webapp ,不可以为其它的。
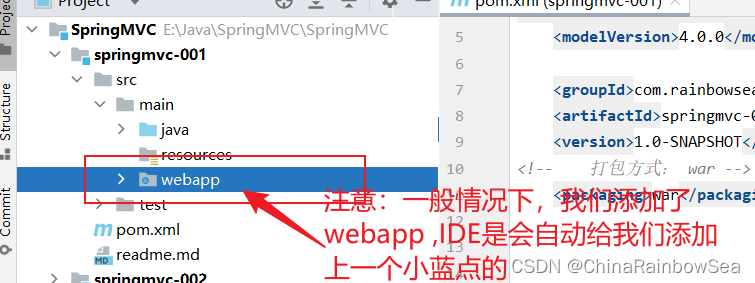
注意:一般情况下,我们添加了webapp ,IDE是会自动给我们添加上一个小蓝点的,如果没有的话,需要我们自己手动添加。
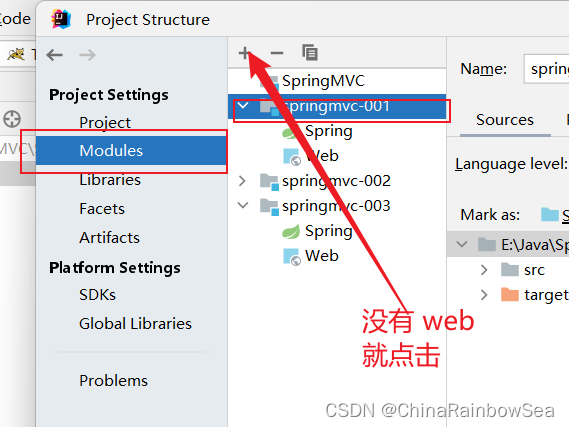
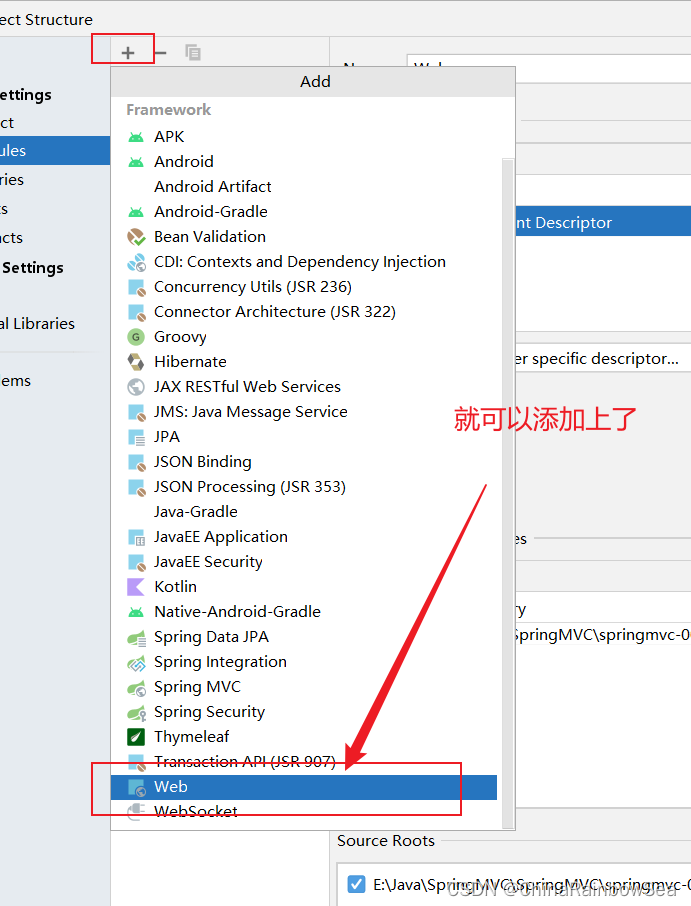
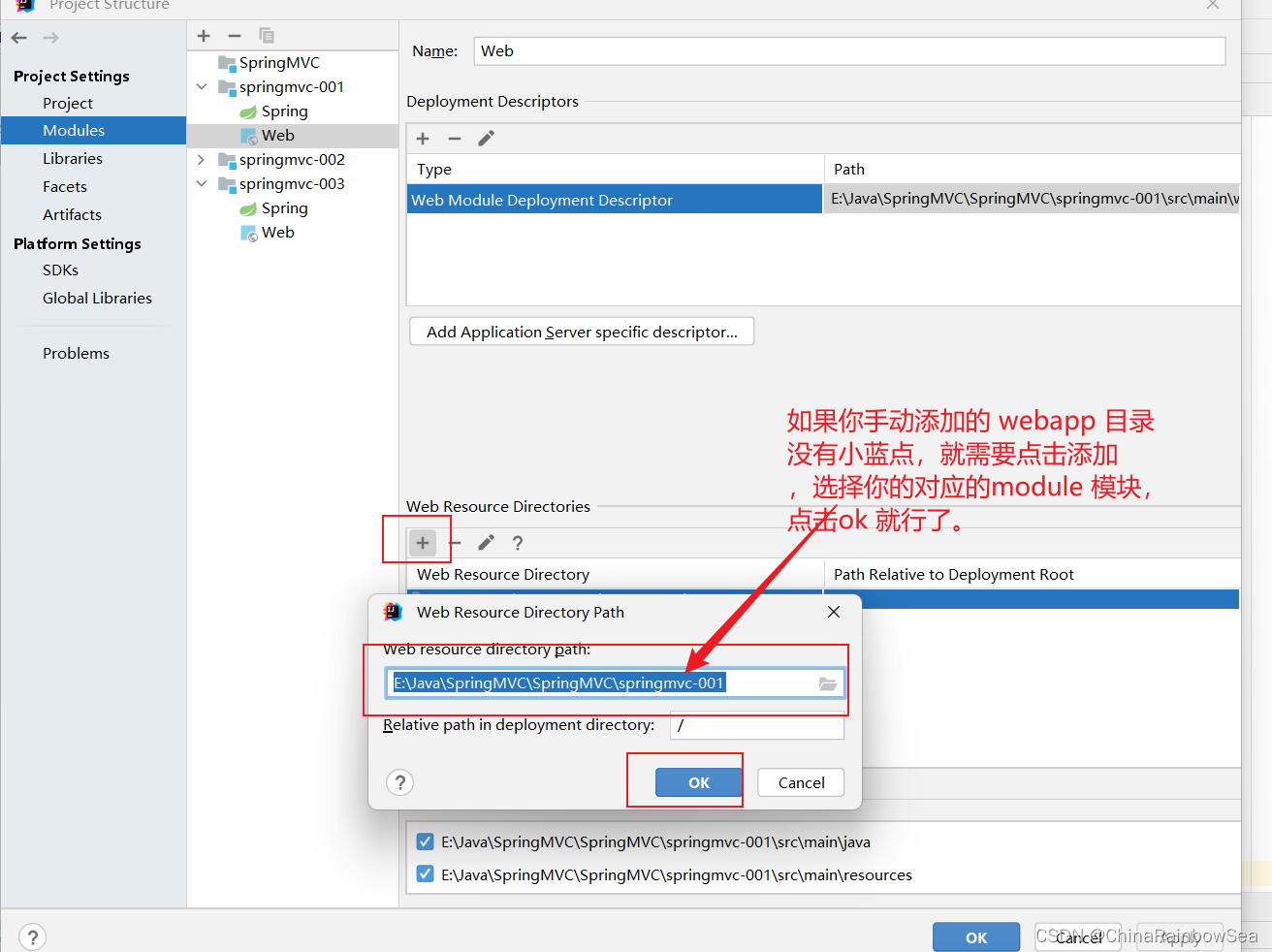
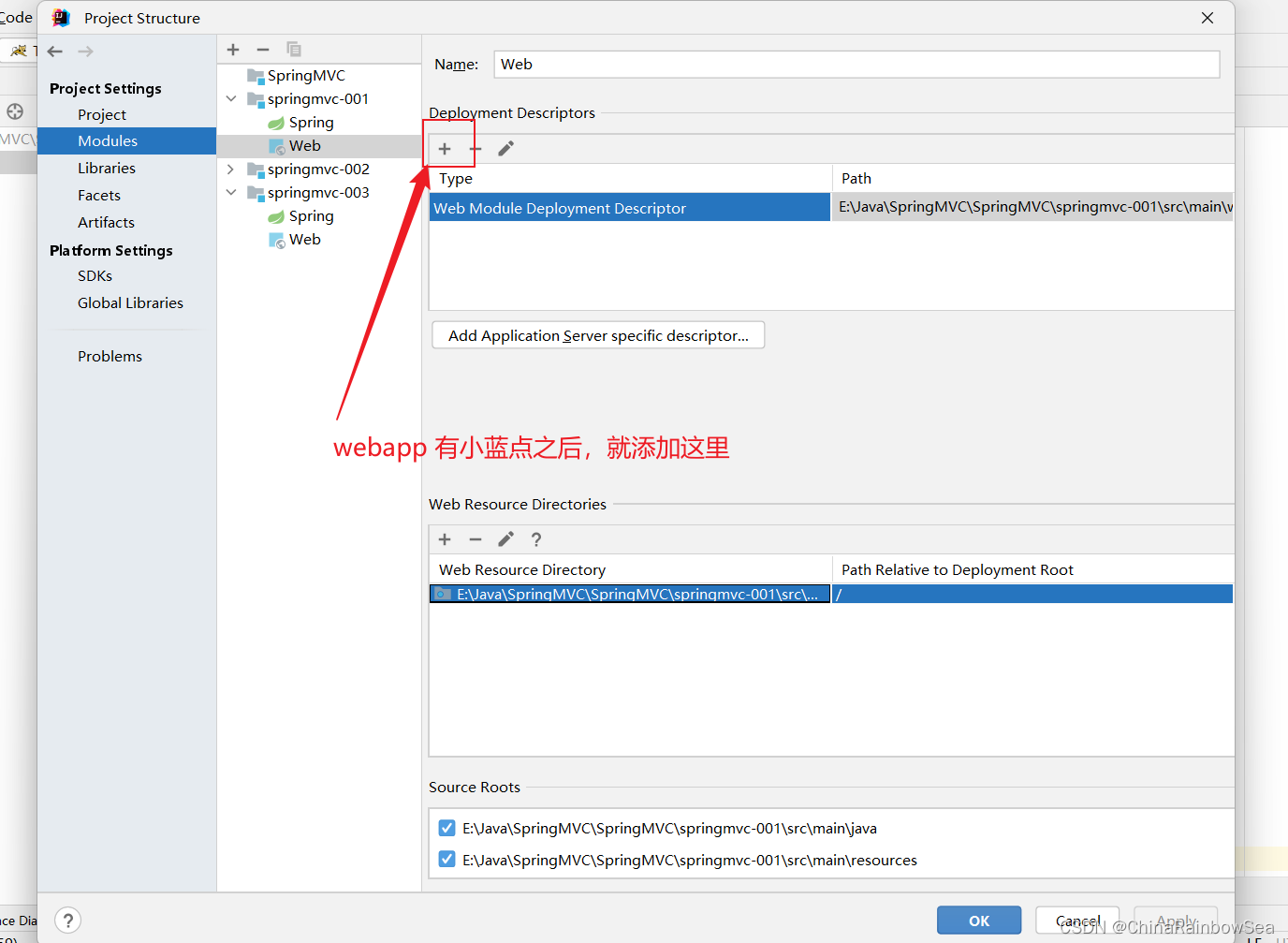
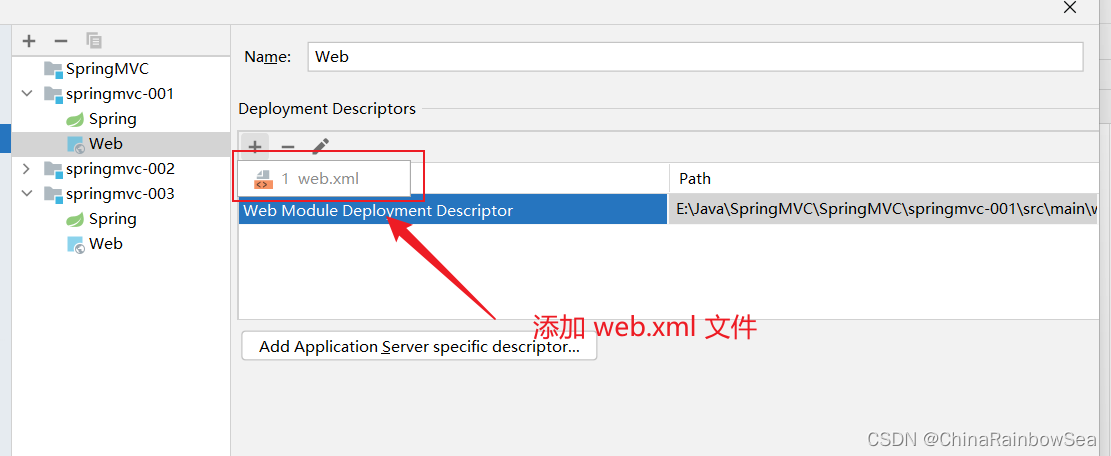
注意 web.xml 文件的位置:E:\Java\SpringMVC\SpringMVC\springmvc-001\src\main\webapp\WEB-INF\web.xml
注意版本选择:6.0
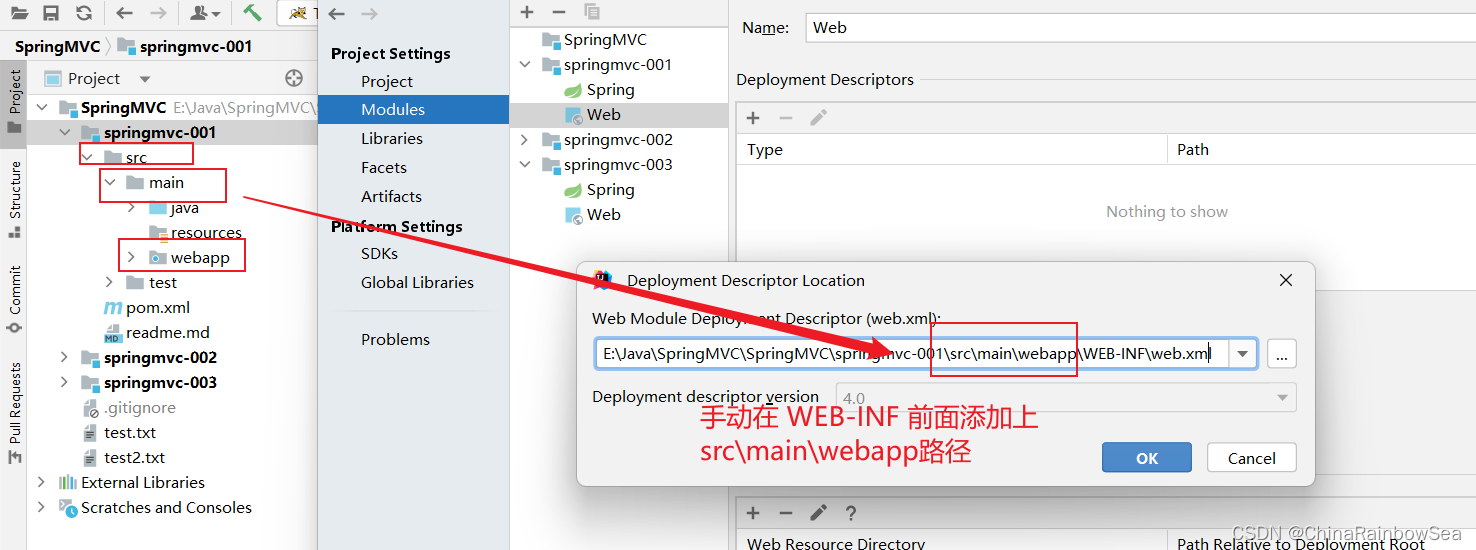
手动在 WEB-INF 前面添加上 src\main\webapp路径。因为我们的WEB-INF 要在 webapp 目录下才行。
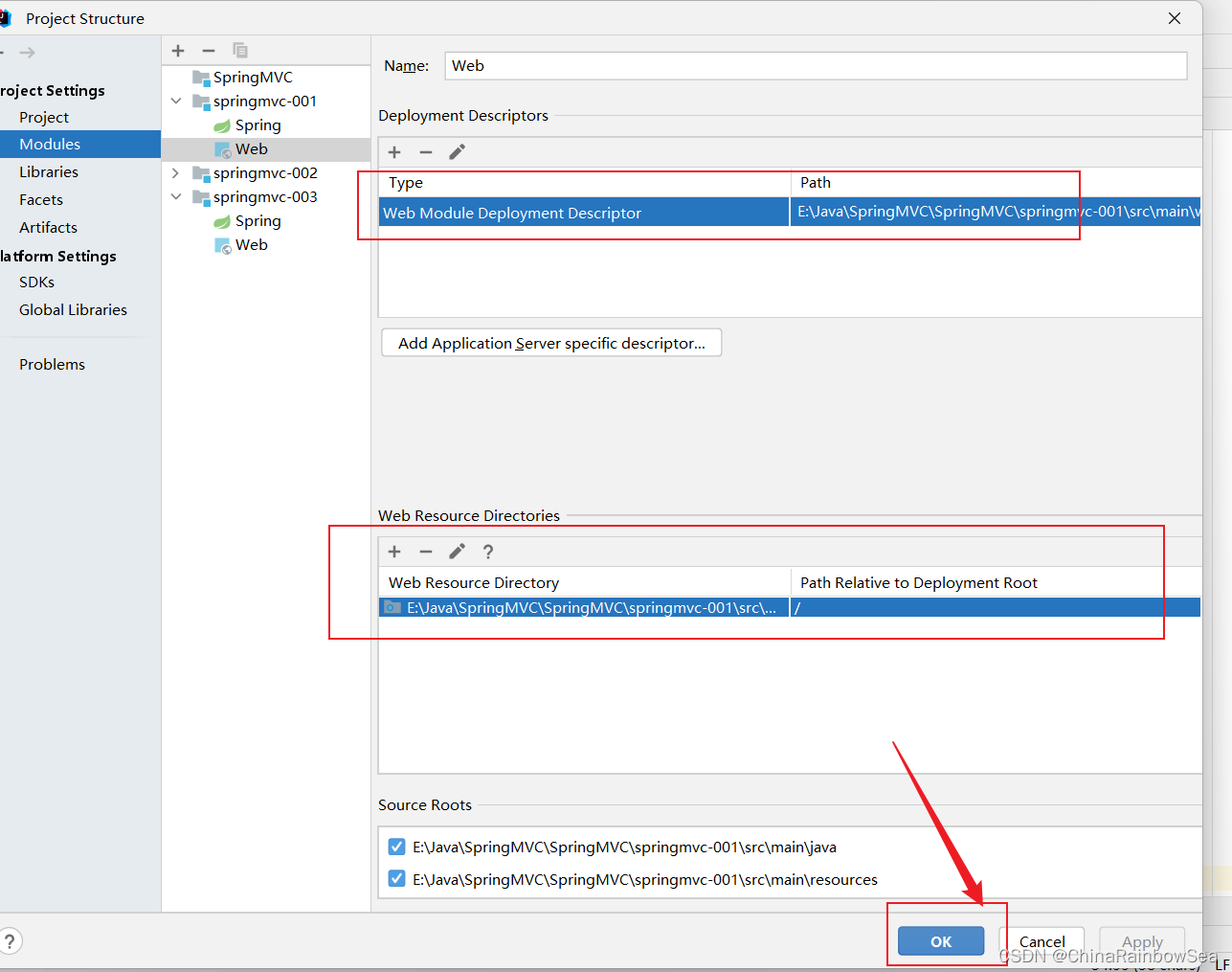
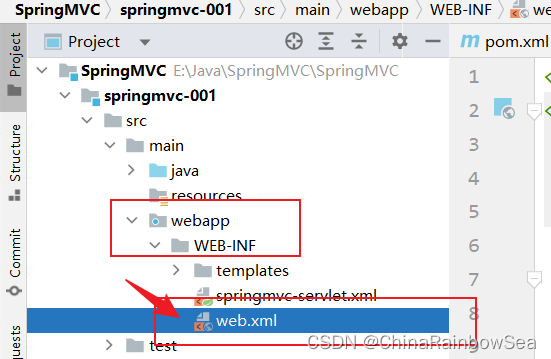
3.3 第三步:配置 web.xml文件
Spring MVC 是一个 web 框架,在 java web 中谁来负责接收请求,处理请求,以及响应?
当然是 Servlet ,在 Spring MVC 框架中已经为我们写好了一个 Servlet ,它的名字叫做:DispatcherServlet ,我们称其为前端控制器 ,既然是 Servlet,那么它就需要在 web.xml 文件中进行配置。
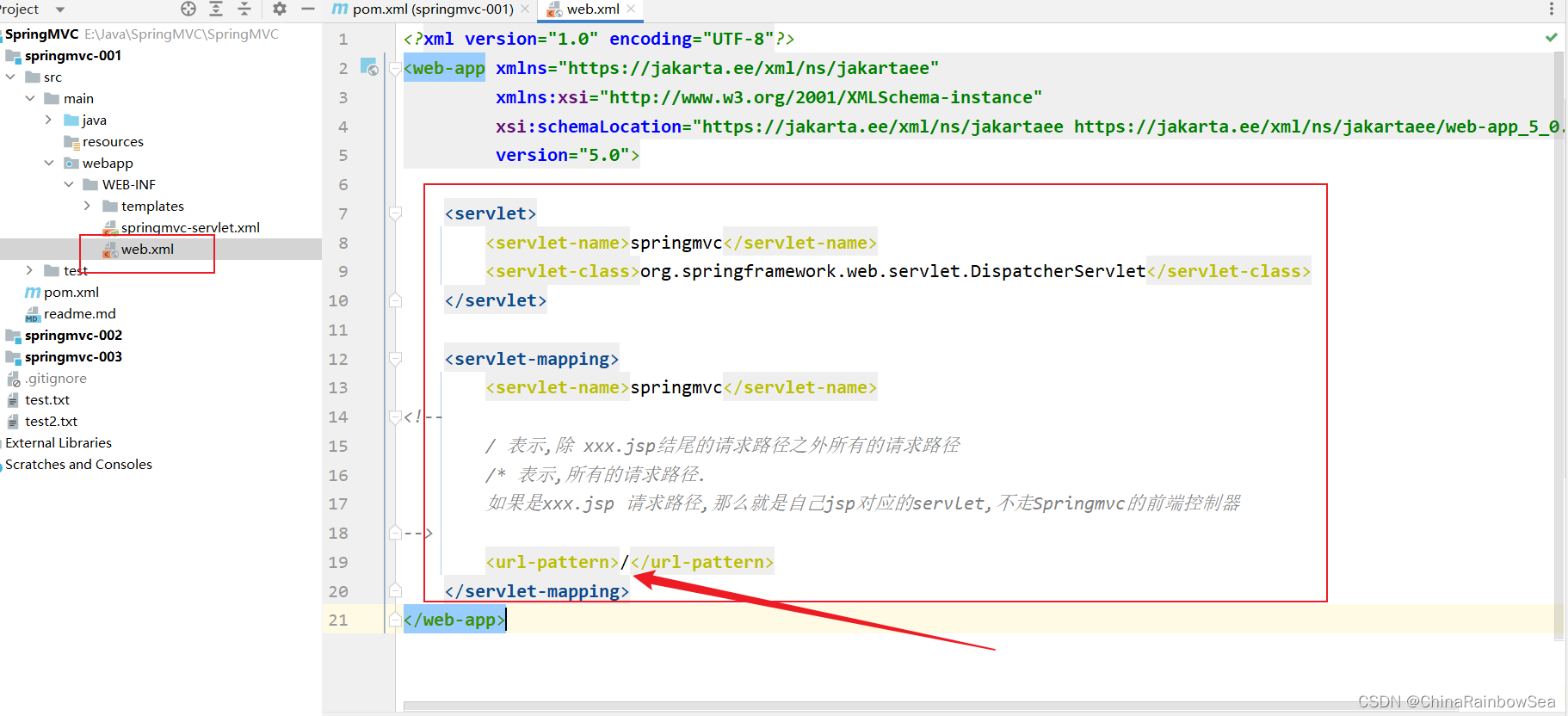
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="https://jakarta.ee/xml/ns/jakartaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="https://jakarta.ee/xml/ns/jakartaee https://jakarta.ee/xml/ns/jakartaee/web-app_6_0.xsd"version="6.0"><!--SpringMVC提供的前端控制器--><servlet><servlet-name>springmvc</servlet-name><servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class></servlet><servlet-mapping><servlet-name>springmvc</servlet-name><!