自己建站的网站网站改版 被k
在Laravel中,可以使用maatwebsite/excel这个库来处理Excel文件的导入。
1.用命令行窗口打开项目根目录,使用 Composer 安装 maatwebsite/excel
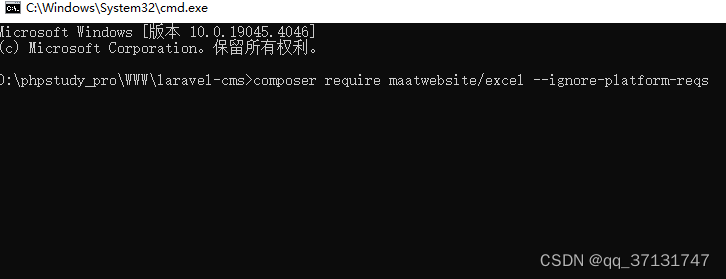
composer require maatwebsite/excel --ignore-platform-reqs在你的config/app.php文件中注册服务提供者(可选)
'providers' => [// ...Maatwebsite\Excel\ExcelServiceProvider::class,
],注册门面(Facade)(可选)
'aliases' => [// ...'Excel' => Maatwebsite\Excel\Facades\Excel::class,
],
2. 使用php artisan make:import命令创建一个新的导入类
php artisan make:import UsersImport --model=User这将会生成一个新的Import类UsersImport,并且已经引入了你需要的User模型。
在生成的UsersImport类中,你需要定义collection方法来处理导入的数据集合,以及model方法来处理单个模型的导入。这里是一个简单的例子:
// app/Imports/UsersImport.phpnamespace App\Imports;use App\Models\User;
use Maatwebsite\Excel\Concerns\ToModel;
use Maatwebsite\Excel\Concerns\Importable;class UsersImport implements ToModel
{use Importable;public function model(array $row){return new User(['name' => $row[0],'email' => $row[1],'password' => \Hash::make($row[2]),]);}
}3.在控制器中,添加一个方法来处理文件上传,并且调用导入。
// app/Http/Controllers/UserController.phpnamespace App\Http\Controllers;use App\Imports\UsersImport;
use Illuminate\Http\Request;class UserController extends Controller
{public function import(Request $request){$request->validate(['file' => 'required|file|mimes:xls,xlsx']);$file = $request->file('file');$import = new UsersImport();$import->import($file);return "Users imported successfully.";}
}4.定义路由
// routes/web.phpuse App\Http\Controllers\UserController;Route::post('/users/import', [UserController::class, 'import'])->name('users.import');5.确保表单有enctype="multipart/form-data"属性,以便正确上传文件。
<form action="{{ route('users.import') }}" method="POST" enctype="multipart/form-data">@csrf<input type="file" name="file"><button type="submit">Import</button>
</form>