网站做产品的审核工作内容字体大全
目录
web及网络基础
在浏览器地址栏输入URL时,页面呈现过程
TCP/IP协议族
IP(网际协议):负责传输
TCP协议:确保可靠性
DNS服务:负责域名解析
URI和URL
HTTP
HTTP 请求报文结构
请求行
请求头
空行
请求体
HTTP 响应报文结构
状态行
响应头
空行
响应体
HTTP方法和状态码
HTTP 状态码类别
常见HTTP状态码
成功响应 (2xx)
重定向 (3xx)
客户端错误(4xx)
服务器错误 (5xx)
web及网络基础
在浏览器地址栏输入URL时,页面呈现过程

在浏览器地址栏输入URL之后,信息被送往服务器;然后从服务器获得回复就会显示在web页面上。
HTTP协议(超文本传输协议):规范完成从客户端到服务器等一系列运作流程。
web是建立在HTTP协议上通信的。
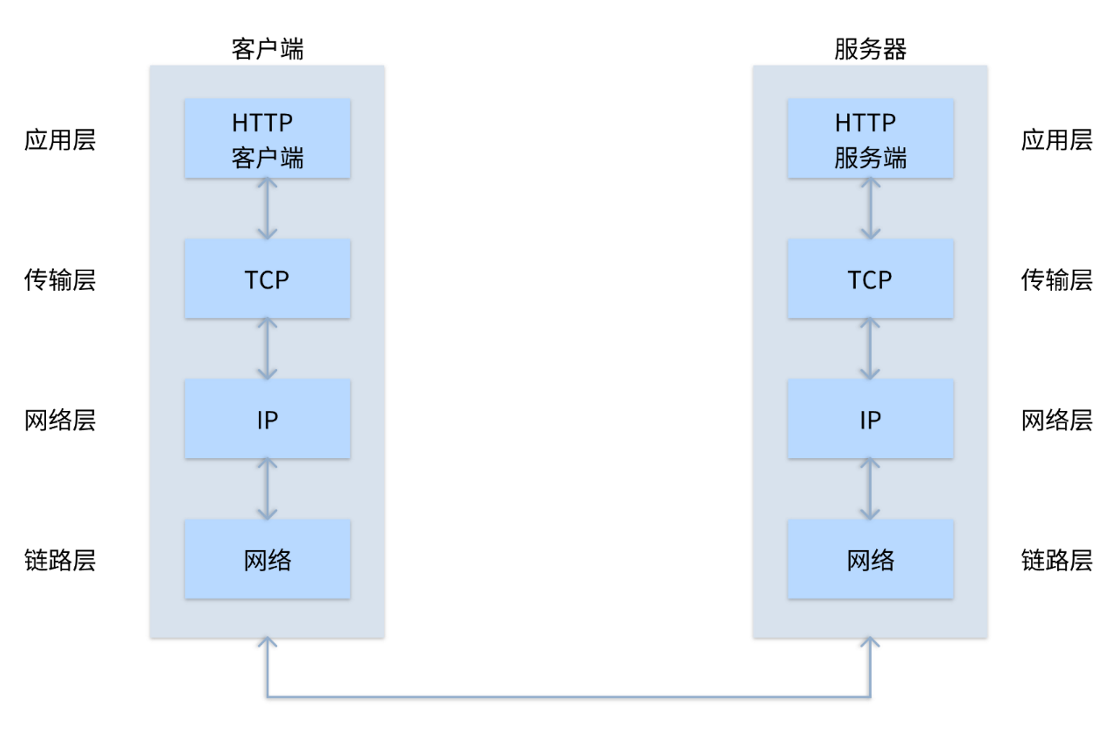
TCP/IP协议族
协议:计算机与网络设备要相互通信,双方就必须基于相同的方法。不同的硬件、操作系统之间的通信,所有的这一切都需要一种规则。这中规则就成为协议。
TCP/IP是互联网相关的各类协议族的总称。
IP(网际协议):负责传输
IP网际协议位于网络层。
IP 协议的作用是把各种数据包传送给对方。而要保证确实传送到对方那里,则需要满足各类条件。其中两个重要的条件是 IP 地址和 MAC 地址。
IP 地址指明了节点被分配到的地址,MAC 地址是指网卡所属的固定地址。
TCP协议:确保可靠性
TCP位于传输层,提供可靠的字节流服务。
为了准确无误地将数据送达目标处,TCP协议采用了三次握手策略。
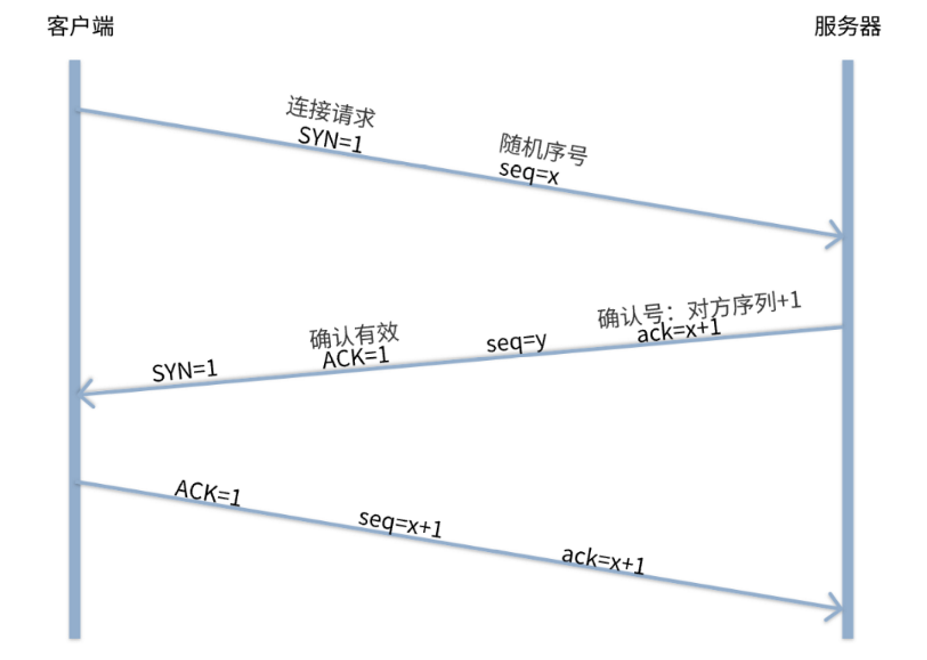
TCP协议把数据包送出去后,不会对传送后的情况置之不理,一定会向对方确认是否成功送达。握手过程中使用了TCP的标志(flag)——SYN和ACK)。
DNS服务:负责域名解析
DNS服务位于应用层,它提供域名到IP地址之间的解析服务。
用户通常使用主机名或域名来访问对方的计算机,而不是直接通过IP地址访问,原因是与IP地址的一组纯数字相比,用字母配合数字的表示形式来指定计算机名更符合人类的记忆习惯。
