建设网站采用的网络技术马来西亚的网站后缀
在 Qt 中实现系统托盘图标是一个常见的需求,尤其是在桌面应用程序中。系统托盘图标可以让应用程序在后台运行时仍然具有可见性,同时避免占用过多的桌面空间。本文将详细介绍如何在 Qt 项目中添加托盘图标,并通过资源系统(.qrc 文件)来管理图标文件。
1. 创建 Qt 项目并准备资源文件
首先,确保已经创建了一个 Qt 项目。以下是步骤:
- 创建 Qt 项目:在 Qt Creator 中创建一个新的 Qt Widgets 应用程序。
- 添加资源文件:在 Qt Creator 中右键点击项目文件夹,选择 New > Qt > Resource File,然后命名为
resources.qrc。
2. 将图标添加到资源文件中
一旦有了资源文件(resources.qrc),就可以将图标文件(例如 tray_icon.png)添加到资源系统中了。以下是具体步骤:
- 在 Qt Creator 中打开
resources.qrc:右键点击resources.qrc文件并选择 Open。 - 添加图标文件:
- 在资源文件中,点击 添加前缀 按钮,输入前缀。
- 在资源文件中,点击 添加文件 按钮,选择你的图标文件(例如
tray_icon.png)。
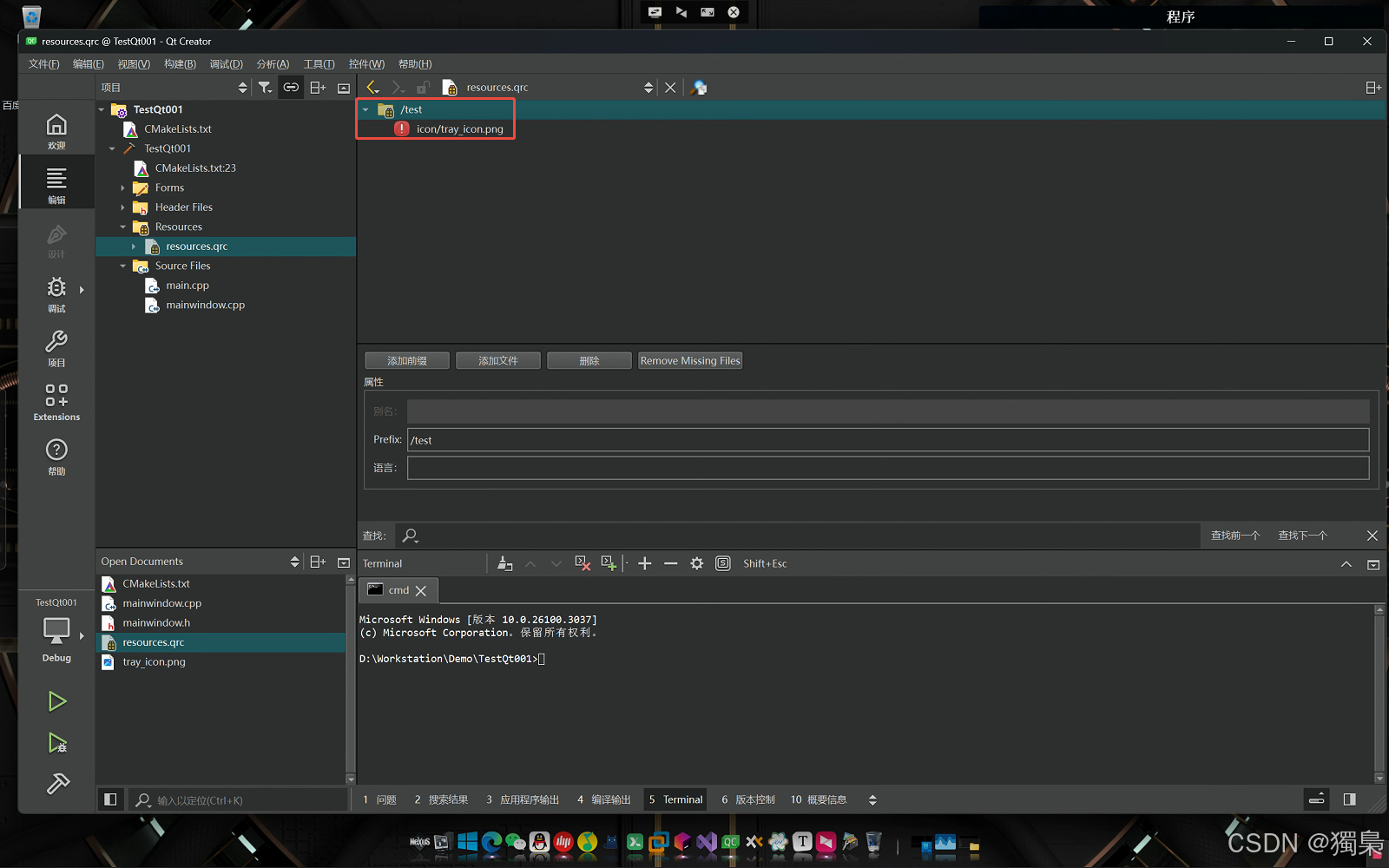
这样,图标就会被嵌入到应用的资源系统中,并且可以通过 :/test/icon/tray_icon.png 路径来访问。
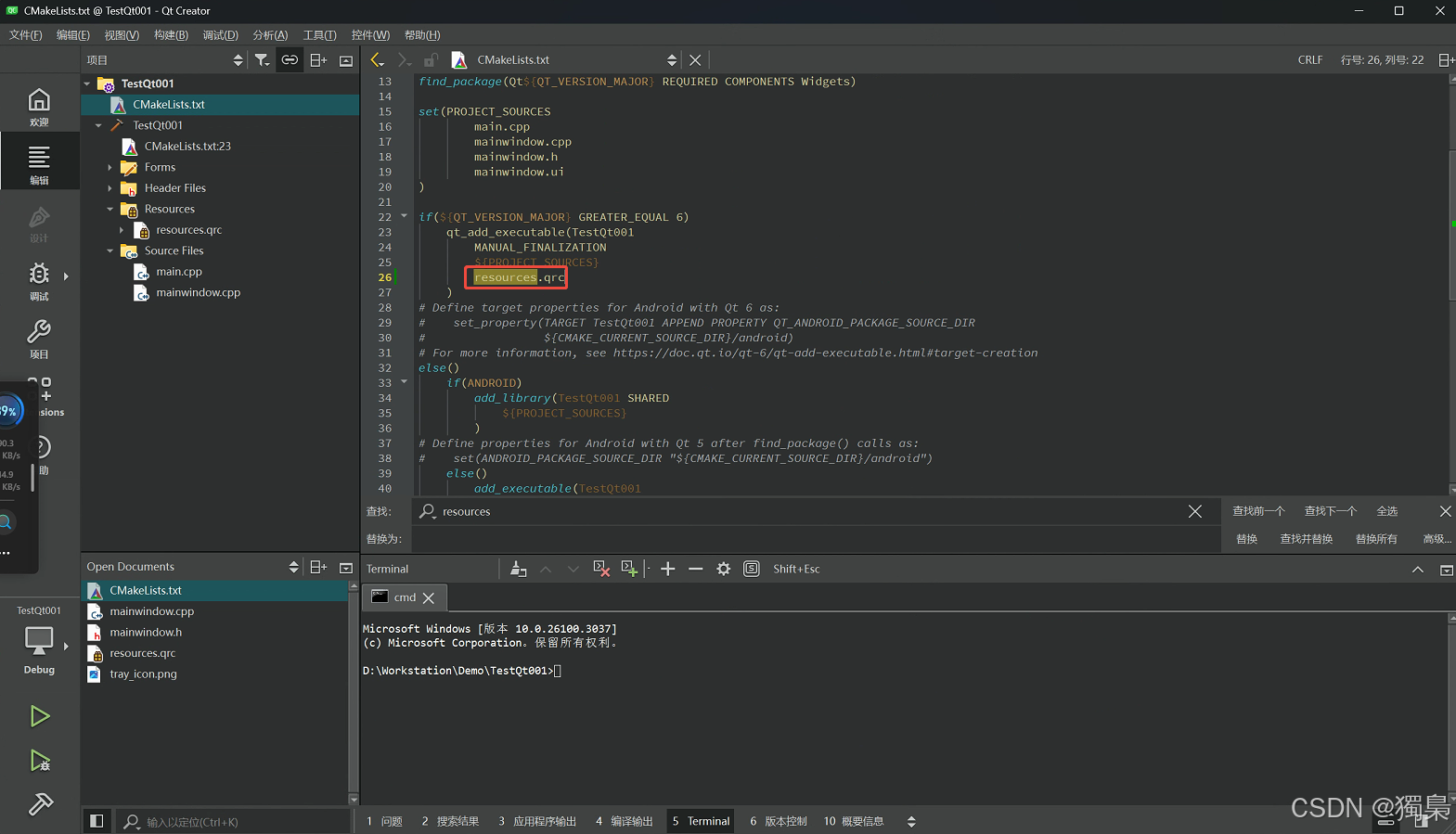
3. 修改 .pro 文件
确保 .pro 文件包含了 resources.qrc 文件。打开 .pro 文件,并确认其中有以下行:
RESOURCES += resources.qrc
这一步非常重要,因为它确保了资源文件会被正确加载到项目中。