-- /* 表示任何一个请求都交给DispatcherServlet来处理 --><!-- / 表示当请求不是xx.jsp的时候,DispatcherServlet来负责处理本次请求--><!-- jsp本质就是Servlet,因此如果请求是jsp的话,应该走它自己的Servlet,而不应该走DispatcherServlet --><!-- 因此我们的 url-pattern 使用 / --><url-pattern>/</url-pattern></servlet-mapping></web-app>
注意:
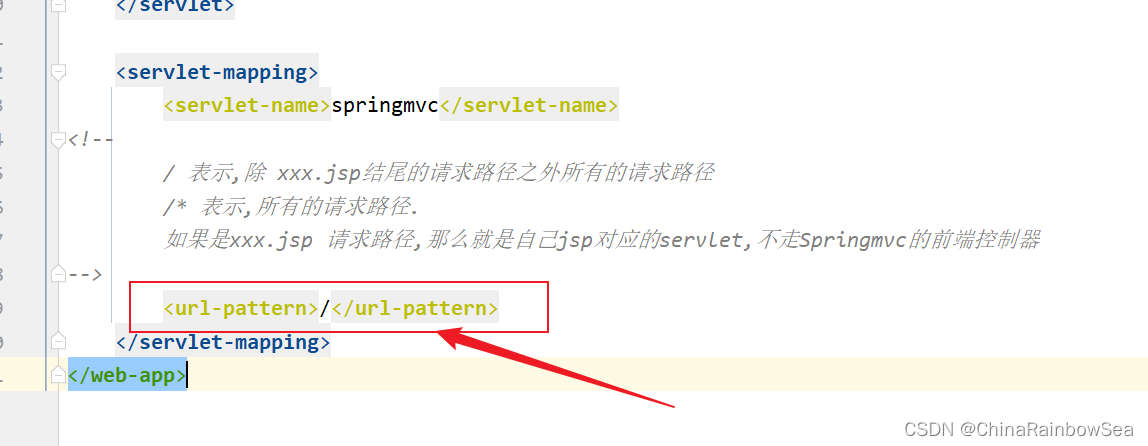
<url-pattern>/</url-pattern>配置为/的作用意义是:/* 表示任何一个请求都交给DispatcherServlet来处理 --> / 表示当请求不是xx.jsp的时候,DispatcherServlet来负责处理本次请求--> jsp本质就是Servlet,因此如果请求是jsp的话,应该走它自己的Servlet,而不应该走DispatcherServlet <!-- 因此我们的 url-pattern 使用 / -->
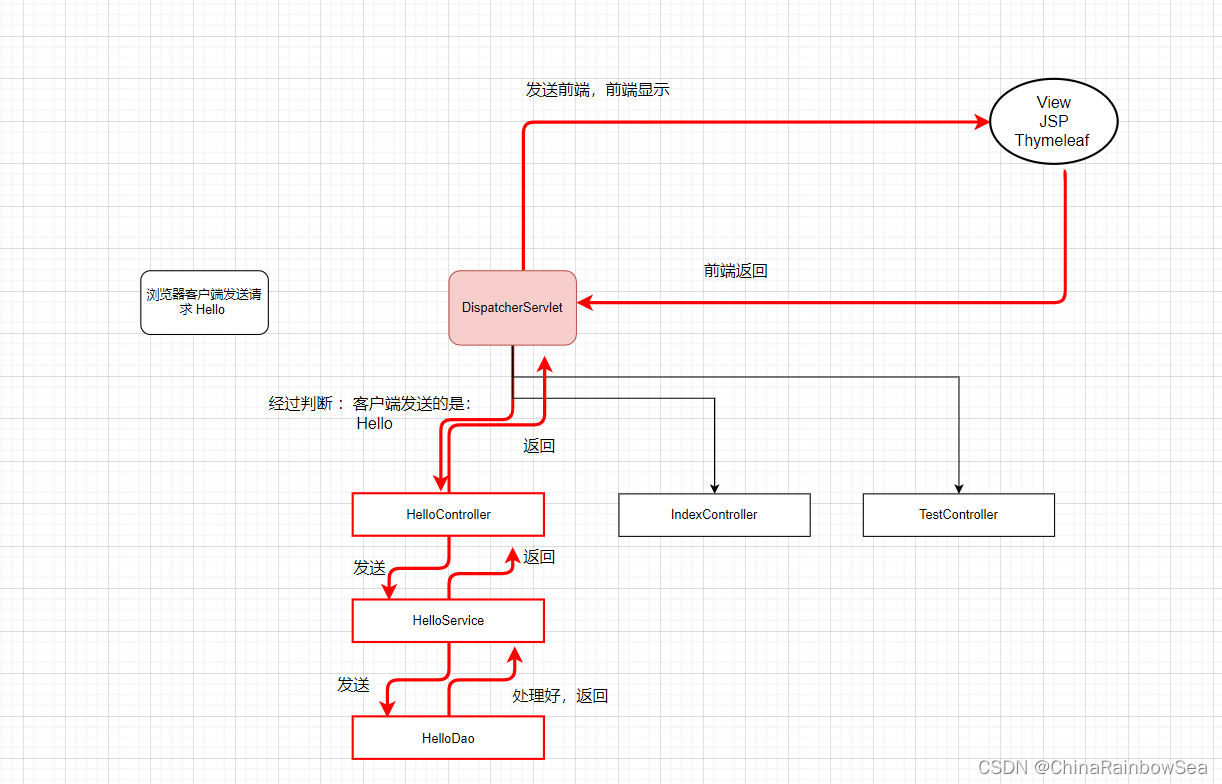
DispatcherServlet 是 Spring MVC 框架为我们提供的最核心 的类。它是整个 Spring MVC 框架的前端控制器。负责接收 HTTP 请求,将请求路由到处理程序,处理响应信息,最终将响应返回给客户端。DispatcherServlet 是 Web 应用程序的主要入口之一,它的职责包括:
- 接收客户端的 HTTP 请求:DispatcherServlet 监听来自 Web 浏览器的 HTTP 请求,然后根据请求的 URL 将请求数据解析为 Request 对象。
- 处理请求的 URL:DispatcherServlet 将请求的URL(Uniform Resource Locator)与处理程序进行匹配,确定要调用哪个控制器(Controller) 来处理此请求。
- 调用相应的控制器:DispatcherServlet 将请求发送给找到的控制器处理,控制器将执行业务逻辑,然后返回一个模型对象(Model)
- 渲染视图:DispatcherServlet 将调用视图对象引擎,将模型对象呈现为用户可以查看的 HTML 页面。
- 返回响应给客户端:DispatcherServlet 将用户生成的响应发送回浏览器,响应可以包括:表单,JSON,XML,HTML 以及其它类型的数据。
DispatcherServlet 工作流程图:
3.4 第四步:编写控制器 FirstController
