餐饮业网站建设招标书郴州市人力资源考试网官网
目录
一、共享内存
1、基本原理
2、共享内存的创建
3、共享内存的释放
4、共享内存的关联
5、共享内存的去关联
6、查看IPC资源
二、完整通信代码
三、共享内存的特点
四、信号量
1、相关概念
2、信号量概念
进程间通信的本质就是让不同的进程看到同一个资源。而前面我们讲到了进程通信的最基础,最传统的方法——管道。我们知道了,无论是匿名管道还是命名管道,它们让不同进程看到同样的资源的方法,就是通过访问同样的文件来看到同样的资源。
进程间是相互独立的,因此进程的各种数据是存储在物理内存的不同区域的。那么,如果两个不同的进程能够访问到同一块内存空间,是不是就相当于看到了同样的资源。那么有没有这样的方法呢?答案是肯定的,system V中的共享内存就是这样的一种进程间通信的方法。
一、共享内存
1、基本原理
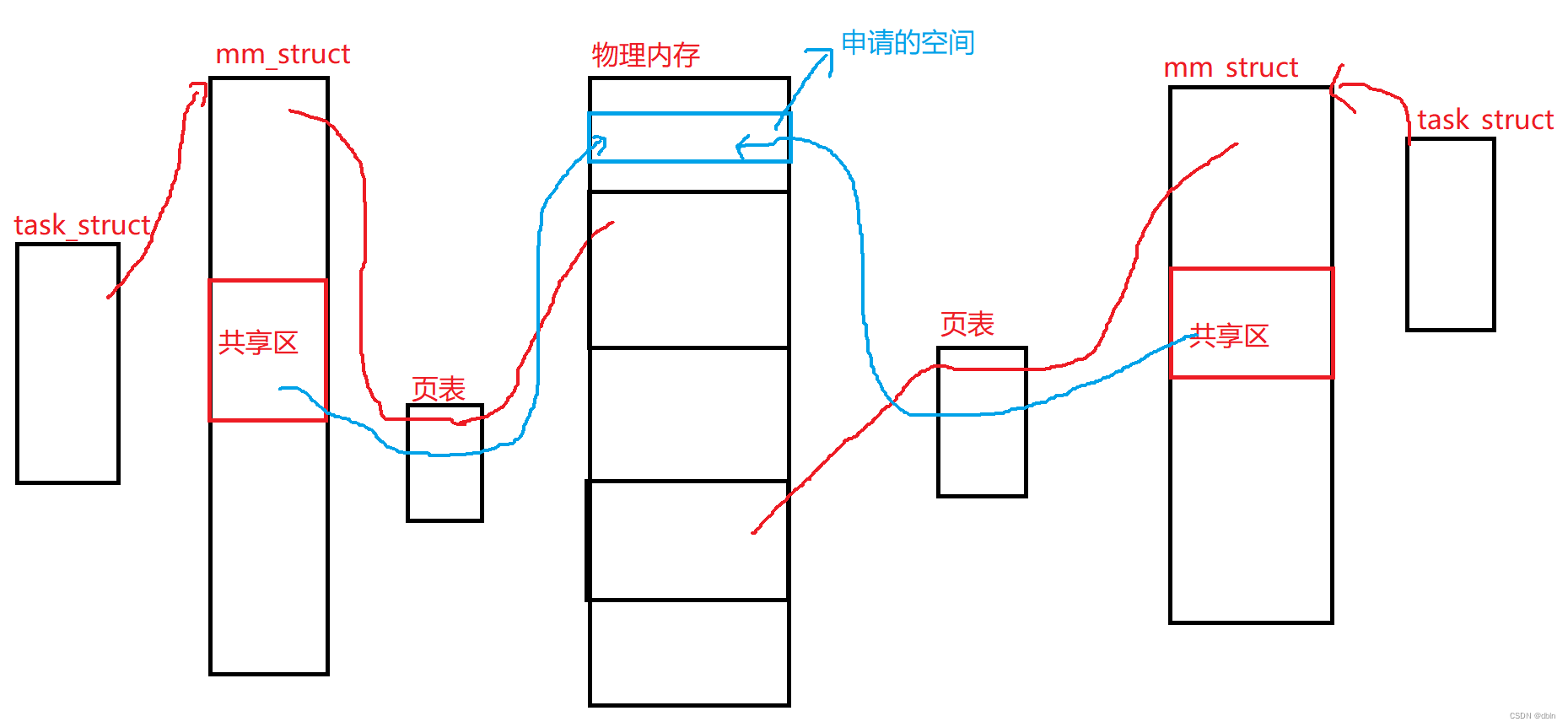
在学习了进程地址空间后,我们知道,在堆和栈之间有一块空间叫做共享区。
我们在物理内存中申请了一块空间,然后通过页表将这块空间,映射到不同进程的进程地址空间的共享区中, 然后再将映射到共享区的地址返回给各自的进程。那么,不同的进程就可以通过拿到虚拟地址,找到共享区,接着通过页表映射,找到物理内存。
这样,不同的进程就能够看到同一块空间了。这种工作方式就叫做共享内存。
如果想结束通信,我们直接取消进程和内存的映射关系,释放共享内存。
共享内存的提供者是操作系统,而操作系统中可能会有多个共享内存,所以操作系统必定需要将各个共享内存管理起来,怎么管理呢?当然是,先描述,再组织。
所以,共享内存包括了共享内存块和描述共享内存的内核数据结构。
2、共享内存的创建
shmget :作用是用来创建共享内存。返回值:shmid:共享内存的用户层标识符(类似于fd)。
#include <sys/ipc.h>
#include <sys/shm.h>int shmget(key_t key, size_t size, int shmflg);RETURN VALUEOn success, a valid shared memory identifier is returned. On errir, -1 is returned, and errno is set to indicate the error参数说明:
size:创建的共享内存的大小。
shmflg:通常被设置成两个选项: IPC_CREAT、 IPC_EXCL
