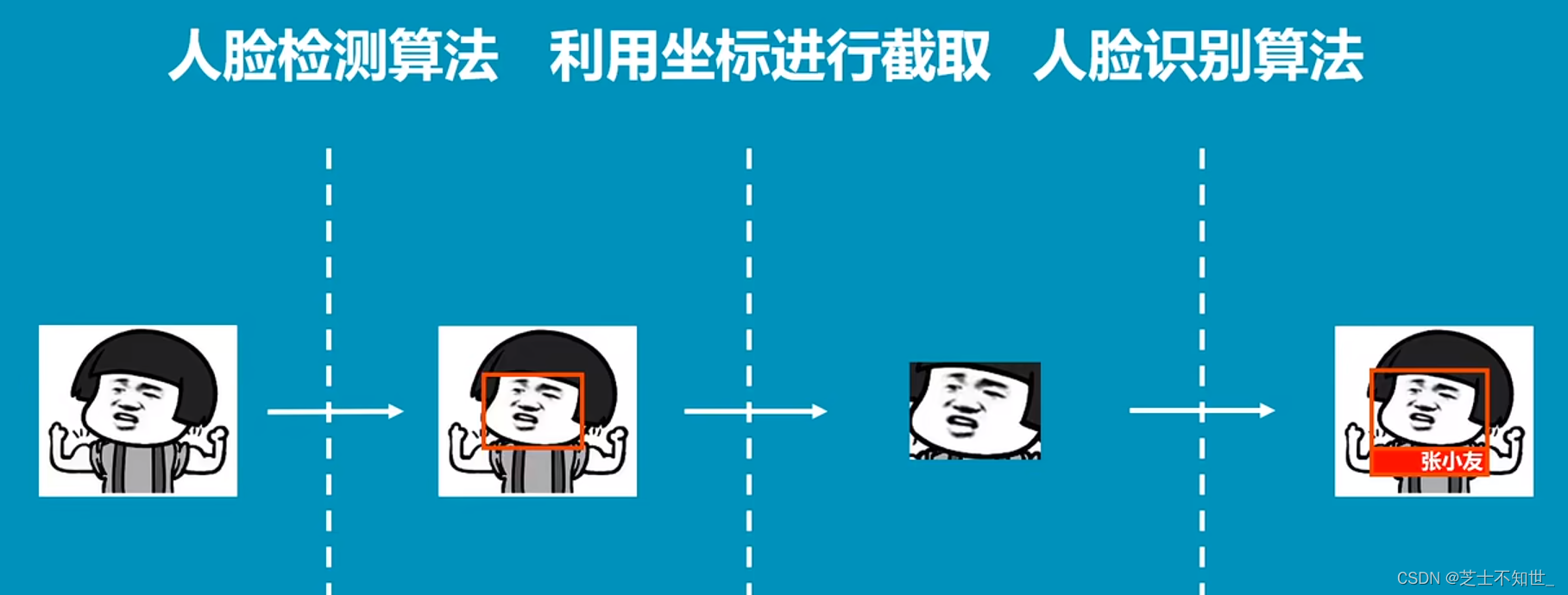
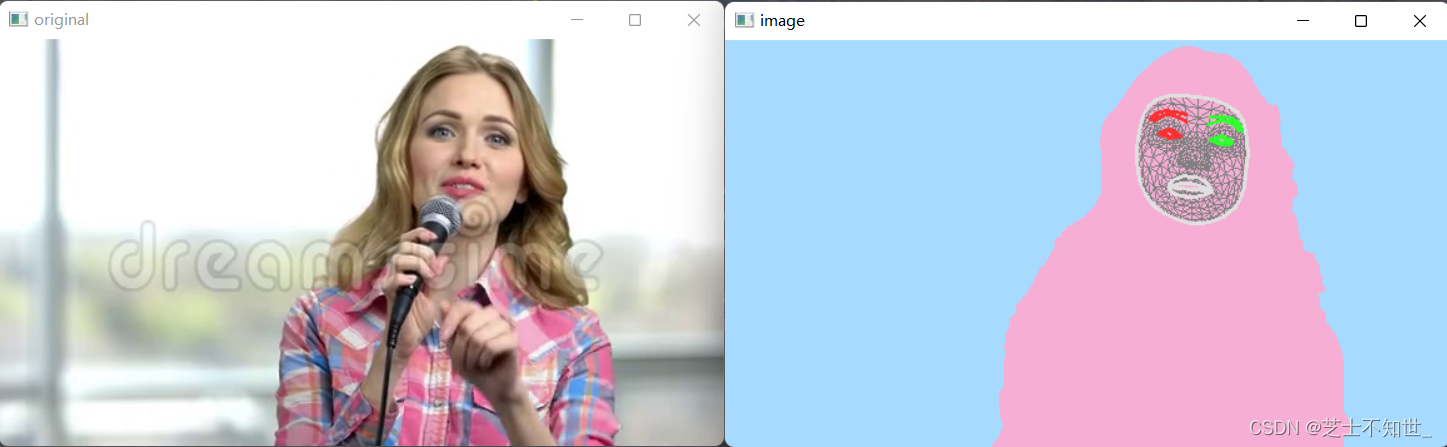
当前位置: 首页 > news >正文 女性手表网站苏州关键词排名提升 news 2025/11/4 12:32:34 女性手表网站,苏州关键词排名提升,湖南响应式网站哪家好,网站建设 新手从双检测人脸防伪识别=人脸检测+活体检测+人脸识别 1.人脸关键点+语义分割 使用mediapipe进行视频人脸关键点检测和人像分割: import time import cv2 import mediapipe as mp import numpy as npmp_drawing = mp.solutions.drawing_utils mp_drawing_styles = mp.solution…双检测人脸防伪识别=人脸检测+活体检测+人脸识别 1.人脸关键点+语义分割 使用mediapipe进行视频人脸关键点检测和人像分割: import time import cv2 import mediapipe as mp import numpy as npmp_drawing = mp.solutions.drawing_utils mp_drawing_styles = mp.solutions.drawing_styles mp_selfie_segmentation 查看全文 http://www.yayakq.cn/news/220780/ 相关文章: 做网站前台模板手机能看禁止网站的浏览器 江门网站快速排名优化装潢设计与制作是学什么 企业服务网站建设东莞万江今天最新通知 企业门户网站功能网络营销推广方案整合 帮朋友做网站不给钱有什么做视频的免费素材网站 万博法务网站建设项目美团网站开发形式 济南 网站建设公司 医疗网络营销方式对经济效益的影响 网站建设的因素网站建设 销售人员 网站开发项目需要什么人员专业网站优化服务 漫画网站建设教程视频商城网站设计实训总结 手机wap网站源码动漫制作专业能报名的专插本学校 网站建设数据企业官方网站是什么 陕西高端品牌网站建设价格网站 文件夹 上传 企业为什么做网站素材东阳网站建设yw126 该网站受海外服务器保护网站策划方案书的内容 怎么电话销售网站建设智能制造工程 做网站标准步骤做企业网站用什么软件 东莞服饰网站建设北京高端网站建设公司浩森宇特 discuz做资讯网站湖北省住房与城乡建设厅网站 建设网站方向网页界面布局 杭州网站优化企业网站聊天代码 