DispatcherServlet 接收到请求之后,会根据请求路径分发到对应的Controller,Controller 来负责处理请求的核心业务。在Spring MVC 框架中 Controller 是一个普通的Java类(一个普通的POJO类,不需要继承任何类或实现任何接口),需要注意的是:POJO类要纳入 IOC 容器来管理,POJO类的生命周期由 Spring 来管理,因此要使用注解标注@Controller 。
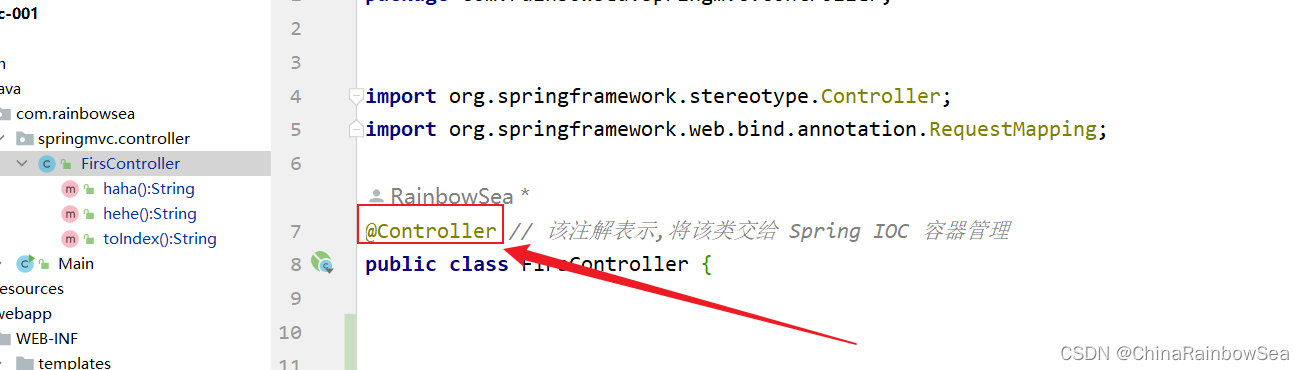
package com.rainbowsea.springmvc.controller;import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;@Controller // 该注解表示,将该类交给 Spring IOC 容器管理
public class FirsController {}3.5 第五步:配置springmvc-servlet.xml文件
SpringMVC框架有它自己的配置文件,该配置文件的名字默认为:-servlet.xml,默认存放的位置是WEB-INF 目录下:
当然,这个默认的,都是可以通过配置修改的。关于这部分的内容,在后续更新文章当中会说明的。
要在该 -servlet.xml 配置文件当中,配置如下两项信息:
第一项:组件扫描,Spring 扫描这个包中的类,将这个包中的类实例化并纳入IOC容器当中进行管理。
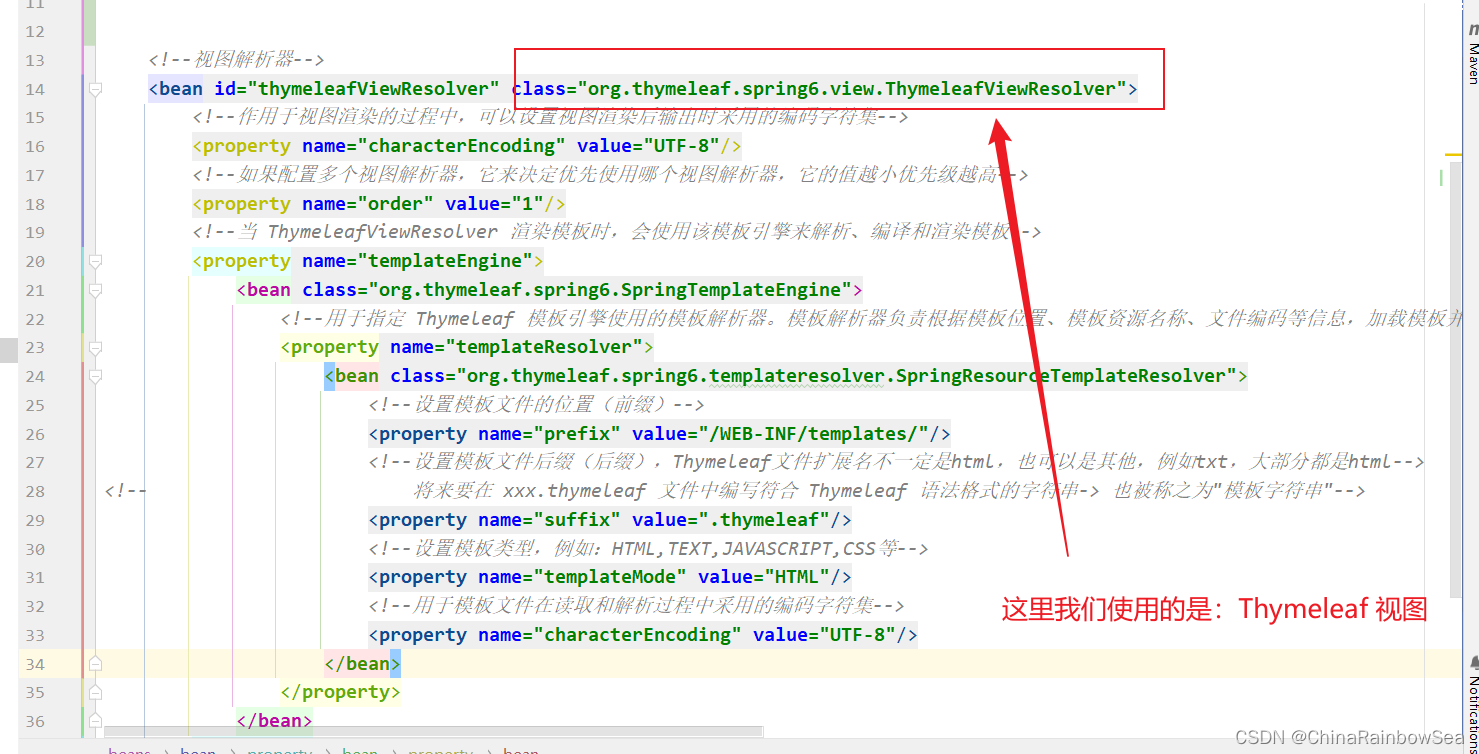
第二项:视图解析器:视图解析器(View Resolver) 的作用主要是将Controller 方法返回的逻辑视图名称解析成实际的视图对象。视图解析器将解析出的视图对象返回给 DispatcherServlet,并最终由 DispatcherServlet 将该视图对象转化为响应结果,呈现给用户。
注意:如果采用了其它视图,请配置对应的视图解析器,例如:
JSP的视图解析器:InternalResourceViewResolver
FreeMarker视图解析器:FreeMarkerViewResolver
Velocity视图解析器:VelocityViewResolver
第一项:组件扫描,Spring 扫描这个包中的类,将这个包中的类实例化并纳入IOC容器当中进行管理。
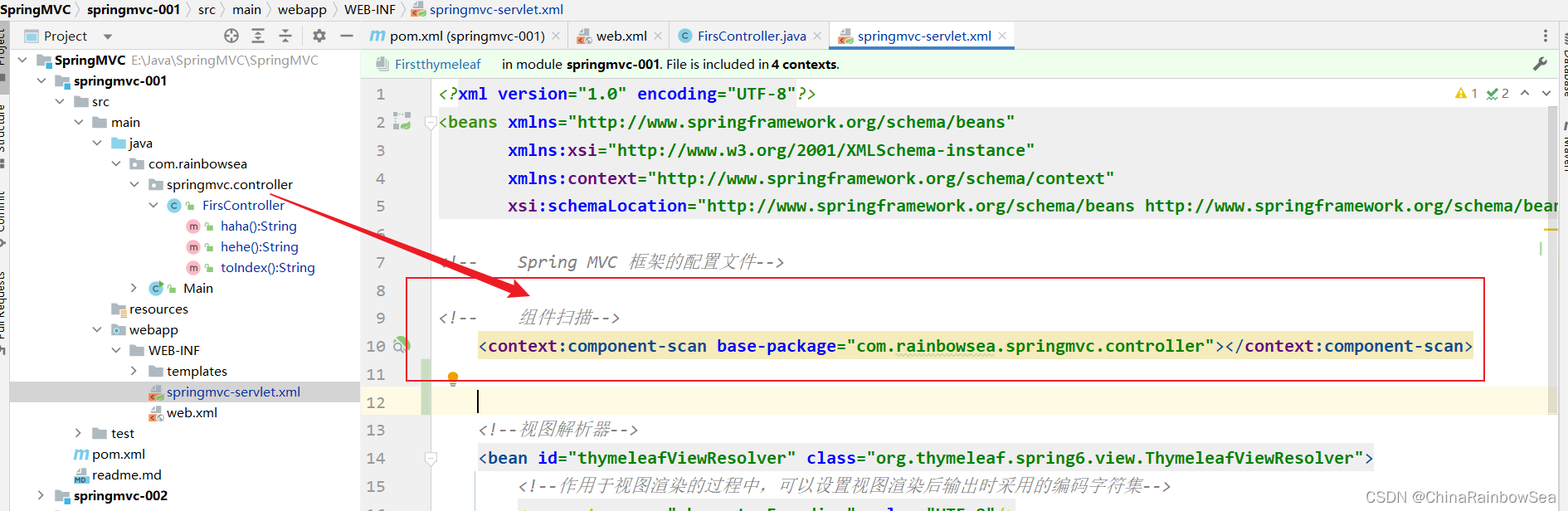
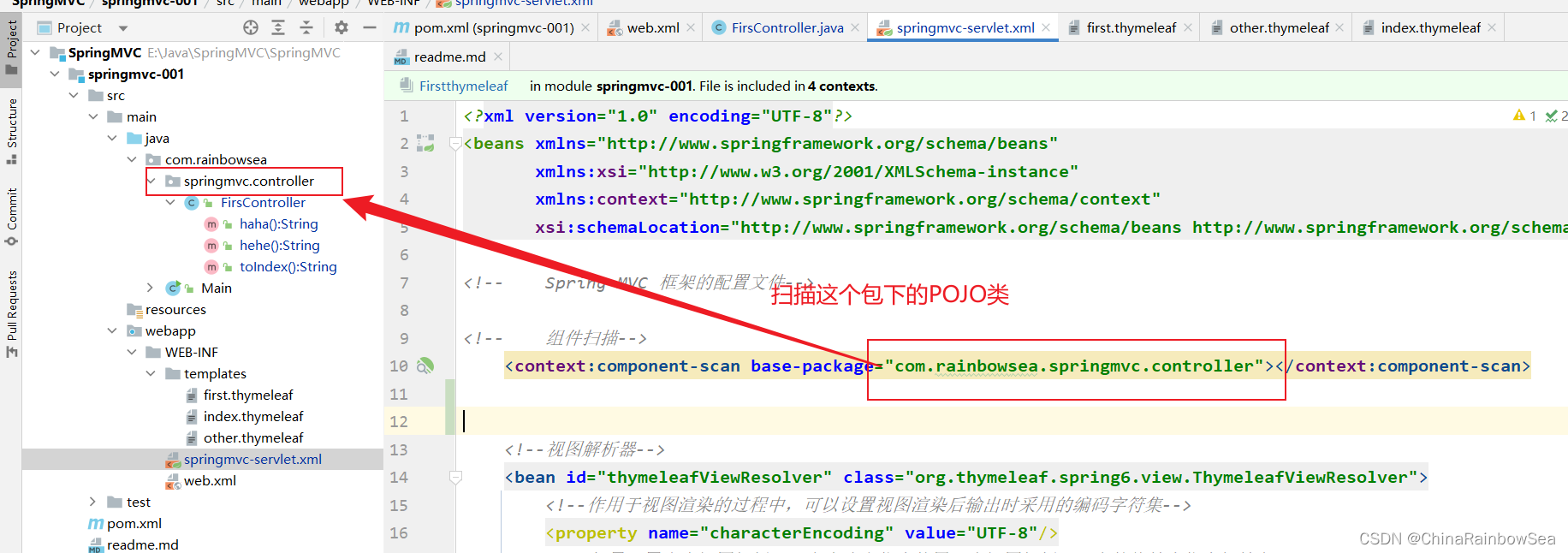
第二项:视图解析器:视图解析器(View Resolver) 的作用主要是将Controller 方法返回的逻辑视图名称解析成实际的视图对象。视图解析器将解析出的视图对象返回给 DispatcherServlet,并最终由 DispatcherServlet 将该视图对象转化为响应结果,呈现给用户
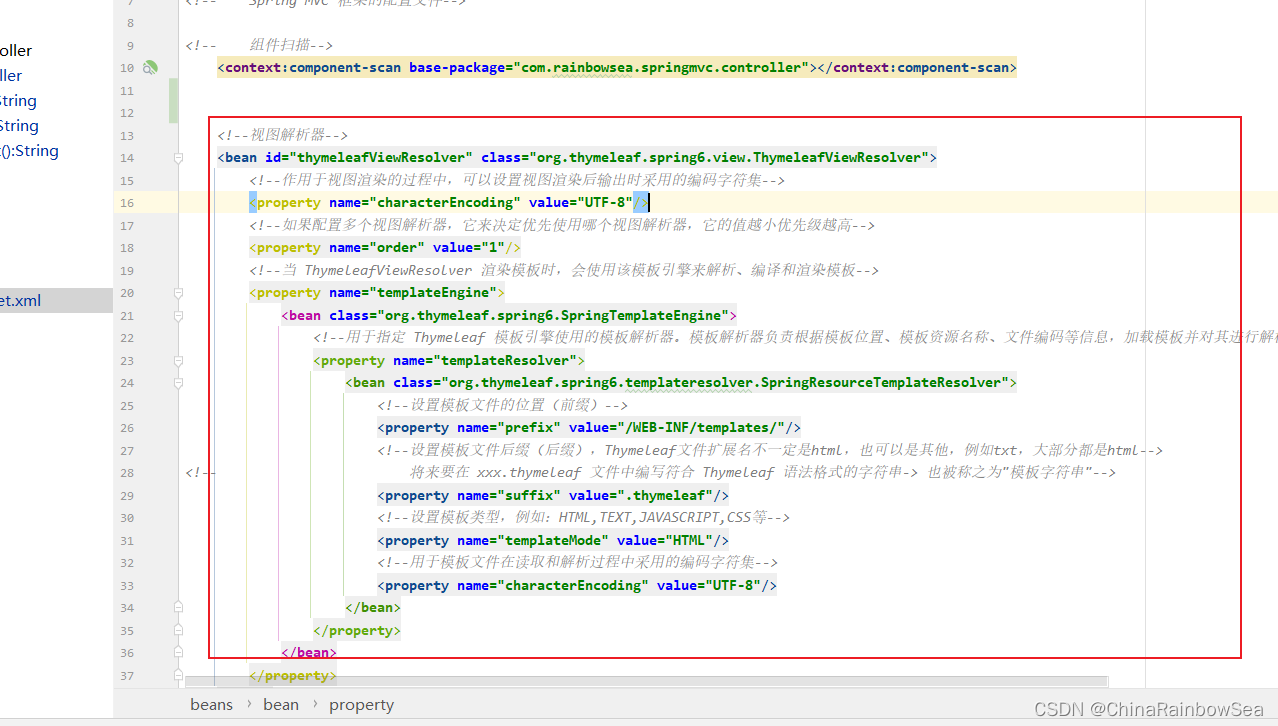
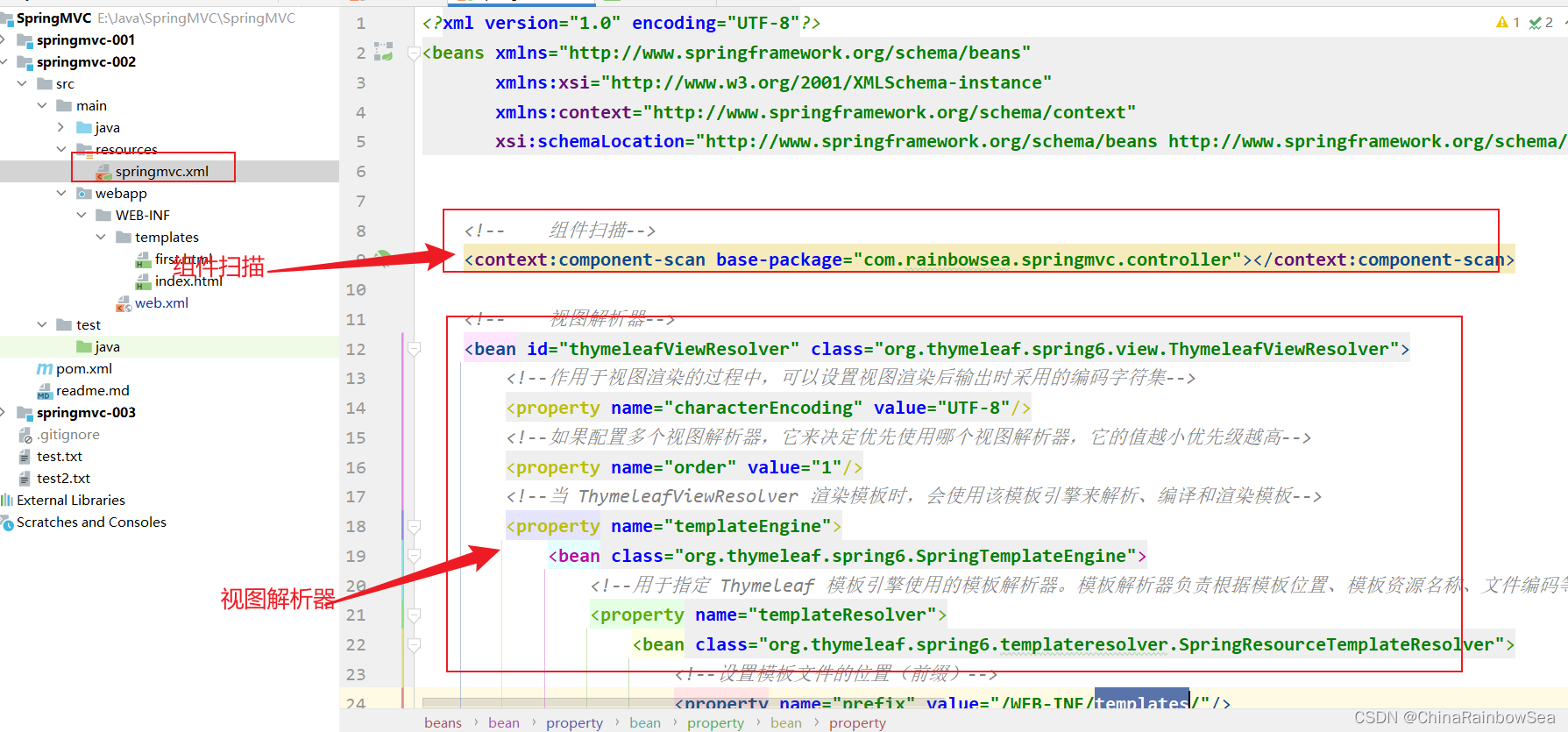
<?xml version="1.0" encoding="UTF-8"?>
