网站首页包含的内容北京万户网络技术有限公司
前 言
在开始集成支付宝支付之前,我们需要准备一个支付宝商家账户,如果是个人开发者,可以通过注册公司或者让有公司资质的单位进行授权,后续在集成相关API的时候需要提供这些信息。
下面我以电脑网页端在线支付为例,介绍整个从集成、测试到上线的具体流程。
1. 预期效果展示
在开始之前我们先看下我们要达到的最后效果,具体如下:
- 前端点击支付跳转到支付宝界面
- 支付宝界面展示付款二维码
- 用户手机端支付
- 完成支付,支付宝回调开发者指定的url

2. 开发流程
2.1 沙盒调试
支付宝为我们准备了完善的沙盒开发环境,我们可以先在沙盒环境调试好程序,后续新建好应用并成功上线后,把程序中对应的参数替换为线上参数即可。
1. 创建沙盒应用
直接进入 https://open.alipay.com/develop/sandbox/app 创建沙盒应用即可,
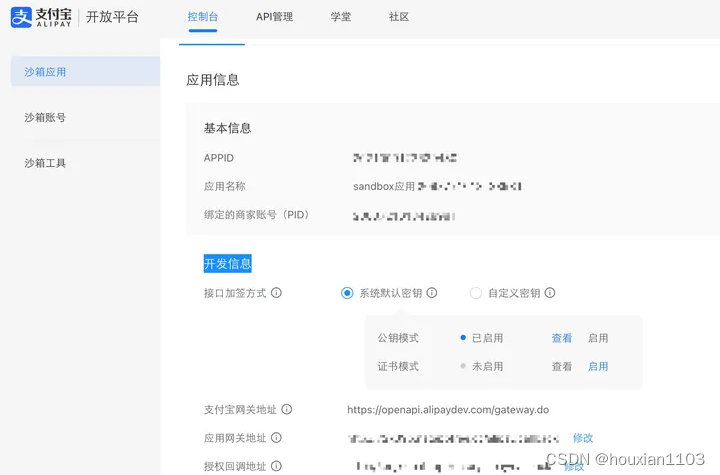
这里因为是测试环境,我们就选择系统默认密钥就行了,下面选择公钥模式,另外应用网关地址就是用户完成支付之后,支付宝会回调的url。在开发环境中,我们可以采用内网穿透的方式,将我们本机的端口暴露在某个公网地址上,这里推荐 https://natapp.cn/ ,可以免费注册使用。
2. SpringBoot代码实现
在创建好沙盒应用,获取到密钥,APPID,商家账户PID等信息之后,就可以在测试环境开发集成对应的API了。这里我以电脑端支付API为例,介绍如何进行集成。
关于电脑网站支付的详细产品介绍和API接入文档可以参考:https://opendocs.alipay.com/open/repo-0038oa?ref=api 和 https://opendocs.alipay.com/open
- 步骤1, 添加alipay sdk对应的Maven依赖。
<!-- alipay -->
<dependency> <groupId>com.alipay.sdk</groupId> <artifactId>alipay-sdk-java</artifactId> <version>4.35.132.ALL</version>
</dependency>
- 步骤2,添加支付宝下单、支付成功后同步调用和异步调用的接口。
这里需要注意,同步接口是用户完成支付后会自动跳转的地址,因此需要是Get请求。异步接口,是用户完成支付之后,支付宝会回调来通知支付结果的地址,所以是POST请求。
@RestController
@RequestMapping("/alipay")
public class AliPayController { @Autowired AliPayService aliPayService; @PostMapping("/order") public GenericResponse<Object> placeOrderForPCWeb(@RequestBody AliPayRequest aliPayRequest) { try { return aliPayService.placeOrderForPCWeb(aliPayRequest); } catch (IOException e) { throw new RuntimeException(e); } } @PostMapping("/callback/async") public String asyncCallback(HttpServletRequest request) { return aliPayService.orderCallbackInAsync(request); } @GetMapping("/callback/sync") public void syncCallback(HttpServletRequest request, HttpServletResponse response) { aliPayService.orderCallbackInSync(request, response); } }
- 步骤3,实现Service层代码
这里针对上面controller中的三个接口,分别完成service层对应的方法。下面是整个支付的核心流程,其中有些地方需要根据你自己的实际情况进行保存订单到DB或者检查订单状态的操作,这个可以根据实际业务需求进行设计。
public class AliPayService { @Autowired AliPayHelper aliPayHelper; @Resource AlipayConfig alipayConfig; @Transactional(rollbackFor = Exception.class) public GenericResponse<Object> placeOrderForPCWeb(AliPayRequest aliPayRequest) throws IOException { log.info("【请求开始-在线购买-交易创建】*********统一下单开始*********"); String tradeNo = aliPayHelper.generateTradeNumber(); String subject = "购买套餐1"; Map<String, Object> map = aliPayHelper.placeOrderAndPayForPCWeb(tradeNo, 100, subject); if (Boolean.parseBoolean(String.valueOf(map.get("isSuccess")))) { log.info("【请求开始-在线购买-交易创建】统一下单成功,开始保存订单数据"); //保存订单信息 // 添加你自己的业务逻辑,主要是保存订单数据log.info("【请求成功-在线购买-交易创建】*********统一下单结束*********"); return new GenericResponse<>(ResponseCode.SUCCESS, map.get("body")); }else{ log.info("【失败:请求失败-在线购买-交易创建】*********统一下单结束*********"); return