让计算机去理解名称相对困难,因为计算机更擅长处理一长串数字。
为了解决上述问题,DNS服务应运而生,DNS协议提供通过域名查找IP地址,或逆向从IP地址反查域名的服务。
URI和URL
URI统一资源标识符——抽象的,高层次概念定义统一资源标识;
URL统一资源定位符——标示资源的位置;URL就是使用web浏览器等访问web页面时需要输入的网页地址。
HTTP
HTTP 请求报文结构
HTTP 报文是客户端和服务器之间通信的基本单位,分为请求报文(客户端→服务器)和响应报文(服务器→客户端)两种类型。它们都遵循相同的结构格式。
[起始行]
[头部字段]
[空行]
[消息主体]请求行
GET /api/users HTTP/1.1
-
请求方法:
GET,POST,PUT,DELETE等 -
请求目标:URI 路径(如
/api/users) -
HTTP 版本:
HTTP/1.1或HTTP/2
请求头
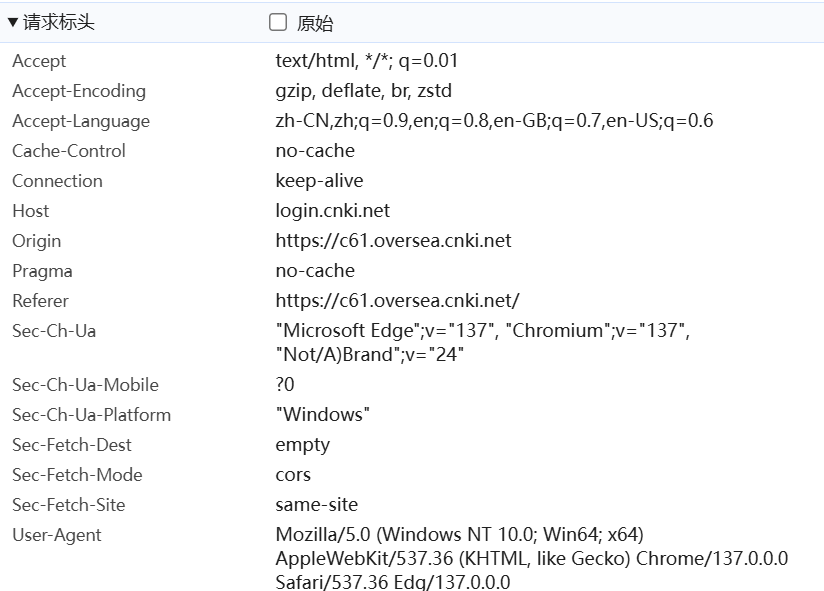
包含请求的元数据信息
格式:字段名: 值
常见头字段:
-
Host:目标主机(必需) -
User-Agent:客户端信息 -
Accept:可接受的响应类型 -
Content-Type:请求体的格式 -
Authorization:认证信息
空行
表示头部的结束
请求体
{
"name": "John",
"email": "john@example.com"
}
可选部分(GET 请求通常没有)
包含发送给服务器的数据
格式由 Content-Type 指定(如 JSON、表单数据等)
HTTP 响应报文结构
状态行
HTTP/1.1 200 OK
HTTP 版本:HTTP/1.1 或 HTTP/2
状态码:3 位数字(如 200)
状态文本:简短的描述(如 OK)
响应头
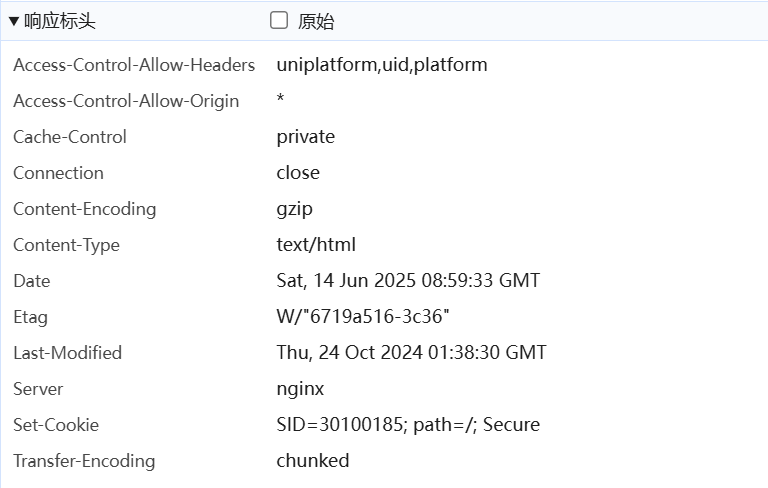
常见头字段:
-
Content-Type:响应体的格式 -
Content-Length:响应体大小(字节) -
Server:服务器软件信息 -
Set-Cookie:设置客户端 Cookie -
Cache-Control:缓存策略
空行
表示头部的结束
响应体