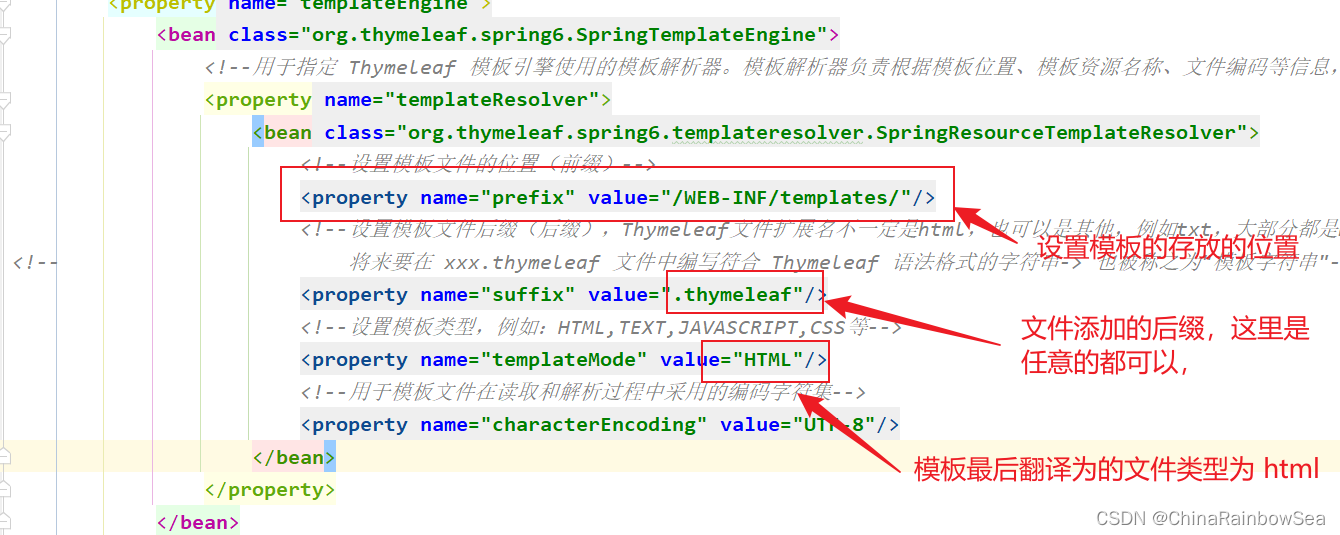
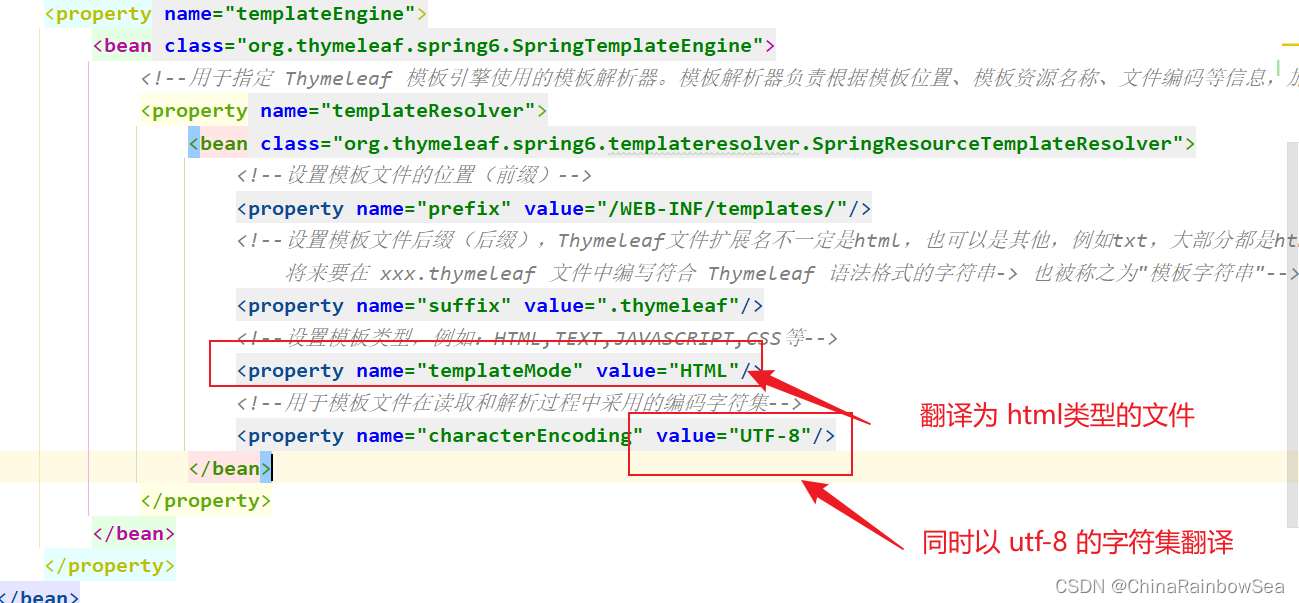
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"><!-- Spring MVC 框架的配置文件--><!-- 组件扫描--><context:component-scan base-package="com.rainbowsea.springmvc.controller"></context:component-scan><!--视图解析器--><bean id="thymeleafViewResolver" class="org.thymeleaf.spring6.view.ThymeleafViewResolver"><!--作用于视图渲染的过程中,可以设置视图渲染后输出时采用的编码字符集--><property name="characterEncoding" value="UTF-8"/><!--如果配置多个视图解析器,它来决定优先使用哪个视图解析器,它的值越小优先级越高--><property name="order" value="1"/><!--当 ThymeleafViewResolver 渲染模板时,会使用该模板引擎来解析、编译和渲染模板--><property name="templateEngine"><bean class="org.thymeleaf.spring6.SpringTemplateEngine"><!--用于指定 Thymeleaf 模板引擎使用的模板解析器。模板解析器负责根据模板位置、模板资源名称、文件编码等信息,加载模板并对其进行解析--><property name="templateResolver"><bean class="org.thymeleaf.spring6.templateresolver.SpringResourceTemplateResolver"><!--设置模板文件的位置(前缀)--><property name="prefix" value="/WEB-INF/templates/"/><!--设置模板文件后缀(后缀),Thymeleaf文件扩展名不一定是html,也可以是其他,例如txt,大部分都是html-->
<!-- 将来要在 xxx.thymeleaf 文件中编写符合 Thymeleaf 语法格式的字符串-> 也被称之为"模板字符串"--><property name="suffix" value=".thymeleaf"/><!--设置模板类型,例如:HTML,TEXT,JAVASCRIPT,CSS等--><property name="templateMode" value="HTML"/><!--用于模板文件在读取和解析过程中采用的编码字符集--><property name="characterEncoding" value="UTF-8"/></bean></property></bean></property></bean>