IPC_CREAT:共享内存不存在,则创建,如果存在则直接获取。IPC_EXCL:无法单独使用IPC_CREAT | IPC_EXCL:如果不存在就创建,如果存在就出错返回。
key:当一个进程将共享内存创建好了,而与之通信的另一个进程怎么保证看到的就是我创建的共享内存呢?key值就可以解决这个问题。
OS中一定会存在很多的共享内存,共享内存本质就是在内存中申请一块空间,而key能对其进行唯一标识。进程如果在内存中创建了共享内存,为了让共享内存在系统中保证唯一的,通过key来进行标识,所以只要让另一个进程也看到同一个key,那么不同的进程就能看到同一个共享内存。而key值就在描述共享内存的内核结构体struct shm中。
那么,我们应该给key传入什么值呢:使用 ftok函数来形成key。
ftok:
#include <sys/types.h>
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);RETURN VALUEOn success, the generated key_t value is returned. On failure -1 is returned, with errno indicating the error as for the stat(2) system call.3、共享内存的释放
因为共享内存是由操作系统提供并管理的,所以共享内存的生命周期是随操作系统,而不是随进程的。所以我们在使用完共享内存后,需要用户亲自删除。
1、使用命令删除:ipcrm -m shmid
2、使用代码函数删除
shmctl:作用是删除共享内存。参数:shmid:删除共享内存的标识符,cmd:控制种类(一般使用 IPC_RMID),buf:控制共享内存的数据结构,可以简单设置为空(nullptr)。
返回值:0表示成功,-1表示失败。
#include <sys/ipc.h>#include <sys/shm.h>int shmctl(int shmid, int cmd, struct shmid_ds *buf);4、共享内存的关联
shmat:作用是将共享内存与对应的进程关联起来。我们把进程和共享内存建立映射关系的操作称为挂接。
#include <sys/types.h>#include <sys/shm.h>void *shmat(int shmid, const void *shmaddr, int shmflg);参数:shmaddr:指定虚拟地址,但是我们并不了解,直接设置为nullptr即可;shmflg:读取权限,默认为0。