cmake参考如下图:
4. 使用资源图标
在 Qt 中加载资源文件的图标非常简单,使用 QIcon 来设置系统托盘图标。以下是代码示例:
4.1 设置系统托盘图标
首先,在你的 MainWindow 或者其他类中,创建一个 QSystemTrayIcon 对象,并为其设置图标:
#include <QSystemTrayIcon>
#include <QMenu>
#include <QAction>// 在 MainWindow 或其他类中添加以下成员变量
QSystemTrayIcon *m_pTrayIcon;
QMenu *m_pTrayMenu;void MainWindow::setupTrayIcon() {// 创建系统托盘图标m_pTrayIcon = new QSystemTrayIcon(this);m_pTrayIcon->setIcon(QIcon(":/icon/tray_icon.png")); // 使用资源图标m_pTrayIcon->setToolTip("Qt 应用 - 托盘模式");// 创建托盘菜单m_pTrayMenu = new QMenu(this);QAction *showAction = new QAction("显示", this);QAction *exitAction = new QAction("退出", this);connect(showAction, &QAction::triggered, this, &MainWindow::showMainWindow);connect(exitAction, &QAction::triggered, this, &MainWindow::exitApplication);m_pTrayMenu->addAction(showAction);m_pTrayMenu->addAction(exitAction);m_pTrayIcon->setContextMenu(m_pTrayMenu);// 显示托盘图标m_pTrayIcon->show();// 处理左键点击:恢复窗口connect(m_pTrayIcon, &QSystemTrayIcon::activated, this, [=](QSystemTrayIcon::ActivationReason reason) {if (reason == QSystemTrayIcon::Trigger) {showMainWindow();}});
}
4.2 可勾选的菜单项
在菜单中添加一个 QAction,并使其可勾选。当用户左键单击时,勾选状态会切换。
// 添加一个可勾选的菜单项QAction *checkAction = new QAction("启用功能", this);checkAction->setCheckable(true); // 设置该项为可勾选checkAction->setChecked(false); // 默认不勾选// 当该项的状态改变时,输出当前状态connect(checkAction, &QAction::toggled, this, [=](bool checked) {if (checked) {qDebug("功能已启用");} else {qDebug("功能已禁用");}});
5. 处理关闭事件
当用户尝试关闭窗口时,你可以让窗口最小化到系统托盘,而不是完全关闭。为了实现这一点,你需要重写 closeEvent 方法:
void MainWindow::closeEvent(QCloseEvent *event)
{// 弹出提示框,确认是否关闭应用QMessageBox::StandardButton reply = QMessageBox::question(this, "确认", "确定要关闭应用吗?