</beans>
注意:
<property name="prefix" value="/WEB-INF/templates/"/><!--设置模板文件后缀(后缀),Thymeleaf文件扩展名不一定是html,也可以是其他,例如txt,大部分都是html--> <!-- 将来要在 xxx.thymeleaf 文件中编写符合 Thymeleaf 语法格式的字符串-> 也被称之为"模板字符串"--><property name="suffix" value=".thymeleaf"/><!--设置模板类型,例如:HTML,TEXT,JAVASCRIPT,CSS等--><property name="templateMode" value="HTML"/><!--用于模板文件在读取和解析过程中采用的编码字符集--><property name="characterEncoding" value="UTF-8"/>
3.6 第六步:根据自行定义好的视图解析器(的配置),提供视图
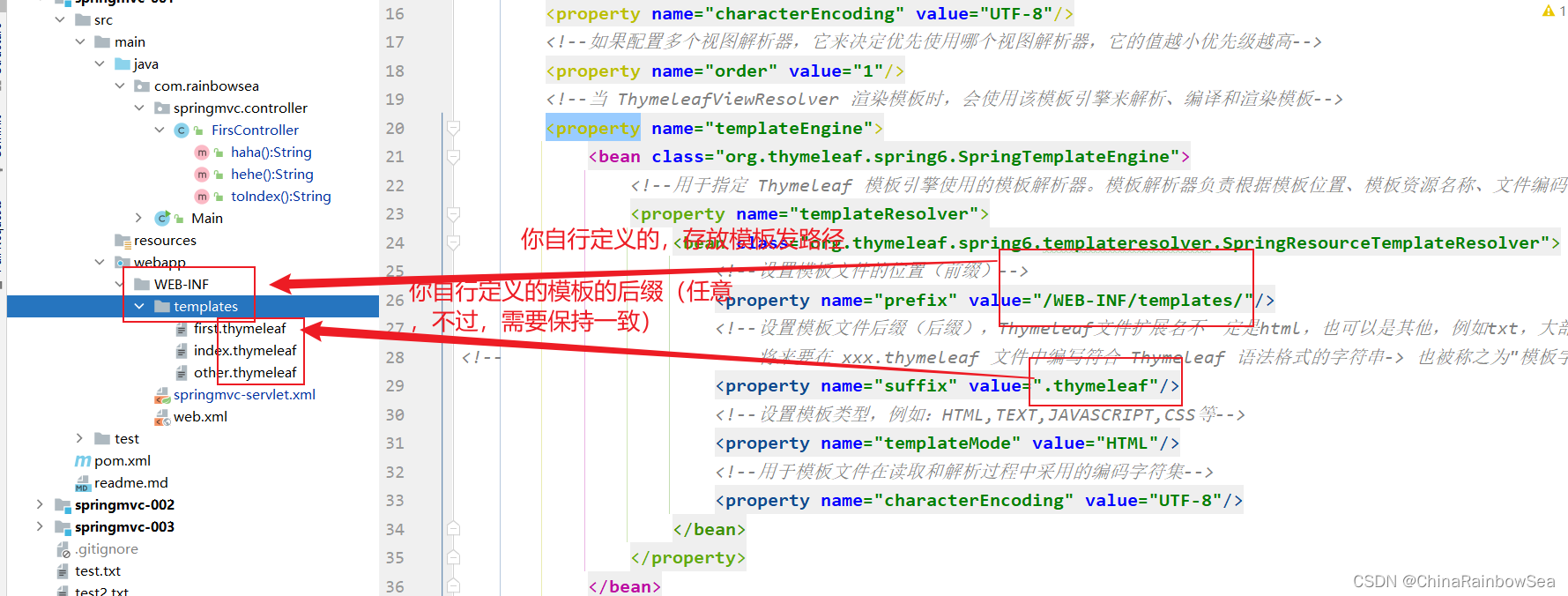
在WEB-INF目录下新建 templates目 录,在 templates 目录中新建 thymeleaf 文件,例如:first.thymeleaf,并提供以下代码:
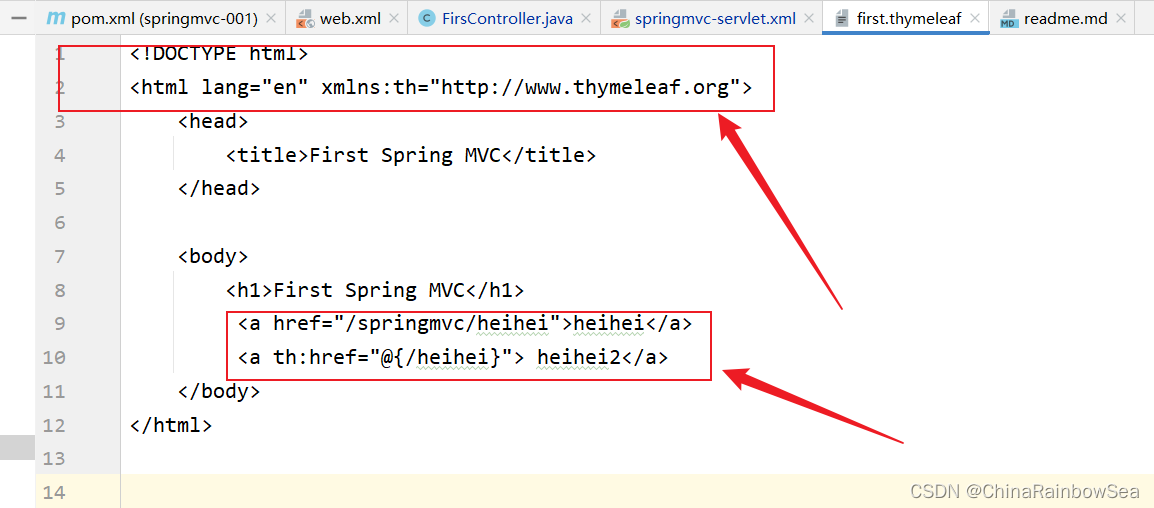
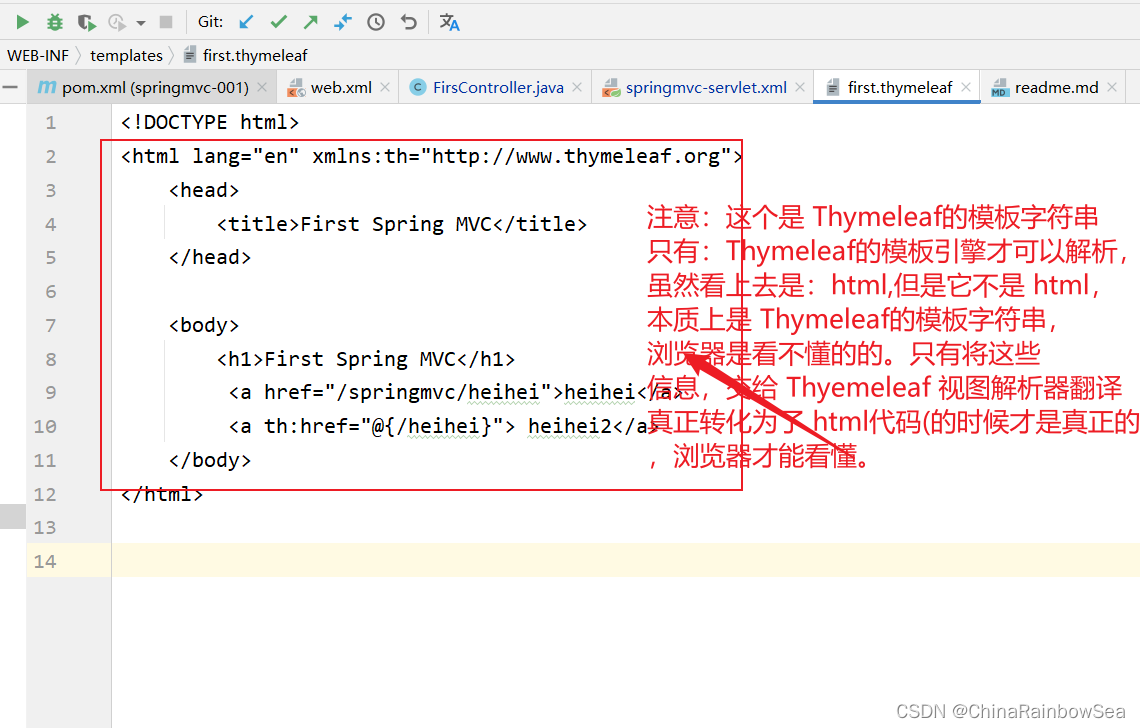
注意:这个是 Thymeleaf的模板字符串,只有:Thymeleaf的模板引擎才可以解析,虽然看上去是:html,但是它不是 html,本质上是 Thymeleaf的模板字符串,浏览器是看不懂的的。只有将这些信息,交给 Thyemeleaf 视图解析器翻译真正转化为了 html代码(的时候才是真正的html),
,浏览器才能看懂。至于为什么是 html 呢,是因为这里我们配置的 Thymeleaf 视图解析器,就是配置的翻译为
html文件,当然也可以配置翻译为其它的类型的文件。
3.7 第七步:控制器 FirstController 处理请求返回逻辑视图名称
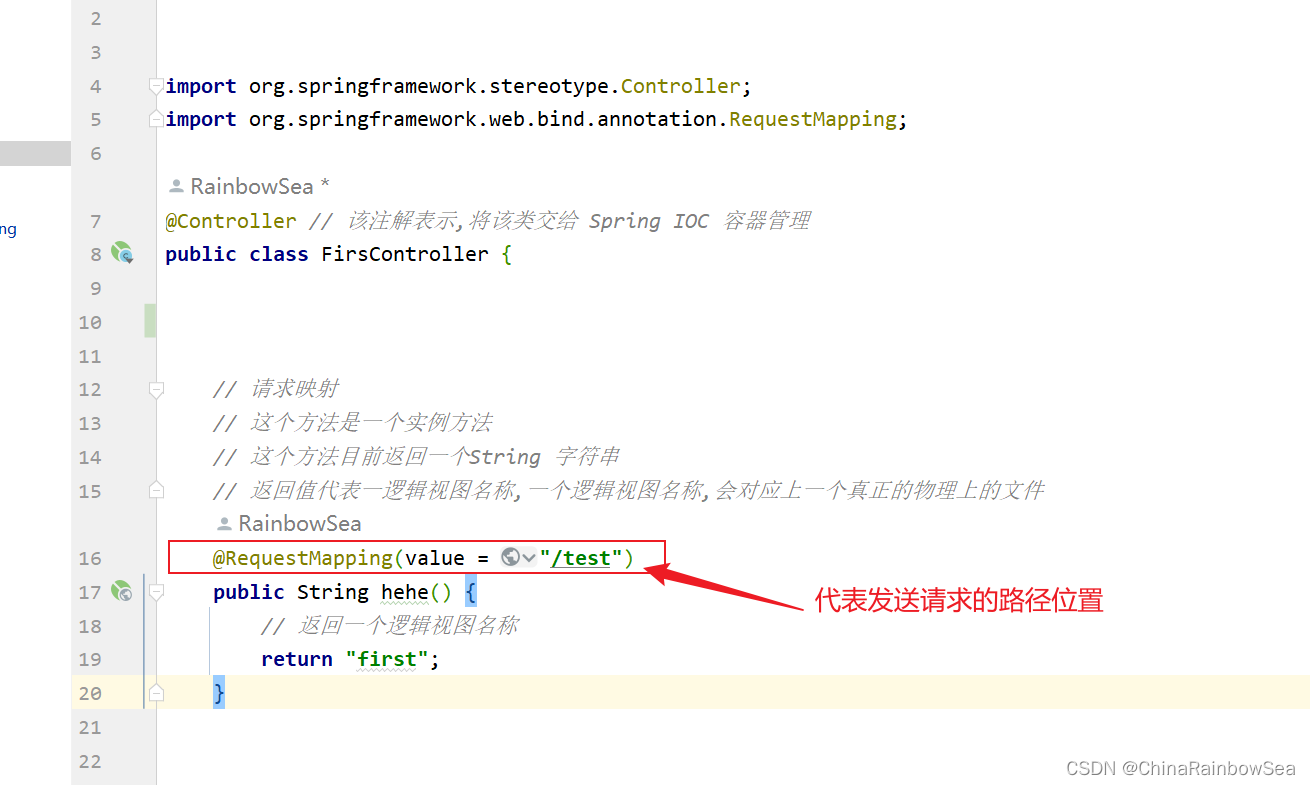
package com.rainbowsea.springmvc.controller;import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;@Controller // 该注解表示,将该类交给 Spring IOC 容器管理
