宁波怎么建网站模板官网网站建设需求
一、概述
1、定义
图像显著性检测(Saliency Detection,SD), 指通过智能算法模拟人的视觉系统特点,预测人类的视觉凝视点和眼动,提取图像中的显著区域(即人类感兴趣的区域),可以广泛用于目标识别、图像编辑以及图像检索等领域,是计算机视觉领域关键的图像分析技术。
示例如图所示,左图为原图,右图为经过显著性检测算法的结果图

2、方法分类
显著性目标检测主要可以分为两个阶段,分别是传统尺度空间手工特征的注意预测算法和基于深度学习的注意预测算法。
第一阶段为等传统尺度空间手工特征的注意预测算法。第二个阶段,随着计算机神经网络技术的革新和发展,基于深度学习的注意预测算法大量出现。
传统注意预测算法,指的是基于强度、颜色和方向等传统特征的算法,由于其特征提取和学习方法都以图像本身空间特征为基础,缺乏多语义等深度特征,相较于人眼仍然具有较大差距,很难检测到人眼注视信息包含的大量高级语义信息,在预测效果的提高上有局限。此外,不同人的注意力机制存在一定差异,在大部分传统模型中未加入先验信息,处理相对困难。
深度学习注意预测算法是近年来发展较为迅速的方法。由于深度学习算法需要大量的训练数据,同时神经网络的设计上针对不同任务需要不断变更,算法较复杂。另外,深度学习模型一般存在可解释性差的共性缺点。
# 二、算法模型
## 1、ITTI视觉显著性模型
TTI视觉显著性模型是根据早期灵长类动物的视觉神经系统设计的一种视觉注意模型[1]。该模型首先利用高斯采样方法构建图像的颜色、亮度和方向的高斯金字塔,然后利用高斯金字塔计算图像的亮度特征图、颜色特征图和方向特征图,最后结合不同尺度的特征图即可获得亮度、颜色和方向显著图,相加得到最终的视觉显著图,如下图所示(引用自原文)。该方法不需要训练学习的过程,仅通过纯数学方法,便可完成显著图的计算。
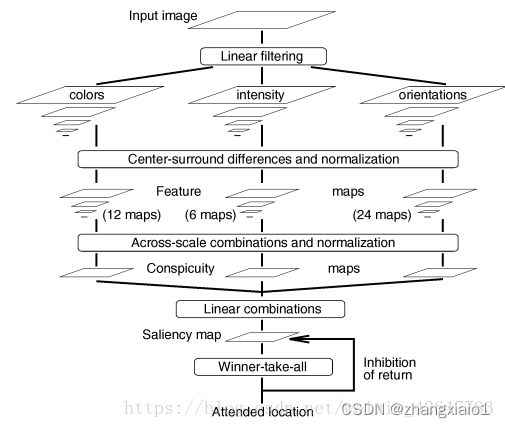
## 高斯金字塔的构建
高斯金字塔包括三部分,分别是亮度、颜色和方向。
首先要对r、g、b三个通道做高斯降采样,从而获得九个尺度下的三通道图像、、,其中。
然后即可构建亮度高斯金字塔,在九个尺度下计算获得,这里需要根据再对、、做归一化处理,以便将色调与亮度分离,原因在于低亮度下色调难以分辨。而每一个像素点的归一化仅对亮度的点进行,而其余的点将置零,其中表示点所处的尺度的图像中最大的亮度值。
接着即可构建颜色高斯金字塔,在九个尺度下计算
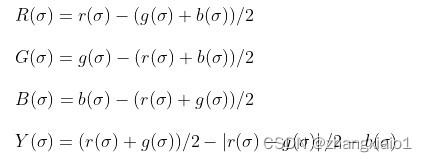
以上四个分别代表红、绿、蓝、黄的颜色高斯金字塔。
最后利用Gabor滤波器构建Gabor方向金字塔,其中,角度分别为0 、45、90、135 。
上述获得亮度、颜色和方向高斯金字塔后,利用Center-Surround方法(Center(c)即精细尺度,Surround(s)即粗尺度)计算对应的特征图。计算方法为:
其中c 为2 3 4,而s=c+3或s=c+3。再通过减法操作调整图片到同一大小,I表示亮度特征图,RG和BY表示颜色特征图,这是利用了大脑皮质的“颜色双对立”系统,O表示方向特征图。所以总共生成的特征图有6+12+6x4=42张特征图。
## 显著图的构建
模型在缺少自顶而下的监督机制的条件下,提出一个特征图归一化操作运算符
,该操作过程基于大脑皮质侧向抑制机智,可以增强存在少量活动峰(即尖锐值)的特征图,抑制存在大量活动峰的特征图。其操作方法如下:
(1)首先对输入的特征图归一化至统一范围[0...M];
(2)找到该特征图的全局最大值M所在位置并计算其他所有局部最大值的均值m,然后把整个特征图同乘以(M-m)^2;
如下图所示,中间列上图便是存在大量活动峰的特征图,经过操作后得到的特征图整体较为平滑,活动峰被抑制,中间列下图是存在少量活动峰的特征图,经过操作后得到的特征图在原有的活动峰处得到了增强。

通过以上操作符结合获得的42张特征图,即可计算最后的视觉显著图,计算方法如下:
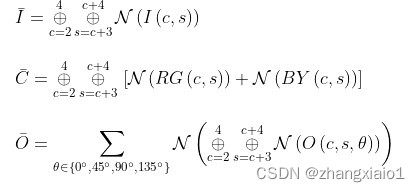

一般在目标检测中,根据设定的阈值检测显著性目标,设定的阈值逐渐下降,得到的显著性目标就会逐渐增多,同时检测时间也会增加,论文实验如图所示。

## LC算法
LC算法的基本思想是:计算某个像素在整个图像上的全局对比度,即该像素与图像中其他所有像素在颜色上的距离之和作为该像素的显著值 [3] 。

HC算法
HC算法和LC算法没有本质的区别,HC算法相比于LC算法考虑了彩色信息,而不是像LC那样只用像素的灰度信息,由于彩色图像最多有256*256*256种颜色,因此直接采用基于直方图技术的方案不适用于彩色图片。但是实际上一幅彩色图像并不会用到那么多种颜色,因此提出了降低颜色数量的方案,将RGB各分量分别映射成12等份,则隐射后的图最多只有12*12*12种颜色,这样就可以构造一个较小的直方图用来加速,但是由于过渡量化会对结果带来一定的影响,因此又用了一个平滑的过程。 最后和LC不同的是,对图像处理在Lab空间进行的,而由于Lab空间和RGB并不是完全对应的,其量化过程还是在RGB空间完成的 [
AC

FT

# 参考
https://blog.csdn.net/weixin_42647783/article/details/82532179
https://baike.baidu.com/item/%E8%A7%86%E8%A7%89%E6%98%BE%E8%91%97%E6%80%A7%E6%A3%80%E6%B5%8B/22761214