深圳外贸英文网站设计公司哪家好重庆做网站外包公司
目录
1. 题目链接及描述
2. 解题思路
3. 程序
1. 题目链接及描述
题目链接:138. 随机链表的复制 - 力扣(LeetCode)
题目描述:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。(拷贝结点的核心解决点)
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。
每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
2. 解题思路
依次拷贝原链表的每一个结点,将拷贝结点插入在源结点的后面,则random指向的结点与拷贝后的结点对应的相对距离是相同的。
具体实现分为三大步:
第一步:遍历原链表,逐个拷贝结点,并将拷贝结点插入原结点的后面(此步需处理每个结点的next域);
第二步:逐个处理拷贝结点的random域:
以题示例为例,依次插入copy结点后,以第二个结点为例,观察cur->random与copy->random的关系:
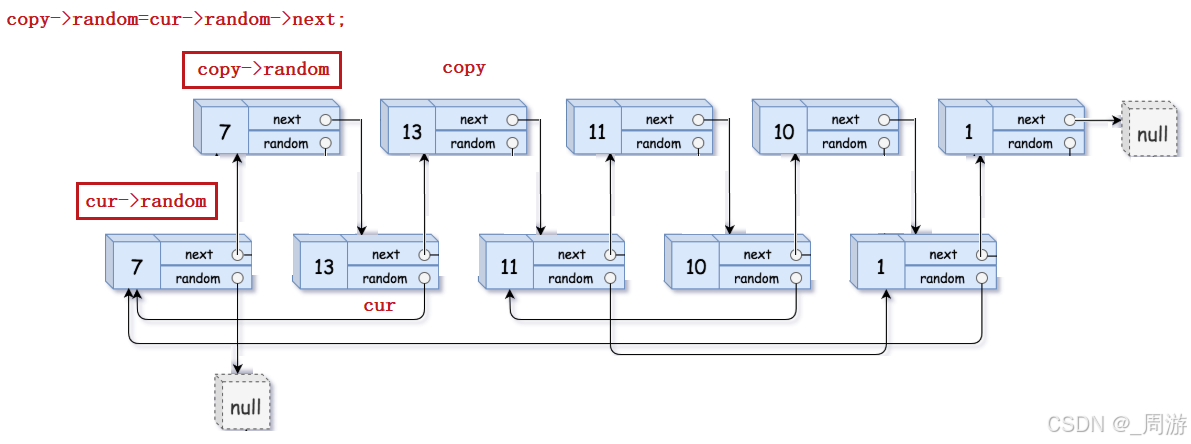
第三步:从原链表中逐个拆解拷贝结点,将其逐个尾插构成一个新链表,记新链表的第一个结点为copyHead,返回copyHead即可;
注:对于原链表是否进行恢复可自行选择。
3. 程序
/*** Definition for a Node.* struct Node {* int val;* struct Node *next;* struct Node *random;* };*/
typedef struct Node Node;
struct Node* copyRandomList(struct Node* head) {Node* cur = head;// Node* curNext=cur->next;// 依次创建原链表每个结点的拷贝结点// 将每个拷贝结点链到原结点的后面:修改next域while (cur) {Node* copy = (Node*)malloc(sizeof(Node));copy->val = cur->val;// 将copy链入原链表copy->next = cur->next;cur->next = copy;// 更新curcur = copy->next;}// 修改random域cur = head;while (cur) {Node* copy = cur->next;if (cur->random == NULL) {copy->random = NULL;} else {copy->random = cur->random->next;}// 更新curcur = copy->next;}// 从原链表中拆解拷贝链表// 依次取copy结点尾插到新链表Node *copyHead = NULL, *copyTail = NULL;cur = head;while (cur) {Node* copy = cur->next;Node* copyNext = copy->next;// 单独处理拷贝链表为空的情况if (copyTail == NULL) {copyHead = copyTail = copy;} else {// 尾插copy并更新copyTailcopyTail->next = copy;copyTail = copyTail->next;}// 更新cur与copycur=copy->next;}return copyHead;
}