public class FirsController {// 请求映射// 这个方法是一个实例方法// 这个方法目前返回一个String 字符串// 返回值代表一逻辑视图名称,一个逻辑视图名称,会对应上一个真正的物理上的文件@RequestMapping(value = "/test")public String hehe() {// 返回一个逻辑视图名称return "first";}}@RequestMapping 注解标识:该请求的路径映射。
注意:方法名随意,但是返回类型一定要是String 字符串的类型,因为这个返回值是一个逻辑视图的名称 是一个字符串。
什么是逻辑视图名称
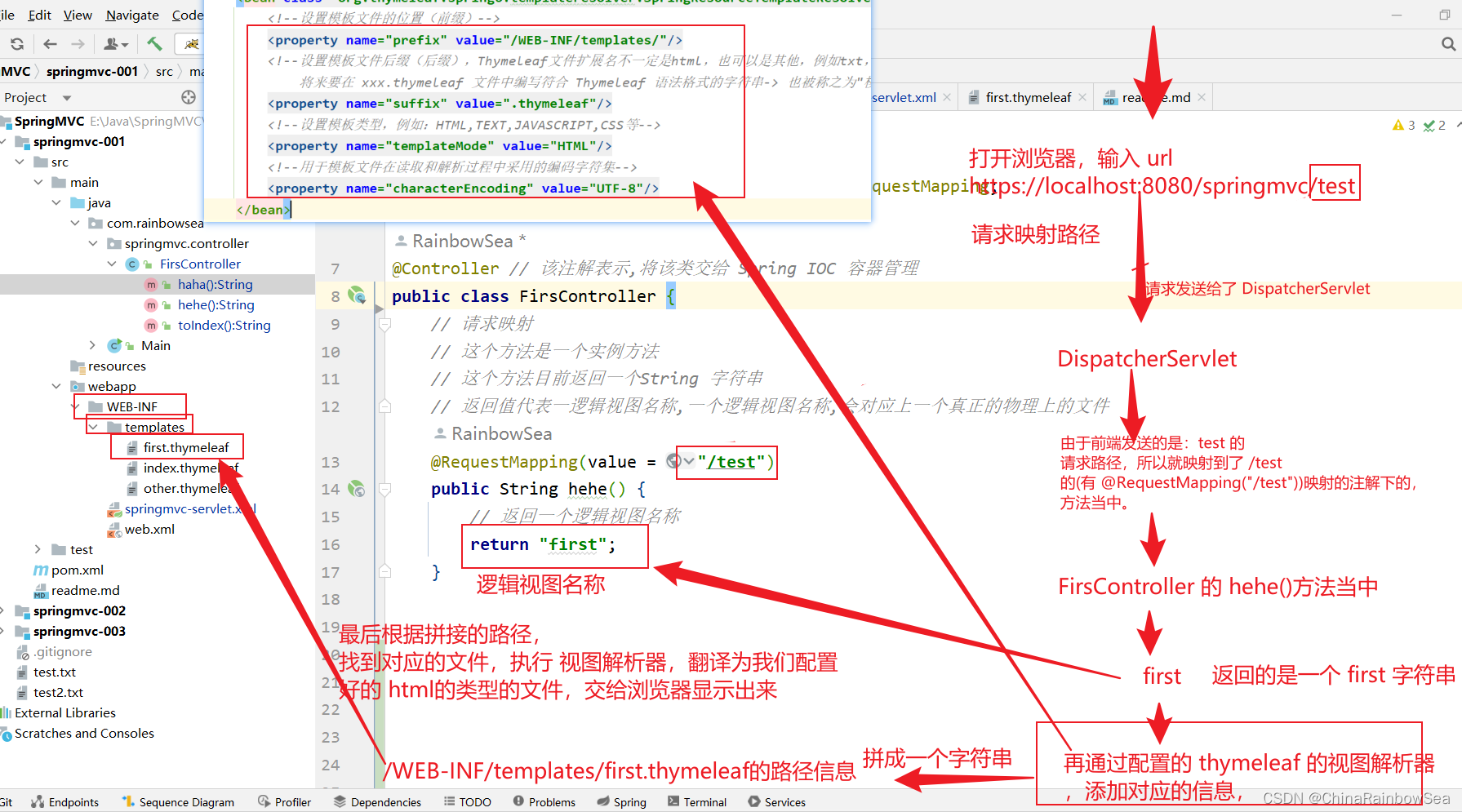
最终会将逻辑视图名称转换为物理视图名称
> 逻辑视图名称:first
> 物理视图名称: 前缀 + first + 后缀
> 最终路径是:/WEB-INF/templates/first.thymeleaf
> 使用Thymeleaf 模板引擎,将/WEB-INF/templates/first.thymeleaf转换成 html代码,最终响应到浏览器端
3.8 第八步:运行 Tomcat 测试
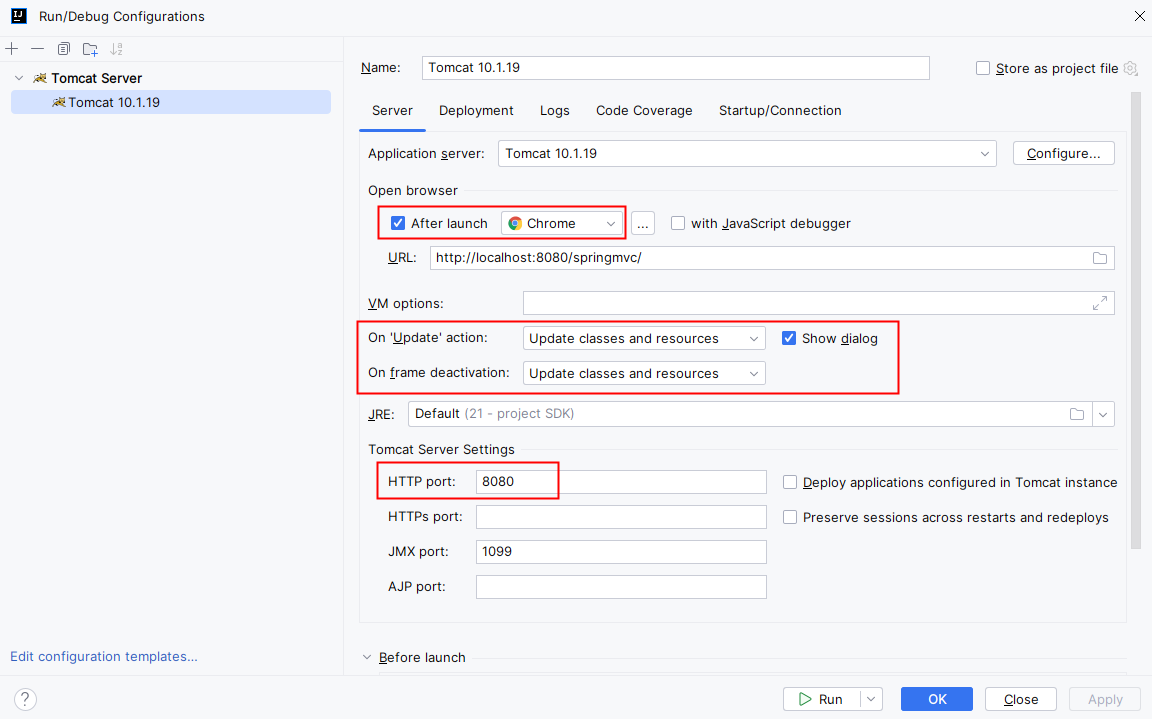
注意:由于我们这里导入的是:jakarta.servlet 包下的 servelt 所以要用,Tomcat 9 以上的版本才行,这里我使用的是 Tomcat 10
第一步:配置Tomcat服务器
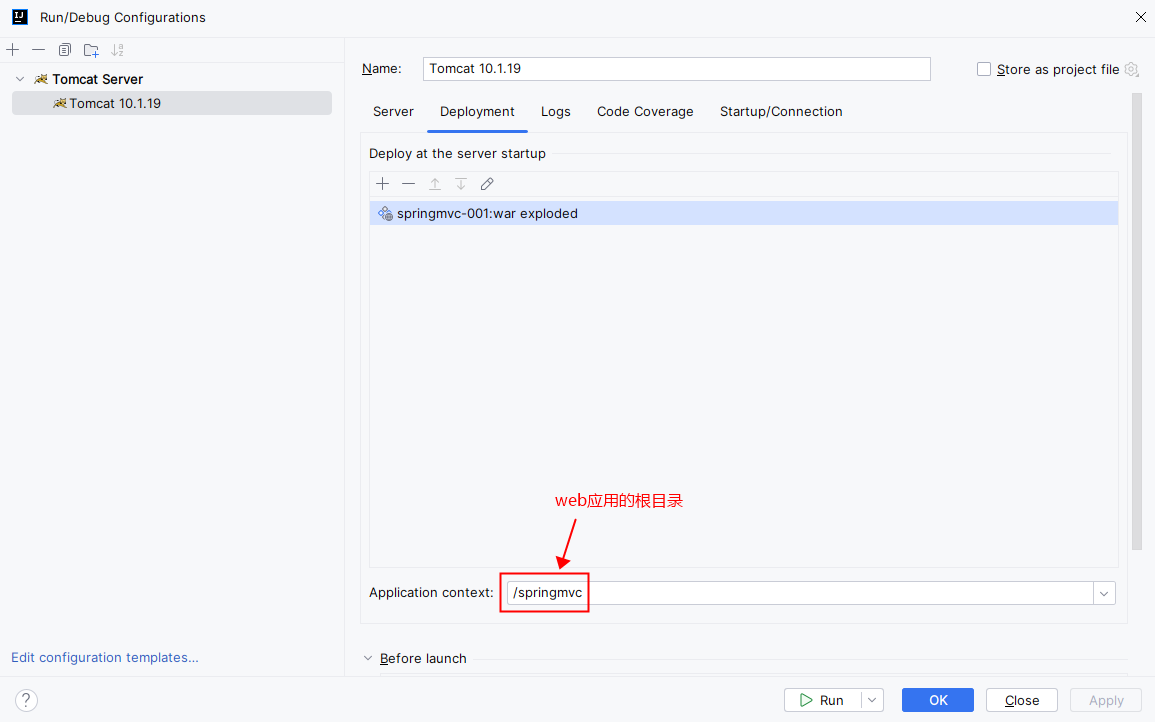
第三步:启动Tomcat服务器。如果在控制台输出的信息有中文乱码,请修改tomcat服务器配置文件:apache-tomcat-10.1.19\conf\logging.properties
第四步:打开浏览器,在浏览器地址栏上输入地址:http://localhost:8080/springmvc/test
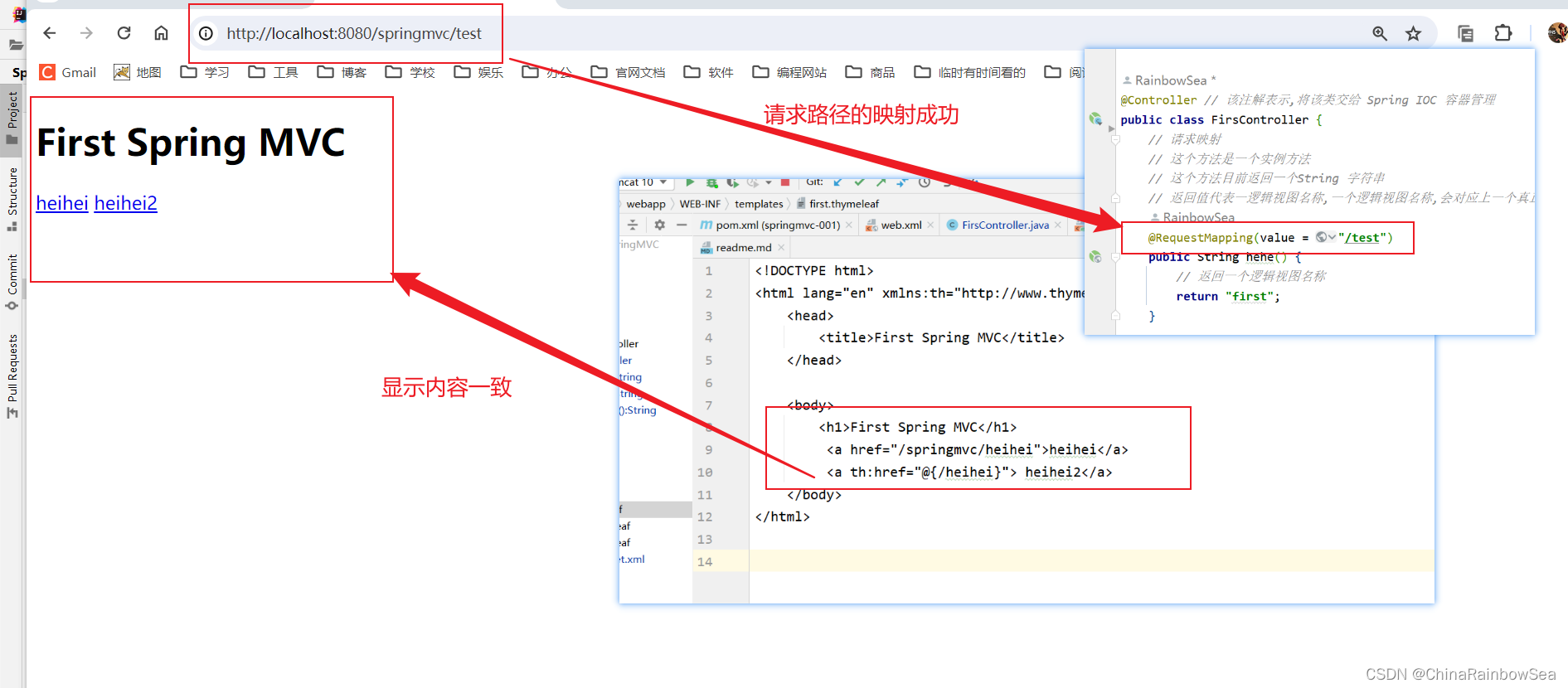
3.9 执行流程总结:
- 浏览器发送请求:http://localhost:8080/springmvc/haha
- SpringMVC的前端控制器DispatcherServlet接收到请求
- DispatcherServlet根据请求路径 /haha 映射到 FirstController#名字随意(),调用该方法
- FirstController#名字随意() 处理请求
- FirstController#名字随意() 返回逻辑视图名称 first 给视图解析器
- 视图解析器找到 /WEB-INF/templates/first.thymeleaf文件,并进行解析,生成视图解析对象返回给前端控制器DispatcherServlet
- 前端控制器DispatcherServlet响应结果到浏览器。
4. 第一个 Spring MVC 程序优化:
4.1 在web.xml 配置文件中 ,手动自定 spring mvc 的配置文件
Spring MVC 中的配置文件,名字是可以指定的,位置也是可以指定的,怎么指定?
