中医医院网站建设需求电商网站有哪些官网
参考:
Hexo添加Live2D看板娘最新教程
live2d-widget
live2d-widget-models
网页/博客Hexo添加live2d游戏角色看板娘,简易添加,碧蓝航线等live2d新型游戏角色模型(moc3)
live2d-moc3
jsdelivr
方法1
可以直接去看参考文章的第一部分的第一篇。操作很简单就不说了。
方法2
很可惜方法1似乎对于cubism4.0以上的版本不成立,因为它不支持moc3格式的文件。所以我们这时候就需要采用方法2.
步骤:
在cubism editor中导出模型文件

注意这些选项的设置。
fork该仓库
https://github.com/xiunianjun/AzurLaneL2DViewer
clone你fork的仓库到本地,然后在asset文件夹中建立一个文件夹,将你的模型文件拖进去,并组织成如下目录结构

【新建文件夹】

【注意文件夹名字与模型名字要一致。把moc3、model3.json、physics3.json放在这里,有没有cdi3无所谓】

【在motion文件夹中放置动作json】
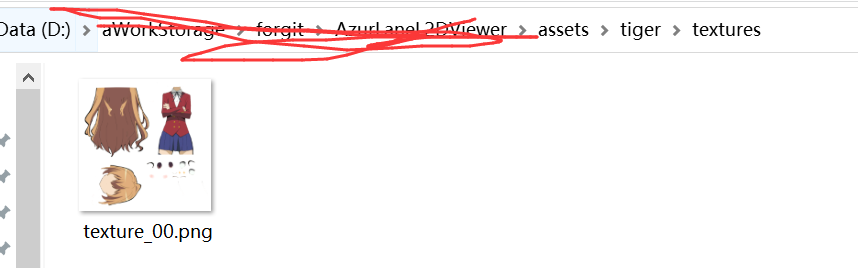
【在textures文件夹中放置贴图】
再把这些pull到你的仓库里
将其发布为一个release版本。我命名该版本为aaa
在你的博客根目录下的public中,将live2d-moc3中要求的代码插入到`index.html`中
注意,推荐插入在body标签结束前面一点点的位置,避免我们的live2d被渲染在最下层。
<div class="Canvas" id="L2dCanvas"></div><script>var config = {width: 800,height: 600,left: '750px',bottom: '-100px',basePath: 'https://cdn.jsdelivr.net/gh/xiunianjun/AzurLaneL2DViewer@aaa/assets/',//role: 'Tiger',role: 'aierdeliqi_4',// background: 'https://cdn.jsdelivr.net/gh/xiunianjun/AzurLaneL2DViewer@gh-page/assets/bg/bg_church_jp.png',opacity: 1,mobile: false}var v = new Viewer(config); </script>注意修改basepath为`https://cdn.jsdelivr.net/gh/你的github名字/AzurLaneL2DViewer@你在5中的release版本命名/assets/`,role修改为3里面建立的文件夹名【同模型名】
然后执行hexo d就好啦。
注意,由于hexo-g会覆盖原来的index.html,故而第6步操作需要在每次generate对index.html进行重新生成后都做一遍,比较麻烦,但我暂时没找到什么好方法。
哪里写的不清楚或者有更好的方法,可以随时评论区/私信我交流。