new GenericResponse<>(ResponseCode.INTERNAL_ERROR, String.valueOf(map.get("subMsg"))); } } // sync return page public void orderCallbackInSync(HttpServletRequest request, HttpServletResponse response) { try { OutputStream outputStream = response.getOutputStream(); //通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码 response.setHeader("content-type", "text/html;charset=UTF-8"); String outputData = "支付成功,请返回网站并刷新页面。"; /** * data.getBytes()是一个将字符转换成字节数组的过程,这个过程中一定会去查码表, * 如果是中文的操作系统环境,默认就是查找查GB2312的码表, */ byte[] dataByteArr = outputData.getBytes("UTF-8");//将字符转换成字节数组,指定以UTF-8编码进行转换 outputStream.write(dataByteArr);//使用OutputStream流向客户端输出字节数组 } catch (IOException e) { throw new RuntimeException(e); } } public String orderCallbackInAsync(HttpServletRequest request) { try { Map<String, String> map = aliPayHelper.paramstoMap(request); String tradeNo = map.get("out_trade_no"); String sign = map.get("sign"); String content = AlipaySignature.getSignCheckContentV1(map); boolean signVerified = aliPayHelper.CheckSignIn(sign, content); // check order status // 这里在DB中检查order的状态,如果已经支付成功,无需再次验证。if(从DB中拿到order,并且判断order是否支付成功过){ log.info("订单:" + tradeNo + " 已经支付成功,无需再次验证。"); return "success"; } //验证业务数据是否一致 if(!checkData(map, order)){ log.error("返回业务数据验证失败,订单:" + tradeNo ); return "返回业务数据验证失败"; } //签名验证成功 if(signVerified){ log.info("支付宝签名验证成功,订单:" + tradeNo); // 验证支付状态 String tradeStatus = request.getParameter("trade_status"); if(tradeStatus.equals("TRADE_SUCCESS")){ log.info("支付成功,订单:"+tradeNo); // 更新订单状态,执行一些业务逻辑return "success"; }else{ System.out.println("支付失败,订单:" + tradeNo ); return "支付失败"; } }else{ log.error("签名验证失败,订单:" + tradeNo ); return "签名验证失败."; } } catch (IOException e) { log.error("IO exception happened ", e); throw new RuntimeException(ResponseCode.INTERNAL_ERROR, e.getMessage()); } } public boolean checkData(Map<String, String> map, OrderInfo order) { log.info("【请求开始-交易回调-订单确认】*********校验订单确认开始*********"); //验证订单号是否准确,并且订单状态为待支付 if(验证订单号是否准确,并且订单状态为待支付){ float amount1 = Float.parseFloat(map.get("total_amount")); float amount2 = (float) order.getOrderAmount(); //判断金额是否相等 if(amount1 == amount2){ //验证收款商户id是否一致 if(map.get("seller_id").equals(alipayConfig.getPid())){ //判断appid是否一致 if(map.get("app_id").equals(alipayConfig.getAppid())){ log.info("【成功:请求开始-交易回调-订单确认】*********校验订单确认成功*********"); return true; } } } } log.info("【失败:请求开始-交易回调-订单确认】*********校验订单确认失败*********"); return false; }
}
- 步骤4,实现alipayHelper类。这个类里面对支付宝的接口进行封装。