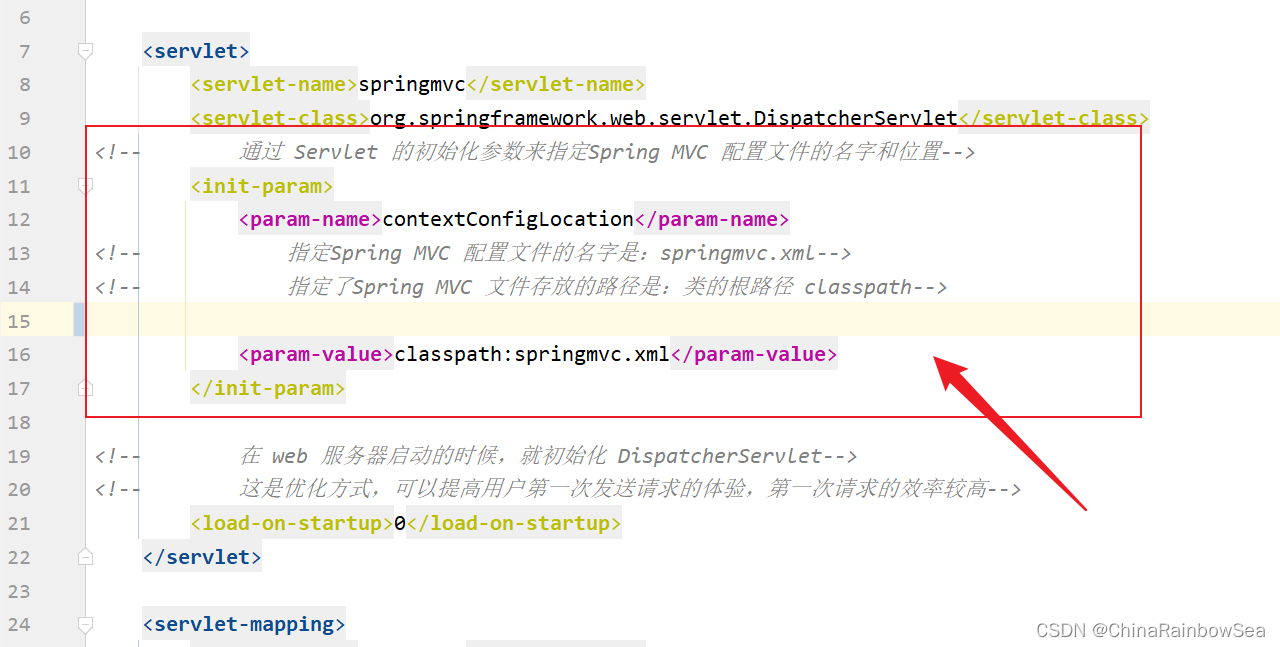
设置 DispatcherServlet 的初始化参数
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!-- 通过 Servlet 的初始化参数来指定Spring MVC 配置文件的名字和位置--><init-param><param-name>contextConfigLocation</param-name>
<!-- 指定Spring MVC 配置文件的名字是:springmvc.xml-->
<!-- 指定了Spring MVC 文件存放的路径是:类的根路径 classpath-->
<!-- 这里爆红是:idea的误报--><param-value>classpath:springmvc.xml</param-value></init-param>
建议: 在 web 服务器启动的时候,初始化 DispatcherServlet,这样用户第一次请求时,效率较高。体验好
重点:SpringMVC 配置文件的名字和路径是可以手动设置的,如下:
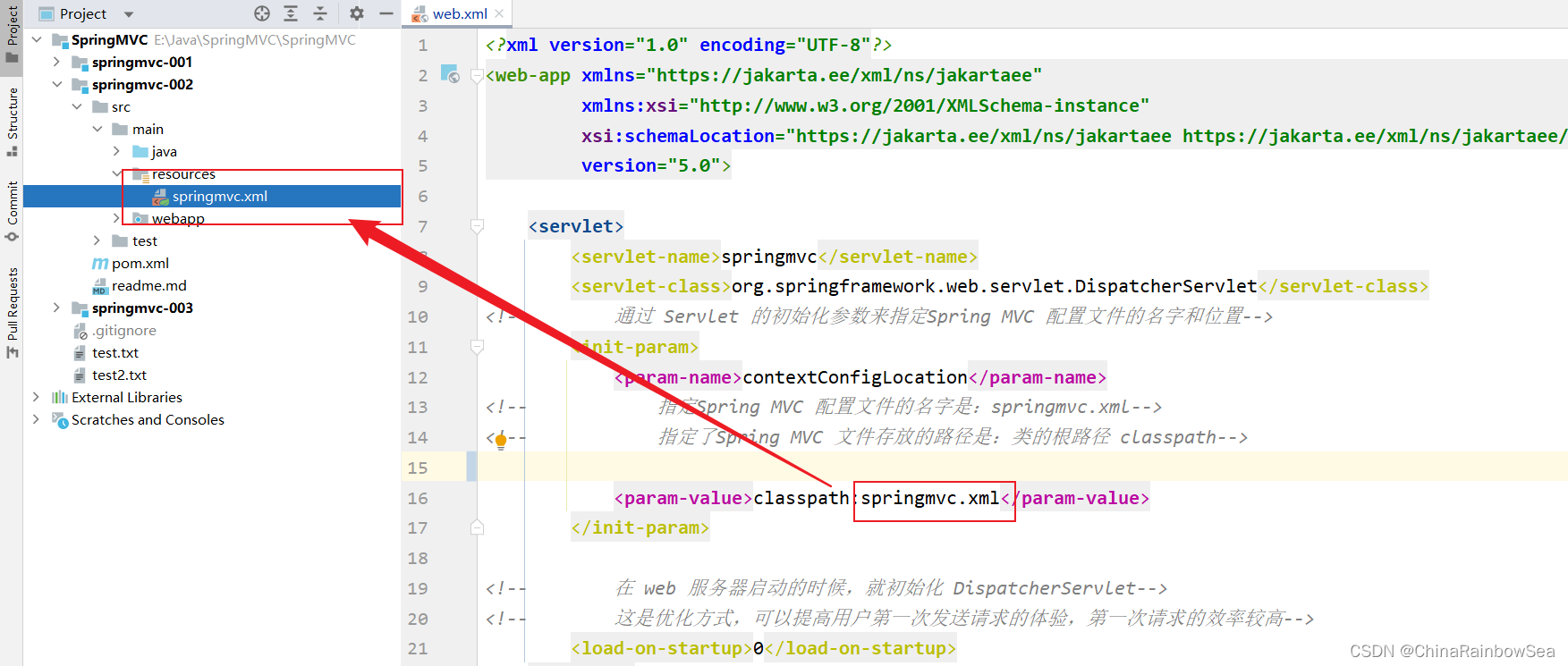
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="https://jakarta.ee/xml/ns/jakartaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="https://jakarta.ee/xml/ns/jakartaee https://jakarta.ee/xml/ns/jakartaee/web-app_5_0.xsd"version="5.0"><servlet><servlet-name>springmvc</servlet-name><servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!-- 通过 Servlet 的初始化参数来指定Spring MVC 配置文件的名字和位置--><init-param><param-name>contextConfigLocation</param-name>
<!-- 指定Spring MVC 配置文件的名字是:springmvc.xml-->
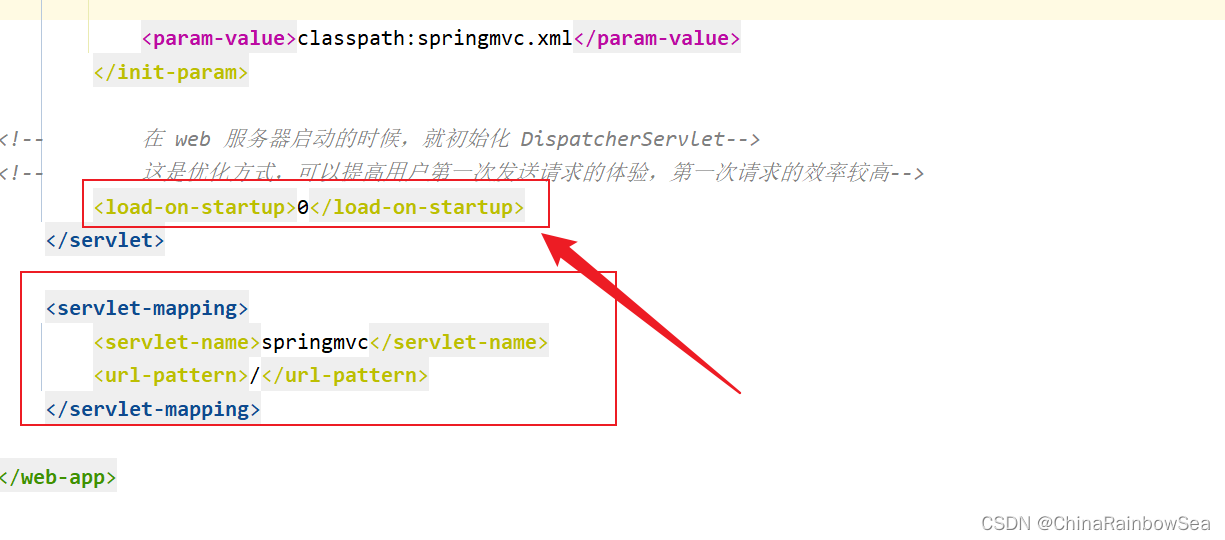
<!-- 指定了Spring MVC 文件存放的路径是:类的根路径 classpath--><param-value>classpath:springmvc.xml</param-value></init-param><!-- 在 web 服务器启动的时候,就初始化 DispatcherServlet-->
<!-- 这是优化方式,可以提高用户第一次发送请求的体验,第一次请求的效率较高--><load-on-startup>0</load-on-startup></servlet><servlet-mapping><servlet-name>springmvc</servlet-name><url-pattern>/</url-pattern></servlet-mapping></web-app>
通过来设置SpringMVC配置文件的路径和名字。在DispatcherServlet的init方法执行时设置的。
1建议加上,这样可以提高用户第一次访问的效率。表示在web服务器启动时初始化DispatcherServlet。
下面是 :springmvc.xml 的编写:
4.2 配置 thymeleaf 翻译为 html 的模板
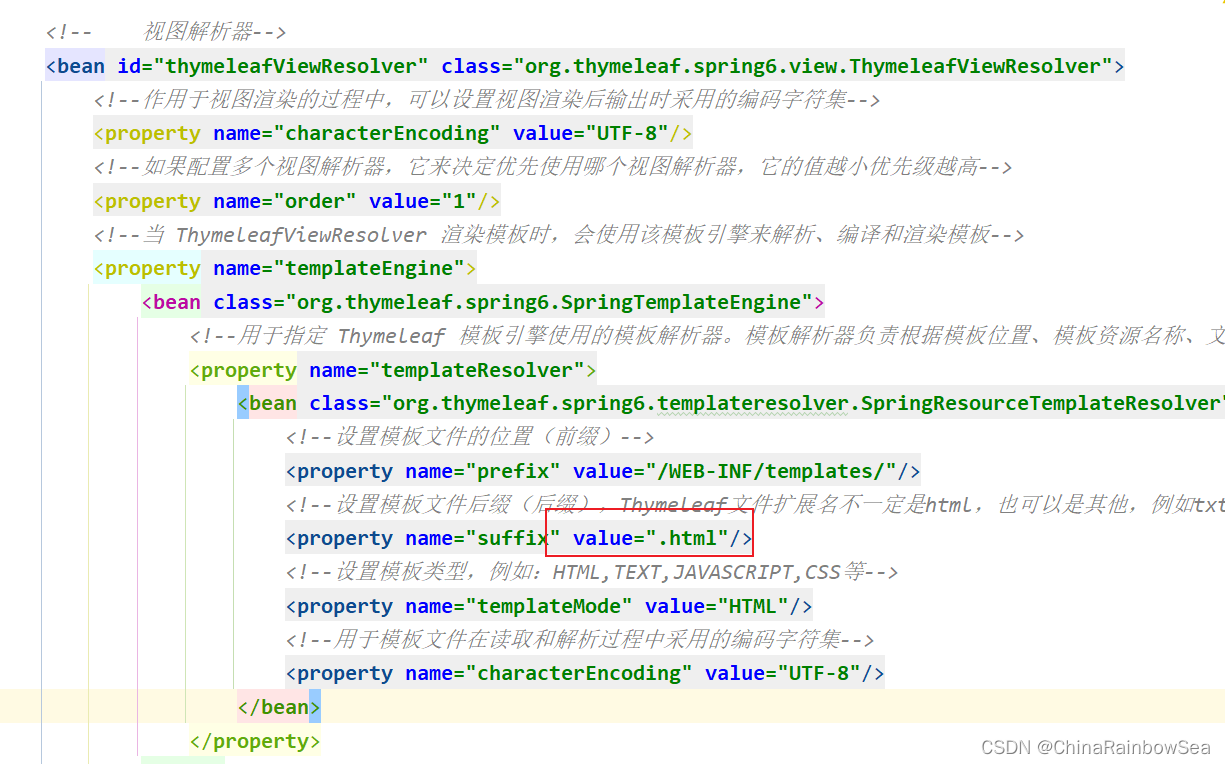
这里我们将 thymeleaf 视图解析器的后缀改为:
WEB-INF目录下新建templates目录,在templates目录中新建html文件,例如:first.html,并提供以下代码:
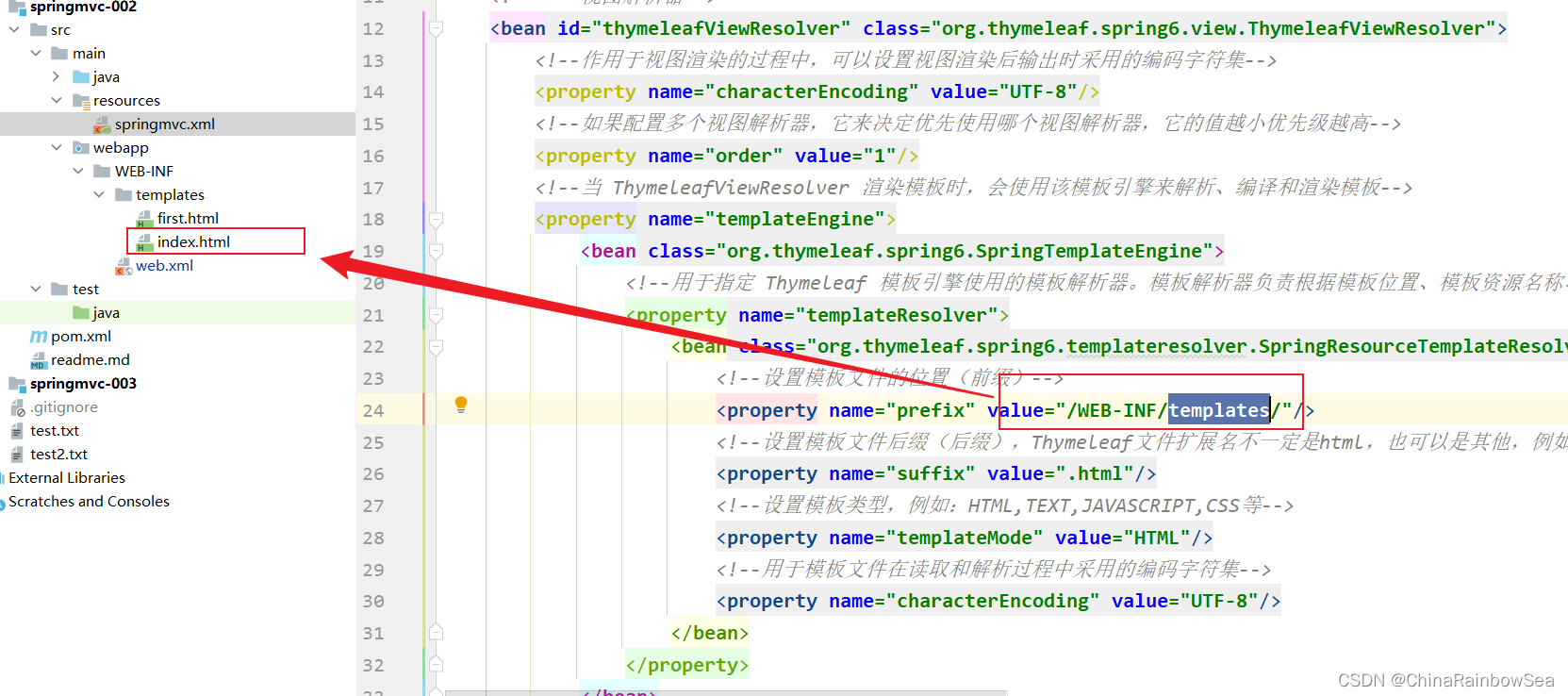
对于每一个Thymeleaf文件来说 xmlns:th=“http://www.thymeleaf.org” 是必须要写的,为了方便后续开发,可以将其添加到html模板文件中:
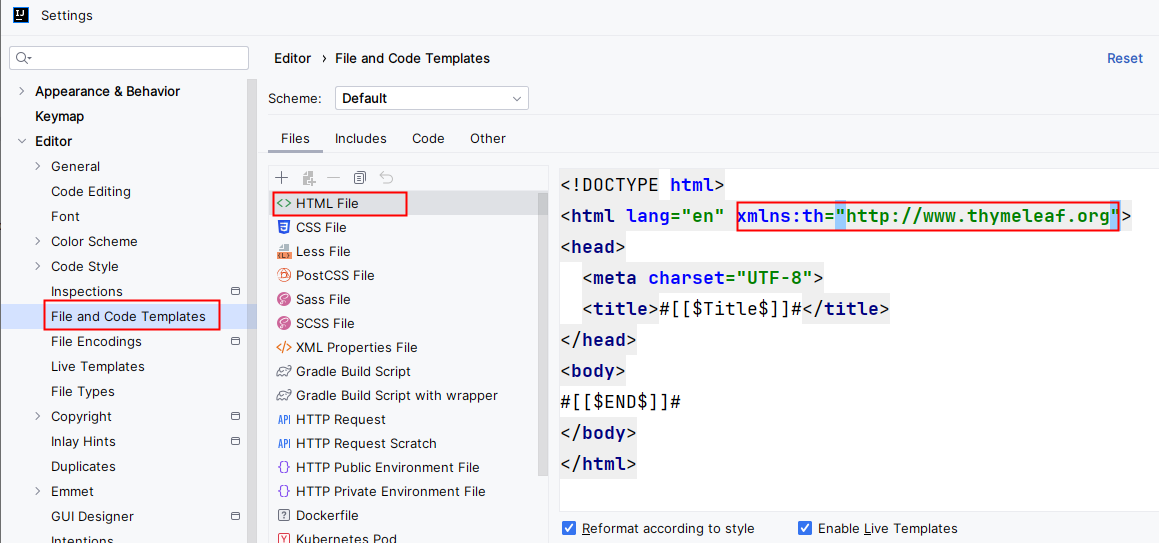