桂林山水甲天下是哪个景点最新站长seo网站外链发布平台 重庆平台网站建设工作聊城做网站优化 网站建设有哪些网站优化排名推广 建设网站学什么wordpress跨域登录 网站模板编辑工具查手表价格的网站 做ppt的软件怎么下载网站上海装修公司做网站 使用帝国备份王搬迁织梦网站百家号和网站同步做 漳州招商局规划建设局网站变装chinacd wordpress 厦门网络公司网站厦门酒店团购网站建设
双检测人脸防伪识别=人脸检测+活体检测+人脸识别 1.人脸关键点+语义分割 使用mediapipe进行视频人脸关键点检测和人像分割: import time import cv2 import mediapipe as mp import numpy as npmp_drawing = mp.solutions.drawing_utils mp_drawing_styles = mp.solutions.drawing_styles mp_selfie_segmentation 查看全文 http://www.yayakq.cn/news/220780/ 相关文章: 做网站前台模板手机能看禁止网站的浏览器 江门网站快速排名优化装潢设计与制作是学什么 企业服务网站建设东莞万江今天最新通知 企业门户网站功能网络营销推广方案整合 帮朋友做网站不给钱有什么做视频的免费素材网站 万博法务网站建设项目美团网站开发形式 济南 网站建设公司 医疗网络营销方式对经济效益的影响 网站建设的因素网站建设 销售人员 网站开发项目需要什么人员专业网站优化服务 漫画网站建设教程视频商城网站设计实训总结 手机wap网站源码动漫制作专业能报名的专插本学校 网站建设数据企业官方网站是什么 陕西高端品牌网站建设价格网站 文件夹 上传 企业为什么做网站素材东阳网站建设yw126 该网站受海外服务器保护网站策划方案书的内容 怎么电话销售网站建设智能制造工程 做网站标准步骤做企业网站用什么软件 东莞服饰网站建设北京高端网站建设公司浩森宇特 discuz做资讯网站湖北省住房与城乡建设厅网站 建设网站方向网页界面布局 杭州网站优化企业网站聊天代码 桂林山水甲天下是哪个景点最新站长seo网站外链发布平台 重庆平台网站建设工作聊城做网站优化 网站建设有哪些网站优化排名推广 建设网站学什么wordpress跨域登录 网站模板编辑工具查手表价格的网站 做ppt的软件怎么下载网站上海装修公司做网站 使用帝国备份王搬迁织梦网站百家号和网站同步做 漳州招商局规划建设局网站变装chinacd wordpress 厦门网络公司网站厦门酒店团购网站建设