public class AliPayHelper { @Resource private AlipayConfig alipayConfig; //返回数据格式 private static final String FORMAT = "json"; //编码类型 private static final String CHART_TYPE = "utf-8"; //签名类型 private static final String SIGN_TYPE = "RSA2"; /*支付销售产品码,目前支付宝只支持FAST_INSTANT_TRADE_PAY*/ public static final String PRODUCT_CODE = "FAST_INSTANT_TRADE_PAY"; private static AlipayClient alipayClient = null; private static final SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMMddHHmmssSSS"); private static final Random random = new Random(); @PostConstruct public void init(){ alipayClient = new DefaultAlipayClient( alipayConfig.getGateway(), alipayConfig.getAppid(), alipayConfig.getPrivateKey(), FORMAT, CHART_TYPE, alipayConfig.getPublicKey(), SIGN_TYPE); }; /*================PC网页支付====================*/ /** * 统一下单并调用支付页面接口 * @param outTradeNo * @param totalAmount * @param subject * @return */ public Map<String, Object> placeOrderAndPayForPCWeb(String outTradeNo, float totalAmount, String subject){ AlipayTradePagePayRequest request = new AlipayTradePagePayRequest(); request.setNotifyUrl(alipayConfig.getNotifyUrl()); request.setReturnUrl(alipayConfig.getReturnUrl()); JSONObject bizContent = new JSONObject(); bizContent.put("out_trade_no", outTradeNo); bizContent.put("total_amount", totalAmount); bizContent.put("subject", subject); bizContent.put("product_code", PRODUCT_CODE); request.setBizContent(bizContent.toString()); AlipayTradePagePayResponse response = null; try { response = alipayClient.pageExecute(request); } catch (AlipayApiException e) { e.printStackTrace(); } Map<String, Object> resultMap = new HashMap<>(); resultMap.put("isSuccess", response.isSuccess()); if(response.isSuccess()){ log.info("调用成功"); log.info(JSON.toJSONString(response)); resultMap.put("body", response.getBody()); } else { log.error("调用失败"); log.error(response.getSubMsg()); resultMap.put("subMsg", response.getSubMsg()); } return resultMap; } /** * 交易订单查询 * @param out_trade_no * @return */ public Map<String, Object> tradeQueryForPCWeb(String out_trade_no){ AlipayTradeQueryRequest request = new AlipayTradeQueryRequest(); JSONObject bizContent = new JSONObject(); bizContent.put("trade_no", out_trade_no); request.setBizContent(bizContent.toString()); AlipayTradeQueryResponse response = null; try { response = alipayClient.execute(request); } catch (AlipayApiException e) { e.printStackTrace(); } Map<String, Object> resultMap = new HashMap<>(); resultMap.put("isSuccess", response.isSuccess()); if(response.isSuccess()){ System.out.println("调用成功"); System.out.println(JSON.toJSONString(response)); resultMap.put("status", response.getTradeStatus()); } else { System.out.println("调用失败"); System.out.println(response.getSubMsg()); resultMap.put("subMsg", response.getSubMsg()); } return resultMap; } /** * 验证签名是否正确 * @param sign * @param content * @return */ public boolean CheckSignIn(String sign, String content){ try { return AlipaySignature.rsaCheck(content, sign, alipayConfig.getPublicKey(), CHART_TYPE, SIGN_TYPE); } catch (AlipayApiException e) { e.printStackTrace(); } return false; } /** * 将异步通知的参数转化为Map * @return */ public Map<String, String> paramstoMap(HttpServletRequest request) throws UnsupportedEncodingException { Map<String, String> params = new HashMap<String, String>(); Map<String, String[]> requestParams = request.getParameterMap(); for (Iterator<String> iter = requestParams.keySet().iterator(); iter.hasNext();) { String name = (String) iter.next(); String[] values = (String[]) requestParams.get(name); String valueStr = ""; for (int i = 0; i < values.length; i++) { valueStr = (i == values.length - 1) ? valueStr + values[i] : valueStr + values[i] + ","; } // 乱码解决,这段代码在出现乱码时使用。
// valueStr = new String(valueStr.getBytes("ISO-8859-1"), "utf-8"); params.put(name, valueStr); } return params; } }
- 步骤5,封装config类,用于存放所有的配置属性。
@Data
@Component
@ConfigurationProperties(prefix = "alipay")
public class AlipayConfig { private String gateway; private String appid; private String pid; private String privateKey; private String publicKey; private String returnUrl; private String notifyUrl; }
另外需要在application.properties中,准备好上述对应的属性。
# alipay config
alipay.gateway=https://openapi.alipaydev.com/gateway.do
alipay.appid=your_appid
alipay.pid=your_pid
alipay.privatekey=your_private_key
alipay.publickey=your_public_key
alipay.returnurl=完成支付后的同步跳转地址
alipay.notifyurl=完成支付后,支付宝会异步回调的地址
3. 前端代码实现
前端代码只需要完成两个功能, 1. 根据用户的请求向后端发起支付请求。 2. 直接提交返回数据完成跳转。
下面的例子中,我用typescript实现了用户点击支付之后的功能,
async function onPositiveClick() { paymentLoading.value = true const { data } = await placeAlipayOrder<string>({ //你的一些请求参数,例如金额等等}) const div = document.createElement('divform') div.innerHTML = data document.body.appendChild(div) document.forms[0].setAttribute('target', '_blank') document.forms[0].submit() showModal.value = false paymentLoading.value = false
}
2.2 创建并上线APP
完成沙盒调试没问题之后,我们需要创建对应的支付宝网页应用并上线。
登录 https://open.alipay.com/develop/manage 并选择创建网页应用。

填写应用相关信息:

创建好应用之后,首先在开发设置中,设置好接口加签方式以及应用网关。

注意密钥选择RSA2,其他按照上面的操作指南一步步走即可,注意保管好自己的私钥和公钥。
之后在产品绑定页,绑定对应的API,比如我们这里是PC网页端支付,找到对应的API绑定就可以了。如果第一次绑定,可能需要填写相关的信息进行审核,按需填写即可,一般审核一天就通过了。
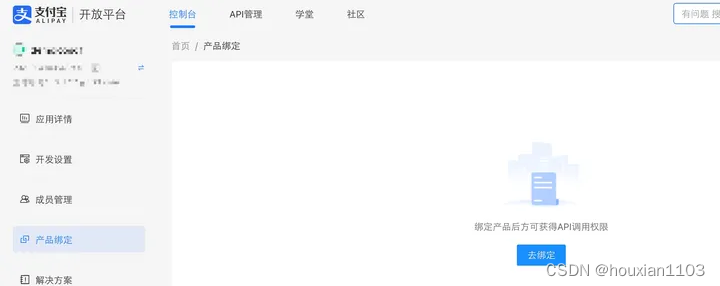
最后如果一切就绪,我们就可以把APP提交上线了,上线成功之后,我们需要把下面SpringBoot中的properties替换为线上APP的信息,然后就可以在生产环境调用支付宝的接口进行支付了。
# alipay config
alipay.gateway=https://openapi.alipaydev.com/gateway.do
alipay.appid=your_appid
alipay.pid=your_pid
alipay.privatekey=your_private_key
alipay.publickey=your_public_key
alipay.returnurl=完成支付后的同步跳转地址
alipay.notifyurl=完成支付后,支付宝会异步回调的地址