包含服务器返回的实际数据
格式由 Content-Type 指定
可以是 HTML、JSON、图片等任意数据
HTTP方法和状态码
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
HTTP 状态码类别
| 类别 | 范围 | 名称 | 核心含义 |
|---|---|---|---|
| 1xx | 100-199 | 信息响应 | 请求已接收,继续处理 |
| 2xx | 200-299 | 成功响应 | 请求被成功处理 |
| 3xx | 300-399 | 重定向 | 需要进一步操作以完成请求 |
| 4xx | 400-499 | 客户端错误 | 请求包含错误或无法完成 |
| 5xx | 500-599 | 服务器错误 | 服务器处理请求失败 |
常见HTTP状态码
成功响应 (2xx)
| 状态码 | 名称 | 使用场景 | 示例说明 |
|---|---|---|---|
| 200 | OK | 标准成功响应 | GET 获取资源成功,响应体包含数据 |
| 201 | Created | 资源创建成功 | POST 创建新用户,响应头包含 Location: /users/123 |
| 204 | No Content | 请求成功但无返回内容 | DELETE 删除资源成功,PUT 更新成功无需返回数据 |
| 202 | Accepted | 请求已接受但未处理完成 | 异步任务(如订单处理中) |
| 206 | Partial Content | 返回部分内容 | 大文件分片下载(视频播放) |
重定向 (3xx)
| 状态码 | 名称 | 使用场景 | 特点说明 |
|---|---|---|---|
| 301 | Moved Permanently | 资源永久移动到新位置 | 浏览器会缓存重定向,SEO 权重转移 |
| 302 | Found | 资源临时移动到新位置 | 默认行为:原请求方法转为 GET |
| 304 | Not Modified | 资源未修改(使用缓存) | 响应无 body,节省带宽 |
| 307 | Temporary Redirect | 临时重定向(保持原请求方法) | POST 重定向时仍用 POST |