应用将最小化到系统托盘",QMessageBox::Yes | QMessageBox::No);if (reply == QMessageBox::Yes) {event->ignore(); // 阻止窗口关闭this->hide(); // 隐藏窗口m_pTrayIcon->showMessage("Qt 应用", "应用已最小化到托盘", QSystemTrayIcon::Information, 3000);} else {event->accept();}
}
6. 重新编译并运行
每次你修改 resources.qrc 文件之后,必须重新编译项目。以下是具体步骤:
- 清理项目:点击 Build > Clean Project。
- 重新构建项目:点击 Build > Run qmake,然后选择 Build > Rebuild Project。
7. 托盘图标的使用
- 左键点击:单击系统托盘图标会将应用恢复到主窗口。
- 右键点击:右键点击托盘图标会显示菜单,菜单中包括 显示 和 退出 选项。
8. 常见问题和调试
如果在运行时遇到如下警告:
QSystemTrayIcon::setVisible: No Icon set
这通常表示 Qt 没有正确加载图标。以下是一些常见的解决方法:
- 确保
.pro文件包含resources.qrc。 - 重新编译项目,确保资源文件被正确嵌入到最终的可执行文件中。
- 检查资源路径是否正确,代码中的路径应该是
:/icon/tray_icon.png。
9. 完整代码
头文件(mainwindow.h)
这个头文件定义了 MainWindow 类,它包含了托盘图标相关的成员变量和函数声明。
#ifndef MAINWINDOW_H
#define MAINWINDOW_H#include <QMainWindow>
#include <QSystemTrayIcon>
#include <QMenu>QT_BEGIN_NAMESPACE
namespace Ui { class MainWindow; }
QT_END_NAMESPACEclass MainWindow : public QMainWindow {Q_OBJECTpublic:MainWindow(QWidget *parent = nullptr);~MainWindow();protected:// 重写关闭事件,将窗口最小化到托盘void closeEvent(QCloseEvent *event) override;private slots:// 显示主窗口void showMainWindow();// 退出应用void exitApplication();private:// 初始化托盘图标void setupTrayIcon();private:Ui::MainWindow *ui; // UI 类QSystemTrayIcon *m_pTrayIcon; // 系统托盘图标QMenu *m_pTrayMenu; // 托盘菜单
};
#endif // MAINWINDOW_H
实现文件(mainwindow.cpp)
在 mainwindow.cpp 中,主要实现了如何初始化系统托盘图标和处理关闭事件。
#include "mainwindow.h"
#include "ui_mainwindow.h"
#include <QMessageBox>
#include <QCloseEvent>MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), ui(new Ui::MainWindow)
{ui->setupUi(this);// 设置托盘图标和菜单setupTrayIcon();
}MainWindow::~MainWindow()
{delete ui;
}void MainWindow::setupTrayIcon()
{// 创建系统托盘图标m_pTrayIcon = new QSystemTrayIcon(this);m_pTrayIcon->setIcon(QIcon(":/icon/tray_icon.png")); // 使用资源图标m_pTrayIcon->setToolTip("Qt 应用 - 托盘模式");// 创建托盘菜单m_pTrayMenu = new QMenu(this);QAction *showAction = new QAction("显示", this);QAction *exitAction = new QAction("退出", this);// 添加一个可勾选的菜单项QAction *checkAction = new QAction("启用功能", this);checkAction->setCheckable(true); // 设置该项为可勾选checkAction->setChecked(false); // 默认不勾选connect(showAction, &QAction::triggered, this, &MainWindow::showMainWindow);connect(exitAction, &QAction::triggered, this, &MainWindow::exitApplication);// 当该项的状态改变时,输出当前状态connect(checkAction, &QAction::toggled, this, [=](bool checked) {if (checked) {qDebug("功能已启用");} else {qDebug("功能已禁用");}});m_pTrayMenu->addAction(showAction);m_pTrayMenu->addAction(exitAction);m_pTrayMenu->addAction(checkAction);m_pTrayIcon->setContextMenu(m_pTrayMenu);// 显示托盘图标m_pTrayIcon->show();// 处理左键点击:恢复窗口connect(m_pTrayIcon, &QSystemTrayIcon::activated, this, [=](QSystemTrayIcon::ActivationReason reason) {if (reason == QSystemTrayIcon::Trigger) {showMainWindow();}});
}void MainWindow::closeEvent(QCloseEvent *event)
{// 弹出提示框,确认是否关闭应用QMessageBox::StandardButton reply = QMessageBox::question(this, "确认", "确定要关闭应用吗?\n应用将最小化到系统托盘",QMessageBox::Yes | QMessageBox::No);if (reply == QMessageBox::Yes) {event->ignore(); // 阻止窗口关闭this->hide(); // 隐藏窗口m_pTrayIcon->showMessage("Qt 应用", "应用已最小化到托盘", QSystemTrayIcon::Information, 3000);} else {event->accept();}
}void MainWindow::showMainWindow()
{this->show(); // 恢复主窗口this->activateWindow(); // 激活窗口
}void MainWindow::exitApplication()
{m_pTrayIcon->hide(); // 隐藏托盘图标QApplication::quit(); // 退出应用
}总结
本文介绍了如何在 Qt 项目中通过资源文件(resources.qrc)添加和使用系统托盘图标。通过这些步骤,可以让应用程序在后台运行时使用托盘图标,同时提供更加友好的用户体验。