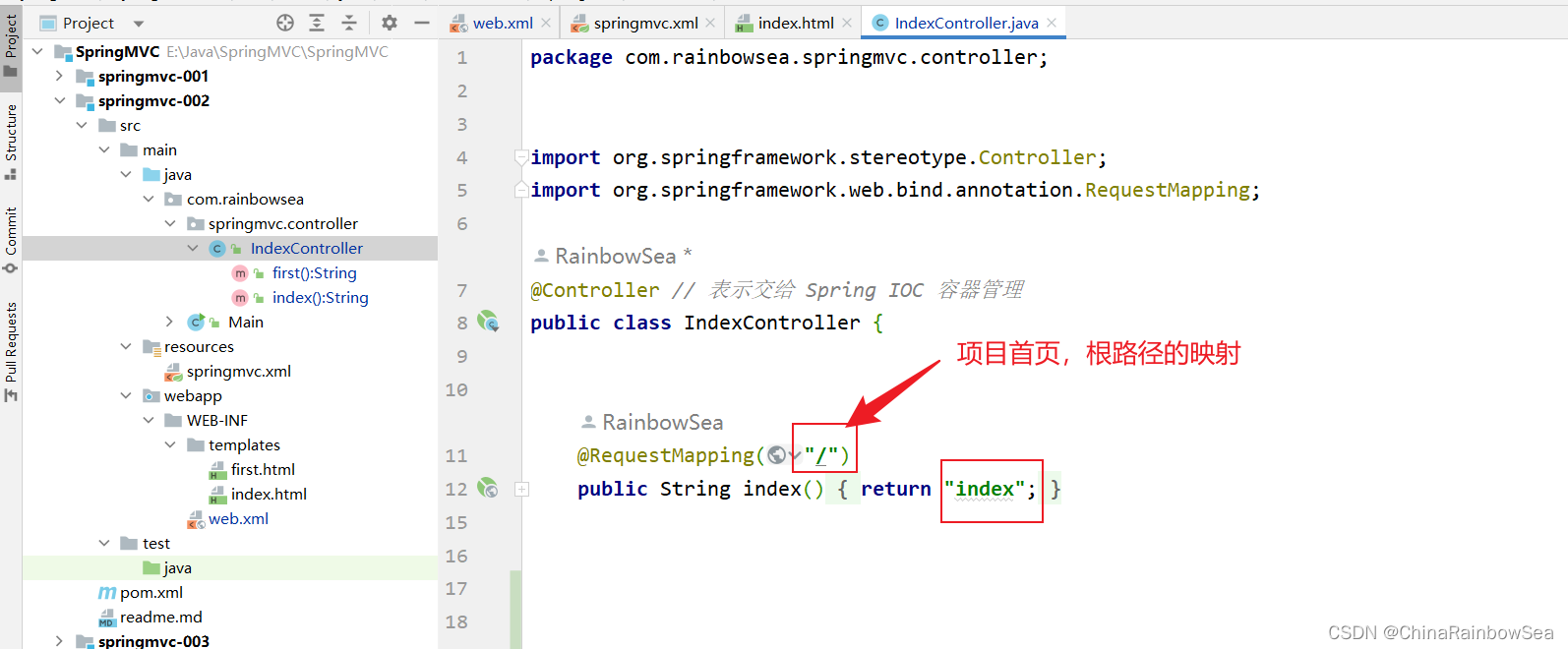
4.3 编写 IndexController 定义个“首页”
package com.rainbowsea.springmvc.controller;import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;@Controller // 表示交给 Spring IOC 容器管理
public class IndexController {@RequestMapping("/")public String index() {return "index";}}表示请求路径如果是:http://localhost:8080/springmvc/ ,则进入 /WEB-INF/templates/index.html 页面。
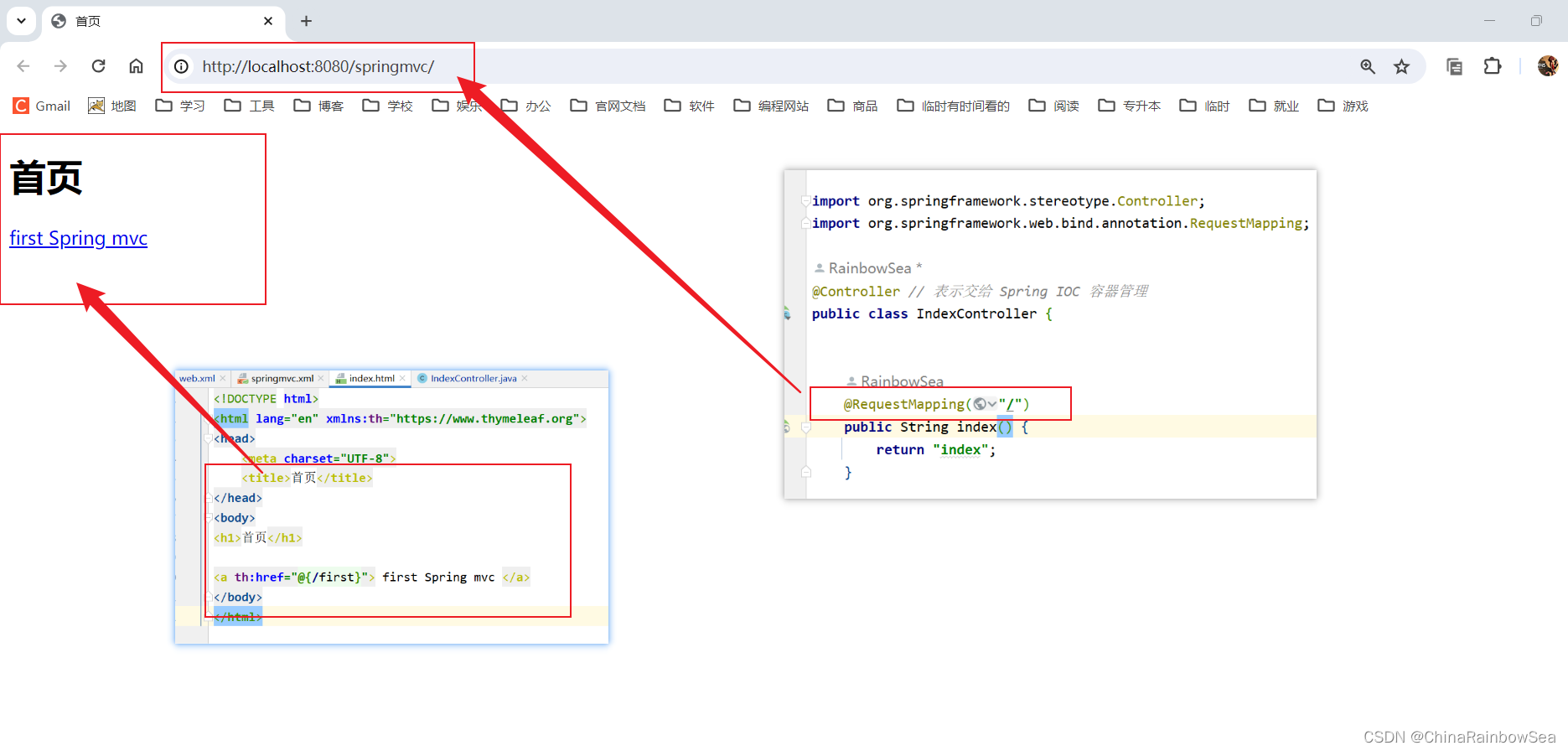
这就是项目的首页效果!!!!!
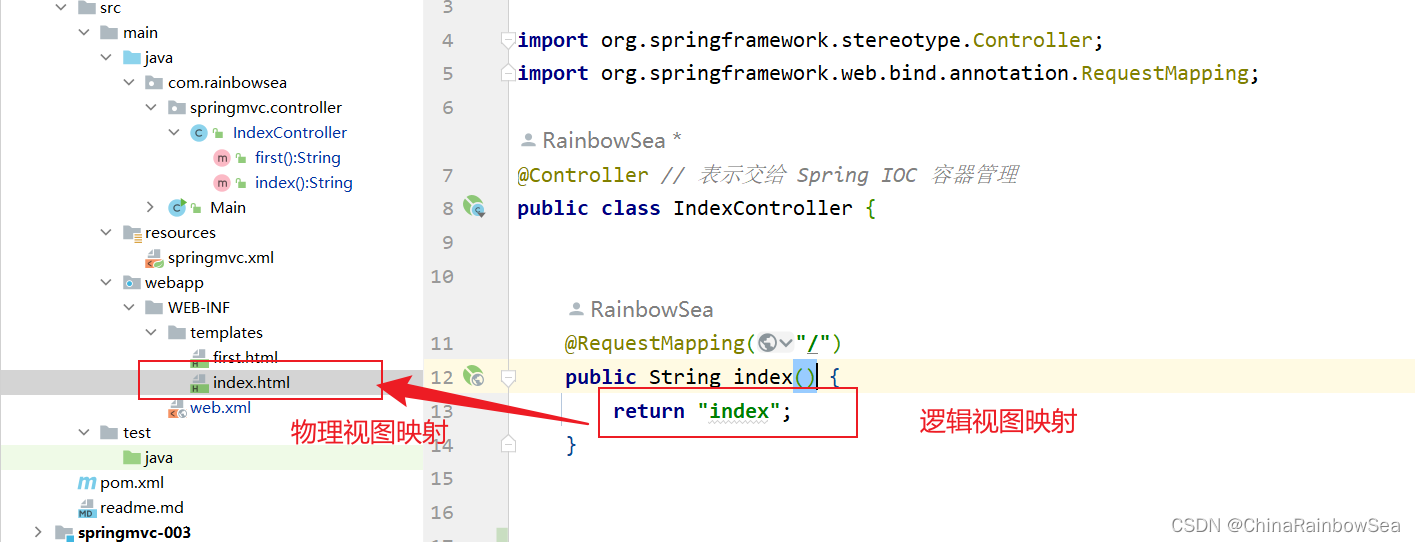
index.html 的编写
<!DOCTYPE html>
<html lang="en" xmlns:th="https://www.thymeleaf.org">
<head><meta charset="UTF-8"><title>首页</title>
</head>
<body>
<h1>首页</h1><a th:href="@{/first}"> first Spring mvc </a>
</body>
</html>
4.4 测试
部署到web服务器,启动web服务器,打开浏览器,在地址栏上输入:http://localhost:8080/springmvc/
5. 总结:
总之,与 Servelt 开发相比,Spring MVC 框架可以帮我们节省很多时间和精力,减少代码的复杂度,更加专注于业务开发。同时,也提供了更多的功能和扩展性,可以更好地满足企业级应用的开发需求。
servlet依赖(scope设置为 provided,表示这个依赖最终由第三方容器来提供)
注意:一般情况下,我们添加了webapp ,IDE是会自动给我们添加上一个小蓝点的,如果没有的话,需要我们自己手动添加。
DispatcherServlet 是 Spring MVC 框架为我们提供的最核心 的类。它是整个 Spring MVC 框架的前端控制器。负责接收 HTTP 请求,将请求路由到处理程序,处理响应信息,最终将响应返回给客户端。DispatcherServlet 是 Web 应用程序的主要入口之一,
视图解析器:视图解析器(View Resolver) 的作用主要是将Controller 方法返回的逻辑视图名称解析成实际的视图对象。视图解析器将解析出的视图对象返回给 DispatcherServlet,并最终由 DispatcherServlet 将该视图对象转化为响应结果,呈现给用户
编写FirsController ,在类上标注 @Controller 注解,纳入IOC容器的管理,当然,也可以采用 @Component注解 进行标注, @Controller 只是 @Component 注解的别名
Spring MVC 中的配置文件,名字是可以指定的,位置也是可以指定的,怎么指定? 设置 DispatcherServlet 的初始化参数```xml<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <!-- 通过 Servlet 的初始化参数来指定Spring MVC 配置文件的名字和位置--><init-param><param-name>contextConfigLocation</param-name> <!-- 指定Spring MVC 配置文件的名字是:springmvc.xml--> <!-- 指定了Spring MVC 文件存放的路径是:类的根路径 classpath--> <!-- 这里爆红是:idea的误报--><param-value>classpath:springmvc.xml</param-value></init-param> ``` 建议: 在 web 服务器启动的时候,初始化 DispatcherServlet,这样用户第一次请求时,效率较高。体验好
6. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