5、共享内存的去关联
shmdt:作用是将共享内存与对应的进程的关联解除。我们把取消进程和内存的映射关系的操作称为去关联。shmaddr:指定虚拟地址。
#include <sys/types.h>
#include <sys/shm.h>
int shmdt(const void *shmaddr);RETURN VALUE
On success shmdt() returns 0; on error -1 is returned, and errno is set to indi‐cate the cause of the error.6、查看IPC资源
1、查看共享内存:ipcs -m bytes:共享内存大小(最后是页PAGE:4096的整数倍) nattch:与该共享内存关联的进程个数
owner:共享内存的拥有者。 perms:拥有者对于该共享内存的权限

2、删除共享内存:ipcsrm -m shmid
3、ipcs -q:查看消息队列
4、ipcs -s:查看信号量
二、完整通信代码
shmcoom.hpp
#pragma once#include<iostream>
#include<cassert>
#include<cstring>
#include<sys/types.h>
#include<sys/stat.h>
#include<sys/shm.h>
#include<sys/ipc.h>
#include<unistd.h>using namespace std;#define SHM_SIZE 4096
#define PATH_NAME "/home/zdl"
#define PROJ_ID 0x66server.cc
#include "shmcomm.hpp"int main()
{// 1.创建key值key_t k = ftok(PATH_NAME, PROJ_ID);assert(k != -1);printf("key: %d\n", k);// 2.创建共享内存int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666);if (shmid == -1){perror("shmget");exit(1);}// 3.关联共享内存char *shmaddr = (char *)shmat(shmid, nullptr, 0);if (shmaddr == nullptr){perror("shmat");exit(2);}// 4.