| 308 | Permanent Redirect | 永久重定向(保持原请求方法) | 更严格的 301 替代 |
客户端错误(4xx)
| 状态码 | 名称 | 使用场景 | 常见原因 |
|---|---|---|---|
| 400 | Bad Request | 请求语法错误 | JSON 格式错误、缺少必填参数 |
| 401 | Unauthorized | 需要身份验证 | 未提供 token 或 token 无效 |
| 403 | Forbidden | 服务器拒绝执行 | 权限不足(如普通用户访问管理员接口) |
| 404 | Not Found | 资源不存在 | URL 拼写错误、资源已被删除 |
| 405 | Method Not Allowed | 请求方法不被允许 | 用 GET 访问只支持 POST 的接口 |
| 408 | Request Timeout | 请求超时 | 服务器未及时收到完整请求 |
| 409 | Conflict | 资源冲突 | 创建重复用户(用户名已存在) |
| 429 | Too Many Requests | 请求过于频繁 | 触发 API 限流策略 |
| 422 | Unprocessable Entity | 请求语义正确但内容错误 | 表单验证失败(邮箱格式错误) |
服务器错误 (5xx)
| 状态码 | 名称 | 使用场景 | 排查方向 |
|---|---|---|---|
| 500 | Internal Server Error | 通用服务器错误 | 未捕获异常、代码逻辑错误 |
| 502 | Bad Gateway | 网关/代理服务器收到无效响应 | 上游服务崩溃、负载均衡配置错误 |
| 503 | Service Unavailable | 服务暂时不可用 | 服务器过载、维护停机 |
| 504 | Gateway Timeout | 网关超时 | 上游服务响应超时(数据库查询过慢) |
| 501 | Not Implemented | 服务器不支持请求的功能 | 请求了未实现的 HTTP 方法 |
关于HTTP方法和HTTP状态码文章:HTTP方法以及HTTP状态码-CSDN博客