北海哪家做网站网站管理cms
原文网址:Java多线程系列--synchronized的原理_IT利刃出鞘的博客-CSDN博客
简介
本文介绍Java的synchronized的原理。
反编译出字节码
Test.java
public class Test {private static Object LOCK = new Object();public static int main(String[] args) {synchronized (LOCK){System.out.println("Hello World");}return 1;}
}
先用javac Test.class 编译出class文件
再用javap –c Test.class查看字节码文件
字节码文件:
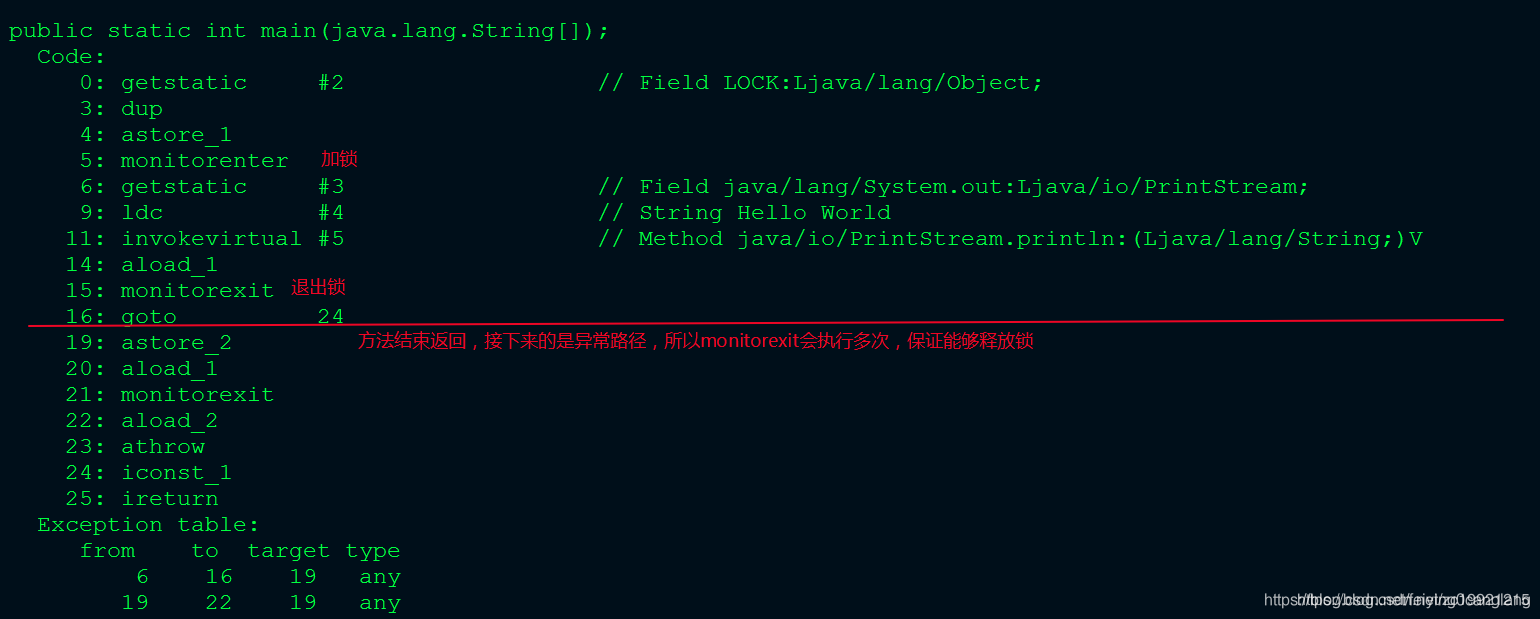
也就是说,锁是通过monitorenter和monitorexit来实现的。
进入监视器
JVM规范中描述:
monitorenter:` Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows: • If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor. • If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count. • If another thread already owns the monitor associated with objectref, the thread blocks until the monitor’s entry count is zero, then tries again to gain ownership. `
翻译:
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
- 如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
- 如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
- 如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
退出监视器
JVM规范中描述:
monitorexit: ` The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref. The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.`
翻译:
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,则线程退出monitor,不再是这个monitor的所有者。此时,其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。