进程间通信for (;;){printf("%s\n", shmaddr);if (strcmp(shmaddr, "quit") == 0)break;sleep(1);}// 5.去关联int m = shmdt(shmaddr);assert(m != -1);(void)m;// 6。删除共享内存int n = shmctl(shmid, IPC_RMID, nullptr);assert(n != -1);(void)n;return 0;
}client.cc
#include "shmcomm.hpp"int main()
{// 获取key值key_t k = ftok(PATH_NAME, PROJ_ID);assert(k != -1);printf("key: %d\n", k);// 获取共享内存int shmid = shmget(k, SHM_SIZE, IPC_CREAT);if (shmid == -1){perror("shmget");exit(1);}// 挂接char *shmaddr = (char *)shmat(shmid, nullptr, 0);if (shmaddr == nullptr){perror("shmat");exit(2);}// 进程间通信int count = 0;while (count < 10){snprintf(shmaddr, SHM_SIZE - 1, "hello server,我是另一个进程,正在和你通信,我的pid:%d count: %d",getpid(), count++);sleep(1);}strcpy(shmaddr, "quit");// 去关联int m = shmdt(shmaddr);assert(m != -1);(void)m;return 0;
}运行结果
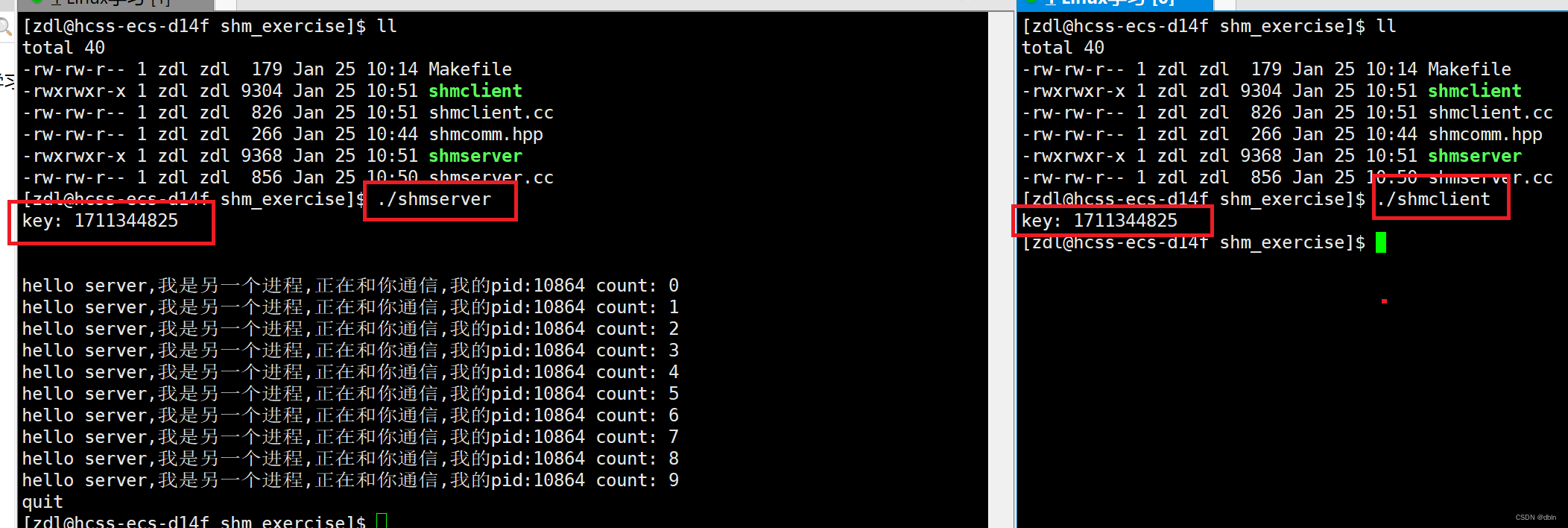
首先,我们看到的是,两个进程的key值相同,且shmserver在输入了quit后,进程退出,shmclient也退出。
三、共享内存的特点
优点:共享内存是所有进程间通信速度是最快的,因为共享内存是被双方所共享,只要写入对方就能立即看到,能大大减少数据的拷贝次数。
具体说明:
管道:我们知道,管道的本质是一个文件,所以我们必须像使用文件那样去使用管道,即我们想要通信就必须调用系统接口。具体如下图:
需要通过键盘输入到自己定义的缓冲区char buffer[],将数据拷贝到buffer中,调用write接口在把buffer里的数据拷贝到管道里,另一进程也有定义buffer缓冲区,调用read读取把数据从管道里读取到buffer里,再把数据显示到显示器上。
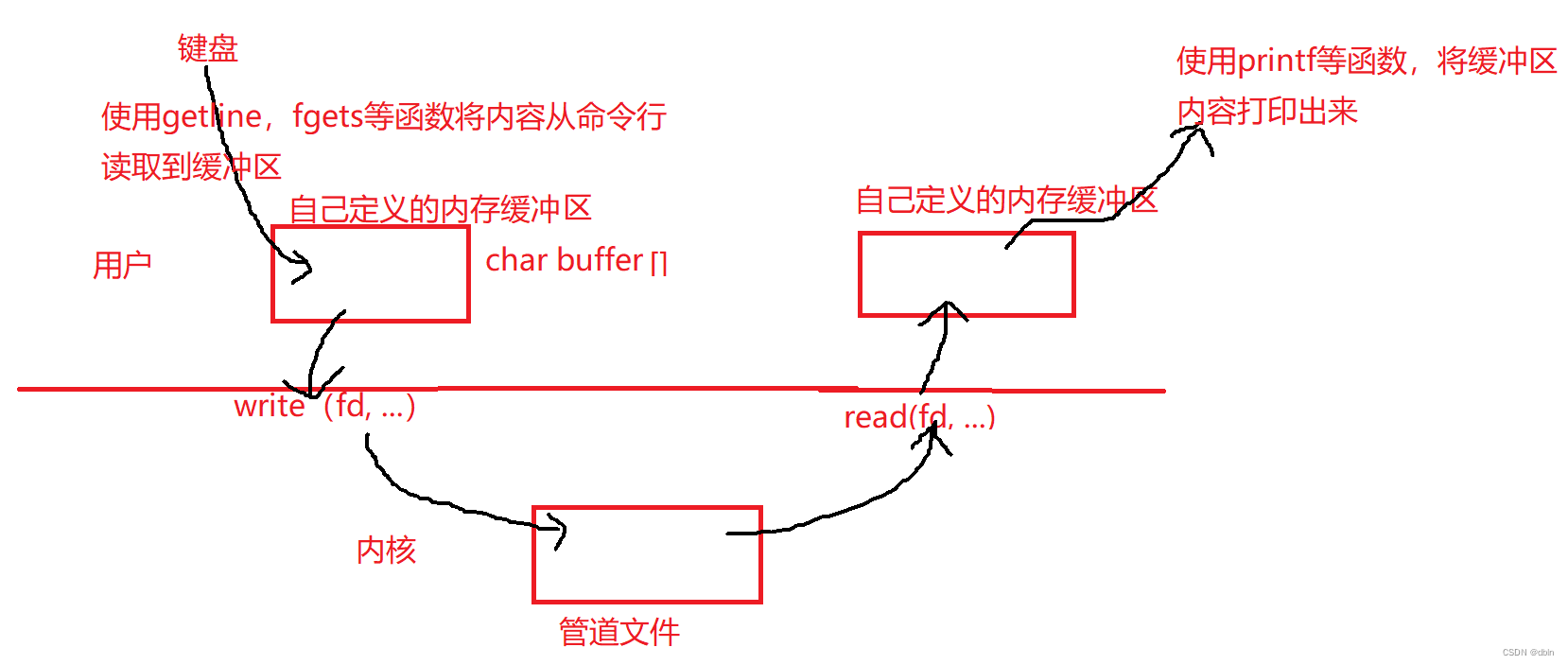
从上图,我们看到:使用管道要进行四次拷贝。
共享内存:只需要两次拷贝。
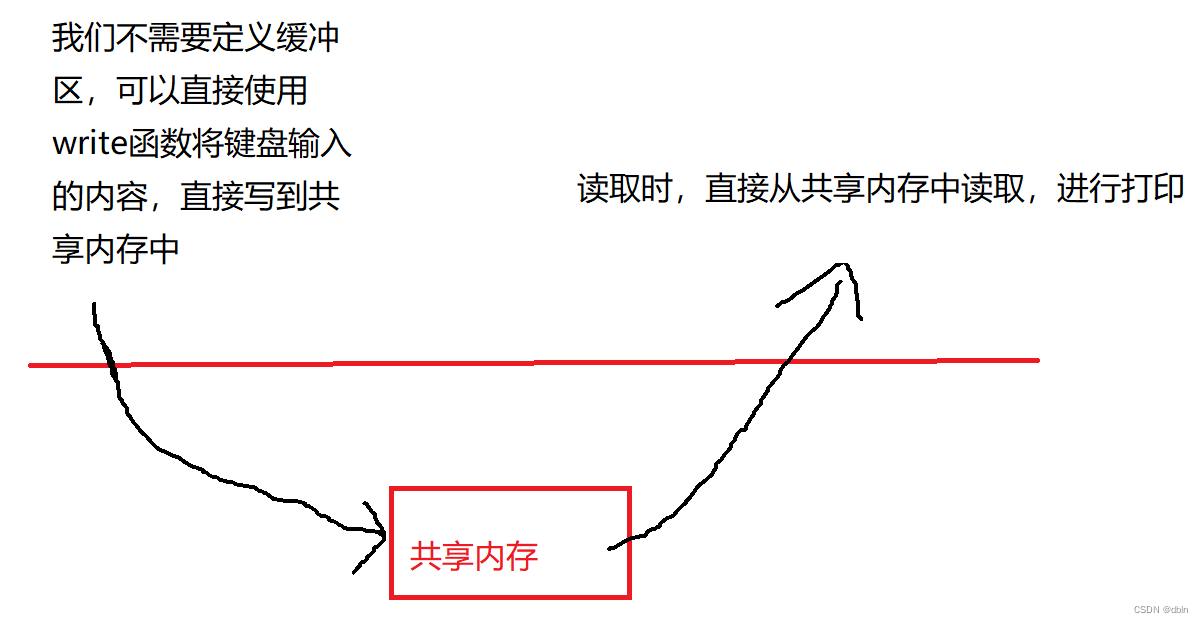
缺点:与管道相比,共享内存没有访问控制,会出现数据不一致问题。即:读取的一方不会因为内存中没有数据或数据还没有写入而停止读取,写入的一方也不会考虑另一方是否读取,而会一直写入。如果想做到访问控制需要用到信号量或使用管道,对共享内存进行保护。
四、信号量
1、相关概念
1、临界资源:我们把多个进程(执行流)看到的公共资源称为临界资源或互斥资源。
2、临界区:我们把自己的进程中,访问临界资源的那部分代码称为临界区。
所以说,如果我们不加保护地访问了临界资源,那么多个执行流在运行时会互相干扰,而在非临界区多个执行流互不影响。
3、互斥:为了更好地保护临界资源,我们要让多个执行流,在任意时刻,只允许一个执行流进入临界资源,去访问临界资源,这种方式就称为互斥。
4、原子性:只要两态,要么不做、要么做完,没有中间状态。
2、信号量概念
引入:为了保护共享资源,我们必须保证进程间是互斥的。如果在同一时刻,不同的执行流要访问的是临界资源的不同区域,那么我们是允许它们同时进入共享内存进行资源访问的。比如,临界资源中有10个区域,那么我们最多就可以同时让10个执行流进入进行资源访问(这10个执行流能够并发地访问临界资源)。而当第11个执行流想要进入时,它就必须要等待,只有它需要的区域没有执行流在访问时,它才能去访问临界资源。
这时,我们就使用了信号量来对临界资源进行保护。
信号量:信号量的本质是一个计数器,通常用来表示临界资源中,资源数的多少。申请信号量实际上就是对临界资源的预定机制。信号量主要用于同步和互斥。
比如,还是上面的例子,信号量会是10,当有不同的10个执行流(访问临界资源的10个不同区域)想要访问临界资源时,它们会先申请信号量(信号量--),然后操作系统一定会在共享内存中为执行流预留好它想要的资源,可以随时访问。而当第11个执行流去申请信号量时,信号量为0,所以该执行流还无法访问临界资源。
只有当其中的一个执行流访问完临界资源,释放信号量后(信号量++),第11个执行流才能够申请信号量,去访问临界资源。